Ketahanan dan pemulihan bencana di Layanan Azure Web PubSub
Ketahanan dan pemulihan bencana adalah kebutuhan umum untuk sistem online. Layanan Azure Web PubSub sudah menjamin ketersediaan 99,9%, tetapi masih berupa layanan regional. Jika terjadi gangguan di tingkat wilayah, layanan harus tetap memproses pesan real-time di wilayah lainnya.
Untuk pemulihan bencana regional, kami merekomendasikan dua pendekatan berikut:
- Aktifkan Geo-Replikasi (Cara mudah). Fitur ini akan menangani failover regional untuk Anda secara otomatis. Saat diaktifkan, hanya ada satu instans Azure SignalR dan tidak ada perubahan kode yang diperkenalkan. Periksa replikasi geografis untuk detailnya.
- Menggunakan Beberapa Titik Akhir. Anda mempelajari cara melakukannya dalam dokumen ini
Arsitektur dengan ketersediaan tinggi untuk layanan Web PubSub
Ada dua pola umum menggunakan layanan Web PubSub:
- Salah satunya adalah pola server klien yang dikirim klien ke server dan server mendorong pesan ke klien.
- Lainnya adalah pola klien-klien yang klien pub/sub pesan melalui layanan Web PubSub ke klien lain.
Bagian di bawah ini menjelaskan berbagai cara bagi kedua pola ini untuk melakukan pemulihan bencana
Arsitektur yang tersedia tinggi untuk pola server klien
Agar memiliki ketahanan lintas wilayah untuk layanan Web PubSub, Anda perlu menyiapkan beberapa instans layanan di berbagai wilayah. Jadi ketika satu wilayah mengalami gangguan, wilayah lain dapat digunakan sebagai cadangan.
Salah satu pengaturan umum untuk skenario lintas wilayah adalah memiliki dua (atau beberapa) pasang instans layanan Web PubSub dan server aplikasi.
Di dalam setiap pasangan, server aplikasi dan layanan Web PubSub berada di wilayah yang sama, dan layanan Web PubSub mengatur upstream penanganan aktivitas ke server aplikasi di wilayah yang sama.
Untuk memberikan penjelasan yang lebih baik terkait arsitektur, kami menyebut layanan Azure Web PubSub sebagai layanan primer untuk server aplikasi pasangan yang sama. Dan kami menyebut layanan Azure Web PubSub di pasangan lain sebagai layanan sekunder untuk server aplikasi.
Server aplikasi dapat menggunakan API pemeriksaan kondisi layanan untuk mendeteksi apakah layanan primer dan sekunder berfungsi atau tidak. Misalnya, untuk layanan Web PubSub yang disebut demo, titik akhir https://demo.webpubsub.azure.com/api/health akan menampilkan 200 saat layanan sehat. Server aplikasi dapat memanggil titik akhir secara berkala atau memanggil titik akhir sesuai permintaan untuk memeriksa apakah titik akhir tersebut sehat. Klien WebSocket biasanya bernegosiasi dengan server aplikasinya terlebih dahulu untuk menghubungkan URL ke layanan Azure Web PubSub, lalu aplikasi menggunakan langkah negosiasi ini untuk mengalihkan klien ke lain yang berfungsi sebagai layanan sekunder. Langkah-langkah mendetailnya sebagai berikut:
- Saat klien bernegosiasi dengan server aplikasi, server aplikasi hanya AKAN menampilkan titik akhir layanan Web PubSub primer, sehingga dalam kasus yang normal, klien hanya terhubung ke titik akhir primer.
- Saat instans primer gangguan, negosiasi AKAN menampilkan titik akhir sekunder yang sehat sehingga klien masih dapat membuat koneksi, dan klien terhubung ke titik akhir sekunder.
- Saat instans utama habis, negosiasi HARUS mengembalikan titik akhir utama yang berfungsi sehingga klien sekarang dapat terhubung ke titik akhir utama
- Saat server aplikasi menyiarkan pesan, server tersebut HARUS menyiarkan pesan ke semua titik akhir yang berfungsi termasuk yang primer maupun yang sekunder.
- Server aplikasi dapat menutup koneksi yang terhubung ke titik akhir sekunder untuk memaksa klien terhubung kembali ke titik akhir primer yang berfungsi.
Dengan topologi ini, pesan dari satu server masih dapat dikirimkan ke semua klien karena semua server aplikasi dan instans layanan Web PubSub saling terhubung.
Kami belum mengintegrasikan strategi ke dalam SDK, jadi untuk saat ini aplikasi perlu menerapkan strategi ini sendiri.
Singkatnya, yang perlu diterapkan oleh pihak aplikasi adalah:
- Pemeriksaan Kondisi. Aplikasi dapat memeriksa apakah layanan berfungsi menggunakan API pemeriksaan kondisi layanan secara berkala di latar belakang atau di tempat yang sesuai permintaan untuk setiap panggilan negosiasi.
- Negosiasi logika. Aplikasi mengembalikan titik akhir primer yang berfungsi secara default. Saat titik akhir primer tidak berfungsi, aplikasi menggantikannya dengan titik akhir sekunder yang berfungsi.
- Logika siaran. Ketika pesan dikirim ke beberapa klien, aplikasi perlu memastikan pesan disiarkan ke semua titik akhir yang sehat .
Di bawah ini adalah diagram yang mengilustrasikan topologi tersebut:
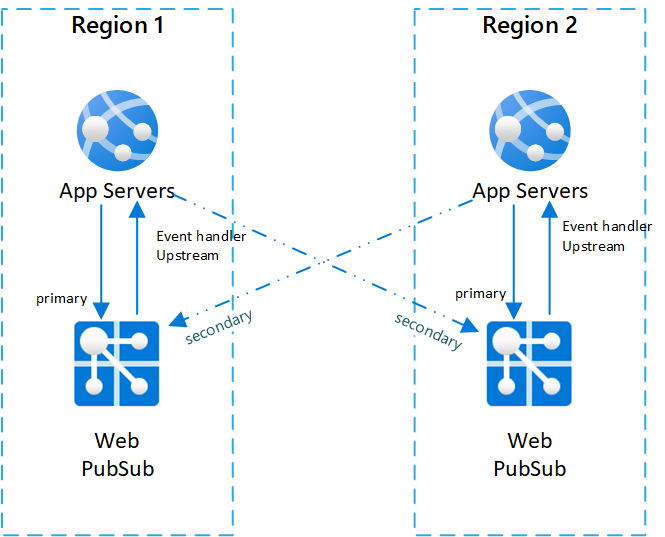
Urutan failover dan praktik terbaik
Sekarang Anda memiliki pengaturan topologi sistem yang tepat. Setiap kali satu instans layanan Web PubSub mengalami gangguan, lalu lintas online akan dirutekan ke instans lain. Inilah yang terjadi ketika instans primer mengalami gangguan (dan pulih setelah beberapa waktu):
- Jika instans layanan primer mengalami gangguan, semua klien yang terhubung ke instans ini akan hilang.
- Klien baru atau klien yang terhubung kembali bernegosiasi dengan server aplikasi
- Server aplikasi mendeteksi instans layanan primer sedang gangguan, dan negosiasi berhenti menampilkan titik akhir ini dan mulai menampilkan titik akhir sekunder yang sehat.
- Klien terhubung ke instans sekunder.
- Sekarang instans sekunder mengambil semua lalu lintas online. Semua pesan dari server ke klien masih dapat dikirim saat sekunder terhubung ke semua server aplikasi. Tetapi pesan peristiwa klien ke server hanya dikirim ke server aplikasi upstream di wilayah yang sama.
- Setelah instans primer dipulihkan dan kembali online, server aplikasi mendeteksi instans primer kembali sehat. Negosiasi sekarang akan mengembalikan titik akhir primer lagi sehingga klien baru terhubung kembali ke primer. Tetapi klien yang ada tidak akan dihilangkan dan akan tetap terhubung ke sekunder hingga terputus dengan sendirinya.
Diagram berikut menunjukkan cara failover dilakukan:
Gambar.1 Sebelum failover 
Gambar 2 Setelah failover 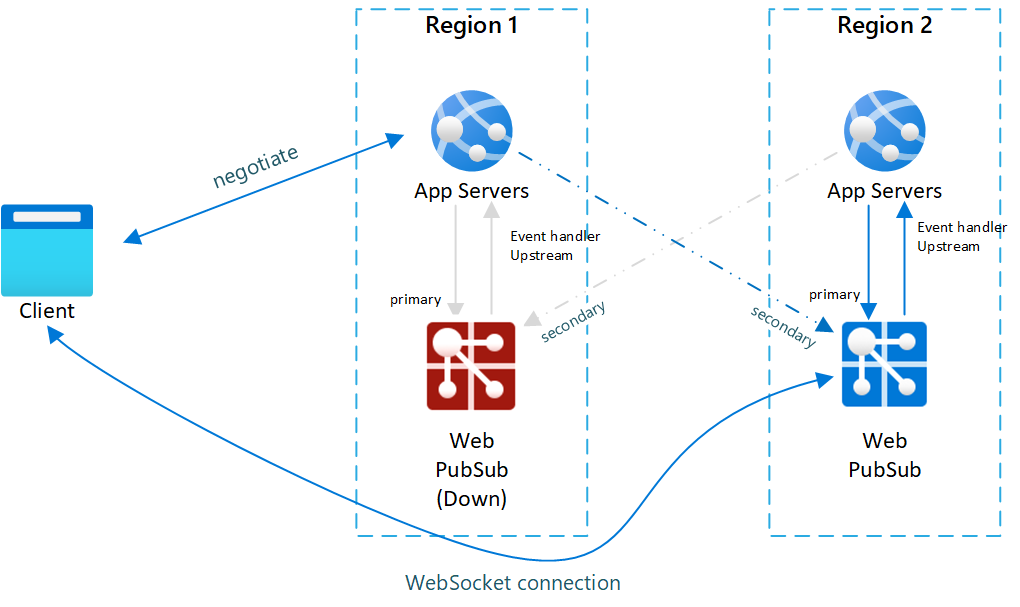
Gambar.3 Waktu singkat setelah primer pulih 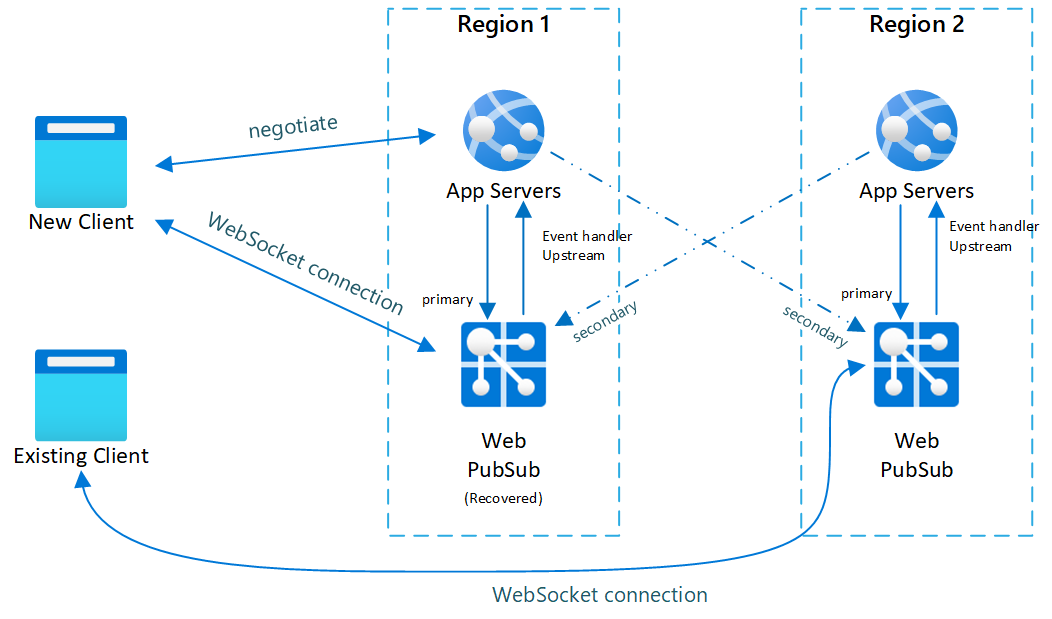
Dalam kasus normal, Anda hanya dapat melihat server aplikasi primer dan layanan Web PubSub memiliki lalu lintas online (berwarna biru).
Setelah failover, server aplikasi sekunder dan layanan Web PubSub juga menjadi aktif. Setelah layanan Web PubSub primer kembali online, klien baru akan terhubung ke Web PubSub primer. Tetapi klien yang ada masih terhubung ke sekunder sehingga kedua instans memiliki lalu lintas.
Setelah semua klien yang ada terputus, sistem Anda akan kembali normal (Gbr.1).
Ada dua pola utama untuk menerapkan arsitektur lintas wilayah dengan ketersediaan tinggi:
- Pola pertama adalah membuat sepasang server aplikasi dan instans layanan Web PubSub yang mengambil semua lalu lintas online, dan membuat pasangan lain sebagai cadangan (yang disebut aktif/pasif, seperti yang diilustrasikan di Gambar.1).
- Pola lainnya adalah membuat dua (atau beberapa) pasang server aplikasi dan instans layanan Web PubSub, yang masing-masing mengambil bagian dari lalu lintas online dan berfungsi sebagai cadangan untuk pasangan lain (yang disebut aktif/aktif, seperti Gambar. 3).
Layanan Web PubSub dapat mendukung kedua pola, perbedaan utamanya adalah cara Anda menerapkan server aplikasi. Jika server aplikasi aktif/pasif, layanan Web PubSub juga akan aktif/pasif (karena server aplikasi primer hanya menampilkan instans layanan Web PubSub primernya). Jika server aplikasi aktif/aktif, layanan Web PubSub juga akan aktif/aktif (karena semua server aplikasi akan menampilkan instans Web PubSub primernya sendiri, sehingga semuanya dapat mendapatkan lalu lintas).
Perhatikan bahwa apa pun pola yang Anda gunakan, Anda harus menghubungkan setiap instans layanan Azure Web PubSub ke server aplikasi sebagai peran primer.
Selain itu, karena sifat koneksi WebSocket (koneksi yang panjang), klien akan mengalami penurunan koneksi saat terjadi bencana dan failover. Anda harus menangani kasus-kasus seperti itu di sisi klien untuk membuatnya transparan kepada pelanggan akhir Anda. Misalnya, sambungkan kembali setelah koneksi ditutup.
Arsitektur yang tersedia tinggi untuk pola klien-klien
Untuk pola klien-klien, saat ini belum dimungkinkan untuk mendukung pemulihan bencana zero-down-time menggunakan beberapa instans. Jika Anda memiliki persyaratan ketersediaan tinggi, pertimbangkan untuk menggunakan replikasi geografis.
Cara menguji failover
Ikuti langkah-langkah untuk memicu failover:
- Di tab Jaringan untuk sumber daya utama di portal, nonaktifkan akses jaringan publik. Jika sumber daya mengaktifkan jaringan privat, gunakan aturan kontrol akses untuk menolak semua lalu lintas.
- Mulai ulang sumber daya utama.
Langkah berikutnya
Dalam artikel ini, Anda telah mempelajari cara mengonfigurasi aplikasi Anda untuk mencapai ketahanan layanan Web PubSub.
Gunakan sumber daya ini untuk mulai membangun aplikasi Anda sendiri: