Azure Virtual Desktop adalah layanan virtualisasi desktop dan aplikasi yang komprehensif yang berjalan di Microsoft Azure. Virtual Desktop membantu mengaktifkan pengalaman desktop jarak jauh yang aman yang membantu organisasi memperkuat ketahanan bisnis. Ini memberikan manajemen yang disederhanakan, multi-sesi Windows 10 dan 11 Enterprise, dan pengoptimalan untuk Aplikasi Microsoft 365 untuk perusahaan. Dengan Virtual Desktop, Anda dapat menyebarkan dan menskalakan desktop dan aplikasi Windows di Azure dalam hitung menit, menyediakan fitur keamanan dan kepatuhan terintegrasi untuk membantu menjaga aplikasi dan data Anda tetap aman.
Saat Anda terus mengaktifkan pekerjaan jarak jauh untuk organisasi Anda dengan Virtual Desktop, penting untuk memahami kemampuan pemulihan bencana (DR) dan praktik terbaiknya. Praktik ini memperkuat keandalan di seluruh wilayah untuk membantu menjaga keamanan data dan karyawan tetap produktif. Artikel ini memberi Anda pertimbangan tentang prasyarat kelangsungan bisnis dan pemulihan bencana (BCDR), langkah-langkah penyebaran, dan praktik terbaik. Anda mempelajari tentang opsi, strategi, dan panduan arsitektur. Konten dalam dokumen ini memungkinkan Anda menyiapkan paket BCDR yang sukses dan dapat membantu Anda menghadirkan lebih banyak ketahanan bagi bisnis Anda selama peristiwa waktu henti yang direncanakan dan tidak direncanakan.
Ada beberapa jenis bencana dan pemadaman, dan masing-masing dapat memiliki dampak yang berbeda. Ketahanan dan pemulihan dibahas secara mendalam untuk peristiwa lokal dan di seluruh wilayah, termasuk pemulihan layanan di wilayah Azure jarak jauh yang berbeda. Jenis pemulihan ini disebut pemulihan bencana geografis. Sangat penting untuk membangun arsitektur Virtual Desktop Anda untuk ketahanan dan ketersediaan. Anda harus memberikan ketahanan lokal maksimum untuk mengurangi dampak peristiwa kegagalan. Ketahanan ini juga mengurangi persyaratan untuk menjalankan prosedur pemulihan. Artikel ini juga menyediakan informasi tentang ketersediaan tinggi dan praktik terbaik.
Tujuan dan cakupan
Tujuan dari panduan ini adalah untuk:
- Pastikan ketersediaan maksimum, ketahanan, dan kemampuan pemulihan bencana geografis sekaligus meminimalkan kehilangan data untuk data pengguna penting yang dipilih.
- Minimalkan waktu pemulihan.
Tujuan ini juga dikenal sebagai tujuan titik pemulihan (RPO) dan Tujuan Waktu Pemulihan (RTO).
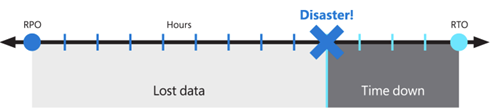
Solusi yang diusulkan memberikan ketersediaan tinggi lokal, perlindungan dari satu kegagalan zona ketersediaan, dan perlindungan dari seluruh kegagalan wilayah Azure. Ini bergantung pada penyebaran redundan di wilayah Azure yang berbeda, atau sekunder untuk memulihkan layanan. Meskipun masih merupakan praktik yang baik, Virtual Desktop dan teknologi yang digunakan untuk membangun BCDR tidak mengharuskan wilayah Azure dipasangkan. Lokasi primer dan sekunder dapat berupa kombinasi wilayah Azure apa pun, jika latensi jaringan mengizinkannya. Mengoperasikan kumpulan host AVD di beberapa wilayah geografis dapat menawarkan lebih banyak manfaat tidak terbatas pada BCDR.
Untuk mengurangi dampak kegagalan zona ketersediaan tunggal, gunakan ketahanan untuk meningkatkan ketersediaan tinggi:
- Pada lapisan komputasi, sebarkan host sesi Virtual Desktop di berbagai zona ketersediaan.
- Pada lapisan penyimpanan, gunakan ketahanan zona jika memungkinkan.
- Di lapisan jaringan, sebarkan Azure ExpressRoute yang tangguh zona dan gateway jaringan privat virtual (VPN).
- Untuk setiap dependensi, tinjau dampak pemadaman zona tunggal dan merencanakan mitigasi. Misalnya, sebarkan Active Directory Domain Controllers dan sumber daya eksternal lainnya yang diakses oleh pengguna Virtual Desktop di beberapa zona ketersediaan.
Bergantung pada jumlah zona ketersediaan yang Anda gunakan, evaluasi provisi berlebihan jumlah host sesi untuk mengimbangi hilangnya satu zona. Misalnya, bahkan dengan zona (n-1) yang tersedia, Anda dapat memastikan pengalaman dan performa pengguna.
Catatan
Zona ketersediaan Azure adalah fitur ketersediaan tinggi yang dapat meningkatkan ketahanan. Namun, jangan anggap mereka sebagai solusi pemulihan bencana yang dapat melindungi dari bencana di seluruh wilayah.

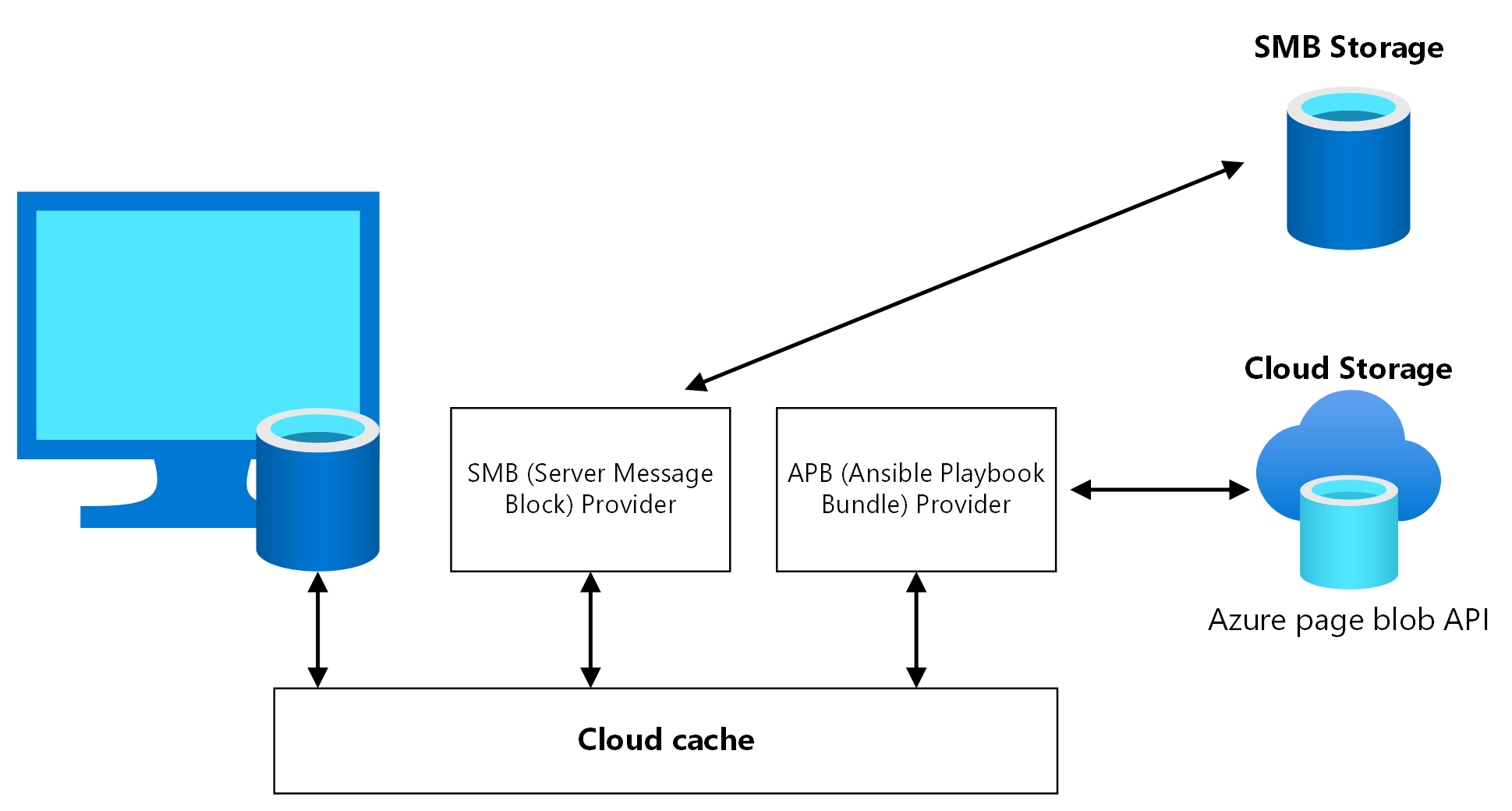
Karena kemungkinan kombinasi jenis, opsi replikasi, kemampuan layanan, dan pembatasan ketersediaan di beberapa wilayah, komponen Cloud Cache dari FSLogix disarankan untuk digunakan alih-alih mekanisme replikasi khusus penyimpanan.
OneDrive tidak tercakup dalam artikel ini. Untuk informasi selengkapnya tentang redundansi dan ketersediaan tinggi, lihat Ketahanan data SharePoint dan OneDrive di Microsoft 365.
Untuk sisa artikel ini, Anda akan mempelajari tentang solusi untuk dua jenis kumpulan host Virtual Desktop yang berbeda. Ada juga pengamatan yang disediakan sehingga Anda dapat membandingkan arsitektur ini dengan solusi lain:
- Pribadi: Dalam jenis kumpulan host ini, pengguna memiliki host sesi yang ditetapkan secara permanen, yang seharusnya tidak pernah berubah. Karena pribadi, VM ini dapat menyimpan data pengguna. Asumsinya adalah menggunakan teknik replikasi dan pencadangan untuk mempertahankan dan melindungi status.
- Dikumpulkan: Pengguna untuk sementara diberi salah satu VM host sesi yang tersedia dari kumpulan, baik secara langsung melalui grup aplikasi desktop atau dengan menggunakan aplikasi jarak jauh. VM adalah data dan profil pengguna dan tanpa status disimpan di penyimpanan eksternal atau OneDrive.
Implikasi biaya dibahas, tetapi tujuan utama adalah memberikan penyebaran pemulihan bencana geografis yang efektif dengan kehilangan data minimal. Untuk detail BCDR selengkapnya, lihat sumber daya berikut ini:
Prasyarat
Sebarkan infrastruktur inti dan pastikan infrastruktur tersebut tersedia di wilayah Azure primer dan sekunder. Untuk panduan tentang topologi jaringan, Anda dapat menggunakan topologi Dan model konektivitas Azure Cloud Adoption Framework Network:
Di kedua model, sebarkan kumpulan host Virtual Desktop utama dan lingkungan pemulihan bencana sekunder di dalam jaringan virtual spoke yang berbeda dan sambungkan ke setiap hub di wilayah yang sama. Tempatkan satu hub di lokasi utama, satu hub di lokasi sekunder, lalu buat konektivitas di antara keduanya.
Hub akhirnya menyediakan konektivitas hibrid ke sumber daya lokal, layanan firewall, sumber daya identitas seperti Pengendali Domain Direktori Aktif, dan sumber daya manajemen seperti Log Analytics.
Anda harus mempertimbangkan aplikasi lini bisnis dan ketersediaan sumber daya dependen saat gagal ke lokasi sekunder.
Kelangsungan bisnis sarana kontrol dan pemulihan bencana
Virtual Desktop menawarkan kelangsungan bisnis dan pemulihan bencana bagi sarana kontrolnya untuk mempertahankan metadata pelanggan selama pemadaman. Platform Azure mengelola data dan proses ini, dan pengguna tidak perlu mengonfigurasi atau menjalankan apa pun.

Virtual Desktop dirancang untuk tahan terhadap kegagalan komponen individual, dan untuk dapat pulih dari kegagalan dengan cepat. Ketika pemadaman terjadi di suatu wilayah, komponen infrastruktur layanan gagal ke lokasi sekunder dan terus berfungsi seperti biasa. Anda masih dapat mengakses metadata terkait layanan, dan pengguna masih dapat terhubung ke host yang tersedia. Koneksi pengguna akhir tetap online jika lingkungan penyewa atau host tetap dapat diakses. Lokasi data untuk Virtual Desktop berbeda dari lokasi penyebaran komputer virtual (VM) host sesi kumpulan host. Anda dapat menemukan metadata Virtual Desktop di salah satu wilayah yang didukung, lalu menyebarkan VM di lokasi yang berbeda. Detail selengkapnya disediakan dalam artikel arsitektur dan ketahanan layanan Virtual Desktop.
Aktif-Aktif vs. Aktif-Pasif
Jika sekumpulan pengguna yang berbeda memiliki persyaratan BCDR yang berbeda, Microsoft menyarankan agar Anda menggunakan beberapa kumpulan host dengan konfigurasi yang berbeda. Misalnya, pengguna dengan aplikasi misi penting mungkin menetapkan kumpulan host yang sepenuhnya berlebihan dengan kemampuan pemulihan bencana geografis. Namun, pengguna pengembangan dan pengujian dapat menggunakan kumpulan host terpisah tanpa pemulihan bencana sama sekali.
Untuk setiap kumpulan host Virtual Desktop tunggal, Anda dapat mendasarkan strategi BCDR Anda pada model aktif-aktif atau pasif. Skenario ini mengasumsikan bahwa sekumpulan pengguna yang sama di satu lokasi geografis dilayani oleh kumpulan host tertentu.
- Aktif-Aktif
Untuk setiap kumpulan host di wilayah utama, Anda menyebarkan kumpulan host kedua di wilayah sekunder.
Konfigurasi ini menyediakan hampir nol RTO, dan RPO memiliki biaya tambahan.
Anda tidak mengharuskan administrator untuk melakukan intervensi atau failover. Selama operasi normal, kumpulan host sekunder memberi pengguna sumber daya Virtual Desktop.
Setiap kumpulan host memiliki akun penyimpanannya sendiri (setidaknya satu) untuk profil pengguna persisten.
Anda harus mengevaluasi latensi berdasarkan lokasi fisik dan konektivitas pengguna yang tersedia. Untuk beberapa wilayah Azure, seperti Eropa Barat dan Eropa Utara, perbedaannya dapat diabaikan saat mengakses wilayah utama atau sekunder. Anda dapat memvalidasi skenario ini menggunakan alat Azure Virtual Desktop Experience Estimator .
Pengguna ditetapkan ke grup aplikasi yang berbeda, seperti Desktop Application Group (DAG) dan RemoteApp Application Group (RAG), di kumpulan host utama dan sekunder. Dalam hal ini, mereka melihat entri duplikat di umpan klien Virtual Desktop mereka. Untuk menghindari kebingungan, gunakan ruang kerja Virtual Desktop terpisah dengan nama dan label yang jelas yang mencerminkan tujuan setiap sumber daya. Beri tahu pengguna Anda tentang penggunaan sumber daya ini.
Jika Anda memerlukan penyimpanan untuk mengelola Profil FSLogix dan kontainer ODFC secara terpisah, gunakan Cloud Cache untuk memastikan hampir nol RPO.
- Untuk menghindari konflik profil, jangan izinkan pengguna mengakses kedua kumpulan host secara bersamaan.
- Karena sifat aktif-aktif dari skenario ini, Anda harus mendidik pengguna Anda tentang cara menggunakan sumber daya ini dengan cara yang tepat.
Catatan
Menggunakan kontainer ODFC terpisah adalah skenario tingkat lanjut dengan kompleksitas yang lebih tinggi. Menyebarkan cara ini disarankan hanya dalam beberapa skenario tertentu.
- Aktif-Pasif
- Seperti aktif-aktif, untuk setiap kumpulan host di wilayah utama, Anda menyebarkan kumpulan host kedua di wilayah sekunder.
- Jumlah sumber daya komputasi yang aktif di wilayah sekunder berkurang dibandingkan dengan wilayah utama, tergantung pada anggaran yang tersedia. Anda dapat menggunakan penskalaan otomatis untuk menyediakan lebih banyak kapasitas komputasi, tetapi membutuhkan lebih banyak waktu, dan kapasitas Azure tidak dijamin.
- Konfigurasi ini menyediakan RTO yang lebih tinggi jika dibandingkan dengan pendekatan aktif-aktif, tetapi lebih murah.
- Anda memerlukan intervensi administrator untuk menjalankan prosedur failover jika ada pemadaman Azure. Kumpulan host sekunder biasanya tidak menyediakan akses pengguna ke sumber daya Virtual Desktop.
- Setiap kumpulan host memiliki akun penyimpanannya sendiri untuk profil pengguna persisten.
- Pengguna yang menggunakan layanan Virtual Desktop dengan latensi dan performa optimal hanya terpengaruh jika ada pemadaman Azure. Anda harus memvalidasi skenario ini dengan menggunakan alat Azure Virtual Desktop Experience Estimator . Performa harus dapat diterima, bahkan jika terdegradasi, untuk lingkungan pemulihan bencana sekunder.
- Pengguna hanya ditetapkan ke satu set grup aplikasi, seperti aplikasi Desktop dan Jarak Jauh. Selama operasi normal, aplikasi ini berada di kumpulan host utama. Selama pemadaman, dan setelah failover, pengguna ditetapkan ke Grup Aplikasi di kumpulan host sekunder. Tidak ada entri duplikat yang ditampilkan di umpan klien Virtual Desktop pengguna, mereka dapat menggunakan ruang kerja yang sama, dan semuanya transparan untuk mereka.
- Jika Anda memerlukan penyimpanan untuk mengelola Profil FSLogix dan kontainer Office, gunakan Cloud Cache untuk memastikan hampir nol RPO.
- Untuk menghindari konflik profil, jangan izinkan pengguna mengakses kedua kumpulan host secara bersamaan. Karena skenario ini aktif-pasif, administrator dapat menerapkan perilaku ini di tingkat grup aplikasi. Hanya setelah prosedur failover adalah pengguna dapat mengakses setiap grup aplikasi di kumpulan host sekunder. Akses dicabut di grup aplikasi kumpulan host utama dan ditetapkan ulang ke grup aplikasi di kumpulan host sekunder.
- Jalankan failover untuk semua grup aplikasi, jika tidak, pengguna yang menggunakan grup aplikasi yang berbeda di kumpulan host yang berbeda dapat menyebabkan konflik profil jika tidak dikelola secara efektif.
- Dimungkinkan untuk memungkinkan subset pengguna tertentu untuk secara selektif melakukan failover ke kumpulan host sekunder dan memberikan perilaku aktif-aktif terbatas dan kemampuan failover pengujian. Dimungkinkan juga untuk mengalihkan grup aplikasi tertentu, tetapi Anda harus mendidik pengguna Anda untuk tidak menggunakan sumber daya dari kumpulan host yang berbeda secara bersamaan.
Untuk keadaan tertentu, Anda dapat membuat satu kumpulan host dengan campuran host sesi yang terletak di berbagai wilayah. Keuntungan dari solusi ini adalah bahwa jika Anda memiliki satu kumpulan host, maka tidak perlu menduplikasi definisi dan penugasan untuk aplikasi desktop dan jarak jauh. Sayangnya, pemulihan bencana untuk kumpulan host bersama memiliki beberapa kelemahan:
- Untuk kumpulan host yang dikumpulkan, tidak dimungkinkan untuk memaksa pengguna ke host sesi di wilayah yang sama.
- Pengguna mungkin mengalami latensi dan performa suboptimal yang lebih tinggi saat menyambungkan ke host sesi di wilayah jarak jauh.
- Jika Anda memerlukan penyimpanan untuk profil pengguna, Anda memerlukan konfigurasi kompleks untuk mengelola penugasan untuk host sesi di wilayah utama dan sekunder.
- Anda dapat menggunakan mode pengurasan untuk menonaktifkan akses sementara ke host sesi yang terletak di wilayah sekunder. Tetapi metode ini memperkenalkan lebih banyak kompleksitas, overhead manajemen, dan penggunaan sumber daya yang tidak efisien.
- Anda dapat mempertahankan host sesi dalam status offline di wilayah sekunder, tetapi memperkenalkan lebih banyak kompleksitas dan overhead manajemen.
Pertimbangan dan rekomendasi
Umum
Untuk menyebarkan konfigurasi aktif-aktif atau aktif-pasif menggunakan beberapa kumpulan host dan mekanisme cache cloud FSLogix, Anda dapat membuat kumpulan host di dalam ruang kerja yang sama atau yang berbeda, tergantung pada model. Pendekatan ini mengharuskan Anda untuk mempertahankan penyelarasan dan pembaruan, menjaga kedua kumpulan host tetap sinkron dan pada tingkat konfigurasi yang sama. Selain kumpulan host baru untuk wilayah pemulihan bencana sekunder, Anda perlu:
- Untuk membuat grup aplikasi baru yang berbeda dan aplikasi terkait untuk kumpulan host baru.
- Untuk mencabut penetapan pengguna ke kumpulan host utama, lalu menetapkan ulang secara manual ke kumpulan host baru selama failover.
Tinjau opsi Kelangsungan bisnis dan pemulihan bencana untuk FSLogix.
- Tidak ada pemulihan profil yang tidak tercakup dalam dokumen ini.
- Cache cloud (aktif/pasif) disertakan dalam dokumen ini tetapi diimplementasikan menggunakan kumpulan host yang sama.
- Cache cloud (aktif/aktif) tercakup dalam bagian yang tersisa dari dokumen ini.
Ada batasan untuk sumber daya Virtual Desktop yang harus dipertimbangkan dalam desain arsitektur Virtual Desktop. Validasi desain Anda berdasarkan batas layanan Virtual Desktop.
Untuk diagnostik dan pemantauan, ada baiknya menggunakan ruang kerja Analitik Log yang sama untuk kumpulan host utama dan sekunder. Dengan menggunakan konfigurasi ini, Azure Virtual Desktop Insights menawarkan tampilan penyebaran terpadu di kedua wilayah.
Namun, menggunakan satu tujuan log dapat menyebabkan masalah jika seluruh wilayah utama tidak tersedia. Wilayah sekunder tidak akan dapat menggunakan ruang kerja Analitik Log di wilayah yang tidak tersedia. Jika situasi ini tidak dapat diterima, solusi berikut dapat diadopsi:
- Gunakan ruang kerja Analitik Log terpisah untuk setiap wilayah, lalu arahkan komponen Virtual Desktop untuk masuk ke ruang kerja lokalnya.
- Uji dan tinjau kemampuan replikasi dan failover ruang kerja Analitik Log.
Compute
Untuk penyebaran kedua kumpulan host di wilayah pemulihan bencana primer dan sekunder, Anda harus menyebarkan armada VM host sesi Anda di beberapa zona ketersediaan. Jika zona ketersediaan tidak tersedia di wilayah lokal, Anda dapat menggunakan set ketersediaan untuk membuat solusi Anda lebih tangguh daripada dengan penyebaran default.
Gambar emas yang Anda gunakan untuk penyebaran kumpulan host di wilayah pemulihan bencana sekunder harus sama dengan yang Anda gunakan untuk primer. Anda harus menyimpan gambar di Azure Compute Gallery dan mengonfigurasi beberapa replika gambar di lokasi utama dan sekunder. Setiap replika gambar dapat mempertahankan penyebaran paralel dari jumlah maksimum VM, dan Anda mungkin memerlukan lebih dari satu berdasarkan ukuran batch penyebaran yang Anda inginkan. Untuk informasi selengkapnya, lihat Menyimpan dan berbagi gambar di Azure Compute Gallery.

Azure Compute Gallery bukan sumber daya global. Disarankan untuk memiliki setidaknya galeri sekunder di wilayah sekunder. Di wilayah utama Anda, buat galeri, definisi gambar VM, dan versi gambar VM. Kemudian, buat objek yang sama juga di wilayah sekunder. Saat membuat versi gambar VM, ada kemungkinan untuk menyalin versi gambar VM yang dibuat di wilayah utama dengan menentukan galeri, definisi gambar VM, dan versi gambar VM yang digunakan di wilayah utama. Azure menyalin gambar dan membuat versi gambar VM lokal. Dimungkinkan untuk menjalankan operasi ini menggunakan perintah portal Azure atau Azure CLI seperti yang diuraikan di bawah ini:
Tidak semua VM host sesi di lokasi pemulihan bencana sekunder harus aktif dan berjalan sepanjang waktu. Anda awalnya harus membuat sejumlah VM yang memadai, dan setelah itu, gunakan mekanisme skala otomatis seperti paket Penskalaan. Dengan mekanisme ini, dimungkinkan untuk mempertahankan sebagian besar sumber daya komputasi dalam keadaan offline atau tidak dialokasikan untuk mengurangi biaya.
Anda juga dapat menggunakan otomatisasi untuk membuat host sesi di wilayah sekunder hanya jika diperlukan. Metode ini mengoptimalkan biaya, tetapi tergantung pada mekanisme yang Anda gunakan, mungkin memerlukan RTO yang lebih lama. Pendekatan ini tidak mengizinkan pengujian failover tanpa penyebaran baru dan tidak mengizinkan failover selektif untuk grup pengguna tertentu.

Catatan
Anda harus menyalakan setiap VM host sesi selama beberapa jam setidaknya satu kali setiap 90 hari untuk menyegarkan token autentikasi yang diperlukan untuk terhubung ke sarana kontrol Virtual Desktop. Anda juga harus secara rutin menerapkan patch keamanan dan pembaruan aplikasi.
- Memiliki host sesi dalam status offline, atau dibatalkan alokasinya, di wilayah sekunder tidak menjamin bahwa kapasitas tersedia jika terjadi bencana di seluruh wilayah utama. Ini juga berlaku jika host sesi baru disebarkan sesuai permintaan saat diperlukan, dan dengan penggunaan Site Recovery . Kapasitas komputasi hanya dapat dijamin jika sumber daya terkait sudah dialokasikan dan aktif.
Penting
Reservasi Azure tidak memberikan kapasitas terjamin di wilayah tersebut.
Untuk skenario penggunaan Cloud Cache, sebaiknya gunakan tingkat Premium untuk disk terkelola.
Penyimpanan
Dalam panduan ini, Anda menggunakan setidaknya dua akun penyimpanan terpisah untuk setiap kumpulan host Virtual Desktop. Salah satunya adalah untuk kontainer Profil FSLogix, dan satu untuk data kontainer Office. Anda juga memerlukan satu akun penyimpanan lagi untuk paket MSIX . Pertimbangan berikut berlaku:
- Anda dapat menggunakan berbagi Azure Files dan Azure NetApp Files sebagai alternatif penyimpanan. Untuk membandingkan opsi, lihat opsi penyimpanan kontainer FSLogix.
- Berbagi Azure Files dapat memberikan ketahanan zona dengan menggunakan opsi ketahanan penyimpanan zona-redundan (ZRS), jika tersedia di wilayah tersebut.
- Anda tidak dapat menggunakan fitur penyimpanan geo-redundan dalam situasi berikut:
- Anda memerlukan wilayah yang tidak memiliki pasangan. Pasangan wilayah untuk penyimpanan geo-redundan diperbaiki dan tidak dapat diubah.
- Anda menggunakan tingkat Premium.
- RPO dan RTO lebih tinggi dibandingkan dengan mekanisme FSLogix Cloud Cache.
- Tidak mudah untuk menguji failover dan failback di lingkungan produksi.
- Azure NetApp Files memerlukan lebih banyak pertimbangan:
- Redundansi zona belum tersedia. Jika persyaratan ketahanan lebih penting daripada performa, gunakan berbagi Azure Files.
- Azure NetApp Files dapat berupa zonal, yaitu pelanggan dapat memutuskan zona ketersediaan Azure (tunggal) mana yang akan dialokasikan.
- Replikasi lintas zona dapat dibuat pada tingkat volume untuk memberikan ketahanan zona tetapi replikasi terjadi secara asinkron dan memerlukan failover manual. Proses ini memerlukan tujuan titik pemulihan (RPO) dan tujuan waktu pemulihan (RTO) yang lebih besar dari nol. Sebelum menggunakan fitur ini, tinjau persyaratan dan pertimbangan untuk replikasi lintas zona.
- Anda dapat menggunakan Azure NetApp Files dengan vpn zona redundan dan gateway ExpressRoute, jika fitur jaringan standar digunakan, yang mungkin Anda gunakan untuk ketahanan jaringan. Untuk informasi selengkapnya, lihat Topologi jaringan yang didukung.
- Azure Virtual WAN didukung saat digunakan bersama dengan jaringan standar Azure NetApp Files. Untuk informasi selengkapnya, lihat Topologi jaringan yang didukung.
- Azure NetApp Files memiliki mekanisme replikasi lintas wilayah. Pertimbangan berikut berlaku:
- Ini tidak tersedia di semua wilayah.
- Replikasi lintas wilayah pasangan wilayah volume Azure NetApp Files dapat berbeda dari pasangan wilayah Azure Storage.
- Ini tidak dapat digunakan pada saat yang sama dengan replikasi lintas zona
- Failover tidak transparan, dan failback memerlukan konfigurasi ulang penyimpanan.
- Perbatasan
- Ada batasan dalam ukuran, operasi input/output per detik (IOPS), bandwidth MBps untuk berbagi Azure Files dan akun dan volume penyimpanan Azure NetApp Files. Jika perlu, dimungkinkan untuk menggunakan lebih dari satu untuk kumpulan host yang sama di Virtual Desktop dengan menggunakan pengaturan per grup di FSLogix. Namun, konfigurasi ini membutuhkan lebih banyak perencanaan dan konfigurasi.
Akun penyimpanan yang Anda gunakan untuk paket aplikasi MSIX harus berbeda dari akun lain untuk kontainer Profil dan Office. Opsi pemulihan bencana geografis berikut ini tersedia:
- Satu akun penyimpanan dengan penyimpanan geo-redundan diaktifkan, di wilayah utama
- Wilayah sekunder diperbaiki. Opsi ini tidak cocok untuk akses lokal jika ada failover akun penyimpanan.
- Dua akun penyimpanan terpisah, satu di wilayah utama dan satu di wilayah sekunder (disarankan)
- Gunakan penyimpanan zona-redundan untuk setidaknya wilayah utama.
- Setiap kumpulan host di setiap wilayah memiliki akses penyimpanan lokal ke paket MSIX dengan latensi rendah.
- Salin paket MSIX dua kali di kedua lokasi dan daftarkan paket dua kali di kedua kumpulan host. Tetapkan pengguna ke grup aplikasi dua kali.
FSLogix
Microsoft menyarankan agar Anda menggunakan konfigurasi dan fitur FSLogix berikut:
Jika konten kontainer Profil harus memiliki manajemen BCDR terpisah, dan memiliki persyaratan yang berbeda dibandingkan dengan kontainer Office, Anda harus membaginya.
- Kontainer Office hanya memiliki konten cache yang dapat dibangun kembali atau diisi ulang dari sumber jika ada bencana. Dengan Kontainer Office, Anda mungkin tidak perlu menyimpan cadangan, yang dapat mengurangi biaya.
- Saat menggunakan akun penyimpanan yang berbeda, Anda hanya dapat mengaktifkan cadangan pada kontainer profil. Atau, Anda harus memiliki pengaturan yang berbeda seperti periode retensi, penyimpanan yang digunakan, frekuensi, dan RTO/RPO.
Cloud Cache adalah komponen FSLogix tempat Anda dapat menentukan beberapa lokasi penyimpanan profil dan mereplikasi data profil secara asinkron, semuanya tanpa mengandalkan mekanisme replikasi penyimpanan yang mendasar. Jika lokasi penyimpanan pertama gagal atau tidak dapat dijangkau, Cloud Cache secara otomatis melakukan failover untuk menggunakan sekunder, dan secara efektif menambahkan lapisan ketahanan. Gunakan Cloud Cache untuk mereplikasi kontainer Profil dan Office antara akun penyimpanan yang berbeda di wilayah utama dan sekunder.
Anda harus mengaktifkan Cloud Cache dua kali di registri VM host sesi, sekali untuk Kontainer Profil dan sekali untuk Kontainer Office. Dimungkinkan untuk tidak mengaktifkan Cloud Cache for Office Container, tetapi tidak mengaktifkannya dapat menyebabkan ketidakselarasan data antara wilayah pemulihan bencana primer dan sekunder jika ada failover dan failback. Uji skenario ini dengan hati-hati sebelum menggunakannya dalam produksi.
Cloud Cache kompatibel dengan pengaturan pemisahan profil dan per grup . per grup memerlukan desain dan perencanaan grup direktori aktif dan keanggotaan yang cermat. Anda harus memastikan bahwa setiap pengguna adalah bagian dari tepat satu grup, dan grup tersebut digunakan untuk memberikan akses ke kumpulan host.
Parameter CCDLocations yang ditentukan dalam registri untuk kumpulan host di wilayah pemulihan bencana sekunder dikembalikan secara berurutan, dibandingkan dengan pengaturan di wilayah utama. Untuk informasi selengkapnya, lihat Tutorial: Mengonfigurasi Cloud Cache untuk mengalihkan kontainer profil atau kontainer office ke beberapa Penyedia.
Tip
Artikel ini berfokus pada skenario tertentu. Skenario tambahan dijelaskan dalam Opsi ketersediaan tinggi untuk opsi FSLogix dan Kelangsungan bisnis dan pemulihan bencana untuk FSLogix.

Contoh berikut menunjukkan konfigurasi Cloud Cache dan kunci registri terkait:
Wilayah Utama = Eropa Utara
Akun penyimpanan kontainer profil URI = \northeustg1\profiles
- Jalur Kunci Registri = HKEY_LOCAL_MACHINE > Profil FSLogix > PERANGKAT LUNAK >
- Nilai CCDLocations = type=smb,connectionString=\northeustg1\profiles; type=smb,connectionString=\westeustg1\profiles
Catatan
Jika sebelumnya Anda mengunduh Templat FSLogix, Anda dapat menyelesaikan konfigurasi yang sama melalui Konsol Manajemen Kebijakan Grup Direktori Aktif. Untuk detail selengkapnya tentang cara menyiapkan Objek Kebijakan Grup untuk FSLogix, lihat panduan, Gunakan File Templat Kebijakan Grup FSLogix.
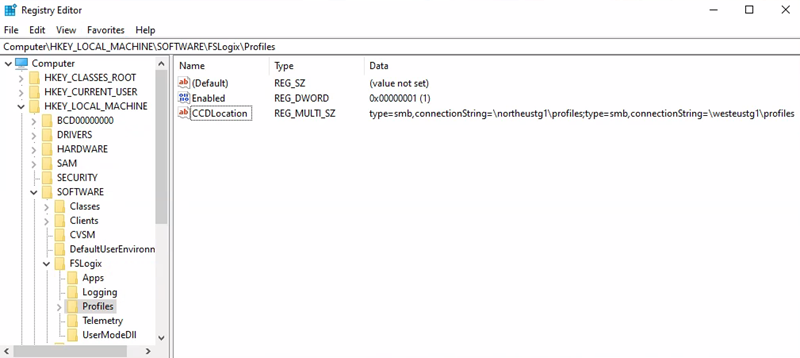
URI akun penyimpanan kontainer Office = \northeustg2\odcf
Jalur Kunci Registri = HKEY_LOCAL_MACHINE > Kebijakan > PERANGKAT LUNAK >FSLogix > ODFC
Nilai CCDLocations = type=smb,connectionString=\northeustg2\odfc; type=smb,connectionString=\westeustg2\odfc
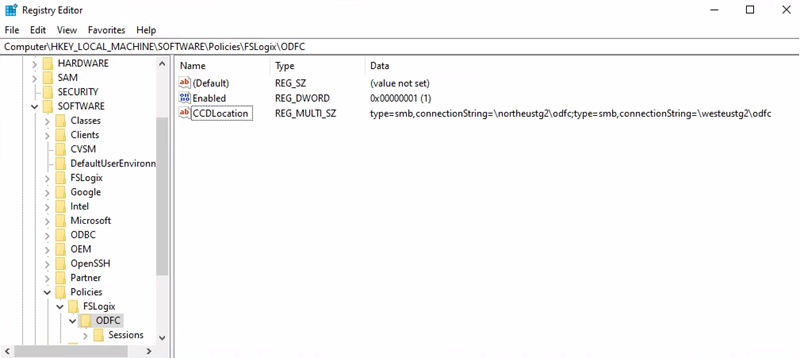


Catatan
Dalam cuplikan layar di atas, tidak semua kunci registri yang direkomendasikan untuk FSLogix dan Cloud Cache dilaporkan, untuk kemudahan dan kesederhanaan. Untuk informasi selengkapnya, lihat Contoh konfigurasi FSLogix.
Wilayah Sekunder = Eropa Barat
- Akun penyimpanan kontainer profil URI = \westeustg1\profiles
- Jalur Kunci Registri = HKEY_LOCAL_MACHINE > Profil FSLogix > PERANGKAT LUNAK >
- Nilai CCDLocations = type=smb,connectionString=\westeustg1\profiles; type=smb,connectionString=\northeustg1\profiles
- URI akun penyimpanan kontainer Office = \westeustg2\odcf
- Jalur Kunci Registri = HKEY_LOCAL_MACHINE > Kebijakan > PERANGKAT LUNAK >FSLogix > ODFC
- Nilai CCDLocations = type=smb,connectionString=\westeustg2\odfc; type=smb,connectionString=\northeustg2\odfc
Replikasi Cloud Cache
Konfigurasi Cloud Cache dan mekanisme replikasi menjamin replikasi data profil antara wilayah yang berbeda dengan kehilangan data minimal. Karena file profil pengguna yang sama dapat dibuka dalam mode ReadWrite hanya dengan satu proses, akses bersamaan harus dihindari, sehingga pengguna tidak boleh membuka koneksi ke kedua kumpulan host secara bersamaan.

Unduh file Visio arsitektur ini.
Aliran data
Pengguna Virtual Desktop meluncurkan klien Virtual Desktop, lalu membuka aplikasi Desktop atau Aplikasi Jarak Jauh yang diterbitkan yang ditetapkan ke kumpulan host wilayah utama.
FSLogix mengambil kontainer Profil dan Office pengguna, lalu memasang VHD/X penyimpanan yang mendasar dari akun penyimpanan yang terletak di wilayah utama.
Pada saat yang sama, komponen Cloud Cache menginisialisasi replikasi antara file di wilayah utama dan file di wilayah sekunder. Untuk proses ini, Cloud Cache di wilayah utama memperoleh kunci baca-tulis eksklusif pada file-file ini.
Pengguna Virtual Desktop yang sama sekarang ingin meluncurkan aplikasi lain yang diterbitkan yang ditetapkan pada kumpulan host wilayah sekunder.
Komponen FSLogix yang berjalan pada host sesi Virtual Desktop di wilayah sekunder mencoba memasang profil pengguna file VHD/X dari akun penyimpanan lokal. Tetapi pemasangan gagal karena file-file ini dikunci oleh komponen Cloud Cache yang berjalan pada host sesi Virtual Desktop di wilayah utama.
Dalam konfigurasi FSLogix dan Cloud Cache default, pengguna tidak dapat masuk dan kesalahan dilacak di log diagnostik FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identitas
Salah satu dependensi terpenting untuk Virtual Desktop adalah ketersediaan identitas pengguna. Untuk mengakses desktop virtual jarak jauh penuh dan aplikasi jarak jauh dari host sesi Anda, pengguna Anda harus dapat mengautentikasi. MICROSOFT Entra ID adalah layanan identitas cloud terpusat Microsoft yang memungkinkan kemampuan ini. ID Microsoft Entra selalu digunakan untuk mengautentikasi pengguna untuk Virtual Desktop. Host sesi dapat digabungkan ke penyewa Microsoft Entra yang sama, atau ke domain Direktori Aktif menggunakan Active Directory Domain Services (AD DS) atau Microsoft Entra Domain Services, memberi Anda pilihan opsi konfigurasi yang fleksibel.
Microsoft Entra ID
- Ini adalah layanan multi-wilayah dan tangguh global dengan ketersediaan tinggi. Tidak ada tindakan lain yang diperlukan dalam konteks ini sebagai bagian dari paket BCDR Virtual Desktop.
Active Directory Domain Services
- Agar Active Directory Domain Services tangguh dan sangat tersedia, bahkan jika ada bencana di seluruh wilayah, Anda harus menyebarkan setidaknya dua pengendali domain (DC) di wilayah Azure utama. Pengendali domain ini harus berada di zona ketersediaan yang berbeda jika memungkinkan, dan Anda harus memastikan replikasi yang tepat dengan infrastruktur di wilayah sekunder dan akhirnya lokal. Anda harus membuat setidaknya satu pengontrol domain lagi di wilayah sekunder dengan katalog global dan peran DNS. Untuk informasi selengkapnya, lihat Menyebarkan Active Directory Domain Services (AD DS) di jaringan virtual Azure.
Microsoft Entra Connect
Jika Anda menggunakan ID Microsoft Entra dengan Active Directory Domain Services, lalu Microsoft Entra Connect untuk menyinkronkan data identitas pengguna antara Active Directory Domain Services dan ID Microsoft Entra, Anda harus mempertimbangkan ketahanan dan pemulihan layanan ini untuk perlindungan dari bencana permanen.
Anda dapat memberikan ketersediaan tinggi dan pemulihan bencana dengan menginstal instans kedua layanan di wilayah sekunder dan mengaktifkan mode penahapan.
Jika ada pemulihan, administrator diharuskan untuk mempromosikan instans sekunder dengan mengeluarkannya dari mode penahapan. Mereka harus mengikuti prosedur yang sama seperti menempatkan server ke mode penahapan. Kredensial Administrator Global Microsoft Entra diperlukan untuk melakukan konfigurasi ini.
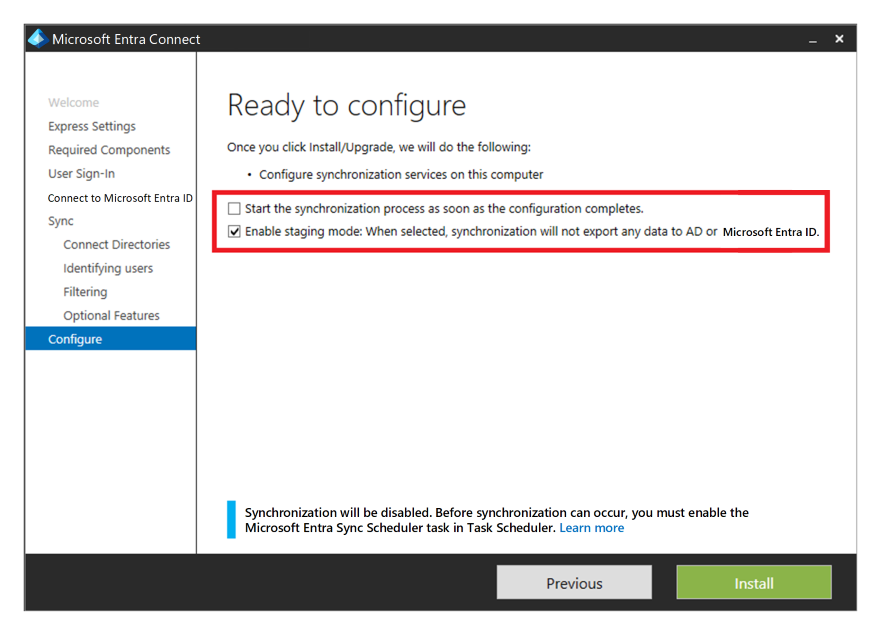
Microsoft Entra Domain Services
- Anda dapat menggunakan Microsoft Entra Domain Services dalam beberapa skenario sebagai alternatif untuk Active Directory Domain Services.
- Ini menawarkan ketersediaan tinggi.
- Jika pemulihan bencana geografis berada dalam cakupan untuk skenario Anda, Anda harus menyebarkan replika lain di wilayah Azure sekunder dengan menggunakan set replika. Anda juga dapat menggunakan fitur ini untuk meningkatkan ketersediaan tinggi di wilayah utama.
Diagram arsitektur
Kumpulan host pribadi

Unduh file Visio arsitektur ini.
Kumpulan host terkumpul

Unduh file Visio arsitektur ini.
Failover dan failback
Skenario kumpulan host pribadi
Catatan
Hanya model aktif-pasif yang tercakup di bagian ini—aktif-aktif tidak memerlukan failover atau intervensi administrator.
Failover dan failback untuk kumpulan host pribadi berbeda, karena tidak ada Cloud Cache dan penyimpanan eksternal yang digunakan untuk kontainer Profil dan Office. Anda masih dapat menggunakan teknologi FSLogix untuk menyimpan data dalam kontainer dari host sesi. Tidak ada kumpulan host sekunder di wilayah pemulihan bencana, jadi tidak perlu membuat lebih banyak ruang kerja dan sumber daya Virtual Desktop untuk mereplikasi dan menyelaraskan. Anda dapat menggunakan Site Recovery untuk mereplikasi VM host sesi.
Anda dapat menggunakan Site Recovery dalam beberapa skenario berbeda. Untuk Virtual Desktop, gunakan arsitektur pemulihan bencana Azure ke Azure di Azure Site Recovery.
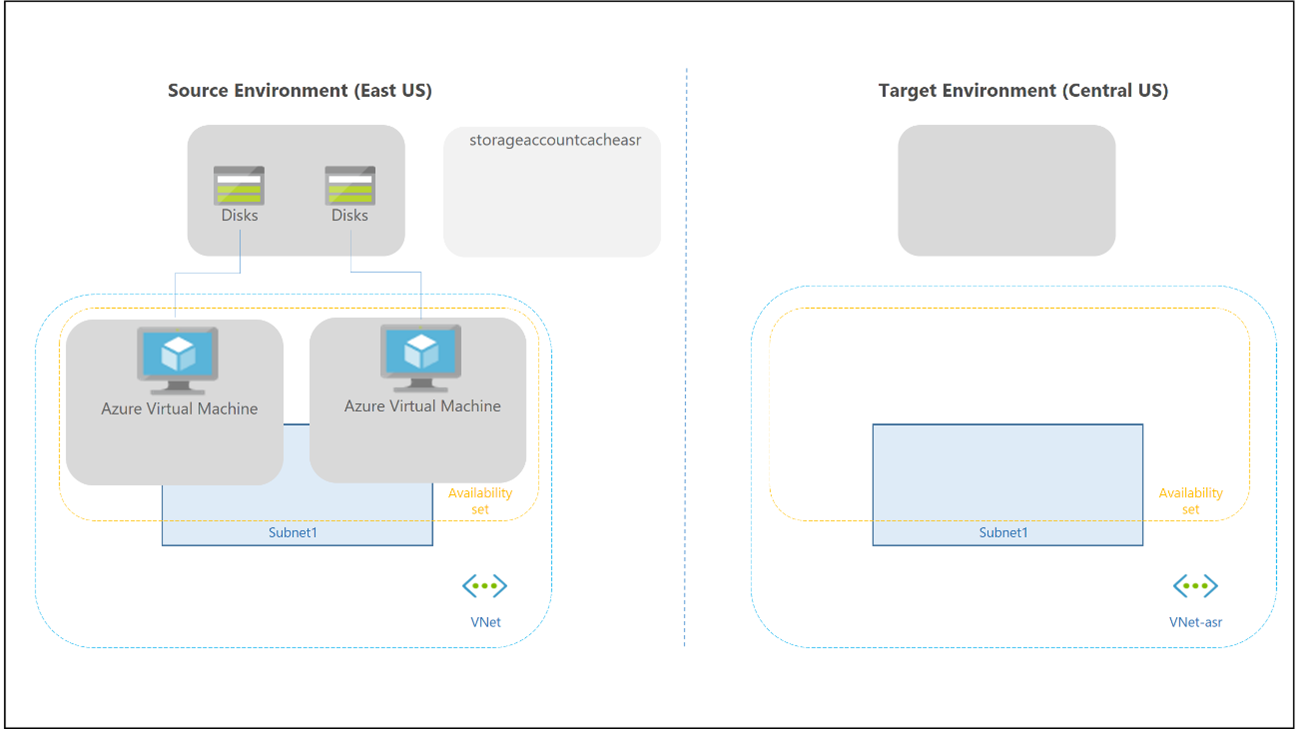
Pertimbangan dan rekomendasi berikut berlaku:
- Failover Site Recovery tidak otomatis—administrator harus memicunya dengan menggunakan portal Azure atau Powershell/API.
- Anda dapat membuat skrip dan mengotomatiskan seluruh konfigurasi dan operasi Site Recovery dengan menggunakan PowerShell.
- Site Recovery memiliki RTO yang dinyatakan di dalam perjanjian tingkat layanan (SLA)-nya. Sebagian besar waktu, Site Recovery dapat melakukan failover pada VM dalam hitungan menit.
- Anda dapat menggunakan Site Recovery dengan Azure Backup. Untuk informasi selengkapnya, lihat Dukungan untuk menggunakan Site Recovery dengan Azure Backup.
- Anda harus mengaktifkan Site Recovery di tingkat VM, karena tidak ada integrasi langsung dalam pengalaman portal Virtual Desktop. Anda juga harus memicu failover dan failback pada tingkat VM tunggal.
- Site Recovery menyediakan kemampuan failover pengujian di subnet terpisah untuk Azure VM umum. Jangan gunakan fitur ini untuk VM Virtual Desktop, karena Anda akan memiliki dua host sesi Virtual Desktop yang identik yang memanggil sarana kontrol layanan secara bersamaan.
- Site Recovery tidak mempertahankan ekstensi Komputer Virtual selama replikasi. Jika Anda mengaktifkan ekstensi kustom untuk VM host sesi Virtual Desktop, Anda harus mengaktifkan kembali ekstensi setelah failover atau failback. Joindomain ekstensi bawaan Virtual Desktop dan Microsoft.PowerShell.DSC hanya digunakan saat VM host sesi dibuat. Aman untuk kehilangan mereka setelah failover pertama.
- Pastikan untuk meninjau matriks Dukungan untuk pemulihan bencana Azure VM antara wilayah Azure dan memeriksa persyaratan, batasan, dan matriks kompatibilitas untuk skenario pemulihan bencana Azure-ke-Azure Site Recovery, terutama versi OS yang didukung.
- Saat Anda melakukan failover VM dari satu wilayah ke wilayah lain, VM dimulai di wilayah pemulihan bencana target dalam keadaan tidak terlindungi. Failback dimungkinkan, tetapi pengguna harus melindungi ulang VM di wilayah sekunder, lalu mengaktifkan replikasi kembali ke wilayah utama.
- Jalankan pengujian berkala prosedur failover dan failback. Kemudian dokumentasikan daftar langkah-langkah dan tindakan pemulihan yang tepat berdasarkan lingkungan Virtual Desktop spesifik Anda.
Skenario kumpulan host terkumpul
Salah satu karakteristik yang diinginkan dari model pemulihan bencana aktif-aktif adalah bahwa intervensi administrator tidak diperlukan untuk memulihkan layanan jika ada pemadaman. Prosedur failover hanya boleh diperlukan dalam arsitektur pasif aktif.
Dalam model pasif aktif, wilayah pemulihan bencana sekunder harus menganggur, dengan sumber daya minimal dikonfigurasi, dan aktif. Konfigurasi harus tetap selaras dengan wilayah utama. Jika ada failover, penetapan ulang untuk semua pengguna ke semua desktop dan grup aplikasi untuk aplikasi jarak jauh di kumpulan host pemulihan bencana sekunder terjadi pada saat yang sama.
Dimungkinkan untuk memiliki model aktif-aktif dan failover parsial. Jika kumpulan host hanya digunakan untuk menyediakan grup desktop dan aplikasi, maka Anda dapat mempartisi pengguna dalam beberapa grup Direktori Aktif yang tidak tumpang tindih dan menetapkan ulang grup ke desktop dan grup aplikasi di kumpulan host pemulihan bencana primer atau sekunder. Pengguna tidak boleh memiliki akses ke kedua kumpulan host secara bersamaan. Jika ada beberapa grup dan aplikasi aplikasi, grup pengguna yang Anda gunakan untuk menetapkan pengguna mungkin tumpang tindih. Dalam hal ini, sulit untuk menerapkan strategi aktif-aktif. Setiap kali pengguna memulai aplikasi jarak jauh di kumpulan host utama, profil pengguna dimuat oleh FSLogix pada VM host sesi. Mencoba melakukan hal yang sama pada kumpulan host sekunder dapat menyebabkan konflik pada disk profil yang mendasarinya.
Peringatan
Secara default, pengaturan registri FSLogix melarang akses bersamaan ke profil pengguna yang sama dari beberapa sesi. Dalam skenario BCDR ini, Anda tidak boleh mengubah perilaku ini dan meninggalkan nilai 0 untuk kunci registri ProfileType.
Berikut adalah situasi awal dan asumsi konfigurasi:
- Kumpulan host di wilayah utama dan wilayah pemulihan bencana sekunder selaras selama konfigurasi, termasuk Cloud Cache.
- Di kumpulan host, desktop DAG1 dan grup aplikasi jarak jauh APPG2 dan APPG3 ditawarkan kepada pengguna.
- Di kumpulan host di wilayah utama, grup pengguna Direktori Aktif GRP1, GRP2, dan GRP3 digunakan untuk menetapkan pengguna ke DAG1, APPG2, dan APPG3. Grup ini mungkin memiliki keanggotaan pengguna yang tumpang tindih, tetapi karena model di sini menggunakan pasif aktif dengan failover penuh, itu bukan masalah.
Langkah-langkah berikut menjelaskan kapan failover terjadi, setelah pemulihan bencana yang direncanakan atau tidak direncanakan.
- Di kumpulan host utama, hapus penetapan pengguna oleh grup GRP1, GRP2, dan GRP3 untuk grup aplikasi DAG1, APPG2, dan APPG3.
- Ada pemutusan paksa untuk semua pengguna yang terhubung dari kumpulan host utama.
- Di kumpulan host sekunder, di mana grup aplikasi yang sama dikonfigurasi, Anda harus memberikan akses pengguna ke DAG1, APPG2, dan APPG3 menggunakan grup GRP1, GRP2, dan GRP3.
- Tinjau dan sesuaikan kapasitas kumpulan host di wilayah sekunder. Di sini, Anda mungkin ingin mengandalkan rencana skala otomatis untuk menyalakan host sesi secara otomatis. Anda juga dapat memulai sumber daya yang diperlukan secara manual.
Langkah dan alur Failback serupa, dan Anda dapat menjalankan seluruh proses beberapa kali. Cloud Cache dan mengonfigurasi akun penyimpanan memastikan bahwa data kontainer Profil dan Office direplikasi. Sebelum failback, pastikan konfigurasi kumpulan host dan sumber daya komputasi dipulihkan. Untuk bagian penyimpanan, jika ada kehilangan data di wilayah utama, Cloud Cache mereplikasi profil dan data kontainer Office dari penyimpanan wilayah sekunder.
Dimungkinkan juga untuk menerapkan rencana failover pengujian dengan beberapa perubahan konfigurasi, tanpa memengaruhi lingkungan produksi.
- Buat beberapa akun pengguna baru di Direktori Aktif untuk produksi.
- Buat grup Direktori Aktif baru bernama GRP-TEST dan tetapkan pengguna.
- Tetapkan akses ke DAG1, APPG2, dan APPG3 dengan menggunakan grup GRP-TEST.
- Berikan instruksi kepada pengguna di grup GRP-TEST untuk menguji aplikasi.
- Uji prosedur failover dengan menggunakan grup GRP-TEST untuk menghapus akses dari kumpulan host utama dan memberikan akses ke kumpulan pemulihan bencana sekunder.
Rekomendasi penting:
- Otomatiskan proses failover dengan menggunakan PowerShell, Azure CLI, atau API atau alat lain yang tersedia.
- Uji seluruh prosedur failover dan failback secara berkala.
- Lakukan pemeriksaan penyelarasan konfigurasi reguler untuk memastikan kumpulan host di wilayah bencana primer dan sekunder sinkron.
Cadangan
Asumsi dalam panduan ini adalah bahwa ada pemisahan profil dan pemisahan data antara kontainer Profil dan kontainer Office. FSLogix mengizinkan konfigurasi ini dan penggunaan akun penyimpanan terpisah. Setelah berada di akun penyimpanan terpisah, Anda dapat menggunakan kebijakan pencadangan yang berbeda.
Untuk Kontainer ODFC, jika konten hanya mewakili data cache yang dapat dibangun kembali dari penyimpanan data on-line seperti Microsoft 365, tidak perlu mencadangkan data.
Jika perlu mencadangkan data kontainer Office, Anda dapat menggunakan penyimpanan yang lebih murah atau frekuensi cadangan dan periode retensi yang berbeda.
Untuk jenis kumpulan host pribadi, Anda harus menjalankan cadangan di tingkat VM host sesi. Metode ini hanya berlaku jika data disimpan secara lokal.
Jika Anda menggunakan OneDrive dan pengalihan folder yang diketahui, persyaratan untuk menyimpan data di dalam kontainer mungkin hilang.
Catatan
Pencadangan OneDrive tidak dipertimbangkan dalam artikel dan skenario ini.
Kecuali ada persyaratan lain, pencadangan untuk penyimpanan di wilayah utama harus cukup. Pencadangan lingkungan pemulihan bencana biasanya tidak digunakan.
Untuk berbagi Azure Files, gunakan Azure Backup.
- Untuk jenis ketahanan vault, gunakan penyimpanan zona-redundan jika penyimpanan cadangan di luar situs atau wilayah tidak diperlukan. Jika cadangan tersebut diperlukan, gunakan penyimpanan geo-redundan.
Azure NetApp Files menyediakan solusi cadangan bawaannya sendiri.
- Pastikan Anda memeriksa ketersediaan fitur wilayah, bersama dengan persyaratan dan batasan.
Akun penyimpanan terpisah yang digunakan untuk MSIX juga harus dicakup oleh cadangan jika repositori paket aplikasi tidak dapat dengan mudah dibangun kembali.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Ben Martin Baur | Arsitek Solusi Cloud
- Igor Pagliai | Insinyur Utama FastTrack for Azure (FTA)
Kontributor lain:
- Nelson Del Villar | Arsitek Solusi Cloud, Infrastruktur Inti Azure
- Jason Martinez | Penulis Teknis
Langkah berikutnya
- Rencana pemulihan bencana Virtual Desktop
- BCDR untuk Virtual Desktop - Kerangka Kerja Adopsi Cloud
- Cloud Cache untuk membuat ketahanan dan ketersediaan