Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Artikel ini memberikan gambaran umum tentang fitur grup failover dengan praktik terbaik dan rekomendasi untuk digunakan dengan Azure SQL Managed Instance. Fitur grup failover memungkinkan Anda mengelola replikasi dan failover semua database pengguna dalam instans terkelola SQL ke wilayah Azure lain.
Untuk memulai, tinjau Mengonfigurasi grup failover untuk Azure SQL Managed Instance.
Gambaran Umum
Fitur grup failover memungkinkan Anda mengelola replikasi dan failover database pengguna dari satu instans terkelola SQL ke instans terkelola SQL lain di wilayah Azure yang berbeda. Grup failover dirancang untuk menyederhanakan penyebaran dan manajemen database yang direplikasi secara geografis dalam skala besar.
Untuk informasi selengkapnya, lihat Ketersediaan tinggi untuk Azure SQL Managed Instance. Untuk RPO geo-failover dan RTO, lihat gambaran umum kelangsungan bisnis.
Pengalihan titik akhir
Grup failover menyediakan titik akhir pendengar baca-tulis dan baca-saja yang tetap tidak berubah selama geo-failover. Anda tidak perlu mengubah pengaturan koneksi untuk aplikasi Anda setelah failover geografis, karena koneksi secara otomatis dirutekan ke server utama saat ini. Geo-failover mengalihkan semua database sekunder dalam grup ke peran utama. Setelah geo-failover selesai, catatan DNS secara otomatis diperbarui untuk mengalihkan titik akhir ke wilayah baru.
Mengalihkan beban kerja baca-saja
Untuk mengurangi lalu lintas ke database utama Anda, Anda juga dapat menggunakan database sekunder dalam grup failover untuk mengalihkan beban kerja membaca saja. Gunakan pendengar hanya-baca untuk mengarahkan trafik hanya-baca ke database sekunder yang dapat dibaca.
Memulihkan aplikasi
Untuk mencapai kelangsungan bisnis penuh, menambahkan redundansi basis data regional hanyalah bagian dari solusi. Memulihkan aplikasi (layanan) secara ujung-ke-ujung setelah kegagalan besar membutuhkan pemulihan semua komponen yang membentuk layanan dan layanan yang bergantung. Contoh komponen ini termasuk perangkat lunak klien (misalnya, browser dengan JavaScript khusus), front end web, penyimpanan, dan DNS. Sangat penting bahwa semua komponen tahan terhadap kegagalan yang sama dan tersedia dalam tujuan waktu pemulihan (RTO) aplikasi Anda. Oleh karena itu, Anda perlu mengidentifikasi semua layanan yang bergantung dan memahami jaminan dan kemampuan yang diberikan layanan tersebut. Kemudian, Anda harus mengambil langkah-langkah yang memadai untuk memastikan bahwa layanan Anda berfungsi selama failover layanan yang bergantung padanya.
Kebijakan failover
Grup failover mendukung dua kebijakan failover:
-
Dikelola pelanggan (disarankan) - Pelanggan dapat melakukan failover suatu grup ketika mereka melihat ada pemadaman tak terduga yang berdampak pada satu atau beberapa database dalam grup failover. Saat menggunakan alat baris perintah seperti PowerShell, Azure CLI, atau Rest API, nilai kebijakan failover untuk dikelola pelanggan adalah
manual. -
Dikelola Microsoft - Jika terjadi pemadaman luas yang berdampak pada wilayah utama, Microsoft memulai failover semua grup failover yang terkena dampak yang memiliki kebijakan failover yang dikonfigurasi agar dikelola Microsoft. Failover yang dikelola Microsoft tidak akan dimulai untuk grup failover individual atau subset grup failover di suatu wilayah. Saat menggunakan alat baris perintah seperti PowerShell, Azure CLI, atau Rest API, nilai kebijakan failover untuk dikelola Microsoft adalah
automatic.
Setiap kebijakan failover memiliki serangkaian kasus penggunaan yang unik dan ekspektasi yang sesuai pada cakupan failover dan kehilangan data, seperti yang dirangkum tabel berikut:
| Kebijakan failover | Cakupan failover | Studi kasus | Potensi kehilangan data |
|---|---|---|---|
| Dikelola oleh pelanggan (Disarankan) |
Grup failover | Satu atau beberapa database dalam grup failover terpengaruh oleh pemadaman dan menjadi tidak tersedia. Anda dapat memilih untuk melakukan failover. | Ya |
| Microsoft yang mengelola | Semua grup failover di wilayah | Pemadaman yang meluas di suatu wilayah menyebabkan tidak tersedianya database dan tim layanan Microsoft Azure SQL memutuskan untuk memicu failover paksa. Gunakan opsi ini hanya ketika Anda ingin mendelegasikan tanggung jawab pemulihan bencana kepada Microsoft dan aplikasi ini toleran terhadap RTO (waktu henti) setidaknya satu jam atau lebih. Failover yang dikelola Microsoft hanya dapat dijalankan dalam keadaan ekstrem. Kebijakan failover yang dikelola pelanggan sangat disarankan. |
Ya |
Dikelola pelanggan
Pada kesempatan yang jarang terjadi, ketersediaan bawaan atau ketersediaan tinggi tidak cukup untuk mengurangi pemadaman, dan database Anda dalam grup failover mungkin tidak tersedia selama durasi yang tidak dapat diterima oleh perjanjian tingkat layanan (SLA) aplikasi yang menggunakan database. Database dapat tidak tersedia karena masalah yang dilokalkan hanya berdampak pada beberapa database, atau bisa berada di pusat data, zona ketersediaan, atau tingkat wilayah. Dalam salah satu kasus ini, untuk memulihkan kelangsungan bisnis, Anda dapat memulai failover paksa.
Mengatur kebijakan failover Anda ke yang dikelola pelanggan sangat disarankan, karena membuat Anda terkendali kapan harus memulai failover dan memulihkan kelangsungan bisnis. Anda dapat memulai failover saat melihat gangguan tak terduga yang berdampak pada satu atau beberapa database dalam grup failover.
Microsoft yang mengelola
Dengan kebijakan failover terkelola Microsoft, tanggung jawab pemulihan bencana didelegasikan ke layanan Azure SQL. Agar layanan Azure SQL memulai failover paksa, kondisi berikut harus dipenuhi:
- Pemadaman tingkat wilayah yang disebabkan oleh peristiwa bencana alam, perubahan konfigurasi, bug perangkat lunak atau kegagalan komponen perangkat keras dan banyak database di wilayah tersebut terpengaruh.
- Masa tenggang telah berakhir. Karena verifikasi skala dan upaya untuk mengurangi pemadaman bergantung pada tindakan manusia, masa tenggang tidak dapat ditetapkan kurang dari satu jam.
Ketika kondisi ini terpenuhi, layanan Azure SQL memulai failover paksa untuk semua grup failover di wilayah yang memiliki kebijakan failover yang diatur untuk dikelola oleh Microsoft.
Penting
Gunakan kebijakan failover yang dikelola pelanggan untuk menguji dan menerapkan rencana pemulihan bencana Anda. Jangan mengandalkan failover terkelola Microsoft, yang mungkin hanya dijalankan oleh Microsoft dalam keadaan ekstrem. Failover terkelola Microsoft dimulai untuk semua grup failover di wilayah yang kebijakan failover-nya diatur ke dikelola Microsoft. Ini tidak dapat dimulai untuk grup failover individual. Jika Anda perlu secara selektif melakukan failover atas grup failover Anda, gunakan kebijakan failover yang dikelola pelanggan.
Atur kebijakan failover ke yang hanya dikelola oleh Microsoft saat:
- Anda ingin mendelegasikan tanggung jawab pemulihan bencana ke layanan Azure SQL.
- Aplikasi ini toleran terhadap database Anda yang tidak tersedia setidaknya selama satu jam atau lebih.
- Dapat diterima untuk memicu failover paksa beberapa waktu setelah masa tenggang berakhir, karena waktu aktual untuk failover paksa dapat bervariasi secara signifikan.
- Dapat diterima bahwa semua database dalam grup failover gagal, terlepas dari konfigurasi redundansi zona atau status ketersediaannya. Meskipun database yang dikonfigurasi untuk redundansi zona tahan terhadap kegagalan zonal dan mungkin tidak terpengaruh oleh pemadaman, database tersebut masih akan gagal jika merupakan bagian dari grup failover dengan kebijakan failover terkelola Microsoft.
- Tidak menjadi masalah untuk melakukan failover secara paksa pada database dalam grup failover tanpa mempertimbangkan dependensi aplikasi pada layanan atau komponen Azure lainnya yang digunakan oleh aplikasi, yang dapat menyebabkan penurunan performa atau ketidaktersediaan aplikasi.
- Dapat diterima untuk terjadi kehilangan data yang tidak diketahui jumlahnya, karena waktu yang tepat dari failover paksa tidak dapat dikontrol, dan tanpa memerhatikan status sinkronisasi database sekunder.
- Replika utama dan sekunder dalam grup failover memiliki tingkat layanan, tingkat komputasi, dan ukuran komputasi yang sama.
Saat failover dipicu oleh Microsoft, entri untuk nama operasi Failover Grup Failover Azure SQL ditambahkan ke log aktivitas Azure Monitor. Entri menyertakan nama grup failover di bawah Sumber Daya, dan Peristiwa yang dipicu oleh menampilkan satu tanda hubung (-) untuk menunjukkan failover dimulai oleh Microsoft. Informasi ini juga dapat ditemukan di halaman Log aktivitas server utama atau instans baru di portal Azure.
Terminologi dan kemampuan
Grup failover (FOG)
Grup failover memungkinkan semua database pengguna dalam instans terkelola SQL untuk beralih sebagai satu kesatuan ke wilayah Azure lain jika instans terkelola SQL utama menjadi tidak tersedia akibat pemadaman di wilayah utama. Karena grup failover untuk SQL Managed Instance berisi semua database pengguna dalam instans, hanya satu grup failover yang dapat dikonfigurasi pada suatu instans.
Penting
Nama grup failover harus unik secara global dalam domain
.database.windows.net.Primer
Instans terkelola SQL yang menjadi host database utama dalam grup failover.
Sekunder
Instans terkelola SQL yang mengelola database sekunder dalam grup failover. Sekunder tidak boleh berada di wilayah Azure yang sama dengan yang utama.
Penting
Jika database berisi objek OLTP dalam memori, instans geo-replika primer dan sekunder harus memiliki tingkat layanan yang cocok, karena objek OLTP dalam memori berada dalam memori. Tingkat layanan yang lebih rendah pada instans geo-replika dapat mengakibatkan kekurangan memori. Jika ini terjadi, replika sekunder mungkin gagal memulihkan database, menyebabkan tidak tersedianya database sekunder bersama dengan objek OLTP dalam memori pada geo-sekunder. Hal ini dapat menyebabkan failover juga gagal. Untuk menghindari hal ini, pastikan tingkat layanan instans geo-sekunder cocok dengan database utama. Peningkatan tingkat layanan dapat berupa operasi ukuran data dan dapat memakan waktu cukup lama untuk diselesaikan.
Failover (tidak ada kehilangan data)
Failover melakukan sinkronisasi data penuh antara database primer dan sekunder sebelum sekunder beralih ke peran utama. Hal ini menjamin tidak ada data yang hilang. Failover hanya dimungkinkan ketika sistem utama dapat diakses. Failover digunakan dalam skenario-skenario berikut:
- Melakukan latihan pemulihan bencana (DR) dalam produksi saat kehilangan data tidak dapat diterima
- Merelokasi beban kerja ke wilayah lain
- Kembalikan beban kerja ke wilayah utama setelah pemadaman teratasi (pemulihan)
Failover yang dipaksakan (potensi kehilangan data)
Failover paksa segera mengalihkan sekunder ke peran utama tanpa menunggu perubahan terbaru untuk disebarluaskan dari primer. Operasi ini dapat mengakibatkan potensi kehilangan data. Failover paksa digunakan sebagai metode pemulihan selama pemadaman saat primer tidak dapat diakses. Ketika pemadaman dikurangi, primer lama akan secara otomatis terhubung kembali dan menjadi sekunder baru. Failover dapat dieksekusi untuk melakukan failback, mengembalikan replika ke peran utama dan sekunder aslinya.
Masa tenggang dengan kehilangan data
Karena data direplikasi ke sekunder menggunakan replikasi asinkron, failover paksa grup dengan kebijakan failover terkelola Microsoft dapat mengakibatkan kehilangan data. Anda dapat menyesuaikan kebijakan failover untuk mencerminkan toleransi aplikasi Anda terhadap kehilangan data. Dengan mengonfigurasi
GracePeriodWithDataLossHours, Anda dapat mengontrol berapa lama layanan Azure SQL menunggu sebelum memulai failover paksa, yang dapat mengakibatkan kehilangan data.
Zona DNS
ID unik yang dibuat secara otomatis saat Azure SQL Managed Instance baru dibuat. Sertifikat multi-domain (SAN) untuk instans ini disediakan untuk mengautentikasi koneksi klien ke instans apa pun di zona DNS yang sama. Dua instans terkelola SQL dalam grup failover yang sama harus berbagi zona DNS.
Pendengar baca-tulis grup failover
Data CNAME DNS yang menunjuk ke URL utama saat ini. Ini dibuat secara otomatis ketika grup failover dibuat dan memungkinkan beban kerja baca-tulis untuk terhubung kembali dengan mulus ke server utama ketika server utama berubah setelah failover. Saat grup failover dibuat pada instans terkelola SQL, catatan DNS CNAME untuk URL pendengar dibuat sebagai
<fog-name>.<zone_id>.database.windows.net.Pendengar baca-saja grup failover
Catatan CNAME DNS yang menunjuk ke sekunder saat ini. Ini dibuat secara otomatis ketika kelompok failover dibuat dan memungkinkan beban kerja SQL baca-saja untuk terhubung secara transparan ke server sekunder saat server sekunder berubah setelah failover. Saat grup failover dibuat pada instans terkelola SQL, catatan DNS CNAME untuk URL pendengar dibuat sebagai
<fog-name>.secondary.<zone_id>.database.windows.net. Secara bawaan, failover untuk pendengar baca-saja dinonaktifkan agar tidak mengganggu kinerja server utama saat server sekunder sedang offline. Namun, itu juga berarti sesi baca-saja tidak akan dapat terhubung sampai server sekunder dipulihkan. Jika Anda tidak dapat mentolerir waktu henti untuk sesi baca-saja dan dapat menggunakan server utama untuk lalu lintas baca-saja dan baca-tulis dengan risiko potensi penurunan performa server utama, Anda dapat mengaktifkan failover untuk pendengar baca-saja dengan mengonfigurasi propertiAllowReadOnlyFailoverToPrimary. Dalam hal ini, trafik baca-saja secara otomatis dialihkan ke sistem utama jika sistem sekunder tidak tersedia.Catatan
Properti
AllowReadOnlyFailoverToPrimaryhanya berpengaruh jika kebijakan failover terkelola Microsoft diaktifkan dan failover paksa telah dipicu. Dalam hal ini, jika properti diatur ke True, primer baru melayani sesi baca-tulis dan baca-saja.
Arsitektur kelompok failover
Grup failover harus dikonfigurasi pada instans utama dan menghubungkannya ke instans sekunder di wilayah Azure yang berbeda. Semua database pengguna pada instans utama direplikasi ke instans sekunder. Database sistem seperti master dan msdb tidak direplikasi.
Diagram berikut mengilustrasikan konfigurasi umum aplikasi cloud geo-redundan menggunakan instans terkelola SQL dan grup failover:
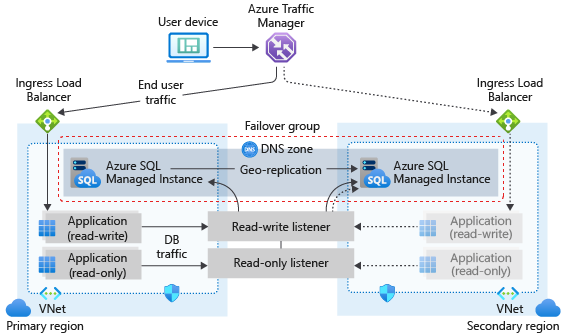
Jika aplikasi Anda menggunakan Azure SQL Managed Instance sebagai tingkat data, ikuti panduan umum dan praktik terbaik yang ditulis dalam artikel ini ketika merancang kelangsungan bisnis.
Buat instans geo-sekunder
Untuk memastikan konektivitas yang tidak terganggu ke SQL Managed Instance utama setelah failover, instans primer dan sekunder harus berada di zona DNS yang sama. Ini menjamin bahwa sertifikat multi-domain (SAN) yang sama dapat digunakan untuk mengautentikasi koneksi klien ke salah satu dari dua instans dalam grup failover. Saat aplikasi Anda siap untuk penyebaran produksi, buat SQL Managed Instance sekunder di wilayah yang berbeda, dan pastikan aplikasi tersebut berbagi zona DNS dengan SQL Managed Instance utama. Anda dapat melakukannya dengan menentukan parameter opsional saat membuat instans. Jika Anda menggunakan PowerShell atau REST API, nama parameter opsional adalah DNSZonePartner. Nama bidang opsional yang sesuai di portal Azure adalah Primary Managed Instance.
Penting
Instans terkelola SQL pertama yang dibuat di subnet menentukan zona DNS untuk semua instans berikutnya di subnet yang sama. Ini berarti bahwa dua instans dari subnet yang sama tidak dapat termasuk dalam zona DNS yang berbeda.
Untuk informasi selengkapnya tentang membuat SQL Managed Instance sekunder di zona DNS yang sama dengan instans utama, lihat Mengonfigurasi grup failover untuk Azure SQL Managed Instance.
Gunakan wilayah berpasangan
Sebarkan kedua instans terkelola SQL ke wilayah yang dipasangkan karena alasan performa. Grup failover SQL Instans Terkelola di wilayah terhubung memiliki kinerja yang lebih baik dibandingkan dengan wilayah yang tidak terhubung.
Azure SQL Managed Instance mengikuti praktik penyebaran yang aman di mana wilayah berpasangan Azure umumnya tidak disebarkan secara bersamaan. Namun, tidak mungkin untuk memprediksi wilayah mana yang ditingkatkan terlebih dahulu, sehingga urutan penyebaran tidak dijamin. Terkadang, instans utama Anda ditingkatkan terlebih dahulu, dan terkadang instans sekunder ditingkatkan terlebih dahulu.
Dalam situasi di mana Azure SQL Managed Instance adalah bagian dari grup failover, dan instans dalam grup tidak berada di wilayah berpasangan Azure, pilih jadwal jendela pemeliharaan yang berbeda untuk database utama dan sekunder Anda. Misalnya, pilih jendela pemeliharaan Hari Kerja untuk database geo-sekunder Anda dan jendela pemeliharaan Akhir Pekan untuk database geo-primer Anda.
Mengaktifkan dan mengoptimalkan arus lalu lintas replikasi geografis antar instans
Konektivitas antara subnet jaringan virtual yang menghosting instans primer dan sekunder harus dibuat dan dikelola untuk arus lalu lintas replikasi geografis yang tidak terganggu. Ada beberapa cara untuk menyediakan konektivitas antara instans yang dapat Anda pilih berdasarkan topologi dan kebijakan jaringan Anda:
Peering jaringan virtual global (peering VNet) adalah cara yang disarankan untuk membangun konektivitas antara dua instans dalam grup failover. Ini menyediakan koneksi privat dengan latensi rendah dan bandwidth tinggi antara jaringan virtual yang peering menggunakan infrastruktur backbone Microsoft. Tidak diperlukan internet publik, gateway, atau enkripsi tambahan dalam komunikasi antar jaringan virtual yang di-peering.
Awal penyemaian
Saat membentuk grup failover di antara instans SQL terkelola, terdapat fase penyemaian awal sebelum replikasi data dimulai. Fase penyemaian awal adalah bagian terpanjang dan termahal dari operasi. Setelah penyemaian awal selesai, data disinkronkan, dan hanya perubahan data berikutnya yang direplikasi. Waktu yang diperlukan agar penyemaian awal selesai tergantung pada ukuran data, jumlah database yang direplikasi, intensitas beban kerja pada database utama, dan kecepatan tautan antara jaringan virtual yang menghosting instans primer dan sekunder, yang sebagian besar tergantung pada cara konektivitas dibuat. Dalam keadaan normal, kecepatan transfer mencapai hingga 360 GB per jam untuk SQL Managed Instance ketika konektivitas dibuat menggunakan pemadanan jaringan virtual global yang direkomendasikan. Proses seeding dilakukan pada batch database pengguna secara paralel, namun tidak harus untuk semua database secara bersamaan. Beberapa batch mungkin diperlukan jika ada banyak database yang dihosting pada instans.
Jika kecepatan tautan antara kedua instance lebih lambat dari yang dibutuhkan, waktu yang dibutuhkan untuk penyemaian kemungkinan akan terpengaruh secara signifikan. Anda dapat menggunakan kecepatan penyemaian yang dinyatakan, jumlah database, ukuran total data, dan kecepatan tautan untuk memperkirakan berapa lama fase penyemaian awal berlangsung sebelum replikasi data dimulai. Misalnya, untuk database tunggal sebesar 100 GB, tahap pemindahan awal akan memakan waktu sekitar 1,2 jam jika tautan mampu memindahkan 84 GB per jam, dan jika tidak ada database lain yang dipindahkan. Jika tautan hanya dapat mentransfer 10 GB per jam, maka menyemai database 100 GB dapat memakan waktu sekitar 10 jam. Jika ada beberapa database untuk direplikasi, penyemaian dijalankan secara paralel. Ketika dikombinasikan dengan kecepatan tautan yang lambat, fase penyemaian awal mungkin memakan waktu jauh lebih lama, terutama jika penyemaian data paralel dari semua database melebihi bandwidth tautan yang tersedia.
Penting
Tahap awal seeding dapat memakan waktu berhari-hari dengan koneksi berkecepatan sangat rendah atau sibuk. Dalam hal ini, pembuatan grup failover dapat kadaluwarsa. Pembuatan grup failover dibatalkan secara otomatis setelah enam hari.
Kelola failover geografis ke instans sekunder geografis
Grup failover mengelola failover geografis semua database pada instans terkelola SQL utama. Saat grup dibuat, setiap database pada instans secara otomatis direplikasi secara geografis ke instans geo-sekunder. Anda tidak dapat menggunakan grup failover untuk memulai failover parsial dari subset database.
Penting
Jika database dihilangkan pada instans terkelola SQL utama, database juga secara otomatis dihilangkan pada instans terkelola SQL geo-sekunder.
Gunakan pendengar baca-tulis (MI utama)
Untuk beban kerja baca-tulis, gunakan <fog-name>.zone_id.database.windows.net sebagai nama server. Koneksi secara otomatis diarahkan ke utama. Nama ini tidak berubah setelah failover. Failover geografis melibatkan pembaruan catatan DNS, sehingga koneksi klien baru dirutekan ke primer baru hanya setelah cache DNS klien diperbarui. Karena instans sekunder berbagi zona DNS dengan primer, aplikasi klien akan dapat terhubung kembali ke sana menggunakan sertifikat SAN yang sama. Koneksi klien yang ada perlu dihentikan dan kemudian dibuat ulang untuk dirutekan ke primer baru. Pendengar mode baca-tulis dan mode baca-saja tidak dapat dijangkau melalui titik akhir Publik untuk instans terkelola SQL.
Gunakan pendengar pasif (MI sekunder)
Jika Anda memiliki beban kerja baca-saja yang terisolasi secara logis dan toleran terhadap latensi data, Anda dapat menjalankannya di unit sekunder geografis. Untuk terhubung langsung ke geo-sekunder, gunakan <fog-name>.secondary.<zone_id>.database.windows.net sebagai nama server.
Di tier Business Critical, SQL Managed Instance mendukung penggunaan replika baca-saja untuk mengalihkan beban kerja kueri baca-saja, menggunakan parameter ApplicationIntent=ReadOnly dalam string koneksi. Setelah Anda mengonfigurasi sekunder yang direplikasi secara geografis, Anda dapat menggunakan fitur ini untuk terhubung ke replika baca-saja baik di lokasi utama maupun di lokasi yang direplikasi secara geografis.
- Untuk terhubung ke replika baca-saja di lokasi utama, gunakan
ApplicationIntent=ReadOnlydan<fog-name>.<zone_id>.database.windows.net. - Untuk terhubung ke replika baca-saja di lokasi sekunder, gunakan
ApplicationIntent=ReadOnlydan<fog-name>.secondary.<zone_id>.database.windows.net.
Listener baca-tulis dan listener baca-saja tidak dapat dicapai melalui Titik akhir publik untuk instans terkelola SQL.
Potensi penurunan kinerja setelah failover
Aplikasi Azure yang khas menggunakan beberapa layanan Azure dan terdiri dari beberapa komponen. Failover geografis grup dipicu berdasarkan status komponen Azure SQL saja. Pemadaman mungkin tidak memengaruhi layanan Azure lainnya di wilayah utama, dan komponennya mungkin masih tersedia di wilayah tersebut. Setelah database utama beralih ke wilayah sekunder, latensi antara komponen dependen dapat meningkat. Pastikan redundansi semua komponen aplikasi di region sekunder dan pengalihan komponen aplikasi bersama dengan database sehingga latensi lintas wilayah yang lebih tinggi tidak memengaruhi performa aplikasi.
Kemungkinan kehilangan data setelah failover paksa
Jika pemadaman terjadi di wilayah utama, transaksi terbaru mungkin belum direplikasi ke geo-sekunder, dan mungkin ada kehilangan data jika failover paksa dilakukan.
Pembaruan DNS
Pembaruan DNS untuk pendengar baca-tulis akan terjadi seketika setelah failover dimulai. Operasi ini tidak akan mengakibatkan kehilangan data. Namun, proses peralihan peran database dapat memakan waktu hingga lima menit dalam kondisi normal. Hingga selesai, beberapa database dalam instans utama baru masih akan bersifat baca-saja. Jika failover dimulai menggunakan PowerShell, operasi untuk mengalihkan peran replika utama bersifat sinkron. Jika dimulai menggunakan portal Azure, UI menunjukkan status penyelesaian. Jika dimulai menggunakan REST API, gunakan mekanisme polling Azure Resource Manager standar untuk memantau penyelesaian.
Penting
Gunakan failover terencana manual untuk memindahkan server utama kembali ke lokasi asal setelah pemadaman yang menyebabkan geo-failover teratasi.
Menghemat biaya dengan replika DR bebas lisensi
Anda dapat menghemat biaya lisensi SQL Server dengan mengonfigurasi instans terkelola SQL sekunder Anda untuk digunakan hanya untuk pemulihan bencana (DR). Untuk menyiapkannya, lihat Mengonfigurasi replika siaga bebas lisensi untuk Azure SQL Managed Instance.
Selama instans sekunder tidak digunakan untuk beban kerja baca, Microsoft memberi Anda jumlah vCore gratis yang setara dengan instans utama. Anda masih dikenakan biaya untuk komputasi dan penyimpanan yang digunakan oleh instans sekunder. Grup failover hanya mendukung satu replika, dan replika harus berupa replika yang dapat dibaca atau ditetapkan sebagai replika khusus DR.
Mengaktifkan skenario yang bergantung pada objek dari database sistem
Database sistem tidak direplikasi ke instans sekunder dalam grup failover. Untuk mengaktifkan skenario yang bergantung pada objek dari database sistem, pastikan untuk membuat objek yang sama pada instans sekunder. Jaga agar tetap sinkron dengan instans utama.
Misalnya, jika Anda berencana untuk menggunakan login yang sama pada instans sekunder, pastikan untuk membuatnya dengan yang identik SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Untuk mempelajari selengkapnya, lihat Replikasi login dan pekerjaan agen.
Menyinkronkan properti instans dan kebijakan retensi instans.
Instans dalam grup failover tetap terpisah dari sumber daya Azure, dan tidak ada perubahan yang dilakukan pada konfigurasi instans utama yang secara otomatis direplikasi ke instans sekunder. Pastikan untuk melakukan semua perubahan yang relevan pada instans primer dan sekunder. Misalnya, jika Anda mengubah redundansi penyimpanan cadangan atau kebijakan penyimpanan cadangan jangka panjang pada instans utama, pastikan untuk mengubahnya pada instans sekunder juga.
Mengubah skala instance
Konfigurasi instans utama dan sekunder Anda harus sama. Ini termasuk ukuran komputasi, ukuran penyimpanan, dan tingkat layanan. Jika Anda perlu mengubah konfigurasi grup failover, Anda dapat melakukannya dengan menskalakan setiap instans ke konfigurasi yang sama. Untuk mempelajari lebih lanjut, tinjau Menskalakan instans dalam grup failover.
Mencegah hilangnya data penting
Karena tingginya latensi pada jaringan area luas, replikasi geo menggunakan mekanisme replikasi asinkron. Replikasi asinkron membuat kemungkinan kehilangan data tidak dapat dihindari jika primer gagal. Untuk mempelajari cara melindungi data Anda, tinjau Mencegah kehilangan data.
Status grup failover
Grup failover melaporkan statusnya yang menjelaskan status replikasi data saat ini:
- Seeding: Penginisialisasian awal dimulai setelah grup failover terbentuk, sampai semua database pengguna diaktifkan pada instans sekunder. Failover tidak dapat dimulai saat grup failover berada dalam status Seeding , karena database pengguna belum disalin ke instans sekunder.
- Sinkronisasi: Status grup failover yang umum. Ini berarti bahwa perubahan data pada instans utama direplikasi secara asinkron ke instans sekunder. Status ini tidak menjamin bahwa data disinkronkan sepenuhnya setiap saat. Mungkin ada perubahan data dari primer yang masih akan direplikasi ke sekunder karena sifat asinkron dari proses replikasi antara instans dalam grup failover. Failover otomatis dan manual dapat dimulai saat grup failover berada dalam status Sinkronisasi .
- Failover sedang berlangsung: Status ini menunjukkan bahwa failover yang dimulai secara otomatis atau manual sedang berlangsung. Tidak ada perubahan pada grup failover atau failover tambahan yang dapat dimulai saat grup failover dalam status ini.
Gagal kembali
Ketika grup failover dikonfigurasi dengan kebijakan failover yang dikelola Microsoft, failover paksa ke server geo-sekunder dimulai selama skenario bencana sesuai masa tenggang yang ditentukan. Pemulihan ke sistem primer lama harus dimulai secara manual.
Interoperabilitas fitur
Pencadangan
Pencadangan penuh diambil dalam skenario berikut:
- Sebelum penanaman awal dimulai ketika Anda membuat grup failover.
- Setelah proses failover.
Pencadangan penuh adalah jenis operasi data yang tidak bisa dilewati atau ditangguhkan, dan dapat memakan waktu untuk diselesaikan. Waktu yang diperlukan untuk menyelesaikan tergantung pada ukuran data, jumlah database, dan intensitas beban kerja pada database utama. Pencadangan keseluruhan dapat secara signifikan menunda penyemaian awal, dan dapat menunda atau bahkan mencegah terjadinya operasi failover di instans baru segera setelah failover.
Pertimbangkan hal berikut:
- Database-database yang dihosting pada instance sekunder grup failover tidak dicadangkan sampai instance tersebut menjadi utama setelah failover, atau sampai grup failover dihapus.
- Setelah database berubah menjadi peran utama setelah failover, atau menjadi mandiri setelah grup failover dihilangkan, cadangan database lengkap secara otomatis dimulai untuk memfasilitasi pemulihan titik waktu.
- Database tidak dapat dipulihkan dari instans ke titik waktu ketika instans tersebut adalah replika sekunder dalam grup failover. Untuk memulihkan ke titik waktu tertentu, Anda harus memulihkan database dari instans yang utama selama titik waktu tersebut.
- Untuk membuat ulang grup failover yang dihilangkan pada pasangan instans terkelola SQL yang sama, semua database pengguna perlu dihapus dari sekunder yang dimaksudkan setelah grup failover dihilangkan. Database hanya dihapus sepenuhnya setelah semua operasi pencadangan yang tertunda selesai, termasuk pencadangan penuh jika tidak diambil (yang merupakan operasi ukuran data). Izinkan waktu untuk membersihkan instans sekunder setelah menghilangkan grup failover dengan database yang sangat besar, karena setiap database dapat memiliki operasi pencadangan penuh yang sedang berlangsung.
Pencadangan penuh adalah jenis operasi data yang tidak dapat dilewati atau ditangguhkan dan dapat memerlukan waktu untuk selesai. Waktu yang diperlukan untuk menyelesaikan tergantung pada ukuran data, jumlah database, dan intensitas beban kerja pada database utama. Pencadangan penuh dapat secara signifikan menunda penyemaian awal dan dapat menunda atau mencegah operasi pemulihan otomatis pada instance baru tak lama setelah failover.
Layanan Pemutaran Ulang Log
Database yang dimigrasikan ke Azure SQL Managed Instance dengan menggunakan Log Replay Service (LRS) tidak dapat ditambahkan ke grup failover hingga langkah cutover dijalankan. Database yang dimigrasikan dengan LRS berada dalam status pemulihan hingga cutover, dan database dalam status pemulihan tidak dapat ditambahkan ke grup failover. Mencoba membuat grup failover dengan database dalam status pemulihan menunda pembuatan grup failover hingga pemulihan database selesai.
Replikasi Transaksional
Menggunakan replikasi transaksional dengan instans yang berada dalam grup failover didukung. Namun, jika Anda mengonfigurasi replikasi sebelum menambahkan instans terkelola SQL Anda ke dalam grup failover, replikasi akan berhenti sejenak saat Anda mulai membuat grup failover. Monitor replikasi menunjukkan status Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Replikasi dilanjutkan setelah grup failover berhasil dibuat.
Jika penerbit atau distributor instans terkelola SQL berada dalam grup failover, administrator instans terkelola SQL harus membersihkan semua publikasi pada primer lama dan mengonfigurasi ulang pada primer baru setelah failover terjadi. Tinjau panduan replikasi transaksional untuk langkah aktivitas yang diperlukan dalam skenario ini.
Izin dan batasan
Tinjau daftar izin dan batasan sebelum mengonfigurasi grup failover.
Mengelola grup failover secara terprogram
Grup failover juga dapat dikelola secara terprogram menggunakan Azure PowerShell, Azure CLI, dan REST API. Periksa Mengonfigurasi grup failover untuk mendapatkan informasi lebih lanjut.
Latihan pemulihan bencana
Cara yang disarankan untuk melakukan latihan DR menggunakan failover yang direncanakan manual, sesuai tutorial berikut: Uji failover.
Melakukan latihan menggunakan failover paksa tidak disarankan, karena operasi ini tidak menyediakan pagar pembatas terhadap kehilangan data. Namun demikian, dimungkinkan untuk mencapai failover paksa tanpa kehilangan data dengan memastikan kondisi berikut terpenuhi sebelum memulai failover paksa:
- Beban kerja dihentikan pada instans terkelola SQL utama.
- Semua transaksi yang berjalan lama telah selesai.
- Semua koneksi klien ke instans terkelola SQL utama telah terputus.
- Status grup failover adalah 'Mensinkronkan'.
Pastikan dua instans terkelola SQL telah beralih peran. Selain itu, status grup failover telah beralih dari 'Failover sedang berlangsung' ke 'Sinkronisasi' sebelum secara opsional membuat koneksi ke instans terkelola SQL utama baru dan memulai beban kerja baca-tulis.
Untuk melakukan failback tanpa kehilangan data ke peran instans terkelola SQL asli, menggunakan failover yang direncanakan manual alih-alih failover paksa sangat disarankan. Jika failback paksa digunakan:
- Ikuti langkah-langkah yang sama seperti untuk failover tanpa kehilangan data.
- Waktu eksekusi failback yang lebih lama diharapkan jika failback paksa dijalankan segera setelah failover paksa awal selesai, karena harus menunggu penyelesaian operasi pencadangan otomatis yang luar biasa pada instans terkelola SQL utama sebelumnya.
- Setiap operasi pencadangan otomatis yang luar biasa pada instans yang bertransisi dari peran utama ke sekunder dapat memengaruhi ketersediaan database pada instans ini.
- Silakan gunakan status grup failover untuk menentukan apakah kedua instans telah berhasil mengubah peran mereka dan siap untuk menerima koneksi klien.
Konten terkait
- Mengonfigurasi grup failover untuk Azure SQL Managed Instance
- Menggunakan PowerShell untuk menambahkan instans terkelola SQL ke grup failover
- Mengonfigurasi replika siaga bebas lisensi untuk Azure SQL Managed Instance
- Gambaran umum kelangsungan bisnis dengan Azure SQL Managed Instance
- Pencadangan otomatis di Azure SQL Managed Instance
- Memulihkan database dari cadangan di Azure SQL Managed Instance