Panduan pemartisian data
Dalam banyak solusi skala besar, data dibagi menjadi partisi yang dapat dikelola dan diakses secara terpisah. Partisi dapat meningkatkan skalabilitas, mengurangi ketidakcocokan, dan mengoptimalkan performa. Partisi juga dapat memberikan mekanisme untuk pembagian data menurut pola penggunaan. Misalnya, Anda dapat mengarsipkan data yang lebih lama dalam penyimpanan data yang lebih murah.
Namun, strategi partisi harus dipilih dengan hati-hati untuk memaksimalkan manfaat sekaligus meminimalkan efek buruk.
Nota
Dalam artikel ini, istilah pemartisian berarti proses pembagian data secara fisik menjadi penyimpanan data terpisah. Ini tidak sama dengan partisi tabel SQL Server.
Mengapa data partisi?
Meningkatkan skalabilitas. Ketika Anda meningkatkan sistem database tunggal, pada akhirnya akan mencapai batas perangkat keras fisik. Jika Anda membagi data di beberapa partisi, setiap yang dihosting di server terpisah, Anda dapat menskalakan sistem hampir tanpa batas waktu.
Meningkatkan performa. Operasi akses data pada setiap partisi terjadi melalui volume data yang lebih kecil. Dengan benar dilakukan, pemartisian dapat membuat sistem Anda lebih efisien. Operasi yang memengaruhi lebih dari satu partisi dapat berjalan secara paralel.
Meningkatkan keamanan. Dalam beberapa kasus, Anda dapat memisahkan data sensitif dan tidak sensitif ke dalam partisi yang berbeda dan menerapkan kontrol keamanan yang berbeda ke data sensitif.
Memberikan fleksibilitas operasional. Pemartisian menawarkan banyak peluang untuk menyempurnakan operasi, memaksimalkan efisiensi administratif, dan meminimalkan biaya. Misalnya, Anda dapat menentukan strategi yang berbeda untuk manajemen, pemantauan, pencadangan dan pemulihan, dan tugas administratif lainnya berdasarkan pentingnya data di setiap partisi.
Cocokkan penyimpanan data dengan pola penggunaan. Pemartisian memungkinkan setiap partisi disebarkan pada jenis penyimpanan data yang berbeda, berdasarkan biaya dan fitur bawaan yang ditawarkan penyimpanan data. Misalnya, data biner besar dapat disimpan dalam penyimpanan blob, sementara data yang lebih terstruktur dapat disimpan dalam database dokumen. Untuk informasi selengkapnya, lihat Memilih penyimpanan data yang tepat.
Meningkatkan ketersediaan. Memisahkan data di beberapa server menghindari satu titik kegagalan. Jika satu instans gagal, hanya data dalam partisi tersebut yang tidak tersedia. Operasi pada partisi lain dapat dilanjutkan. Untuk penyimpanan data platform as a service (PaaS) terkelola, pertimbangan ini kurang relevan, karena layanan ini dirancang dengan redundansi bawaan.
Merancang partisi
Ada tiga strategi umum untuk mempartisi data:
Pemartisian horizontal (sering disebut sharding). Dalam strategi ini, setiap partisi adalah penyimpanan data terpisah, tetapi semua partisi memiliki skema yang sama. Setiap partisi dikenal sebagai shard dan menyimpan subset data tertentu, seperti semua pesanan untuk sekumpulan pelanggan tertentu.
Pemartisian vertikal. Dalam strategi ini, setiap partisi menyimpan subset bidang untuk item di penyimpanan data. Bidang dibagi sesuai dengan pola penggunaannya. Misalnya, bidang yang sering diakses mungkin ditempatkan dalam satu partisi vertikal dan bidang yang kurang sering diakses di bidang lain.
Pemartisian fungsi. Dalam strategi ini, data dikumpulkan sesuai dengan cara data digunakan oleh setiap konteks terikat dalam sistem. Misalnya, sistem e-niaga mungkin menyimpan data faktur dalam satu partisi dan data inventori produk di yang lain.
Strategi ini dapat digabungkan, dan kami sarankan Anda mempertimbangkan semuanya ketika Anda merancang skema partisi. Misalnya, Anda dapat membagi data menjadi pecahan lalu menggunakan partisi vertikal untuk membagi data lebih lanjut di setiap shard.
Pemartisian horizontal (sharding)
Gambar 1 memperlihatkan pemartisian horizontal atau sharding. Dalam contoh ini, data inventaris produk dibagi menjadi pecahan berdasarkan kunci produk. Setiap shard menyimpan data untuk rentang kunci shard yang berdampingan (A-G dan H-Z), diatur menurut abjad. Sharding menyebarkan beban ke lebih banyak komputer, yang mengurangi ketidakcocokan dan meningkatkan performa.
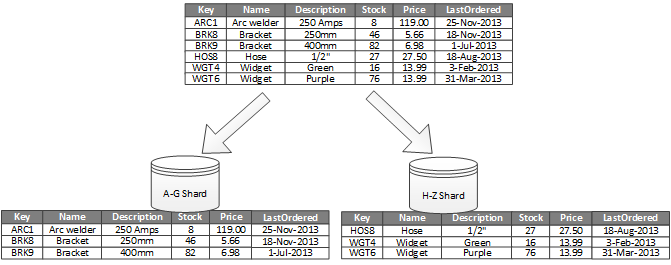
Gambar 1 - Mempartisi data (sharding) secara horizontal berdasarkan kunci partisi.
Faktor terpenting adalah pilihan kunci sharding. Mungkin sulit untuk mengubah kunci setelah sistem beroperasi. Kunci harus memastikan bahwa data dipartisi untuk menyebarkan beban kerja semaksimal mungkin di seluruh pecahan.
Pecahan tidak harus berukuran sama. Lebih penting untuk menyeimbangkan jumlah permintaan. Beberapa pecahan mungkin sangat besar, tetapi setiap item memiliki jumlah operasi akses yang rendah. Pecahan lain mungkin lebih kecil, tetapi setiap item diakses jauh lebih sering. Penting juga untuk memastikan bahwa satu shard tidak melebihi batas skala (dalam hal kapasitas dan sumber daya pemrosesan) penyimpanan data.
Hindari membuat partisi "panas" yang dapat memengaruhi performa dan ketersediaan. Misalnya, menggunakan huruf pertama nama pelanggan menyebabkan distribusi yang tidak seimbang, karena beberapa huruf lebih umum. Sebagai gantinya, gunakan hash pengidentifikasi pelanggan untuk mendistribusikan data secara lebih merata di seluruh partisi.
Pilih kunci sharding yang meminimalkan persyaratan di masa depan untuk membagi pecahan besar, menyatukan pecahan kecil menjadi partisi yang lebih besar, atau mengubah skema. Operasi ini bisa sangat memakan waktu, dan mungkin perlu mengambil satu atau beberapa pecahan offline saat dilakukan.
Jika pecahan direplikasi, mungkin untuk menjaga beberapa replika tetap online saat yang lain dibagi, digabungkan, atau dikonfigurasi ulang. Namun, sistem mungkin perlu membatasi operasi yang dapat dilakukan selama konfigurasi ulang. Misalnya, data dalam replika mungkin ditandai sebagai baca-saja untuk mencegah inkonsistensi data.
Untuk informasi selengkapnya tentang pemartisian horizontal, lihat Pola sharding.
Pemartisian vertikal
Penggunaan yang paling umum untuk partisi vertikal adalah mengurangi I/O dan biaya performa yang terkait dengan pengambilan item yang sering diakses. Gambar 2 menunjukkan contoh pemartisian vertikal. Dalam contoh ini, properti item yang berbeda disimpan dalam partisi yang berbeda. Satu partisi menyimpan data yang diakses lebih sering, termasuk nama produk, deskripsi, dan harga. Partisi lain menyimpan data inventori: jumlah stok dan tanggal pesanan terakhir.
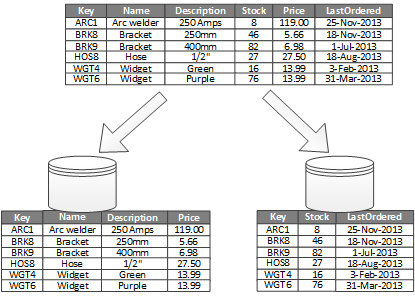
Gambar 2 - Mempartisi data secara vertikal dengan pola penggunaannya.
Dalam contoh ini, aplikasi secara teratur mengkueri nama produk, deskripsi, dan harga saat menampilkan detail produk kepada pelanggan. Jumlah stok dan tanggal terakhir yang dipesan disimpan dalam partisi terpisah karena kedua item ini biasanya digunakan bersama-sama.
Keuntungan lain dari pemartisian vertikal:
Data yang bergerak relatif lambat (nama produk, deskripsi, dan harga) dapat dipisahkan dari data yang lebih dinamis (tingkat stok dan tanggal pesanan terakhir). Data yang bergerak lambat adalah kandidat yang baik bagi aplikasi untuk di-cache dalam memori.
Data sensitif dapat disimpan dalam partisi terpisah dengan kontrol keamanan tambahan.
Pemartisian vertikal dapat mengurangi jumlah akses bersamaan yang diperlukan.
Pemartisian vertikal beroperasi di tingkat entitas dalam penyimpanan data, sebagian menormalkan entitas untuk memecahnya dari item lebar ke sekumpulan item sempit . Ini sangat cocok untuk penyimpanan data berorientasi kolom seperti HBase dan Cassandra. Jika data dalam kumpulan kolom tidak mungkin berubah, Anda juga dapat mempertimbangkan untuk menggunakan penyimpanan kolom di SQL Server.
Pemartisian fungsional
Ketika dimungkinkan untuk mengidentifikasi konteks terikat untuk setiap area bisnis yang berbeda dalam aplikasi, pemartisian fungsional adalah cara untuk meningkatkan isolasi dan performa akses data. Penggunaan umum lainnya untuk pemartisian fungsi adalah memisahkan data baca-tulis dari data baca-saja. Gambar 3 menunjukkan gambaran umum pemartisian fungsional di mana data inventori dipisahkan dari data pelanggan.
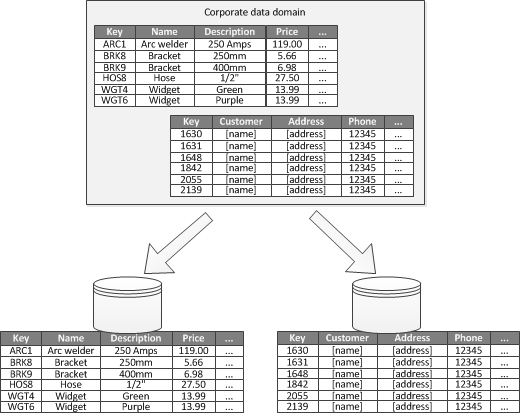
Gambar 3 - Mempartisi data secara fungsional berdasarkan konteks atau subdomain terikat.
Strategi partisi ini dapat membantu mengurangi ketidakcocokan akses data di berbagai bagian sistem.
Merancang partisi untuk skalabilitas
Sangat penting untuk mempertimbangkan ukuran dan beban kerja untuk setiap partisi dan menyeimbangkannya sehingga data didistribusikan untuk mencapai skalabilitas maksimum. Namun, Anda juga harus mempartisi data sehingga tidak melebihi batas penskalaan penyimpanan partisi tunggal.
Ikuti langkah-langkah ini saat merancang partisi untuk skalabilitas:
- Analisis aplikasi untuk memahami pola akses data, seperti ukuran tataan hasil yang dikembalikan oleh setiap kueri, frekuensi akses, latensi yang melekat, dan persyaratan pemrosesan komputasi sisi server. Dalam banyak kasus, beberapa entitas utama akan menuntut sebagian besar sumber daya pemrosesan.
- Gunakan analisis ini untuk menentukan target skalabilitas saat ini dan di masa mendatang, seperti ukuran data dan beban kerja. Kemudian distribusikan data di seluruh partisi untuk memenuhi target skalabilitas. Untuk pemartisian horizontal, memilih kunci shard yang tepat penting untuk memastikan distribusi merata. Untuk informasi selengkapnya, lihat pola sharding.
- Pastikan setiap partisi memiliki sumber daya yang cukup untuk menangani persyaratan skalabilitas, dalam hal ukuran dan throughput data. Bergantung pada penyimpanan data, mungkin ada batasan jumlah ruang penyimpanan, daya pemrosesan, atau bandwidth jaringan per partisi. Jika persyaratan cenderung melebihi batas ini, Anda mungkin perlu menyempurnakan strategi partisi Anda atau membagi data lebih lanjut, mungkin menggabungkan dua strategi atau lebih.
- Pantau sistem untuk memverifikasi bahwa data didistribusikan seperti yang diharapkan dan bahwa partisi dapat menangani beban. Penggunaan aktual tidak selalu cocok dengan apa yang diprediksi analisis. Jika demikian, mungkin untuk menyeimbangkan ulang partisi, atau mendesain ulang beberapa bagian sistem untuk mendapatkan keseimbangan yang diperlukan.
Beberapa lingkungan cloud mengalokasikan sumber daya dalam hal batas infrastruktur. Pastikan bahwa batas batas yang Anda pilih memberikan ruang yang cukup untuk setiap pertumbuhan yang diantisipasi dalam volume data, dalam hal penyimpanan data, daya pemrosesan, dan bandwidth.
Misalnya, jika Anda menggunakan penyimpanan tabel Azure, ada batasan volume permintaan yang dapat ditangani oleh satu partisi dalam periode waktu tertentu. (Untuk informasi selengkapnya, lihat Skalabilitas penyimpanan Azure dan target performa.) Pecahan yang sibuk mungkin memerlukan lebih banyak sumber daya daripada yang dapat ditangani partisi tunggal. Jika demikian, pecahan mungkin perlu dipartisi ulang untuk menyebarkan beban. Jika ukuran total atau throughput tabel ini melebihi kapasitas akun penyimpanan, Anda mungkin perlu membuat akun penyimpanan tambahan dan menyebarkan tabel di seluruh akun ini.
Merancang partisi untuk performa kueri
Performa kueri sering kali dapat ditingkatkan dengan menggunakan himpunan data yang lebih kecil dan dengan menjalankan kueri paralel. Setiap partisi harus berisi proporsi kecil dari seluruh himpunan data. Pengurangan volume ini dapat meningkatkan performa kueri. Namun, pemartisian bukanlah alternatif untuk merancang dan mengonfigurasi database dengan tepat. Misalnya, pastikan Anda memiliki indeks yang diperlukan.
Ikuti langkah-langkah ini saat merancang partisi untuk performa kueri:
Periksa persyaratan dan performa aplikasi:
- Gunakan persyaratan bisnis untuk menentukan kueri penting yang harus selalu berkinerja cepat.
- Pantau sistem untuk mengidentifikasi kueri apa pun yang berkinerja lambat.
- Temukan kueri mana yang paling sering dilakukan. Bahkan jika satu kueri memiliki biaya minimal, konsumsi sumber daya kumulatif bisa signifikan.
Partisi data yang menyebabkan performa lambat:
- Batasi ukuran setiap partisi sehingga waktu respons kueri berada dalam target.
- Jika Anda menggunakan partisi horizontal, rancang kunci shard sehingga aplikasi dapat dengan mudah memilih partisi yang tepat. Ini mencegah kueri harus memindai melalui setiap partisi.
- Pertimbangkan lokasi partisi. Jika memungkinkan, cobalah untuk menyimpan data dalam partisi yang secara geografis dekat dengan aplikasi dan pengguna yang mengaksesnya.
Jika entitas memiliki persyaratan performa throughput dan kueri, gunakan pemartisian fungsional berdasarkan entitas tersebut. Jika ini masih tidak memenuhi persyaratan, terapkan pemartisian horizontal juga. Dalam kebanyakan kasus, strategi partisi tunggal akan cukup, tetapi dalam beberapa kasus lebih efisien untuk menggabungkan kedua strategi.
Pertimbangkan untuk menjalankan kueri secara paralel di seluruh partisi untuk meningkatkan performa.
Merancang partisi untuk ketersediaan
Pemartisian data dapat meningkatkan ketersediaan aplikasi dengan memastikan bahwa seluruh himpunan data tidak merupakan satu titik kegagalan dan bahwa subset individual himpunan data dapat dikelola secara independen.
Pertimbangkan faktor-faktor berikut yang memengaruhi ketersediaan:
Seberapa penting data untuk operasi bisnis. Identifikasi data mana yang merupakan informasi bisnis penting, seperti transaksi, dan data mana yang kurang penting data operasionalnya, seperti file log.
Pertimbangkan untuk menyimpan data penting dalam partisi yang sangat tersedia dengan rencana pencadangan yang sesuai.
Tetapkan prosedur manajemen dan pemantauan terpisah untuk himpunan data yang berbeda.
Tempatkan data yang memiliki tingkat kekritisan yang sama dalam partisi yang sama sehingga dapat dicadangkan bersama pada frekuensi yang sesuai. Misalnya, partisi yang menyimpan data transaksi mungkin perlu dicadangkan lebih sering daripada partisi yang menyimpan informasi pengelogan atau pelacakan.
Bagaimana partisi individual dapat dikelola. Merancang partisi untuk mendukung manajemen dan pemeliharaan independen memberikan beberapa keuntungan. Contohnya:
Jika partisi gagal, partisi dapat dipulihkan secara independen tanpa aplikasi yang mengakses data di partisi lain.
Pemartisian data berdasarkan area geografis memungkinkan tugas pemeliharaan terjadwal terjadi pada jam di luar jam sibuk untuk setiap lokasi. Pastikan bahwa partisi tidak terlalu besar untuk mencegah pemeliharaan terencana selesai selama periode ini.
Apakah akan mereplikasi data penting di seluruh partisi. Strategi ini dapat meningkatkan ketersediaan dan performa, tetapi juga dapat memperkenalkan masalah konsistensi. Dibutuhkan waktu untuk menyinkronkan perubahan dengan setiap replika. Selama periode ini, partisi yang berbeda akan berisi nilai data yang berbeda.
Pertimbangan desain aplikasi
Pemartisian menambah kompleksitas pada desain dan pengembangan sistem Anda. Pertimbangkan pemartisian sebagai bagian mendasar dari desain sistem meskipun sistem awalnya hanya berisi satu partisi. Jika Anda mengatasi partisi sebagai setelahnya, itu akan lebih menantang karena Anda sudah memiliki sistem langsung untuk dipertahankan:
- Logika akses data perlu dimodifikasi.
- Sejumlah besar data yang ada mungkin perlu dimigrasikan, untuk mendistribusikannya di seluruh partisi.
- Pengguna berharap dapat terus menggunakan sistem selama migrasi.
Dalam beberapa kasus, pemartisian tidak dianggap penting karena himpunan data awal kecil dan dapat dengan mudah ditangani oleh satu server. Ini mungkin berlaku untuk beberapa beban kerja, tetapi banyak sistem komersial perlu diperluas saat jumlah pengguna meningkat.
Selain itu, tidak hanya penyimpanan data besar yang mendapat manfaat dari partisi. Misalnya, penyimpanan data kecil mungkin sangat diakses oleh ratusan klien bersamaan. Mempartisi data dalam situasi ini dapat membantu mengurangi ketidakcocokan dan meningkatkan throughput.
Pertimbangkan poin-poin berikut saat Anda merancang skema pemartisian data:
Minimalkan operasi akses data lintas partisi. Jika memungkinkan, simpan data untuk operasi database yang paling umum bersama-sama di setiap partisi untuk meminimalkan operasi akses data lintas partisi. Mengkueri di seluruh partisi bisa lebih memakan waktu daripada mengkueri dalam satu partisi, tetapi mengoptimalkan partisi untuk satu set kueri mungkin berdampak buruk pada kumpulan kueri lainnya. Jika Anda harus mengkueri di seluruh partisi, minimalkan waktu kueri dengan menjalankan kueri paralel dan menggabungkan hasil dalam aplikasi. (Pendekatan ini mungkin tidak dimungkinkan dalam beberapa kasus, seperti ketika hasil dari satu kueri digunakan dalam kueri berikutnya.)
Pertimbangkan untuk mereplikasi data referensi statis. Jika kueri menggunakan data referensi yang relatif statis, seperti tabel kode pos atau daftar produk, pertimbangkan untuk mereplikasi data ini di semua partisi untuk mengurangi operasi pencarian terpisah di partisi yang berbeda. Pendekatan ini juga dapat mengurangi kemungkinan data referensi menjadi himpunan data "panas", dengan lalu lintas yang padat dari seluruh sistem. Namun, ada biaya tambahan yang terkait dengan sinkronisasi perubahan apa pun pada data referensi.
Minimalkan gabungan lintas partisi. Jika memungkinkan, minimalkan persyaratan untuk integritas referensial di seluruh partisi vertikal dan fungsional. Dalam skema ini, aplikasi bertanggung jawab untuk mempertahankan integritas referensial di seluruh partisi. Kueri yang menggabungkan data di beberapa partisi tidak efisien karena aplikasi biasanya perlu melakukan kueri berturut-turut berdasarkan kunci dan kemudian kunci asing. Sebagai gantinya, pertimbangkan untuk mereplikasi atau mendenormalisasi data yang relevan. Jika gabungan lintas partisi diperlukan, jalankan kueri paralel melalui partisi dan gabungkan data dalam aplikasi.
Merangkul konsistensi akhir. Mengevaluasi apakah konsistensi yang kuat sebenarnya merupakan persyaratan. Pendekatan umum dalam sistem terdistribusi adalah menerapkan konsistensi akhir. Data di setiap partisi diperbarui secara terpisah, dan logika aplikasi memastikan bahwa semua pembaruan berhasil diselesaikan. Ini juga menangani inkonsistensi yang dapat muncul dari kueri data saat operasi yang akhirnya konsisten berjalan.
Pertimbangkan bagaimana kueri menemukan partisi yang benar. Jika kueri harus memindai semua partisi untuk menemukan data yang diperlukan, ada dampak signifikan pada performa, bahkan ketika beberapa kueri paralel berjalan. Dengan pemartisian vertikal dan fungsi, kueri dapat menentukan partisi secara alami. Pemartisian horizontal, di sisi lain, dapat membuat menemukan item menjadi sulit, karena setiap pecahan memiliki skema yang sama. Solusi umum untuk mempertahankan peta yang digunakan untuk mencari lokasi shard untuk item tertentu. Peta ini dapat diimplementasikan dalam logika sharding aplikasi, atau dikelola oleh penyimpanan data jika mendukung sharding transparan.
Pertimbangkan untuk menyeimbangkan ulang pecahan secara berkala. Dengan pemartisian horizontal, menyeimbangkan ulang pecahan dapat membantu mendistribusikan data secara merata berdasarkan ukuran dan berdasarkan beban kerja untuk meminimalkan hotspot, memaksimalkan performa kueri, dan mengatasi keterbatasan penyimpanan fisik. Namun, ini adalah tugas kompleks yang sering memerlukan penggunaan alat atau proses kustom.
Mereplikasi partisi. Jika Anda mereplikasi setiap partisi, itu memberikan perlindungan tambahan terhadap kegagalan. Jika satu replika gagal, kueri dapat diarahkan ke salinan yang berfungsi.
Jika Anda mencapai batas fisik strategi partisi, Anda mungkin perlu memperluas skalabilitas ke tingkat yang berbeda. Misalnya, jika partisi berada di tingkat database, Anda mungkin perlu menemukan atau mereplikasi partisi dalam beberapa database. Jika partisi sudah berada di tingkat database, dan keterbatasan fisik adalah masalah, itu mungkin berarti Bahwa Anda perlu menemukan atau mereplikasi partisi di beberapa akun hosting.
Hindari transaksi yang mengakses data dalam beberapa partisi. Beberapa penyimpanan data menerapkan konsistensi transaksional dan integritas untuk operasi yang memodifikasi data, tetapi hanya ketika data terletak dalam satu partisi. Jika Anda memerlukan dukungan transaksi di beberapa partisi, Anda mungkin perlu menerapkan ini sebagai bagian dari logika aplikasi Anda karena sebagian besar sistem partisi tidak memberikan dukungan asli.
Semua penyimpanan data memerlukan beberapa manajemen operasional dan aktivitas pemantauan. Tugas dapat berkisar dari memuat data, mencadangkan dan memulihkan data, mengatur ulang data, dan memastikan bahwa sistem berkinerja dengan benar dan efisien.
Pertimbangkan faktor-faktor berikut yang memengaruhi manajemen operasional:
Cara menerapkan tugas manajemen dan operasional yang sesuai saat data dipartisi. Tugas-tugas ini mungkin mencakup pencadangan dan pemulihan, pengarsipan data, pemantauan sistem, dan tugas administratif lainnya. Misalnya, mempertahankan konsistensi logis selama operasi pencadangan dan pemulihan dapat menjadi tantangan.
Cara memuat data ke dalam beberapa partisi dan menambahkan data baru yang tiba dari sumber lain. Beberapa alat dan utilitas mungkin tidak mendukung operasi data pecahan seperti memuat data ke dalam partisi yang benar.
Cara mengarsipkan dan menghapus data secara teratur. Untuk mencegah pertumbuhan partisi yang berlebihan, Anda perlu mengarsipkan dan menghapus data secara teratur (seperti bulanan). Mungkin perlu mengubah data agar sesuai dengan skema arsip yang berbeda.
Cara menemukan masalah integritas data. Pertimbangkan untuk menjalankan proses berkala untuk menemukan masalah integritas data apa pun, seperti data dalam satu partisi yang mereferensikan informasi yang hilang di partisi lain. Proses ini dapat mencoba memperbaiki masalah ini secara otomatis atau menghasilkan laporan untuk peninjauan manual.
Menyeimbangkan ulang partisi
Saat sistem matang, Anda mungkin harus menyesuaikan skema partisi. Misalnya, partisi individu mungkin mulai mendapatkan volume lalu lintas yang tidak proporsional dan menjadi panas, yang menyebabkan ketidakcocokan yang berlebihan. Atau Anda mungkin telah meremehkan volume data di beberapa partisi, menyebabkan beberapa partisi mendekati batas kapasitas.
Beberapa penyimpanan data, seperti Azure Cosmos DB, dapat menyeimbangkan kembali partisi secara otomatis. Dalam kasus lain, penyeimbangan ulang adalah tugas administratif yang terdiri dari dua tahap:
Tentukan strategi partisi baru.
- Partisi mana yang perlu dipisahkan (atau mungkin digabungkan)?
- Apa itu kunci partisi baru?
Migrasikan data dari skema partisi lama ke set partisi baru.
Bergantung pada penyimpanan data, Anda mungkin dapat memigrasikan data antar partisi saat digunakan. Ini disebut migrasi online. Jika itu tidak memungkinkan, Anda mungkin perlu membuat partisi tidak tersedia saat data direlokasi (migrasi offline).
Migrasi offline
Migrasi offline biasanya lebih sederhana karena mengurangi kemungkinan ketidakcocokan yang terjadi. Secara konseptual, migrasi offline berfungsi sebagai berikut:
- Tandai partisi offline.
- Pisahkan-gabungkan dan pindahkan data ke partisi baru.
- Memverifikasi data.
- Bawa partisi baru online.
- Hapus partisi lama.
Secara opsional, Anda dapat menandai partisi sebagai baca-saja di langkah 1, sehingga aplikasi masih dapat membaca data saat sedang dipindahkan.
Migrasi online
Migrasi online lebih kompleks untuk dilakukan tetapi kurang mengganggu. Proses ini mirip dengan migrasi offline, kecuali partisi asli tidak ditandai offline. Tergantung pada granularitas proses migrasi (misalnya, item berdasarkan item versus pecahan menurut shard), kode akses data dalam aplikasi klien mungkin harus menangani membaca dan menulis data yang disimpan di dua lokasi, partisi asli dan partisi baru.
Langkah selanjutnya
- Pelajari tentang strategi pemartisian untuk layanan Azure tertentu. Untuk informasi selengkapnya, lihat Strategi pemartisian data.
- Skalabilitas penyimpanan Azure dan target performa
Sumber daya terkait
Pola desain berikut mungkin relevan dengan skenario Anda:
Pola sharding menjelaskan beberapa strategi umum untuk memecah data.
Pola tabel indeks memperlihatkan cara membuat indeks sekunder melalui data. Aplikasi dapat dengan cepat mengambil data dengan pendekatan ini, dengan menggunakan kueri yang tidak mereferensikan kunci utama koleksi.
Pola tampilan materialisasi menjelaskan cara menghasilkan tampilan yang telah diisi sebelumnya yang meringkas data untuk mendukung operasi kueri cepat. Pendekatan ini dapat berguna dalam penyimpanan data yang dipartisi jika partisi yang berisi data yang diringkas didistribusikan di beberapa situs.