Database non-relasional adalah database yang tidak menggunakan skema tabular baris dan kolom yang ditemukan di sebagian besar sistem database tradisional. Sebaliknya, database non-relasional menggunakan model penyimpanan yang dioptimalkan untuk persyaratan spesifik dari jenis data yang disimpan. Misalnya, data dapat disimpan sebagai pasangan kunci/nilai sederhana, seperti dokumen JSON, atau sebagai grafik yang terdiri dari tepi dan simpul.
Hal yang sama dari semua penyimpanan data ini adalah bahwa penyimpanan data ini tidak menggunakan model relasional. Penyimpanan data ini juga cenderung lebih spesifik dalam jenis data yang didukung dan cara data dapat dikuerikan. Misalnya, penyimpanan data deret waktu dioptimalkan untuk kueri melalui urutan data berbasis waktu. Namun, penyimpanan data grafik dioptimalkan untuk mengeksplorasi hubungan tertimbang antara entitas. Tidak ada format yang akan menggeneralisasi dengan baik untuk tugas pengelolaan data transaksional.
Istilah NoSQL mengacu pada penyimpanan data yang tidak menggunakan SQL untuk kueri. Sebaliknya, penyimpanan data menggunakan bahasa pemrograman lain dan konstruksi untuk mengkueri data. Dalam praktiknya, "NoSQL" berarti "database non-relasional," meskipun banyak dari database ini mendukung kueri yang kompatibel dengan SQL. Namun, strategi eksekusi kueri yang mendasar biasanya sangat berbeda dari cara sistem manajemen database relasional tradisional (RDBMS) akan menjalankan kueri SQL yang sama.
Ada variasi dalam implementasi dan spesialisasi database NoSQL, seperti ada variasi dalam kemampuan database relasional. Variasi ini memberi setiap implementasi kekuatan utama mereka sendiri dan dilengkapi dengan kurva pembelajaran dan rekomendasi penggunaan mereka sendiri. Bagian berikut menjelaskan kategori utama database non-relasional atau NoSQL.
Penyimpanan data dokumen
Penyimpanan data dokumen mengelola sekumpulan bidang string bernama dan nilai data objek dalam entitas yang disebut sebagai dokumen. Penyimpanan data ini biasanya menyimpan data dalam bentuk dokumen JSON. Setiap nilai bidang bisa menjadi item skalar, seperti angka, atau elemen majemuk, seperti daftar atau koleksi induk-turunan. Data dalam bidang dokumen dapat dikodekan dengan berbagai cara, termasuk XML, YAML, JSON, JSON biner (BSON), atau bahkan disimpan sebagai teks biasa. Bidang dalam dokumen terpapar sistem manajemen penyimpanan, memungkinkan aplikasi mengkueri dan memfilter data dengan menggunakan nilai di bidang ini.
Biasanya, dokumen berisi keseluruhan data untuk entitas. Item yang membentuk entitas bervariasi tergantung pada aplikasinya. Misalnya, entitas dapat memuat detail mengenai pelanggan, pesanan, atau kombinasi keduanya. Satu dokumen dapat berisi informasi yang akan tersebar di beberapa tabel relasional dalam sistem manajemen database relasional (RDBMS). Penyimpanan dokumen tidak mengharuskan semua dokumen memiliki struktur yang sama. Pendekatan bentuk bebas seperti ini memberikan fleksibilitas yang tinggi. Misalnya, aplikasi dapat menyimpan data yang berbeda dalam dokumen sebagai tanggapan atas perubahan persyaratan bisnis.
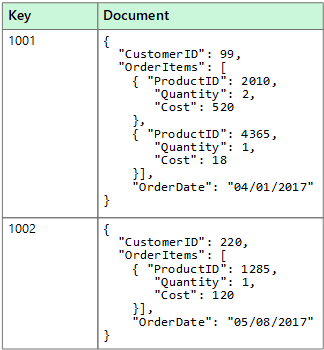
Aplikasi dapat mengambil dokumen dengan menggunakan kunci dokumen. Kunci ini adalah pengenal unik untuk dokumen, yang sering di-hash, untuk membantu mendistribusikan data secara merata. Beberapa database dokumen membuat kunci dokumen secara otomatis. Database lain memungkinkan Anda menyebutkan atribut dokumen untuk digunakan sebagai kunci. Aplikasi juga dapat meminta data dari dokumen berdasarkan nilai satu atau beberapa bidang. Beberapa database dokumen mendukung pengindeksan untuk memfasilitasi pencarian cepat dokumen berdasarkan satu atau beberapa bidang terindeks.
Banyak database dokumen mendukung pembaruan di tempat, memungkinkan aplikasi memodifikasi nilai bidang tertentu dalam dokumen tanpa menulis ulang seluruh dokumen. Operasi baca dan tulis di beberapa bidang dalam satu dokumen biasanya bersifat atomik.
Layanan Azure yang relevan:
Penyimpanan data kolom
Penyimpanan data kolom atau kelompok kolom mengatur data menjadi kolom dan baris. Dalam bentuknya yang paling sederhana, penyimpanan data kelompok kolom dapat terlihat serupa dengan database relasional, setidaknya secara konseptual. Kekuatan sebenarnya dari database kelompok kolom terletak pada pendekatan denormalisasi untuk penataan data jarang, yang berasal dari pendekatan berorientasi kolom untuk menyimpan data.
Anda dapat menganggap penyimpanan data kelompok kolom sebagai menyimpan data tabular dengan baris dan kolom, tetapi kolom dibagi menjadi beberapa kelompok yang dikenal sebagai kelompok kolom. Setiap kelompok kolom menyimpan satu set kolom yang terkait secara logis dan biasanya diambil atau dimanipulasi sebagai satu unit. Data lain yang diakses secara terpisah dapat disimpan dalam kelompok kolom terpisah. Dalam kelompok kolom, kolom baru dapat ditambahkan secara dinamis, dan baris dapat berupa jarang (yaitu, baris tidak perlu memiliki nilai untuk setiap kolom).
Diagram berikut menunjukkan contoh dengan dua kelompok kolom, Identity dan Contact Info. Data untuk satu entitas memiliki kunci baris yang sama di setiap kelompok kolom. Struktur ini, tempat baris untuk setiap objek tertentu dalam kelompok kolom dapat bervariasi secara dinamis, merupakan manfaat penting dari pendekatan kelompok kolom, membuat bentuk penyimpanan data ini sangat cocok untuk menyimpan data dengan berbagai skema.

Tidak seperti penyimpanan kunci/nilai atau database dokumen, sebagian besar database kelompok kolom secara fisik menyimpan data dalam urutan kunci, bukan dengan menghitung hash. Kunci baris dianggap sebagai indeks utama dan memungkinkan akses berbasis kunci melalui kunci tertentu atau berbagai tombol. Beberapa penerapan memungkinkan Anda membuat indeks sekunder di atas kolom tertentu dalam kelompok kolom. Indeks sekunder memungkinkan Anda mengambil data berdasarkan nilai kolom, bukan kunci baris.
Pada disk, semua kolom dalam kelompok kolom disimpan bersama dalam file yang sama, dengan jumlah baris tertentu di setiap file. Dengan himpunan data yang besar, pendekatan ini menciptakan keuntungan performa dengan mengurangi jumlah data yang perlu dibaca dari disk saat hanya beberapa kolom yang dikueri bersama pada satu waktu.
Operasi baca dan tulis untuk baris biasanya atomik dalam satu kelompok kolom, meskipun beberapa penerapan memberikan atomitas di seluruh baris, mencakup beberapa kelompok kolom.
Layanan Azure yang relevan:
Penyimpanan data kunci/nilai
Penyimpanan kunci/nilai pada dasarnya adalah tabel hash besar. Anda mengaitkan setiap nilai data dengan kunci unik, dan penyimpanan kunci/nilai menggunakan kunci ini untuk menyimpan data dengan menggunakan algoritme hash yang sesuai. Algoritme hash dipilih untuk menyediakan distribusi kunci hash yang merata di seluruh penyimpanan data.
Sebagian besar penyimpanan kunci/nilai hanya mendukung kueri sederhana, menyisipkan, dan menghapus operasi. Untuk memodifikasi nilai (baik sebagian atau seluruhnya), aplikasi harus menimpa data yang ada untuk seluruh nilai. Dalam kebanyakan implementasi, membaca atau menulis nilai tunggal adalah operasi atomik. Jika nilainya besar, penulisan dapat memakan waktu.
Aplikasi dapat menyimpan data arbitrer sebagai sekumpulan nilai, meskipun beberapa penyimpanan kunci/nilai memberlakukan batasan pada ukuran nilai maksimum. Nilai yang disimpan tidak terlalu terlihat oleh perangkat lunak sistem penyimpanan. Setiap informasi skema harus disediakan dan ditafsirkan oleh aplikasi. Pada dasarnya, nilai adalah blob dan penyimpanan kunci/nilai hanya mengambil atau menyimpan nilai berdasarkan kunci.
Penyimpanan kunci/nilai sangat dioptimalkan untuk aplikasi yang melakukan pencarian sederhana menggunakan nilai kunci, atau dengan berbagai kunci, tetapi kurang cocok untuk sistem yang perlu mengkueri data di berbagai tabel kunci/nilai, seperti menggabungkan data di beberapa tabel.
Penyimpanan kunci/nilai juga tidak dioptimalkan untuk skenario saat proses kueri atau pemfilteran berdasarkan nilai non-kunci penting, dan tidak melakukan pencarian hanya berdasarkan kunci. Misalnya, dengan database relasional, Anda dapat menemukan rekaman dengan menggunakan klausa WHERE untuk memfilter kolom non-kunci, tetapi penyimpanan kunci/nilai biasanya tidak memiliki jenis kemampuan pencarian untuk nilai, atau jika memiliki kemampuan untuk melakukannya, diperlukan pemindaian lambat dari semua nilai.
Satu penyimpanan kunci/nilai bisa sangat terukur, karena penyimpanan data dapat dengan mudah mendistribusikan data di beberapa node pada mesin terpisah.
Layanan Azure yang relevan:
Penyimpanan data grafik
Penyimpanan data grafik mengelola dua jenis informasi, node, dan tepi. Node mewakili entitas, dan tepi menentukan hubungan antara entitas ini. Baik node dan tepi dapat memiliki properti yang memberikan informasi tentang node atau tepi, serupa dengan kolom dalam tabel. Tepi juga dapat memiliki arah yang menunjukkan sifat hubungan.
Tujuan dari penyimpanan data grafik adalah untuk memungkinkan aplikasi mengkueri yang melintasi jaringan node dan tepi secara efisien, dan untuk menganalisis hubungan antara entitas. Diagram berikut menunjukkan data personalia organisasi yang terstruktur sebagai grafik. Entitas adalah karyawan dan departemen, dan tepi akan menunjukkan hubungan pelaporan dan departemen tempat karyawan bekerja. Dalam grafik ini, arah panah pada tepi menunjukkan arah hubungan.
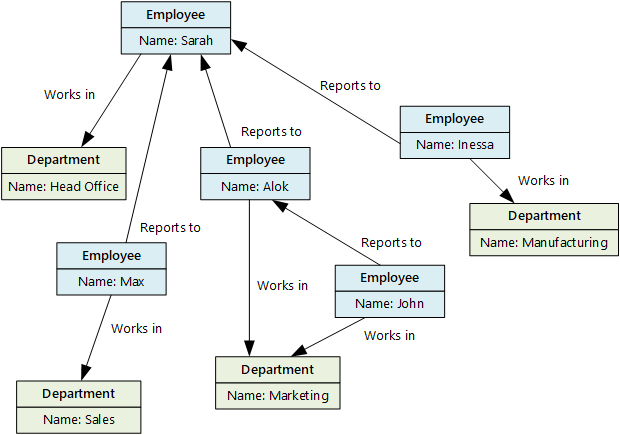
Struktur ini membuatnya mudah untuk melakukan kueri seperti "Temukan semua karyawan yang melapor secara langsung atau tidak langsung kepada Sarah" atau "Siapa yang bekerja di departemen yang sama dengan John?" Untuk grafik besar dengan banyak entitas dan hubungan, Anda dapat melakukan analisis yang kompleks dengan cepat. Banyak database grafik menyediakan bahasa kueri yang dapat Anda gunakan untuk melintasi jaringan hubungan secara efisien.
Layanan Azure yang relevan:
Penyimpanan data deret waktu
Data deret waktu adalah sekumpulan nilai yang diatur oleh waktu, dan penyimpanan data rangkaian waktu dioptimalkan untuk jenis data ini. Penyimpanan data rangkaian waktu harus mendukung jumlah penulisan yang sangat tinggi, karena biasanya mengumpulkan sejumlah besar data secara real time dari sejumlah besar sumber. Penyimpanan data rangkaian waktu dioptimalkan untuk menyimpan data telemetri. Skenario termasuk sensor IoT atau penghitung aplikasi/sistem. Pembaruan jarang terjadi, dan penghapusan sering kali dilakukan sebagai operasi massal.
Meskipun rekaman yang ditulis ke database deret waktu umumnya kecil, sering kali ada sejumlah besar rekaman, dan ukuran data total dapat tumbuh dengan cepat. Penyimpanan data rangkaian waktu juga menangani data rusak dan yang terlambat datang, pengindeksan otomatis poin data rangkaian, dan pengoptimalan untuk kueri yang dijelaskan dalam hal rentang waktu. Fitur terakhir ini memungkinkan kueri berjalan di jutaan titik data dan beberapa aliran data dengan cepat, untuk mendukung visualisasi rangkaian waktu, yang merupakan cara umum data rangkaian waktu dikonsumsi.
Layanan Azure yang relevan:
Penyimpanan data objek
Penyimpanan data objek dioptimalkan untuk menyimpan dan mengambil blob atau objek biner besar seperti gambar, file teks, streaming video dan audio, objek dan dokumen data aplikasi besar, dan gambar disk mesin virtual. Objek terdiri dari data yang disimpan, beberapa metadata, dan ID unik untuk mengakses objek. Penyimpanan objek dirancang untuk mendukung file yang secara individual sangat besar, serta menyediakan penyimpanan total dalam jumlah besar untuk mengelola semua file.
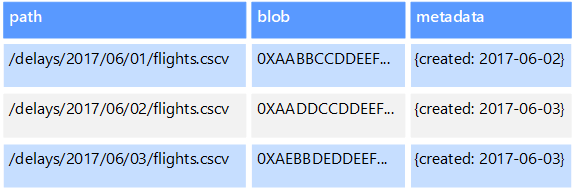
Beberapa penyimpanan data objek mereplikasi blob yang diberikan di beberapa node kluster, yang memungkinkan pembacaan paralel yang cepat. Proses ini, pada gilirannya, memungkinkan pengkuerian peluasan skala data yang ada dalam file besar, karena beberapa proses, biasanya berjalan di server yang berbeda, masing-masing dapat mengkueri file data besar secara bersamaan.
Salah satu kasus khusus penyimpanan data objek adalah berbagi file jaringan. Menggunakan berbagi file memungkinkan file diakses di seluruh jaringan menggunakan protokol jaringan standar seperti blok pesan server (SMB). Dengan adanya keamanan yang tepat dan mekanisme kontrol akses bersamaan, berbagi data dengan cara ini dapat memungkinkan layanan terdistribusi menyediakan akses data yang dapat diskalakan untuk operasi dasar tingkat rendah seperti permintaan baca dan tulis sederhana.
Layanan Azure yang relevan:
Penyimpanan data indeks eksternal
Penyimpanan data indeks eksternal menyediakan kemampuan untuk mencari informasi yang disimpan di penyimpanan dan layanan data lainnya. Indeks eksternal bertindak sebagai indeks sekunder untuk penyimpanan data apa pun, dan dapat digunakan untuk mengindeks volume data yang sangat besar dan menyediakan akses mendekati real-time ke indeks ini.
Misalnya, Anda mungkin memiliki file teks yang disimpan dalam sistem file. Menemukan file dengan jalur filenya cepat, tetapi mencari berdasarkan isi file akan memerlukan pemindaian semua file dan prosesnya lambat. Indeks eksternal memungkinkan Anda membuat indeks pencarian sekunder dan kemudian dengan cepat menemukan jalur ke file yang sesuai dengan kriteria Anda. Contoh lain penerapan indeks eksternal adalah dengan penyimpanan kunci/nilai yang hanya mengindeks berdasarkan kunci. Anda dapat membuat indeks sekunder berdasarkan nilai dalam data, dan dengan cepat mencari kunci yang secara unik mengidentifikasi setiap item yang cocok.
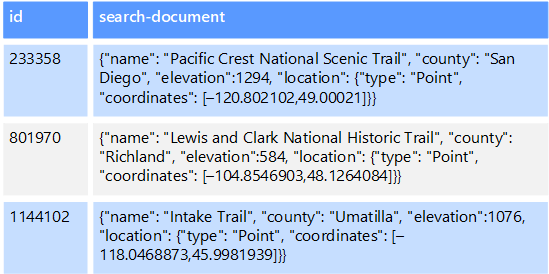
Indeks dibuat dengan menjalankan proses pengindeksan. Ini dapat dilakukan dengan menggunakan model tarik, dipicu oleh penyimpanan data, atau menggunakan model push, yang diawali oleh kode aplikasi. Indeks dapat berupa multidimensi dan dapat mendukung pencarian teks bebas di sejumlah besar data teks.
Penyimpanan data indeks eksternal sering digunakan untuk mendukung teks lengkap dan pencarian berbasis web. Dalam kasus ini, pencarian dapat tepat atau kabur. Pencarian yang kabur akan menemukan dokumen yang cocok dengan serangkaian istilah dan menghitung seberapa dekat kecocokannya. Beberapa indeks eksternal juga mendukung analisis linguistik yang dapat mengembalikan kecocokan berdasarkan sinonim, ekspansi genre (misalnya, mencocokkan "anjing" dengan "hewan peliharaan"), dan bentuk kata (misalnya, mencari "lari" juga cocok dengan "telah lari" dan "berlari").
Layanan Azure yang relevan:
Persyaratan umum
Penyimpanan data non-relasional sering menggunakan arsitektur penyimpanan yang berbeda dari yang digunakan oleh database relasional. Secara khusus, data ini cenderung tidak memiliki skema yang tetap. Data ini juga cenderung tidak mendukung transaksi, atau membatasi cakupan transaksi, dan umumnya tidak mencakup indeks sekunder karena alasan skalabilitas.
Dibandingkan dengan banyak database relasional tradisional, database NoSQL sering menawarkan tingkat fleksibilitas skema dan skalabilitas platform yang diinginkan tetapi terkadang manfaat tersebut dikenakan biaya konsistensi yang lebih lemah. Meskipun Anda dapat menyimpan data Anda secara fleksibel, Anda masih perlu mengidentifikasi dan menganalisis pola akses data Anda, lalu merancang skema data yang sesuai jika tidak database NoSQL Anda dapat menderita di bawah beban kerja berat atau pola penggunaan yang tidak terduga.
Berikut ini adalah perbandingan persyaratan untuk masing-masing penyimpanan data non-relasional:
| Persyaratan | Data dokumen | Data kelompok kolom | Data kunci/nilai | Data grafik |
|---|---|---|---|---|
| Normalisasi kasus | Denormalisasi | Denormalisasi | Denormalisasi | Dinormalisasi |
| Skema | Skema saat dibaca | Kelompok kolom yang didefinisikan pada tulis, skema kolom saat dibaca | Skema saat dibaca | Skema saat dibaca |
| Konsistensi (di seluruh transaksi bersamaan) | Konsistensi yang dapat disetel, jaminan tingkat dokumen | Jaminan tingkat kelompok kolom | Jaminan tingkat kunci | jaminan tingkat grafik |
| Atomisitas (cakupan transaksi) | Koleksi | Tabel | Tabel | Grafik |
| Strategi Penguncian | Optimis (bebas kunci) | Pesimis (penguncian baris) | Optimis (tag entitas (ETag)) | |
| Pola akses | Akses acak | Agregat pada data tinggi/lebar | Akses acak | Akses acak |
| Pengindeksan | Indeks primer dan sekunder | Indeks primer dan sekunder | Indeks primer saja | Indeks primer dan sekunder |
| Bentuk data | Dokumen | Tabular dengan kelompok kolom yang berisi kolom | Kunci dan nilai | Grafik yang berisi tepi dan puncak |
| Sparse | Ya | Ya | Ya | Tidak |
| Lebar (banyak kolom/atribut) | Ya | Ya | No | Tidak |
| Ukuran datum | Kecil (KB) hingga sedang (MB tingkat bawah) | Sedang (MB) ke Besar (GB tingkat bawah) | Kecil (KB) | Kecil (KB) |
| Skala Maksimum Keseluruhan | Sangat Besar (PB) | Sangat Besar (PB) | Sangat Besar (PB) | Besar (TB) |
| Persyaratan | Data rangkaian waktu | Data objek | Data indeks eksternal |
|---|---|---|---|
| Normalisasi kasus | Dinormalisasi | Denormalisasi | Denormalisasi |
| Skema | Skema saat dibaca | Skema saat dibaca | Skema saat menulis |
| Konsistensi (di seluruh transaksi bersamaan) | T/A | T/A | T/A |
| Atomisitas (cakupan transaksi) | T/A | Objek | T/A |
| Strategi Penguncian | T/A | Pesimis (penguncian blob) | T/A |
| Pola akses | Akses dan agregasi acak | Akses sekuensial | Akses acak |
| Pengindeksan | Indeks primer dan sekunder | Indeks primer saja | T/A |
| Bentuk data | Tabular | Blob dan metadata | Dokumen |
| Sparse | No | T/A | No |
| Lebar (banyak kolom/atribut) | Tidak | Ya | Ya |
| Ukuran datum | Kecil (KB) | Besar (GB) hingga Sangat Besar (TB) | Kecil (KB) |
| Skala Maksimum Keseluruhan | Besar (TB tingkat bawah) | Sangat Besar (PB) | Besar (TB tingkat bawah) |
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Zoiner Tejada | CEO dan Arsitek
Langkah berikutnya
- Data Relasional vs. NoSQL
- Memahami database NoSQL terdistribusi
- Dasar-Dasar Data Microsoft Azure: Menjelajahi data non-relasional di Azure
- Menerapkan model data non-relasional