Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Cosmos DB dapat menyimpan data berukuran terabyte. Anda dapat melakukan migrasi data skala besar untuk memindahkan beban kerja produksi ke Azure Cosmos DB. Artikel ini menjelaskan tantangan dalam memindahkan data skala besar ke Azure Cosmos DB serta memperkenalkan Anda dengan alat yang membantu mengatasi tantangan dan memigrasikan data ke Azure Cosmos DB. Dalam studi kasus ini, pelanggan menggunakan API Azure Cosmos DB untuk NoSQL.
Sebelum memigrasikan seluruh beban kerja ke Azure Cosmos DB, Anda dapat memigrasikan subset data untuk validasi beberapa aspek seperti pilihan kunci partisi, performa kueri, dan pemodelan data. Setelah validasi bukti konsep, Anda dapat memindahkan seluruh beban kerja ke Azure Cosmos DB.
Alat untuk migrasi data
Strategi migrasi Azure Cosmos DB saat ini berbeda berdasarkan pilihan API dan ukuran data. Untuk memigrasikan himpunan data yang lebih kecil – untuk memvalidasi pemodelan data, performa kueri, pilihan kunci partisi, dll. – Anda dapat menggunakan konektor Azure Cosmos DB Azure Data Factory. Jika terbiasa dengan Spark, Anda juga dapat memilih untuk menggunakan konektor Azure Cosmos DB Spark untuk memigrasikan data.
Tantangan untuk migrasi skala besar
Alat yang ada untuk memigrasikan data ke Azure Cosmos DB memiliki beberapa batasan yang menjadi begitu nyata dalam skala besar:
Kemampuan peluasan skala terbatas: Agar bisa memigrasikan terabyte data ke Azure Cosmos DB secepat mungkin, dan untuk secara efektif mengonsumsi seluruh throughput yang disediakan, klien migrasi harus memiliki kemampuan untuk meluaskan skala tanpa batas.
Kurangnya pelacakan kemajuan dan pembuatan titik pemeriksaan: Penting untuk melacak kemajuan migrasi dan memiliki titik pemeriksaan saat memigrasikan kumpulan data besar. Jika tidak, kesalahan apa pun yang terjadi selama migrasi menghentikan migrasi, dan Anda harus memulai proses dari awal. Tentu menjadi tidak produktif untuk memulai kembali seluruh proses migrasi saat 99% telah selesai.
Tidak adanya dead letter queue: Dalam kumpulan data besar, di beberapa kasus mungkin ada masalah dengan bagian-bagian data sumber. Selain itu, mungkin ada masalah sementara dengan klien atau jaringan. Salah satu kasus ini seharusnya tidak menyebabkan seluruh migrasi gagal. Meskipun sebagian besar alat migrasi memiliki kemampuan coba ulang yang kuat untuk melindungi dari masalah yang terjadi sesekali, itu tidak selalu cukup. Misalnya, jika kurang dari 0,01% dokumen data sumber berukuran lebih besar dari 2 MB, itu menyebabkan penulisan dokumen gagal di Azure Cosmos DB. Idealnya, alat migrasi berguna untuk mempertahankan dokumen 'gagal' ini ke antrean surat mati lainnya, yang dapat diproses pasca migrasi.
Banyak dari batasan ini yang diperbaiki untuk alat seperti Azure Data Factory, layanan Azure Data Migration.
Alat kustom dengan pustaka eksekutor massal
Tantangan yang dijelaskan di bagian sebelumnya, dapat diselesaikan dengan menggunakan alat kustom yang dapat dengan mudah diskalakan di beberapa instans dan tahan terhadap kegagalan sementara. Selain itu, alat kustom dapat menjeda dan melanjutkan migrasi di berbagai pos pemeriksaan. Azure Cosmos DB sudah menyediakan pustaka pelaksana massal yang menggabungkan beberapa fitur ini. Misalnya, pustaka pelaksana massal sudah memiliki fungsionalitas untuk menangani kesalahan sementara dan dapat meluaskan skala utas dalam satu simpul untuk mengonsumsi sekitar 500 K RUs per simpul. Pustaka pelaksana massal juga mempartisi kumpulan data sumber ke dalam kelompok-kelompok kecil yang dioperasikan secara mandiri sebagai bentuk checkpointing.
Alat kustom menggunakan perpustakaan eksekutor massal, mendukung peningkatan skala di beberapa klien, dan melacak kesalahan selama proses penyerapan. Untuk menggunakan alat ini, data sumber harus dipartisi ke dalam file yang berbeda di Azure Data Lake Storage (ADLS) sehingga berbagai pekerja migrasi dapat mengambil setiap file dan memasukannya ke Azure Cosmos DB. Alat kustom menggunakan koleksi terpisah, yang menyimpan metadata tentang kemajuan migrasi untuk setiap file sumber di ADLS dan melacak kesalahan apa pun yang terkait dengannya.
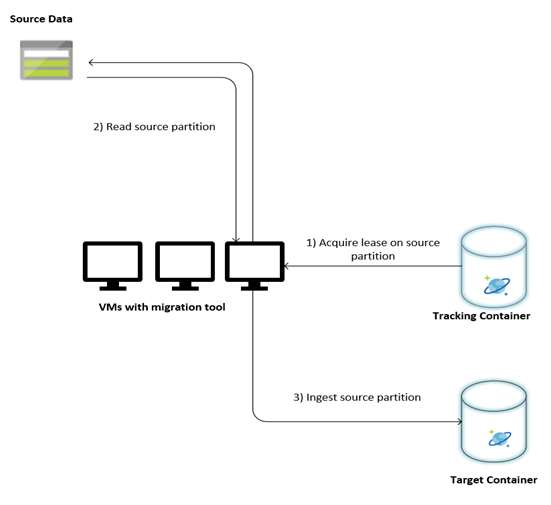
Gambar berikut menjelaskan proses migrasi menggunakan alat kustom ini. Alat ini berjalan pada satu set komputer virtual, dan setiap komputer virtual meminta pengumpulan pelacakan di Azure Cosmos DB untuk memperoleh sewa pada salah satu partisi data sumber. Setelah ini selesai, partisi data sumber dibaca oleh alat dan dimasukkan ke Azure Cosmos DB dengan menggunakan pustaka eksekutor massal. Selanjutnya, pengumpulan pelacakan diperbarui untuk merekam kemajuan pemasukan data dan kesalahan yang ditemukan. Setelah partisi data diproses, alat ini mencoba untuk mengueri partisi sumber berikutnya yang tersedia. Alat ini terus memproses partisi sumber berikutnya sampai semua data dimigrasikan. Kode sumber untuk alat ini tersedia di repo pemasukan massal Azure Cosmos DB.
Kumpulan pelacakan berisi dokumen seperti yang diperlihatkan dalam contoh berikut. Anda akan melihat dokumen tersebut untuk setiap partisi dalam data sumber. Setiap dokumen berisi metadata untuk partisi data sumber seperti lokasi, status migrasi, dan kesalahan (jika ada):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Prasyarat untuk migrasi data
Sebelum migrasi data dimulai, ada beberapa prasyarat yang perlu dipertimbangkan:
Perkirakan ukuran data:
Ukuran data sumber mungkin tidak benar-benar terpetakan ke ukuran data di Azure Cosmos DB. Beberapa dokumen sampel dari sumber dapat disisipkan untuk memeriksa ukuran data mereka di Azure Cosmos DB. Tergantung ukuran dokumen sampel, ukuran total data di Azure Cosmos DB pasca migrasi dapat diperkirakan.
Misalnya, jika setiap dokumen setelah migrasi di Azure Cosmos DB sekitar 1 KB dan jika ada sekitar 60 miliar dokumen dalam kumpulan data sumber, artinya perkiraan ukuran di Azure Cosmos DB akan mendekati 60 TB.
Siapkan terlebih dahulu kontainer dengan RU yang cukup:
Meskipun Azure Cosmos DB menskalakan penyimpanan secara otomatis, tidak disarankan untuk memulai dari ukuran kontainer terkecil. Kontainer yang lebih kecil memiliki ketersediaan throughput lebih rendah, sehingga migrasi akan memakan waktu lebih lama untuk diselesaikan. Sebaliknya, berguna untuk membuat kontainer dengan ukuran data akhir (seperti yang diperkirakan pada langkah sebelumnya) dan memastikan bahwa beban kerja migrasi sepenuhnya mengkonsumsi throughput yang disediakan.
Pada langkah sebelumnya, karena ukuran data diperkirakan sekitar 60 TB, kontainer setidaknya 2,4 M RU diperlukan untuk mengakomodasi seluruh himpunan data.
Perkirakan kecepatan migrasi:
Dengan asumsi bahwa beban kerja migrasi dapat mengonsumsi seluruh throughput yang disediakan, maka throughput tersebut akan memberikan estimasi kecepatan migrasi. Melanjutkan contoh sebelumnya, lima RU diperlukan untuk menulis dokumen 1 KB ke AZURE Cosmos DB API untuk akun NoSQL. 2,4 juta RUs akan mengizinkan transfer 480.000 dokumen per detik (atau 480 MB/s). Ini berarti bahwa migrasi lengkap 60 TB membutuhkan waktu 125.000 detik atau sekitar 34 jam.
Jika ingin migrasi selesai dalam sehari, Anda harus meningkatkan throughput yang disediakan menjadi 5 juta RUs.
Matikan pengindeksan:
Karena migrasi harus diselesaikan sesegera mungkin, disarankan untuk meminimalkan waktu dan RU yang dihabiskan untuk membuat indeks untuk setiap dokumen yang diserap. Azure Cosmos DB secara otomatis mengindeks semua properti, ada baiknya untuk meminimalkan pengindeksan ke beberapa istilah yang dipilih atau menonaktifkannya sepenuhnya selama migrasi. Anda dapat menonaktifkan kebijakan pengindeksan kontainer dengan mengubah indexingMode menjadi tidak ada seperti yang ditunjukkan di sini:
{
"indexingMode": "none"
}
Setelah migrasi selesai, Anda dapat memperbarui pengindeksan.
Proses migrasi
Setelah prasyarat dipenuhi, Anda bisa melakukan migrasi data dengan langkah-langkah berikut:
Pertama-tama impor data dari sumber ke Azure Blob Storage. Untuk meningkatkan kecepatan migrasi, sangat membantu untuk memparallelkan di berbagai partisi sumber yang berbeda. Sebelum memulai migrasi, kumpulan data sumber harus dipartisi ke dalam file dengan ukuran sekitar 200 MB.
Perpustakaan eksekutor massal dapat meningkatkan skala untuk mengonsumsi 500.000 RUs dalam satu VM klien. Karena throughput yang tersedia adalah 5 juta RU, 10 VM Ubuntu 16.04 (Standard_D32_v3) harus disediakan di wilayah yang sama tempat database Azure Cosmos DB Anda berada. Anda harus menyiapkan VM ini dengan alat migrasi dan file pengaturannya.
Jalankan langkah antrean pada salah satu komputer virtual klien. Langkah ini membuat koleksi pelacakan, yang memindai kontainer ADLS dan membuat dokumen pelacakan kemajuan untuk setiap file partisi himpunan data sumber.
Selanjutnya, jalankan langkah impor pada semua VM klien. Setiap klien dapat mengambil kepemilikan pada partisi sumber dan memasukan datanya ke Azure Cosmos DB. Setelah selesai dan statusnya diperbarui dalam koleksi pelacakan, klien kemudian dapat meminta partisi sumber berikutnya yang tersedia dalam koleksi pelacakan.
Proses ini berlanjut sampai seluruh rangkaian partisi sumber dimasukkan. Setelah semua partisi sumber diproses, alat harus dijalankan ulang pada mode koreksi kesalahan di koleksi pelacakan yang sama. Langkah ini diperlukan untuk mengidentifikasi partisi sumber yang harus diolah ulang karena kesalahan.
Beberapa kesalahan ini bisa disebabkan oleh dokumen yang salah dalam data sumber. Kesalahan ini harus diidentifikasi dan diperbaiki. Selanjutnya, Anda harus menjalankan kembali langkah impor pada partisi yang gagal untuk mengimpor ulang mereka.
Setelah migrasi selesai, Anda dapat memvalidasi bahwa jumlah dokumen di Azure Cosmos DB sama dengan jumlah dokumen dalam database sumber. Dalam contoh ini, ukuran total di Azure Cosmos DB ternyata 65 terabyte. Pasca migrasi, pengindeksan dapat diaktifkan secara selektif dan RU dapat diturunkan ke tingkat yang diperlukan oleh operasi beban kerja.
Langkah berikutnya
- Pelajari selengkapnya dengan mencoba aplikasi contoh yang menggunakan pustaka pelaksana massal di .NET dan Java.
- Pustaka pelaksana massal diintegrasikan ke dalam konektor Azure Cosmos DB Spark. Untuk mempelajari lebih lanjut, lihat artikel konektor Azure Cosmos DB Spark.
- Hubungi tim produk Azure Cosmos DB dengan membuka tiket dukungan di bawah jenis masalah "Penasihat Umum" dan subjenis masalah "Migrasi besar (TB+)" untuk bantuan lebih lanjut terkait migrasi skala besar.
- Mencoba melakukan perencanaan kapasitas untuk migrasi ke Azure Cosmos DB? Anda dapat menggunakan informasi tentang kluster database Anda yang ada saat ini untuk membuat perencanaan kapasitas.
- Jika Anda hanya mengetahui jumlah vCore dan server di kluster database yang ada, baca tentang memperkirakan unit permintaan menggunakan vCore atau vCPU
- Jika Anda mengetahui rasio permintaan umum untuk beban kerja database Anda saat ini, baca memperkirakan unit permintaan menggunakan perencana kapasitas Azure Cosmos DB