Artikel ini menjelaskan beberapa strategi untuk mempartisi data di berbagai penyimpanan data Azure. Untuk panduan umum tentang waktu harus mempartisi data dan praktik terbaik, lihat Pemartisian data.
Pemartisian Azure SQL Database
Database SQL tunggal memiliki batas volume data yang ada di dalamnya. Throughput dibatasi oleh faktor arsitektur dan jumlah koneksi bersamaan yang didukungnya.
Kumpulan elastis mendukung penskalaan horizontal untuk database SQL. Dengan menggunakan kumpulan elastis, Anda dapat membagi data Anda menjadi shard yang tersebar di beberapa database SQL. Anda juga dapat menambahkan atau menghapus shard sebagai volume data yang perlu penambahan dan pengurangannya perlu ditangani. Kumpulan elastis juga dapat membantu mengurangi ketidaksesuaian dengan mendistribusikan beban di seluruh database.
Setiap shard diimplementasikan sebagai database SQL. Shard dapat menampung lebih dari satu himpunan data (disebut shardlet). Setiap database memelihara metadata yang menggambarkan shardlet di dalamnya. Shardlet dapat berupa satu item data, atau sekelompok item yang berbagi kunci shard yang sama. Misalnya, dalam aplikasi multipenyewa, kunci shardlet dapat berupa ID penyewa, dan semua data untuk penyewa dapat disimpan dalam shard yang sama.
Aplikasi klien bertanggung jawab untuk menghubungkan himpunan data dengan kunci shardlet. SQL Database terpisah bertindak sebagai manajer peta shard global. Database ini memiliki daftar semua shard dan shardlet dalam sistem. Aplikasi ini terhubung ke database manajer peta shard untuk mendapatkan salinan peta shard. Ini membuat cache peta shard secara lokal, dan menggunakan peta untuk merutekan permintaan data ke shard yang sesuai. Fungsi ini tersembunyi di balik serangkaian API yang ada dalam pustaka klien Elastic Database, yang tersedia untuk Java dan .NET.
Untuk informasi selengkapnya tentang kumpulan elastis, lihat Meluaskan skala dengan Azure SQL Database.
Untuk mengurangi latensi dan meningkatkan ketersediaan, Anda dapat mereplikasi database pengelola peta shard global. Dengan tingkat harga Premium, Anda dapat mengonfigurasi replikasi geografis aktif untuk terus menyalin data ke database di berbagai wilayah.
Atau, gunakan Azure SQL Data Sync atau Azure Data Factory untuk mereplikasi database pengelola peta shard di seluruh wilayah. Bentuk replikasi ini berjalan secara berkala dan lebih cocok jika peta shard jarang berubah, dan tidak memerlukan tingkat Premium.
Elastic Database menyediakan dua skema untuk memetakan data ke shardlet dan menyimpannya dalam shard:
Peta shard daftar mengaitkan satu kunci untuk shardlet. Misalnya, dalam sistem multipenyewa, data untuk setiap penyewa dapat dikaitkan dengan kunci unik dan disimpan dalam shardlet-nya sendiri. Untuk menjamin isolasi, setiap shardlet dapat dipegang dalam shard-nya sendiri.

Unduh file Visio dari diagram ini.
Peta shard rentang mengaitkan satu set nilai kunci yang berdekatan dengan shardlet. Misalnya, Anda dapat mengelompokkan data untuk sekumpulan penyewa (masing-masing dengan kuncinya sendiri) dalam shardlet yang sama. Skema ini lebih murah daripada yang pertama, karena penyewa berbagi penyimpanan data, tetapi memiliki lebih sedikit isolasi.

Mengunduh file Visio dari diagram ini
Satu shard dapat berisi data untuk beberapa shardlet. Misalnya, Anda dapat menggunakan shardlet daftar untuk menyimpan data untuk penyewa yang tidak berdekatan yang berbeda dalam shard yang sama. Anda juga dapat mencampur shardlet rentang dan shardlet daftar dalam shard yang sama, meskipun shardlet tersebut akan ditangani melalui peta yang berbeda. Diagram berikut menunjukkan pendekatan ini:

Unduh file Visio dari diagram ini.
Kumpulan elastis memungkinkan untuk menambahkan dan menghapus shard saat volume data berkurang dan bertambah. Aplikasi klien dapat membuat dan menghapus shard secara dinamis, dan memperbarui pengelola peta shard secara transparan. Namun, menghapus shard adalah operasi destruktif yang juga membutuhkan penghapusan semua data dalam shard tersebut.
Jika aplikasi perlu membagi shard menjadi dua shard terpisah atau menggabungkan shard, gunakan alat pembagi-penggabung. Alat ini berjalan sebagai layanan web Azure, dan memigrasikan data dengan aman di antara shard.
Skema pemartisian dapat secara signifikan memengaruhi performa sistem Anda. Hal ini juga dapat memengaruhi tingkat letak shard harus ditambahkan atau dihapus, atau data yang harus repartisi di shard. Pertimbangkan poin-poin berikut:
Mengelompokkan data yang digunakan bersama dalam shard yang sama, dan hindari operasi yang mengakses data dari beberapa shard. Shard adalah database SQL dengan sendirinya, dan gabungan lintas database harus dilakukan di sisi klien.
Meskipun SQL Database tidak mendukung gabungan lintas database, Anda dapat menggunakan alat Elastic Database untuk melakukan kueri multi-shard. Kueri multi-shard mengirimkan kueri individual ke setiap database dan menggabungkan hasilnya.
Jangan mendesain sistem yang memiliki ketergantungan antar-shard. Batasan integritas referensial, pemicu, dan prosedur yang disimpan dalam satu database tidak dapat merujuk objek di database lain.
Jika Anda memiliki data referensi yang sering digunakan oleh kueri, pertimbangkan untuk mereplikasi data ini di seluruh shard. Pendekatan ini dapat menghapus kebutuhan untuk menggabungkan data di seluruh database. Idealnya, data tersebut harus statis atau bergerak lambat, untuk meminimalkan upaya replikasi dan mengurangi kemungkinan data menjadi usang.
Shardlet yang termasuk dalam peta shard yang sama harus memiliki skema yang sama. Aturan ini tidak diberlakukan oleh SQL Database, tetapi manajemen data dan kueri menjadi sangat kompleks jika setiap shardlet memiliki skema yang berbeda. Sebagai gantinya, buat peta shard terpisah untuk setiap skema. Ingatlah bahwa data milik shardlet yang berbeda dapat disimpan dalam shard yang sama.
Operasi transaksional hanya didukung untuk data dalam satu shard, dan bukan di seluruh shard. Transaksi dapat menjangkau shardlet selama merupakan bagian dari shard yang sama. Oleh karena itu, jika logika bisnis Anda perlu melakukan transaksi, simpan data dalam shard yang sama atau terapkan konsistensi akhirnya.
Tempatkan shard dekat dengan pengguna yang mengakses data di shard tersebut. Strategi ini membantu mengurangi latensi.
Hindari memiliki campuran shard yang sangat aktif dan relatif tidak aktif. Cobalah untuk menyebarkan beban secara merata di shard. Ini mungkin memerlukan hash kunci shard. Jika Anda merupakan shard geolokasi, pastikan bahwa kunci hash memetakan shardlet yang disimpan dalam shard yang disimpan dekat dengan pengguna yang mengakses data itu.
Mempartisi penyimpanan Azure Table
Penyimpanan Azure Table adalah penyimpanan kunci-nilai yang dirancang di sekitar partisi. Semua entitas disimpan dalam partisi, dan partisi dikelola secara internal oleh penyimpanan Azure Table. Setiap entitas yang disimpan dalam tabel harus menyediakan kunci dua bagian yang mencakup:
Kunci partisi. Ini adalah nilai string yang menentukan partisi tempat penyimpanan Azure Table akan menempatkan entitas. Semua entitas dengan kunci partisi yang sama disimpan dalam partisi yang sama.
Kunci baris. Ini adalah nilai string yang mengidentifikasi entitas dalam partisi. Semua entitas dalam partisi diurutkan secara leksikal, dalam urutan naik, dengan kunci ini. Kombinasi kunci partisi/baris kunci harus unik untuk setiap entitas dan panjangnay tidak boleh melebihi 1 KB.
Jika entitas ditambahkan ke tabel dengan kunci partisi yang sebelumnya tidak digunakan, penyimpanan Azure Table membuat partisi baru untuk entitas ini. Entitas lain dengan kunci partisi yang sama akan disimpan di partisi yang sama.
Mekanisme ini secara efektif menerapkan strategi peluasan skala otomatis. Setiap partisi disimpan di server yang sama di pusat data Azure untuk membantu memastikan bahwa kueri yang mengambil data dari satu partisi berjalan dengan cepat.
Microsoft telah menerbitkan target skalabilitas untuk Azure Storage. Jika sistem Anda cenderung melebihi batas ini, pertimbangkan untuk membagi entitas menjadi beberapa tabel. Gunakan partisi vertikal untuk membagi bidang menjadi grup yang paling mungkin diakses bersama.
Diagram berikut menunjukkan struktur logis akun penyimpanan contoh. Akun penyimpanan berisi tiga tabel: Info Pelanggan, Info Produk, dan Info Pesanan.
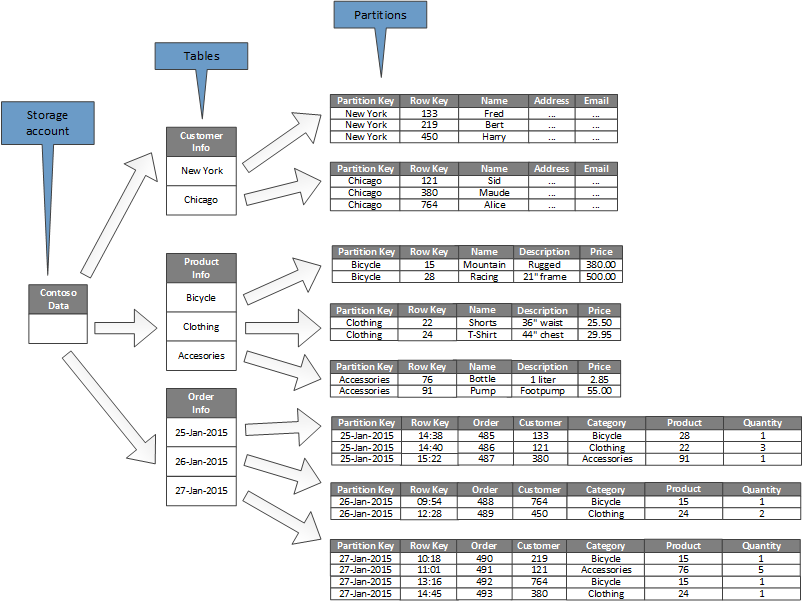
Setiap tabel memiliki beberapa partisi.
- Dalam tabel Info Pelanggan, data dipartisi sesuai dengan kota tempat pelanggan berada. Kunci baris berisi ID pelanggan.
- Dalam tabel Info Produk, produk dipartisi berdasarkan kategori produk, dan kunci baris berisi nomor produk.
- Dalam tabel Info Pesanan, pesanan dipartisi berdasarkan tanggal pesanan, dan kunci baris menentukan waktu pesanan diterima. Semua data dipesan oleh tombol baris di setiap partisi.
Pertimbangkan poin-poin berikut saat Anda merancang entitas Anda untuk penyimpanan Azure Table:
Pilih kunci partisi dan tombol baris dengan cara data diakses. Pilih kombinasi kunci/baris partisi yang mendukung sebagian besar kueri Anda. Kueri yang paling efisien mengambil data dengan menentukan kunci partisi dan kunci baris. Kueri yang menentukan kunci partisi dan berbagai tombol baris dapat diselesaikan dengan memindai satu partisi. Ini relatif cepat karena data disimpan dalam urutan kunci baris. Jika kueri tidak menentukan partisi mana yang akan dipindai, setiap partisi harus dipindai.
Jika entitas memiliki satu kunci alami, gunakan sebagai kunci partisi dan tentukan string kosong sebagai kunci baris. Jika entitas memiliki kunci komposit yang terdiri dari dua properti, pilih properti yang paling lambat berubah sebagai kunci partisi dan yang lainnya sebagai kunci baris. Jika entitas memiliki lebih dari dua properti utama, gunakan penggabungan properti untuk menyediakan kunci partisi dan baris.
Jika Anda secara teratur melakukan kueri yang mencari data dengan menggunakan bidang selain kunci partisi dan baris, pertimbangkan untuk menerapkan pola Tabel Indeks, atau pertimbangkan untuk menggunakan penyimpanan data berbeda yang mendukung pengindeksan, seperti Azure Cosmos DB.
Jika Anda menghasilkan kunci partisi dengan menggunakan urutan monotonik (seperti "0001", "0002", "0003") dan setiap partisi hanya berisi sejumlah data terbatas, penyimpanan Azure Table dapat mengelompokkan partisi ini secara fisik bersama-sama di server yang sama. Azure Storage mengasumsikan bahwa aplikasi ini kemungkinan besar akan melakukan kueri di berbagai partisi yang berdekatan (kueri rentang) dan dioptimalkan untuk kasus ini. Namun, pendekatan ini dapat menyebabkan hotspot, karena semua penyisipan entitas baru cenderung terkonsentrasi di salah satu ujung jangkauan yang berdekatan. Hal ini juga dapat mengurangi skalabilitas. Untuk menyebarkan beban lebih merata, pertimbangkan untuk melakukan hash kunci partisi.
Penyimpanan Azure Table mendukung operasi transaksional untuk entitas milik partisi yang sama. Aplikasi dapat melakukan beberapa penyisipan, pembaruan, penghapusan, penggantian, atau penggabungan operasi sebagai unit atom, selama transaksi tidak mencakup lebih dari 100 entitas dan payload permintaan tidak melebihi 4 MB. Operasi yang mencakup beberapa partisi bersifat tidak transaksional, dan mungkin mengharuskan Anda untuk menerapkan konsistensi akhirnya. Untuk informasi selengkapnya tentang penyimpanan dan transaksi tabel, lihat Melakukan transaksi grup entitas.
Pertimbangkan granularitas kunci partisi:
Menggunakan kunci partisi yang sama untuk setiap entitas menghasilkan satu partisi yang disimpan pada satu server. Ini mencegah partisi meluaskan skala dan memfokuskan beban pada satu server. Akibatnya, pendekatan ini hanya cocok untuk menyimpan sejumlah kecil entitas. Namun, memastikan bahwa semua entitas dapat berpartisipasi dalam transaksi grup entitas.
Menggunakan kunci partisi unik untuk setiap entitas menyebabkan layanan penyimpanan tabel membuat partisi terpisah untuk setiap entitas, yang mungkin menghasilkan sejumlah besar partisi kecil. Pendekatan ini lebih terukur daripada menggunakan kunci partisi tunggal, tetapi transaksi grup entitas tidak dimungkinkan. Selain itu, kueri yang mengambil lebih dari satu entitas mungkin melibatkan pembacaan dari lebih dari satu server. Namun, jika aplikasi melakukan kueri rentang, menggunakan urutan monoton untuk tombol partisi dapat membantu mengoptimalkan kueri ini.
Berbagi kunci partisi di subset entitas memungkinkan untuk mengelompokkan entitas terkait di partisi yang sama. Operasi yang melibatkan entitas terkait dapat dilakukan dengan menggunakan transaksi grup entitas, dan kueri yang mengambil satu set entitas terkait dapat dipenuhi dengan mengakses satu server.
Untuk informasi selengkapnya, lihat Panduan desain tabel Azure Storage dan Strategi partisi yang dapat diskalakan.
Pemartisian Azure Blob Storage
Azure Blob Storage memungkinkan untuk menyimpan objek biner besar. Gunakan blob blok dalam skenario saat Anda perlu mengunggah atau mengunduh data dalam jumlah besar dengan cepat. Gunakan blob halaman untuk aplikasi yang memerlukan akses acak daripada serial ke bagian data.
Setiap blob (baik blok atau halaman) disimpan dalam kontainer di akun Azure Storage. Anda dapat menggunakan kontainer untuk mengelompokkan blob terkait yang memiliki persyaratan keamanan yang sama. Pengelompokan ini bersifat logis dan bukan fisik. Di dalam kontainer, setiap blob memiliki nama unik.
Kunci partisi untuk blob adalah nama akun + nama kontainer + nama blob. Kunci partisi digunakan untuk membagi data ke dalam rentang dan rentang ini seimbang di seluruh sistem. Blob dapat didistribusikan di banyak server untuk mengurangi akses ke blob, tetapi satu blob hanya dapat dilayani oleh satu server.
Jika skema penamaan Anda menggunakan stempel waktu atau pengenal numerik, ini dapat menyebabkan lalu lintas yang berlebihan masuk ke satu partisi, membatasi sistem dari penyeimbangan beban yang efektif. Misalnya, jika Anda memiliki operasi harian yang menggunakan objek blob dengan stempel waktu seperti dd-mm-yyyy, semua lalu lintas untuk operasi itu akan masuk ke satu server partisi. Sebagai gantinya, pertimbangkan untuk memulai nama dengan hash tiga digit. Untuk informasi selengkapnya, lihat Konvensi Penamaan Partisi.
Tindakan menulis satu blok atau halaman bersifat atomik, tetapi operasi yang mencakup blok, halaman, atau blob tidak. Jika Anda perlu memastikan konsistensi saat melakukan operasi tulis di seluruh blok, halaman, dan blob, keluarkan kunci tulis dengan menggunakan sewa blob.
Mempartisi antrean Azure Storage
Antrean Azure Storage memungkinkan Anda menerapkan olahpesan asinkron antar proses. Akun Azure Storage dapat berisi sejumlah antrean, dan setiap antrean dapat berisi sejumlah pesan. Satu-satunya batasan adalah ruang yang tersedia di akun penyimpanan. Ukuran maksimum pesan individual adalah 64 KB. Jika Anda memerlukan pesan yang lebih besar dari ini, pertimbangkan untuk menggunakan antrean Azure Service Bus sebagai gantinya.
Setiap antrean penyimpanan memiliki nama unik di dalam akun penyimpanan tempatnya berada. Antrean partisi Azure berdasarkan namanya. Semua pesan untuk antrean yang sama disimpan di partisi yang sama, yang dikontrol oleh satu server. Antrean yang berbeda dapat dikelola oleh server yang berbeda untuk membantu menyeimbangkan beban. Alokasi antrean ke server bersifat transparan untuk aplikasi dan pengguna.
Dalam aplikasi berskala besar, jangan gunakan antrean penyimpanan yang sama untuk semua instans aplikasi karena pendekatan ini dapat menyebabkan server yang menghosting antrean menjadi hotspot. Sebagai gantinya, gunakan antrean yang berbeda untuk area fungsional aplikasi yang berbeda. Antrean Azure Storage tidak mendukung transaksi, jadi mengarahkan pesan ke antrean yang berbeda harus memiliki sedikit efek pada konsistensi olahpesan.
Antrean Azure Storage dapat menangani hingga 2.000 pesan per detik. Jika Anda perlu memproses pesan dengan kecepatan lebih tinggi dari ini, pertimbangkan untuk membuat beberapa antrean. Misalnya, dalam aplikasi global, buat antrean penyimpanan terpisah di akun penyimpanan terpisah untuk menangani instans aplikasi yang sedang berjalan di setiap wilayah.
Pemartisian Azure Service Bus
Azure Service Bus menggunakan broker pesan untuk menangani pesan yang dikirim ke antrean atau topik Service Bus. Secara default, semua pesan yang dikirim ke antrean atau topik ditangani oleh proses broker pesan yang sama. Arsitektur ini dapat membatasi throughput keseluruhan antrean pesan. Namun, Anda juga dapat mempartisi antrean atau topik saat dibuat. Anda melakukan ini dengan mengatur properti EnablePartitioning dari deskripsi antrean atau topik menjadi true.
Antrean atau topik yang dipartisi dibagi menjadi beberapa fragmen, yang masing-masing didukung oleh penyimpanan pesan terpisah dan broker pesan. Service Bus bertanggung jawab untuk membuat dan mengelola fragmen ini. Saat aplikasi memposting pesan ke antrean atau topik yang dipartisi, Service Bus menetapkan pesan ke fragmen untuk antrean atau topik tersebut. Saat aplikasi menerima pesan dari antrean atau langganan, Service Bus memeriksa setiap fragmen untuk pesan berikutnya yang tersedia dan kemudian meneruskannya ke aplikasi untuk diproses.
Struktur ini membantu mendistribusikan beban di seluruh broker pesan dan penyimpanan pesan, meningkatkan skalabilitas dan meningkatkan ketersediaan. Jika broker pesan atau penyimpanan pesan untuk satu fragmen sementara tidak tersedia, Service Bus dapat mengambil pesan dari salah satu fragmen yang tersisa yang tersedia.
Service Bus memberikan pesan ke fragmen sebagai berikut:
Jika pesan milik sesi, semua pesan dengan nilai yang sama untuk properti SessionId dikirim ke fragmen yang sama.
Jika pesan bukan milik sesi, tetapi pengirim telah menentukan nilai untuk properti PartitionKey, semua pesan dengan nilai PartitionKey yang sama dikirim ke fragmen yang sama.
Catatan
Jika properti SessionId dan PartitionKey ditentukan, properti tersebut harus diatur ke nilai yang sama atau pesan akan ditolak.
Jika properti SessionId dan PartitionKey untuk pesan tidak ditentukan, tetapi deteksi duplikat diaktifkan, properti MessageId akan digunakan. Semua pesan dengan MessageId yang sama akan diarahkan ke fragmen yang sama.
Jika pesan tidak menyertakan properti SessionId, PartitionKey, atau MessageId, Service Bus menetapkan pesan ke fragmen secara berurutan. Jika fragmen tidak tersedia, Service Bus akan beralih ke fragmen berikutnya. Ini berarti bahwa kesalahan sementara dalam infrastruktur pesan tidak menyebabkan operasi pengiriman pesan gagal.
Pertimbangkan poin berikut saat memutuskan bagaimana atau jika akan mempartisi antrean atau topik pesan Service Bus:
Antrean dan topik Service Bus dibuat dalam cakupan nama Service Bus. Service Bus saat ini memungkinkan hingga 100 antrean atau topik yang dipartisi per namespace.
Setiap namespace Service Bus memberlakukan kuota pada sumber daya yang tersedia, seperti jumlah langganan per topik, jumlah permintaan kirim dan terima bersamaan per detik, dan jumlah maksimum koneksi bersamaan yang dapat dibuat. Kuota ini didokumentasikan dalam kuota Service Bus. Jika Anda berharap untuk melampaui nilai ini, buat namespace tambahan dengan antrean dan topiknya sendiri, dan sebarkan pekerjaan di seluruh namespace ini. Misalnya, dalam aplikasi global, buat namespace terpisah di setiap wilayah dan konfigurasikan instans aplikasi untuk menggunakan antrean dan topik di namespace terdekat.
Pesan yang dikirim sebagai bagian dari transaksi harus menentukan kunci partisi. Ini bisa berupa properti SessionId, PartitionKey, atau MessageId. Semua pesan yang dikirim sebagai bagian dari transaksi yang sama harus menentukan kunci partisi yang sama karena harus ditangani oleh proses broker pesan yang sama. Anda tidak dapat mengirim pesan ke antrean atau topik yang berbeda dalam transaksi yang sama.
Antrean dan topik yang dipartisi tidak dapat dikonfigurasi untuk dihapus secara otomatis saat tidak aktif.
Antrean dan topik yang dipartisi saat ini tidak dapat digunakan dengan Advanced Message Queuing Protocol (AMQP) jika Anda sedang membuat solusi lintas platform atau hibrid.
Partisi Azure Cosmos DB
Azure Cosmos DB for NoSQL adalah database NoSQL untuk menyimpan dokumen JSON. Dokumen dalam database Azure Cosmos DB adalah representasi objek yang diserialisasikan JSON atau bagian data lainnya. Tidak ada skema tetap yang diberlakukan kecuali bahwa setiap dokumen harus memiliki ID yang unik.
Dokumen disusun ke dalam koleksi. Anda dapat mengelompokkan dokumen terkait bersama-sama dalam satu koleksi. Misalnya, dalam sistem yang mempertahankan posting blog, Anda dapat menyimpan konten setiap posting blog sebagai dokumen dalam satu koleksi. Anda juga dapat membuat koleksi untuk setiap jenis subjek. Atau, dalam aplikasi multipenyewa, seperti sistem tempat penulis yang berbeda mengontrol dan mengelola posting blog mereka sendiri, Anda dapat mempartisi blog dengan penulis dan membuat koleksi terpisah untuk setiap penulis. Ruang penyimpanan yang dialokasikan ke koleksi bersifat elastis dan dapat berkurang atau bertambah sesuai kebutuhan.
Azure Cosmos DB mendukung pemartisian data otomatis berdasarkan kunci partisi yang ditentukan aplikasi. Partisi logis adalah partisi yang menyimpan semua data untuk nilai kunci partisi tunggal. Semua dokumen yang memiliki nilai yang sama untuk kunci partisi ditempatkan dalam partisi logis yang sama. Azure Cosmos DB mendistribusikan nilai sesuai dengan hash kunci partisi. Partisi logis memiliki ukuran maksimum 20 GB. Oleh karena itu, pilihan kunci partisi adalah keputusan penting pada waktu desain. Pilih properti dengan berbagai nilai dan bahkan pola akses. Untuk informasi selengkapnya, lihat Mempartisi dan menskalakan di Azure Cosmos DB.
Catatan
Setiap database Azure Cosmos DB memiliki tingkat performa yang menentukan jumlah sumber daya yang didapatkannya. Tingkat performa dikaitkan dengan batas rasio unit permintaan (RU). Batas rasio RU menentukan volume sumber daya yang dicadangkan dan tersedia untuk penggunaan eksklusif oleh koleksi tersebut. Biaya koleksi tergantung pada tingkat performa yang dipilih untuk koleksi tersebut. Semakin tinggi tingkat performa (dan batas rasio RU) semakin tinggi biayanya. Anda dapat menyesuaikan tingkat performa koleksi dengan menggunakan portal Azure. Untuk informasi selengkapnya, lihat Unit Permintaan di Azure Cosmos DB.
Jika mekanisme partisi yang disediakan Azure Cosmos DB tidak cukup, Anda mungkin perlu memecah data di tingkat aplikasi. Pengumpulan dokumen menyediakan mekanisme alami untuk mempartisi data dalam satu database. Cara paling sederhana untuk menerapkan shard adalah dengan membuat koleksi untuk setiap shard. Kontainer adalah sumber daya logis dan dapat menjangkau satu atau beberapa server. Kontainer berukuran tetap memiliki batas maksimum 20 GB dan throughput 10.000 RU/dtk. Kontainer tak terbatas tidak memiliki ukuran penyimpanan maksimum, tetapi harus menentukan kunci partisi. Dengan shard aplikasi, aplikasi klien harus mengarahkan permintaan ke shard yang sesuai, biasanya dengan menerapkan mekanisme pemetaan sendiri berdasarkan beberapa atribut data yang menentukan kunci shard.
Semua database dibuat dalam konteks akun database Azure Cosmos DB. Satu akun dapat berisi beberapa database, dan menentukan di wilayah mana database dibuat. Setiap akun juga memberlakukan kontrol aksesnya sendiri. Anda dapat menggunakan akun Azure Cosmos DB untuk menemukan pecahan lokasi geografis (koleksi dalam database) yang dekat dengan pengguna yang perlu mengaksesnya, dan menerapkan pembatasan sehingga hanya pengguna yang dapat terhubung ke mereka.
Pertimbangkan poin-poin berikut saat memutuskan cara mempartisi data dengan Azure Cosmos DB for NoSQL:
Sumber daya yang tersedia untuk database Azure Cosmos DB tunduk pada batasan kuota akun. Setiap database dapat menyimpan sejumlah koleksi, dan setiap koleksi dikaitkan dengan tingkat performa yang mengatur batas rasio RU (throughput cadangan) untuk koleksi tersebut. Untuk informasi selengkapnya, lihat Batas, kuota, dan batasan langganan dan layanan Azure.
Setiap dokumen harus memiliki atribut yang dapat digunakan untuk secara unik mengidentifikasi dokumen tersebut dalam koleksi tempat dokumen tersebut disimpan. Atribut ini berbeda dari kunci shard, yang mendefinisikan koleksi mana yang memegang dokumen. Koleksi dapat berisi sejumlah besar dokumen. Secara teori, koleksi hanya dibatasi oleh panjang maksimum ID dokumen. ID dokumen bisa mencapai 255 karakter.
Semua operasi terhadap dokumen dilakukan dalam konteks transaksi. Transaksi dicakup ke koleksi tempat dokumen tersebut berada. Jika operasi gagal, pekerjaan yang telah dilakukan akan digulung balik. Sementara dokumen tunduk pada operasi, setiap perubahan yang dilakukan tunduk pada isolasi tingkat snapshot. Mekanisme ini menjamin bahwa jika, misalnya, permintaan untuk membuat dokumen baru gagal, pengguna lain yang mengkueri database secara bersamaan tidak akan melihat dokumen parsial yang kemudian dihapus.
Kueri database juga dicakup ke tingkat koleksi. Satu kueri dapat mengambil data hanya dari satu koleksi. Jika perlu mengambil data dari beberapa koleksi, Anda harus meminta setiap koleksi secara individual dan menggabungkan hasilnya dalam kode aplikasi Anda.
Azure Cosmos DB mendukung item yang dapat diprogram yang semuanya dapat disimpan dalam koleksi bersama dokumen. Ini termasuk prosedur tersimpan, fungsi yang ditentukan pengguna, dan pemicu (ditulis dalam JavaScript). Item ini dapat mengakses dokumen apa pun dalam koleksi yang sama. Selain itu, item ini berjalan baik di dalam cakupan transaksi sekitar (dalam kasus pemicu yang aktif sebagai hasil dari membuat, menghapus, atau mengganti operasi yang dilakukan terhadap dokumen), atau dengan memulai transaksi baru (dalam kasus prosedur yang disimpan yang dijalankan sebagai hasil dari permintaan klien eksplisit). Jika kode dalam item yang dapat diprogram melempar pengecualian, transaksi akan digulung balik. Anda dapat menggunakan prosedur dan pemicu tersimpan untuk menjaga integritas dan konsistensi antardokumen, tetapi dokumen ini semuanya harus menjadi bagian dari koleksi yang sama.
Koleksi yang ingin Anda pegang dalam database seharusnya tidak mungkin melebihi batas throughput yang ditentukan oleh tingkat performa koleksi. Untuk informasi selengkapnya, lihat Unit Permintaan di Azure Cosmos DB. Jika Anda mengantisipasi mencapai batas ini, pertimbangkan untuk membagi koleksi di seluruh database di akun yang berbeda untuk mengurangi beban per koleksi.
Pemartisian Azure Search
Kemampuan untuk mencari data sering kali merupakan metode utama navigasi dan eksplorasi yang disediakan oleh banyak aplikasi web. Ini membantu pengguna menemukan sumber daya dengan cepat (misalnya, produk dalam aplikasi e-niaga) berdasarkan kombinasi kriteria pencarian. Layanan Azure Search menyediakan kemampuan pencarian teks lengkap melalui konten web, dan mencakup fitur seperti type-ahead, kueri yang disarankan berdasarkan kecocokan dekat, dan navigasi tersaring. Untuk informasi selengkapnya, lihat Apa itu Azure Search?.
Azure Search menyimpan konten yang dapat dicari sebagai dokumen JSON dalam database. Anda menentukan indeks yang menentukan bidang yang dapat dicari dalam dokumen ini dan memberikan definisi ini ke Azure Search. Saat pengguna mengirimkan permintaan penelusuran, Azure Search menggunakan indeks yang sesuai untuk menemukan item yang cocok.
Untuk mengurangi ketidaksesuaian, penyimpanan yang digunakan oleh Azure Search dapat dibagi menjadi 1, 2, 3, 4, 6, atau 12 partisi, dan setiap partisi dapat direplikasi hingga 6 kali. Produk dari jumlah partisi dikalikan dengan jumlah replika disebut unit pencarian (SU). Satu instans Azure Search dapat berisi maksimum 36 SU (database dengan 12 partisi hanya mendukung maksimal 3 replika).
Anda ditagih untuk setiap SU yang dialokasikan untuk layanan Anda. Seiring meningkatnya volume konten yang dapat dicari atau tingkat permintaan penelusuran bertambah, Anda dapat menambahkan SU ke instans Azure Search yang ada untuk menangani beban tambahan. Azure Search sendiri mendistribusikan dokumen secara merata di seluruh partisi. Tidak ada strategi partisi manual yang saat ini didukung.
Setiap partisi dapat berisi maksimum 15 juta dokumen atau menempati 300 GB ruang penyimpanan (mana yang lebih kecil). Anda dapat membuat hingga 50 indeks. Performa layanan bervariasi dan tergantung pada kompleksitas dokumen, indeks yang tersedia, dan efek latensi jaringan. Rata-rata, satu replika (1 SU) harus dapat menangani 15 kueri per detik (QPS), meskipun sebaiknya lakukan pembandingan dengan data Anda sendiri untuk mendapatkan ukuran throughput yang lebih tepat. Untuk informasi selengkapnya, lihat Batas layanan di Azure Search.
Catatan
Anda dapat menyimpan kumpulan tipe data terbatas dalam dokumen yang dapat dicari, termasuk string, Boolean, data numerik, data tanggalwaktu, dan beberapa data geografis. Untuk informasi selengkapnya, lihat halaman Tipe data yang didukung (Azure Search) di situs web Microsoft.
Anda memiliki kontrol terbatas atas cara Azure Search mempartisi data untuk setiap instans layanan. Namun, dalam lingkungan global Anda mungkin dapat meningkatkan performa dan mengurangi latensi dan ketidaksesuaian lebih lanjut dengan mempartisi layanan itu sendiri menggunakan salah satu strategi berikut:
Buat instans Azure Search di setiap wilayah geografis, dan pastikan aplikasi klien diarahkan ke instans terdekat yang tersedia. Strategi ini mengharuskan setiap pembaruan untuk konten yang dapat dicari direplikasi pada waktu yang tepat di semua instans layanan.
Buat dua tingkatan Azure Search:
- Layanan lokal di setiap wilayah yang berisi data yang paling sering diakses oleh pengguna di wilayah tersebut. Pengguna dapat mengarahkan permintaan di sini untuk hasil yang cepat namun terbatas.
- Layanan global yang mencakup semua data. Pengguna dapat mengarahkan permintaan di sini untuk hasil yang lebih lambat tetapi lebih lengkap.
Pendekatan ini paling cocok saat ada variasi regional yang signifikan dalam data yang sedang dicari.
Pemartisian Azure Cache for Redis
Azure Cache for Redis menyediakan layanan penembolokan bersama di cloud yang didasarkan pada penyimpanan data nilai kunci Redis. Sesuai namanya, Azure Cache for Redis dimaksudkan sebagai solusi penembolokan. Gunakan hanya untuk menyimpan data sementara dan bukan sebagai penyimpanan data permanen. Aplikasi yang menggunakan Azure Cache for Redis harus dapat terus berfungsi jika cache tidak tersedia. Azure Cache for Redis mendukung replikasi primer/sekunder untuk menyediakan ketersediaan tinggi, tetapi saat ini membatasi ukuran cache maksimum hingga 53 GB. Jika membutuhkan lebih banyak ruang dari ini, Anda harus membuat cache tambahan. Untuk informasi selengkapnya, lihat Azure Cache for Redis.
Partisi penyimpanan data Redis melibatkan pemisahan data di seluruh contoh layanan Redis. Setiap instans merupakan partisi tunggal. Azure Cache for Redis mengabstraksi layanan Redis di balik fasad dan tidak mengeksposnya secara langsung. Cara paling sederhana untuk menerapkan partisi adalah dengan membuat beberapa instansAzure Cache for Redis dan menyebarkan data di seluruhnya.
Anda dapat mengaitkan setiap item data dengan pengidentifikasi (kunci partisi) yang menentukan cache mana yang menyimpan item data. Logika aplikasi klien kemudian dapat menggunakan pengidentifikasi ini untuk merutekan permintaan ke partisi yang sesuai. Skema ini sangat sederhana, tetapi jika skema partisi berubah (misalnya, jika instans Azure Cache for Redis tambahan dibuat), aplikasi klien mungkin perlu dikonfigurasi ulang.
Native Redis (bukan Azure Cache for Redis) mendukung partisi sisi server berdasarkan pengklusteran Redis. Dalam pendekatan ini, Anda dapat membagi data secara merata di seluruh server dengan menggunakan mekanisme hash. Setiap server Redis menyimpan metadata yang menggambarkan rentang kunci hash yang dimiliki partisi, dan juga berisi informasi tentang kunci hash mana yang terletak di partisi di server lain.
Aplikasi klien cukup mengirim permintaan ke salah satu server Redis yang berpartisipasi (mungkin yang terdekat). Server Redis memeriksa permintaan klien. Jika dapat diselesaikan secara lokal, server Redis melakukan operasi yang diminta. Jika tidak, meneruskan permintaan ke server yang sesuai.
Model ini diimplementasikan dengan menggunakan pengklusteran Redis, dan dijelaskan secara lebih rinci pada halaman tutorial kluster Redis di situs web Redis. Pengklusteran Redis transparan untuk aplikasi klien. Server Redis tambahan dapat ditambahkan ke kluster (dan data dapat dipartisi ulang) tanpa mengharuskan Anda mengonfigurasi ulang klien.
Penting
Azure Cache for Redis saat ini hanya mendukung pengklusteran Redis di tingkat Premium.
Halaman Pemartisian: cara membagi data di antara beberapa instans Redis di situs web Redis memberikan informasi lebih lanjut tentang penerapan partisi dengan Redis. Sisa bagian ini mengasumsikan bahwa Anda menerapkan partisi sisi klien atau dengan bantuan proksi.
Pertimbangkan poin-poin berikut saat memutuskan cara mempartisi data dengan Azure Cache for Redis:
Azure Cache for Redis tidak dimaksudkan untuk bertindak sebagai penyimpanan data permanen, jadi skema partisi apa pun yang Anda terapkan, kode aplikasi Anda harus dapat mengambil data dari lokasi yang bukan cache.
Data yang sering diakses bersama harus disimpan di partisi yang sama. Redis adalah penyimpanan nilai kunci yang kuat yang menyediakan beberapa mekanisme yang sangat dioptimalkan untuk penataan data. Mekanisme ini dapat menjadi salah satu dari yang berikut:
- String sederhana (panjang data biner hingga 512 MB)
- Tipe agregat seperti daftar (yang dapat bertindak sebagai antrean dan tumpukan)
- Rangkaian (diurutkan dan tidak diurutkan)
- Hash (yang dapat mengelompokkan bidang terkait bersama-sama, seperti item yang mewakili bidang dalam suatu objek)
Jenis agregat memungkinkan Anda mengasosiasikan banyak nilai terkait dengan kunci yang sama. Kunci Redis mengidentifikasi daftar, rangkaian, atau hash daripada item data yang ada. Semua jenis ini tersedia dengan Azure Cache for Redis dan dijelaskan oleh halaman Tipe data di situs web Redis. Misalnya, di bagian dari sistem e-niaga yang melacak pesanan yang dibuat oleh pelanggan, detail setiap pelanggan dapat disimpan dalam hash Redis yang dikunci dengan menggunakan ID pelanggan. Setiap hash dapat menyimpan koleksi ID pesanan untuk pelanggan. Serangkaian Redis terpisah dapat menyimpan pesanan, sekali lagi terstruktur sebagai hash, dan dikunci dengan menggunakan ID pesanan. Gambar 8 menunjukkan struktur ini. Perhatikan bahwa Redis tidak menerapkan segala bentuk integritas referensial, sehingga merupakan tanggung jawab pengembang untuk menjaga hubungan antara pelanggan dan pesanan.
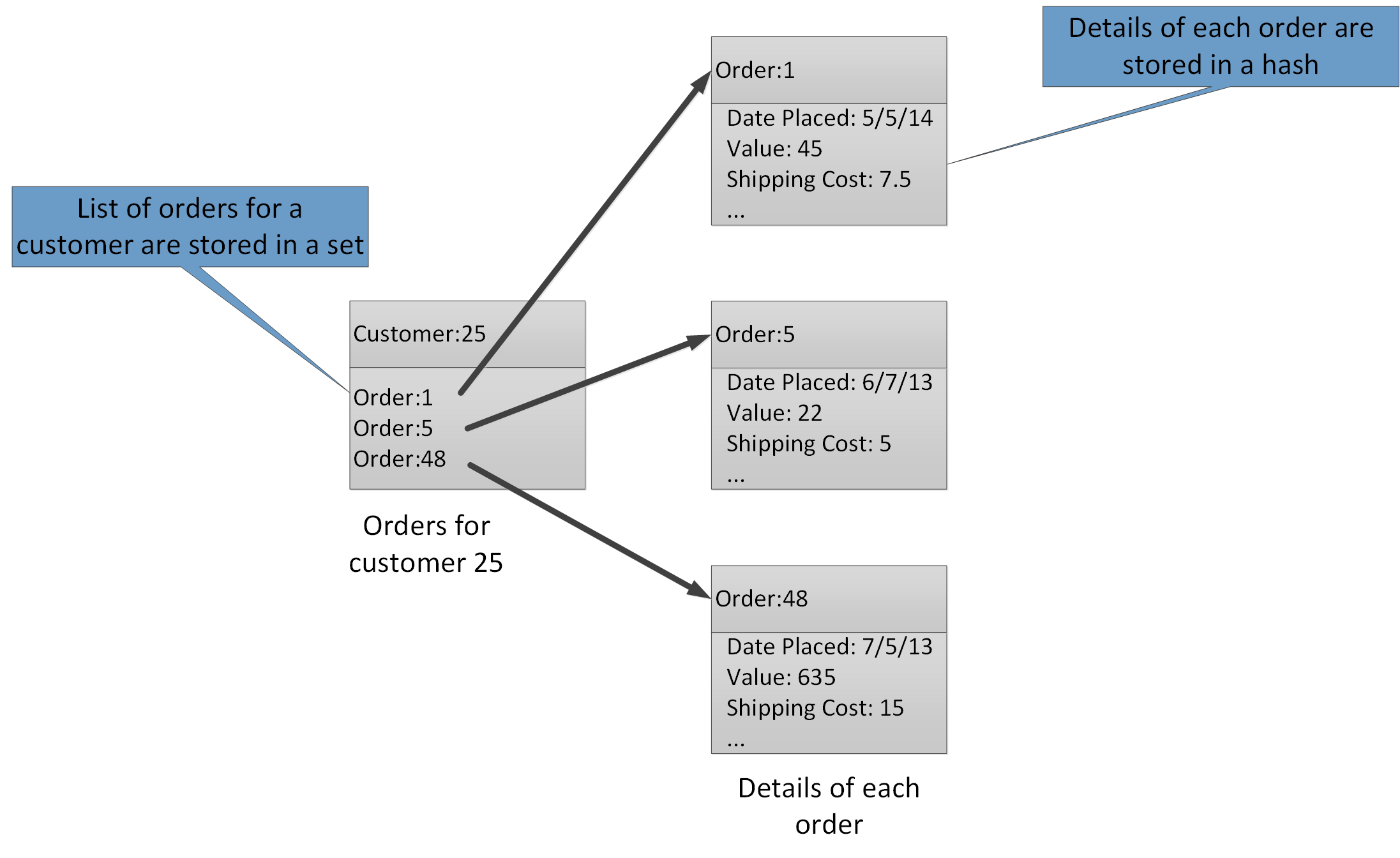
Gambar 8. Struktur yang disarankan dalam penyimpanan Redis untuk merekam pesanan pelanggan dan detailnya.
Catatan
Di Redis, semua kunci adalah nilai data biner (seperti string Redis) dan dapat berisi hingga 512 MB data. Secara teori, kunci dapat berisi hampir semua informasi. Namun, kami sarankan untuk mengadopsi konvensi penamaan yang konsisten untuk kunci yang deskriptif dari jenis data dan yang mengidentifikasi entitas, tetapi tidak terlalu panjang. Pendekatan umum adalah menggunakan kunci formulir "entity_type:ID". Misalnya, Anda dapat menggunakan "customer:99" untuk menunjukkan kunci bagi pelanggan dengan ID 99.
Anda dapat menerapkan partisi vertikal dengan menyimpan informasi terkait dalam agregasi yang berbeda dalam database yang sama. Misalnya, dalam aplikasi e-niaga, Anda dapat menyimpan informasi yang umum diakses tentang produk dalam satu hash Redis dan lebih jarang menggunakan informasi terperinci di hash lain. Kedua hash dapat menggunakan ID produk yang sama sebagai bagian dari kunci. Misalnya, Anda dapat menggunakan "product: nn" (dengan nn adalah ID produk) untuk informasi produk dan "product_details: nn" untuk data terperinci. Strategi ini dapat membantu mengurangi volume data yang kemungkinan besar akan diambil oleh sebagian besar kueri.
Anda dapat mempartisi ulang penyimpanan data Redis, tetapi perlu diingat bahwa ini adalah tugas yang kompleks dan memakan waktu. Pengklusteran Redis dapat mempartisi ulang data secara otomatis, tetapi kemampuan ini tidak tersedia dengan Azure Cache for Redis. Oleh karena itu, saat Anda merancang skema partisi, cobalah untuk memberikan ruang kosong yang cukup di setiap partisi untuk memungkinkan pertumbuhan data yang diharapkan dari waktu ke waktu. Namun, ingatlah bahwa Azure Cache for Redis dimaksudkan untuk menyimpan data sementara, dan data yang disimpan dalam cache dapat memiliki masa pakai terbatas yang ditentukan sebagai nilai time-to-live (TTL). Untuk data yang relatif mudah menguap, TTL bisa pendek, tetapi untuk data statis, TTL bisa jauh lebih lama. Hindari menyimpan sejumlah besar data berumur panjang dalam cache jika volume data ini cenderung mengisi cache. Anda dapat menentukan kebijakan pengeluaran yang menyebabkan Azure Cache for Redis menghapus data jika ruang berada pada tingkat premium.
Catatan
Saat menggunakan Azure Cache for Redis, Anda menentukan ukuran maksimum cache (dari 250 MB hingga 53 GB) dengan memilih tingkat harga yang sesuai. Namun, setelah Azure Cache for Redis dibuat, Anda tidak dapat menambahkan (atau mengurangi) ukurannya.
Batch dan transaksi Redis tidak dapat menjangkau beberapa koneksi, sehingga semua data yang terpengaruh oleh batch atau transaksi harus disimpan dalam database yang sama (shard).
Catatan
Urutan operasi dalam transaksi Redis belum tentu bersifat atomik. Perintah yang menyusun transaksi diverifikasi dan diantrekan sebelum dijalankan. Jika terjadi kesalahan selama fase ini, seluruh antrean akan dibuang. Namun, setelah transaksi berhasil dikirimkan, perintah antrean berjalan secara berurutan. Jika ada perintah yang gagal, hanya perintah tersebut yang berhenti berjalan. Semua perintah sebelumnya dan berikutnya dalam antrean dilakukan. Untuk informasi selengkapnya, buka halaman Transaksi di situs web Redis.
Redis mendukung sejumlah operasi atomik. Satu-satunya operasi tipe ini yang mendukung beberapa kunci dan nilai adalah operasi MGET dan MSET. Operasi MGET menampilkan koleksi nilai untuk daftar kunci tertentu, dan operasi MSET menyimpan koleksi nilai untuk daftar kunci tertentu. Jika Anda perlu menggunakan operasi ini, pasangan nilai-kunci yang dirujuk oleh perintah MSET dan MGET harus disimpan dalam database yang sama.
Pemartisian Azure Service Fabric
Azure Service Fabric adalah platform layanan mikro yang menyediakan runtime untuk aplikasi terdistribusi di cloud. Service Fabric mendukung executable tamu .NET, layanan stateful dan stateless, dan kontainer. Layanan stateful menyediakan koleksi yang andal untuk menyimpan data secara terus-menerus dalam pengumpulan nilai kunci dalam kluster Service Fabric. Untuk informasi selengkapnya tentang strategi untuk mempartisi kunci dalam koleksi yang andal, lihat Panduan dan rekomendasi untuk koleksi yang andal di Azure Service Fabric.
Langkah berikutnya
Gambaran umum Azure Service Fabric adalah pengantar Azure Service Fabric.
Layanan Service Fabric partisi andal ini menyediakan informasi selengkapnya tentang layanan andal di Azure Service Fabric.
Pemartisian Azure Event Hubs
Azure Event Hubs dirancang untuk streaming data dalam skala besar, dan partisi ada di dalam layanan untuk mengaktifkan penskalaan horizontal. Setiap konsumen hanya membaca partisi tertentu dari aliran pesan.
Penerbit acara hanya mengetahui kunci partisinya, bukan partisi di mana peristiwa diterbitkan. Pemisahan kunci dan partisi ini membuat pengirim tidak perlu mengetahui terlalu banyak tentang pemrosesan hilir. (Dimungkinkan juga mengirim peristiwa langsung ke partisi tertentu, tetapi umumnya tidak disarankan.)
Pertimbangkan skala jangka panjang saat Anda memilih jumlah partisi. Setelah hub peristiwa dibuat, Anda tidak dapat mengubah jumlah partisi.
Langkah berikutnya
Untuk informasi selengkapnya tentang menggunakan partisi di Event Hubs, lihat Apa itu Event Hubs?.
Untuk pertimbangan tentang pengorbanan antara ketersediaan dan konsistensi, lihat Ketersediaan dan konsistensi di Event Hubs.