Performa dan pemecahan masalah untuk ekstraksi data SAP
Artikel ini adalah bagian dari seri artikel "SAP memperluas dan berinovasi data: Praktik terbaik".
- Mengidentifikasi sumber data SAP
- Pilih konektor SAP terbaik
- Performa dan pemecahan masalah untuk ekstraksi data SAP
- Keamanan integrasi data untuk SAP di Azure
- Arsitektur generik integrasi data SAP
Ada banyak cara untuk terhubung ke sistem SAP untuk integrasi data. Bagian di bawah ini menjelaskan pertimbangan dan rekomendasi umum dan khusus konektor.
Performa
Penting untuk mengonfigurasi pengaturan optimal untuk sumber dan target sehingga Anda dapat mencapai performa terbaik selama ekstraksi dan pemrosesan data.
Pertimbangan umum
- Pastikan parameter SAP yang benar diatur untuk koneksi bersamaan maksimum.
- Pertimbangkan untuk menggunakan jenis masuk Grup SAP untuk performa dan distribusi beban yang lebih baik.
- Pastikan bahwa komputer virtual runtime integrasi yang dihost sendiri (SHIR) berukuran memadai dan sangat tersedia.
- Saat Anda bekerja dengan himpunan data besar, periksa apakah konektor yang Anda gunakan menyediakan kemampuan partisi. Banyak konektor SAP mendukung kemampuan partisi dan paralelisasi untuk mempercepat beban data. Ketika Anda menggunakan metode ini, data dikemas ke dalam gugus yang lebih kecil yang dapat dimuat dengan menggunakan beberapa proses paralel. Untuk informasi selengkapnya, lihat dokumentasi khusus konektor.
Rekomendasi umum
Gunakan transaksi SAP RZ12 untuk memodifikasi nilai untuk koneksi bersamaan maks.
Parameter SAP untuk RFC - RZ12: Parameter berikut dapat membatasi jumlah panggilan RFC yang diizinkan untuk satu pengguna atau satu aplikasi, jadi pastikan bahwa pembatasan ini tidak menyebabkan hambatan.
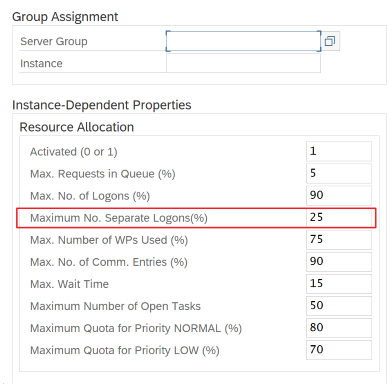
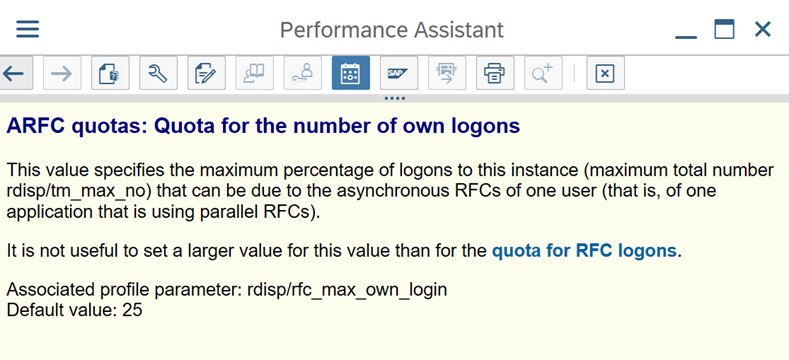
Koneksi ke SAP dengan menggunakan Grup Masuk: SHIR (runtime integrasi yang dihost sendiri) harus terhubung ke SAP dengan menggunakan Grup Masuk SAP (melalui server pesan) dan bukan ke server aplikasi tertentu untuk memastikan distribusi beban kerja di semua server aplikasi yang tersedia.
Catatan
Kluster Spark aliran data dan SHIR sangat kuat. Banyak aktivitas penyalinan SAP internal, misalnya 16, dapat dipicu dan dijalankan. Tetapi jika nomor koneksi bersamaan server SAP kecil, misalnya 8, perf membaca data dari sisi SAP.
Mulailah dengan VM 4vCPU dan 16 GB untuk SHIR. Langkah-langkah berikut menunjukkan koneksi proses kerja dialog di SAP dengan SHIR.
- Periksa apakah pelanggan menggunakan komputer fisik yang buruk untuk mengatur dan menginstal SHIR untuk menjalankan salinan SAP internal.
- Buka portal Azure Data Factory dan temukan layanan tertaut SAP CDC terkait yang digunakan dalam aliran data. Periksa nama SHIR yang dirujuk.
- Periksa pengaturan CPU, memori, jaringan, dan disk komputer fisik tempat SHIR diinstal.
- Periksa berapa banyak
diawp.exeyang berjalan pada mesin SHIR. Seseorangdiawp.exedapat menjalankan satu aktivitas salin. Jumlahdiawp.exedidasarkan pada pengaturan CPU, memori, jaringan, dan disk komputer.
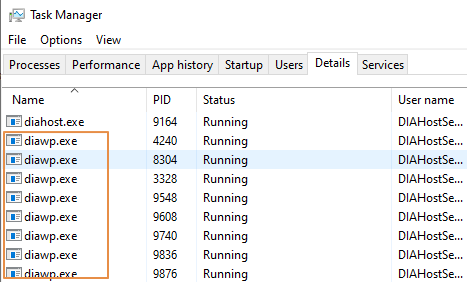
Jika Anda ingin menjalankan beberapa partisi secara paralel pada SHIR pada saat yang sama, gunakan komputer virtual yang kuat untuk mengatur SHIR. Atau gunakan peluasan skala dengan menggunakan fitur ketersediaan tinggi dan skalabilitas SHIR untuk memiliki beberapa simpul. Untuk informasi selengkapnya, lihat Ketersediaan dan skalabilitas tinggi.
Partisi
Bagian berikut menjelaskan proses partisi untuk konektor SAP CDC. Prosesnya sama untuk konektor SAP Table dan SAP BW Open Hub.

Penskalan dapat dilakukan pada IR yang dihost sendiri atau runtime integrasi Azure tergantung pada persyaratan performa Anda. Tinjau konsumsi CPU SHIR untuk melihat metrik untuk membantu Anda memutuskan pendekatan penskalaan Anda. SHIR dapat diskalakan secara vertikal atau horizontal berdasarkan kebutuhan Anda. Kami menyarankan agar Anda menyebarkan Runtime integrasi Azure di SKU yang lebih rendah. Tingkatkan skala untuk memenuhi persyaratan performa Anda sebagaimana ditentukan melalui pengujian beban, daripada memulai di ujung yang lebih tinggi yang tidak perlu.
Catatan
Jika Anda mencapai kapasitas 70%, tingkatkan atau peluasan skala untuk SHIR.

Partisi berguna untuk beban penuh awal atau besar dan biasanya tidak diperlukan untuk pemuatan delta. Jika Anda tidak menentukan partisi, secara default, 1 "produsen" dalam sistem SAP (biasanya satu proses batch) mengambil data sumber ke dalam antrean data operasional (ODQ), dan SHIR mengambil data dari ODQ. Secara default, SHIR menggunakan empat utas untuk mengambil data dari ODQ, sehingga kemungkinan empat proses dialog ditempati di SAP pada saat itu.
Ide pemartisian adalah untuk membagi himpunan data awal yang besar menjadi beberapa subset terputus-putus yang idealnya sama dalam ukuran dan yang dapat diproses secara paralel. Metode ini mengurangi waktu yang diperlukan untuk menghasilkan data dari tabel sumber ke ODQ dengan cara linier. Metode ini mengasumsikan bahwa ada sumber daya yang cukup di sisi SAP untuk menangani beban.
Catatan
- Jumlah partisi yang dijalankan secara paralel dibatasi oleh jumlah inti driver di Runtime integrasi Azure. Resolusi untuk batasan ini saat ini sedang berlangsung.
- Setiap unit atau paket dalam transaksi SAP ODQMON adalah satu file di folder penahapan.
Pertimbangan desain saat menjalankan alur menggunakan CDC
Periksa SAP ke durasi tahap.
Periksa performa runtime di sink.
Pertimbangkan untuk menggunakan fitur partisi untuk meningkatkan performa untuk throughput yang lebih baik.
Jika durasi SAP ke tahap lambat, pertimbangkan untuk mengubah ukuran SHIR ke spesifikasi yang lebih tinggi.
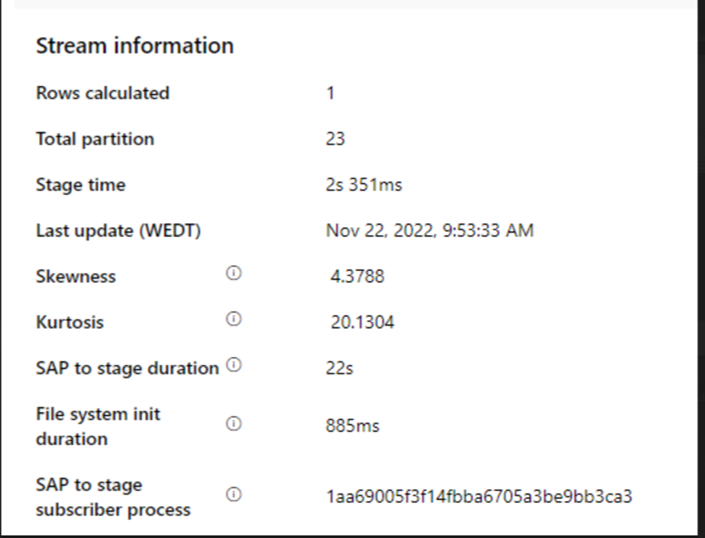
Periksa apakah waktu pemrosesan sink terlalu lambat.
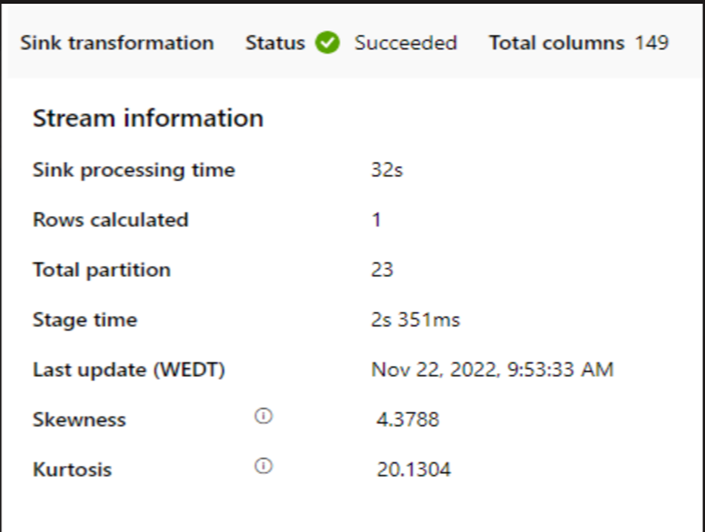
Jika kluster kecil digunakan untuk menjalankan aliran data pemetaan, itu dapat memengaruhi performa di sink. Gunakan kluster besar, misalnya 16 + 256 core, sehingga perf membaca data dari tahap dan menulis ke dalam sink.
Untuk volume data besar, sebaiknya partisi beban untuk menjalankan pekerjaan paralel, tetapi jaga jumlah partisi kurang dari atau sama dengan inti runtime integrasi Azure, juga disebut inti kluster Spark.
Gunakan tab Optimalkan untuk menentukan partisi. Anda dapat menggunakan partisi sumber di konektor CDC.
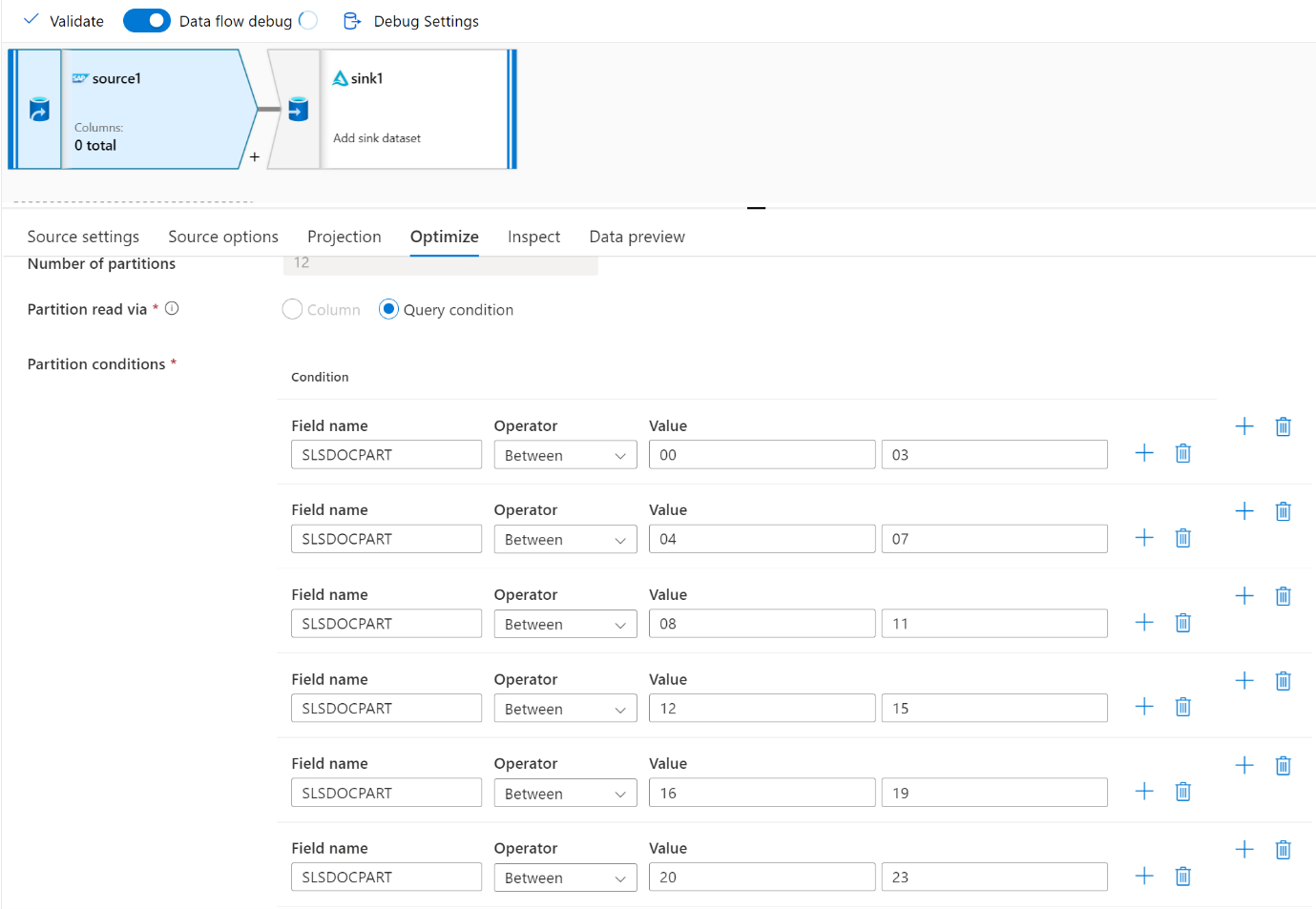
Catatan
- Ada korelasi langsung antara jumlah partisi dengan inti SHIR dan simpul Runtime integrasi Azure.
- Konektor SAP CDC terdaftar sebagai jenis pelanggan Odata "Akses Odata untuk Penyediaan Data Operasional" di bawah ODQMON dalam sistem SAP.
Pertimbangan desain saat menggunakan konektor Tabel
- Optimalkan partisi untuk performa yang lebih baik.
- Pertimbangkan tingkat paralelisme dari Tabel SAP.
- Pertimbangkan desain file tunggal untuk sink target.
- Tolok ukur throughput saat Anda menggunakan volume data besar.
Rekomendasi desain saat menggunakan konektor Tabel
Partisi: Saat Anda mempartisi di konektor Tabel SAP, itu membagi satu pernyataan pilih yang mendasar menjadi beberapa dengan menggunakan klausa di mana berada di bidang yang sesuai, misalnya bidang dengan kardinalitas tinggi. Jika tabel SAP Anda memiliki volume data yang besar, aktifkan partisi untuk membagi data menjadi partisi yang lebih kecil. Cobalah untuk mengoptimalkan jumlah partisi (parameter
maxPartitionsNumber) sehingga partisi cukup kecil untuk menghindari cadangan memori di SAP tetapi cukup besar untuk mempercepat ekstraksi.Paralelisme: Tingkat paralelisme salinan (parameter
parallelCopies) bekerja bersama dengan partisi dan menginstruksikan SHIR untuk melakukan panggilan RFC paralel ke sistem SAP. Misalnya, jika Anda mengatur parameter ini ke 4, layanan secara bersamaan menghasilkan dan menjalankan empat kueri berdasarkan opsi dan pengaturan partisi yang Anda tentukan. Setiap kueri mengambil sebagian data dari tabel SAP Anda.Untuk hasil optimal, jumlah partisi harus kelipatan dari jumlah tingkat paralelisme salinan.
Saat Anda menyalin data dari Tabel SAP ke sink biner, jumlah paralel aktual secara otomatis disesuaikan berdasarkan jumlah memori yang tersedia di SHIR. Catat ukuran VM SHIR untuk setiap siklus pengujian, tingkat paralelisme salinan, dan jumlah partisi. Amati performa VM SHIR, performa sistem SAP sumber, dan tingkat paralelisme yang diinginkan vs. yang sebenarnya. Gunakan proses berulang untuk mengidentifikasi pengaturan optimal dan ukuran ideal untuk VM SHIR. Pertimbangkan semua alur penyerapan yang secara bersamaan memuat data dari satu atau beberapa sistem SAP.
Perhatikan jumlah panggilan RFC yang diamati ke SAP terhadap tingkat paralelisme yang dikonfigurasi. Jika jumlah panggilan RFC ke SAP kurang dari tingkat paralelisme, verifikasi bahwa VM SHIR memiliki cukup memori dan sumber daya CPU yang tersedia. Pilih komputer virtual yang lebih besar jika perlu. Sistem SAP sumber dikonfigurasi untuk membatasi jumlah koneksi paralel. Untuk informasi selengkapnya, lihat bagian Rekomendasi umum di artikel ini.
Jumlah file: Saat Anda menyalin data ke penyimpanan data berbasis file dan sink yang ditargetkan dikonfigurasi menjadi folder, beberapa file dihasilkan secara default. Jika Anda mengatur
fileNameproperti di sink, data ditulis ke satu file. Disarankan agar Anda menulis ke folder sebagai beberapa file karena mendapatkan throughput tulis yang lebih tinggi dibandingkan dengan menulis ke satu file.Tolok ukur performa: Sebaiknya gunakan latihan tolok ukur performa untuk menyerap data dalam jumlah besar. Metode ini bervariasi parameter, seperti partisi, tingkat paralelisme, dan jumlah file untuk menentukan pengaturan optimal untuk arsitektur, volume, dan jenis data yang diberikan. Kumpulkan data dari pengujian dalam format berikut.


Pemecahan Masalah
Untuk ekstraksi yang lambat atau gagal dari sistem SAP, gunakan log SAP dari SM37 dan cocokkan dengan pembacaan di Data Factory.
Jika hanya satu pekerjaan batch yang dipicu, atur partisi sumber SAP untuk memiliki peningkatan performa dalam aliran data pemetaan di Data Factory. Untuk informasi selengkapnya, lihat langkah 6 di Memetakan properti aliran data.
Jika beberapa pekerjaan batch dipicu dalam sistem SAP dan ada perbedaan signifikan antara setiap waktu mulai pekerjaan batch, ubah ukuran Runtime integrasi Azure. Saat Anda meningkatkan jumlah simpul driver di Runtime integrasi Azure, paralelisme pekerjaan batch di sisi SAP meningkat.
Catatan
Jumlah maksimum simpul driver untuk runtime integrasi Azure adalah 16. Setiap simpul driver hanya dapat memicu satu proses batch.
Periksa log di SHIR. Untuk melihat log, buka SHIR VM. Buka Aplikasi penampil > Peristiwa dan log > layanan Runtime integrasi Konektor > .
Untuk mengirim log ke dukungan, buka SHIR VM. Buka manajer > konfigurasi Integration Runtime Log Pengiriman Diagnostik>. Tindakan ini mengirimkan log dari tujuh hari terakhir dan memberi Anda ID laporan. Anda memerlukan ID laporan ini dan RunId dari eksekusi Anda. Dokumentasikan ID laporan untuk referensi di masa mendatang.
Saat Anda menggunakan konektor SAP CDC dalam skenario SLT:
Pastikan prasyarat terpenuhi. Peran diperlukan untuk pengguna Transformasi Lanskap SAP (SLT), misalnya ADFSLTUSER dalam sistem OLTP atau ECC agar replikasi SLT berfungsi. Untuk informasi selengkapnya, lihat Otorisasi dan peran apa yang diperlukan.
Jika kesalahan terjadi dalam skenario SLT, lihat rekomendasi untuk analisis. Isolasi dan uji skenario dalam solusi SAP terlebih dahulu. Misalnya, uji di luar Data Factory dengan menjalankan program pengujian yang disediakan oleh SAP
RODPS_REPL_TESTdi SE38. Jika masalahnya ada di sisi SAP, Anda mendapatkan kesalahan yang sama saat menggunakan laporan. Anda dapat menganalisis ekstraksi data di SAP dengan menggunakan kodeODQMONtransaksi .Jika replikasi berfungsi saat Anda menggunakan laporan pengujian ini, tetapi tidak dengan Data Factory, hubungi dukungan Azure atau Data Factory.
Contoh berikut menunjukkan laporan untuk
RODPS_REPL_TESTdi SE38: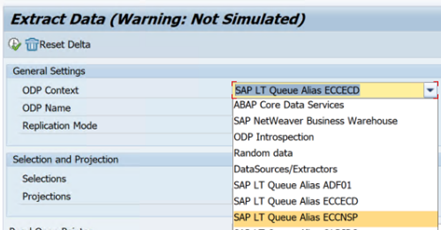
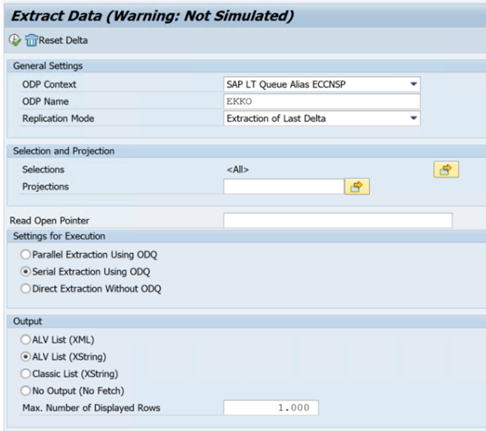

Contoh berikut menunjukkan kode
ODQMONtransaksi :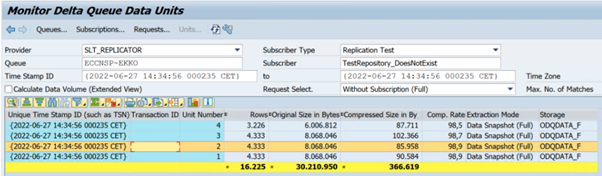
Saat layanan tertaut Data Factory tersambung ke sistem SLT, layanan tersebut tidak menampilkan ID transfer massal SLT saat Anda merefresh bidang Konteks .
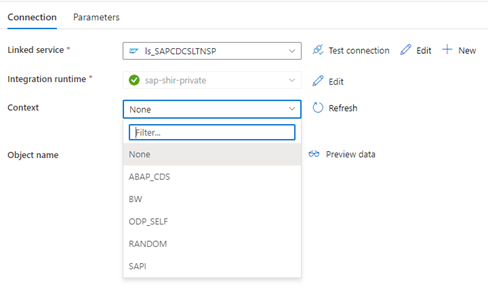
Untuk menjalankan skenario replikasi ODP/ODQ untuk Server Replikasi SAP LT, aktifkan implementasi add-in bisnis (BAdI) berikut.
Badi:
BADI_ODQ_QUEUE_MODELImplementasi peningkatan:
ODQ_ENH_SLT_REPLICATIONDalam transaksi LTRC, buka tab Fungsi Ahli dan pilih Aktifkan/Nonaktifkan Implementasi BAdI untuk mengaktifkan implementasi.
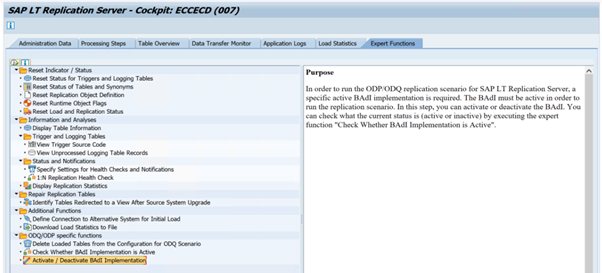
Pilih Ya.
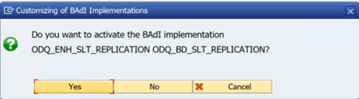
Di folder fungsi khusus ODQ/ODP , pilih Periksa Apakah Implementasi BAdI Aktif.

Dialog menunjukkan aktivitas program.
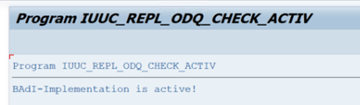
Reset langganan. Untuk memulai dengan ekstraksi baru atau menghentikan data replikasi, hapus langganan di ODQMON. Tindakan ini juga menghapus entri dari LTRC. Setelah mengatur ulang langganan, mungkin perlu beberapa menit sebelum Anda melihat efeknya di LTRC. Jadwalkan pekerjaan housekeeping Penyediaan Data Operasional (ODP) untuk menjaga antrean delta tetap bersih, misalnya
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transaksi DHCDCMON). Pada S/4HANA 1909, SAP mereplikasi data dari tampilan CDS yang menggunakan pemicu berbasis data alih-alih kolom tanggal. Konsepnya mirip dengan SLT, tetapi alih-alih menggunakan transaksi LTRC untuk memantaunya, Anda menggunakan transaksi DHCDCMON.
Pemecahan masalah SLT
Server Replikasi SLT menyediakan replikasi data real-time dari sumber SAP dan/atau sumber non-SAP ke target SAP dan/atau target non-SAP. Ada tiga jenis toolset untuk memantau ekstraksi dari SLT ke Azure.
- ODQMON adalah alat pemantauan keseluruhan untuk ekstraksi data. Mulai analisis dengan ODQMON untuk melacak inkonsistensi data, analisis performa awal, dan buka permintaan langganan dan ekstraksi.
- LTRC adalah transaksi yang digunakan untuk memeriksa analisis performa. Ini berguna jika Anda memiliki masalah replikasi data dari sistem sumber ke ODP karena Anda dapat memantau aliran data dan menemukan inkonsistensi.
- SM37 menyediakan pemantauan terperinci dari setiap langkah ekstraksi SLT.
Housekeeping normal harus dilakukan menggunakan ODQMON di mana Anda dapat mengelola langganan secara langsung dan Anda tidak boleh menggunakan LTRC untuk hal yang sama.
Anda mungkin mengalami masalah saat mengekstrak data dari SLT, seperti:
Ekstraksi tidak berjalan. Periksa apakah koneksi SAP CDC membuat koneksi di ODQMON, dan periksa apakah langganan ada.
Inkonsistensi data. Periksa ODQMON untuk melihat permintaan data individual dan konfirmasikan bahwa Anda dapat melihat data di sana. Jika Anda dapat melihat data di ODQMON tetapi tidak di Azure Synapse atau Data Factory, penyelidikan harus terjadi di sisi Azure. Jika Anda tidak dapat melihat data di ODQMON, lakukan analisis kerangka kerja SLT dengan menggunakan LTRC.
Masalah performa. Ekstraksi data adalah pendekatan dua langkah. Pertama, SLT membaca data dari sistem sumber dan mentransfernya ke ODP. Kedua, konektor SAP CDC mengambil data dari ODP dan mentransfernya ke penyimpanan data yang dipilih. Transaksi LTRC memungkinkan Anda menganalisis bagian pertama dari proses ekstraksi. Untuk menganalisis ekstraksi data dari ODP ke Azure, gunakan ODQMON dan Data Factory atau alat pemantauan Synapse.
Catatan
Untuk informasi selengkapnya, lihat sumber daya berikut:
Performa SLT
Dalam mode pemuatan awal (ODPSLT), ada tiga langkah untuk mengekstrak data dari SLT ke ODP:
- Membuat objek migrasi. Proses ini hanya membutuhkan waktu beberapa detik.
- Akses perhitungan paket yang membagi tabel sumber menjadi potongan yang lebih kecil. Langkah ini tergantung pada mode beban awal yang Anda pilih selama konfigurasi SLT dan ukuran tabel. Opsi yang dioptimalkan sumber daya disarankan.
- Beban data mentransfer data dari sistem sumber ke ODP.
Setiap langkah dikendalikan oleh pekerjaan latar belakang. Anda dapat menggunakan transaksi SM37 dan LTRC untuk memantau durasi. Jika sistem Anda terlalu banyak digunakan, pekerjaan latar belakang mungkin dimulai nanti karena tidak ada cukup proses kerja batch gratis. Ketika tugas menganggur, performa akan menderita.
Jika perhitungan rencana akses membutuhkan waktu lama dan mode beban awal Anda diatur ke "performa dioptimalkan", ubah ke "sumber daya yang dioptimalkan" dan jalankan kembali ekstraksi. Jika beban data membutuhkan waktu lama, tingkatkan jumlah utas paralel dalam konfigurasi.
Jika Anda menggunakan arsitektur mandiri untuk replikasi SLT (server replikasi SLT khusus), throughput jaringan antara sistem sumber dan server replikasi mungkin memengaruhi performa ekstraksi.
Untuk replikasi:
- Pastikan Anda memiliki cukup pekerjaan transfer data yang tidak dicadangkan untuk beban awal.
- Periksa apakah Anda tidak memiliki rekaman tabel pengelogan yang tidak diproscessikan dalam statistik beban.
- Pastikan bahwa opsi replikasi diatur ke real-time.
Pengaturan replikasi tingkat lanjut tersedia di LTRS. Untuk informasi selengkapnya, lihat panduan pemecahan masalah SLT.
Rilis SAP yang berbeda memiliki antarmuka pengguna LTRC yang berbeda. Cuplikan layar berikut menunjukkan halaman yang sama untuk dua rilis yang berbeda.
SAP S/4HANA:
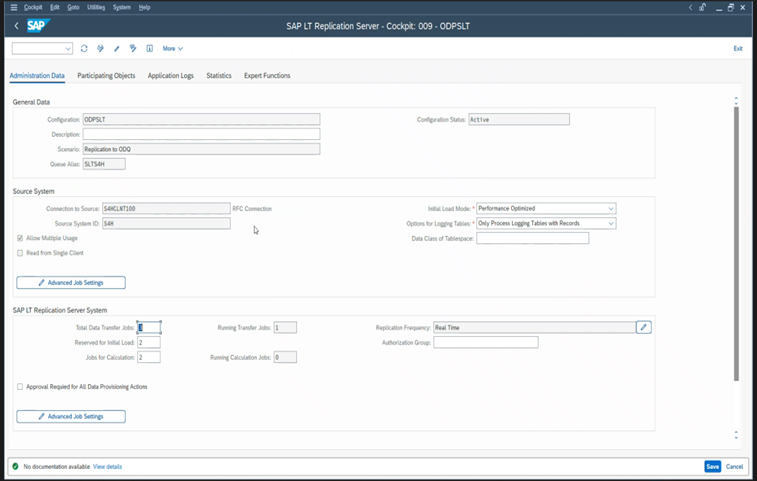
SAP ECC:



Monitor
Untuk informasi tentang memantau ekstraksi data SAP, lihat sumber daya ini:
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk