Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Data Lake Storage adalah solusi data lake yang sangat dapat diskalakan dan hemat biaya untuk analitik big data. Ini menggabungkan kekuatan sistem file berkinerja tinggi dengan skala besar dan ekonomi untuk membantu Anda mengurangi waktu Anda untuk wawasan. Data Lake Storage Gen2 memperluas kemampuan Azure Blob Storage dan dioptimalkan untuk beban kerja analitik.
Azure Data Explorer terintegrasi dengan Azure Blob Storage dan Azure Data Lake Storage (Gen1 dan Gen2), menyediakan akses cepat, cache, dan terindeks ke data yang disimpan di penyimpanan eksternal. Anda dapat menganalisis dan mengkueri data tanpa penyerapan sebelumnya ke Azure Data Explorer. Anda juga dapat mengkueri seluruh data eksternal yang diserap dan tidak diserap secara bersamaan. Untuk informasi selengkapnya, lihat cara membuat tabel eksternal menggunakan wizard antarmuka pengguna web Azure Data Explorer. Untuk gambaran umum singkat, lihat tabel eksternal.
Petunjuk / Saran
Performa kueri terbaik harus menelan data ke Azure Data Explorer. Kemampuan untuk mengkueri data eksternal tanpa penyerapan sebelumnya hanya boleh digunakan untuk data historis atau data yang jarang dikueri. Optimalkan performa kueri data eksternal Anda untuk hasil terbaik.
Membuat tabel eksternal
Katakanlah Anda memiliki banyak file CSV yang berisi info historis tentang produk yang disimpan di gudang, dan Anda ingin melakukan analisis cepat untuk menemukan lima produk paling populer dari tahun lalu. Dalam contoh ini, file CSV terlihat seperti:
| Tanda Waktu | ProductId | Deskripsi Produk |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD Floppy Disk |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
File disimpan di penyimpanan mycompanystorage Azure Blob di bawah kontainer bernama archivedproducts, dipartisi berdasarkan tanggal:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Untuk menjalankan kueri KQL pada file CSV ini secara langsung, gunakan .create external table perintah untuk menentukan tabel eksternal di Azure Data Explorer. Untuk informasi selengkapnya tentang opsi perintah buat tabel eksternal, lihat perintah tabel eksternal.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Tabel eksternal sekarang terlihat di panel kiri UI web Azure Data Explorer:
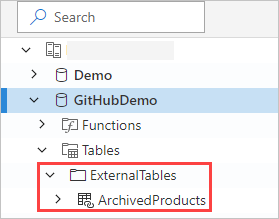
Izin tabel eksternal
Tinjau izin tabel berikut:
- Pengguna database dapat membuat tabel eksternal. Pembuat tabel secara otomatis menjadi administrator tabel.
- Administrator kluster, database, atau tabel dapat mengedit tabel yang sudah ada.
- Setiap pengguna atau pembaca database dapat mengkueri tabel eksternal.
Mengkueri tabel eksternal
Setelah tabel eksternal ditentukan, external_table() fungsi dapat digunakan untuk merujuknya. Kueri lainnya adalah Bahasa Kueri Kusto standar.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Mengkueri data eksternal dan yang diserap bersama-sama
Anda bisa mengkueri tabel eksternal dan tabel data yang diserap dalam kueri yang sama. Anda dapat join atau union tabel eksternal dengan data lain dari Azure Data Explorer, server SQL, atau sumber lainnya.
let( ) statement Gunakan untuk menetapkan nama singkat ke referensi tabel eksternal.
Dalam contoh di bawah ini, Produk adalah tabel data yang diserap dan ArchivedProducts adalah tabel eksternal yang telah kami tentukan:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Mengkueri format data hierarkis
Azure Data Explorer memungkinkan kueri format hierarkis, seperti JSON, , ParquetAvro, dan ORC. Untuk memetakan skema data hierarkis ke skema tabel eksternal (jika berbeda), gunakan perintah pemetaan tabel eksternal. Misalnya, jika Anda ingin mengkueri file log JSON dengan format berikut:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
Definisi tabel eksternal terlihat seperti ini:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Tentukan pemetaan JSON yang memetakan bidang data ke bidang definisi tabel eksternal:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Saat Anda mengkueri tabel eksternal, pemetaan dipanggil, dan data yang relevan dipetakan ke kolom tabel eksternal:
external_table('ApiCalls') | take 10
Untuk info selengkapnya tentang memetakan sintaksis, lihat memetakan data.
Kueri TaxiRides tabel eksternal di kluster bantuan
Gunakan kluster pengujian yang disebut bantuan untuk mencoba kemampuan Azure Data Explorer yang berbeda. Kluster bantuan berisi definisi tabel eksternal untuk himpunan data taksi Kota New York yang berisi miliaran tumpangan taksi.
Buat tabel eksternal TaxiRides
Bagian ini memperlihatkan kueri yang digunakan untuk membuat tabel eksternal TaxiRides di kluster bantuan . Karena Anda sudah membuat tabel ini, Anda dapat melewati bagian ini dan langsung masuk ke kueri data tabel eksternal TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Anda dapat menemukan tabel TaxiRides yang dibuat dengan melihat panel kiri antarmuka pengguna web Azure Data Explorer:
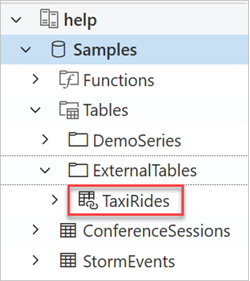
Kueri TaxiRides data tabel eksternal
Masuklah ke https://dataexplorer.azure.com/clusters/help/databases/Samples.
Kueri TaxiRides tabel eksternal tanpa pemartisian
Jalankan kueri ini pada tabel eksternal TaxiRides untuk menampilkan tumpangan untuk setiap hari dalam seminggu, di seluruh himpunan data.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Kueri ini memperlihatkan hari tersibuk dalam seminggu. Karena data tidak dipartisi, kueri mungkin membutuhkan waktu hingga beberapa menit untuk mengembalikan hasil.
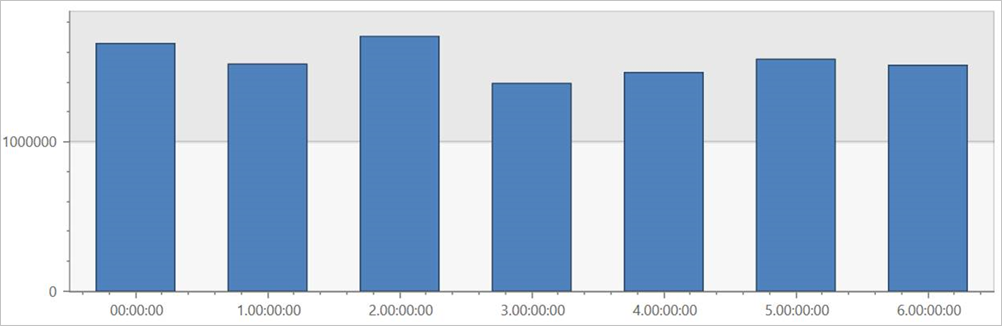
Kueri TaxiRides tabel eksternal dengan pemartisian
Jalankan kueri ini pada tabel eksternal TaxiRides untuk memperlihatkan jenis taksi (kuning atau hijau) yang digunakan pada Januari 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Kueri ini menggunakan pemartisian, yang mengoptimalkan waktu dan performa kueri. Kueri memfilter pada kolom yang dipartisi (pickup_datetime) dan mengembalikan hasil dalam beberapa detik.
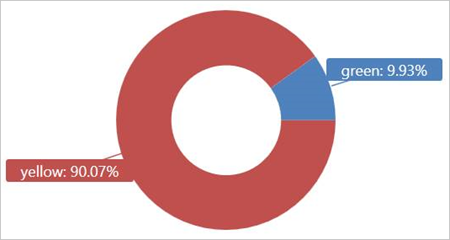
Anda dapat menulis kueri lain untuk dijalankan pada tabel eksternal TaxiRides dan mempelajari selengkapnya tentang data.
Mengoptimalkan performa kueri Anda
Optimalkan performa kueri Anda di lake dengan menggunakan praktik terbaik berikut untuk mengkueri data eksternal.
Format data
- Gunakan format kolom untuk kueri analitik, karena alasan berikut:
- Hanya kolom yang relevan dengan kueri yang dapat dibaca.
- Teknik pengodean kolom dapat mengurangi ukuran data secara signifikan.
- Azure Data Explorer mendukung format kolom Parquet dan ORC. Format parquet disarankan karena implementasi yang dioptimalkan.
Wilayah Azure
Periksa apakah data eksternal berada di wilayah Azure yang sama dengan kluster Azure Data Explorer Anda. Penyiapan ini mengurangi biaya dan waktu pengambilan data.
Ukuran file
Ukuran file optimal adalah ratusan Mb (hingga 1 GB) per file. Hindari banyak file kecil yang memerlukan overhead yang tidak diperlukan, seperti proses enumerasi file yang lebih lambat dan penggunaan format kolom yang terbatas. Jumlah file harus lebih besar dari jumlah inti CPU di kluster Azure Data Explorer Anda.
Kompresi
Gunakan kompresi untuk mengurangi jumlah data yang diambil dari penyimpanan jarak jauh. Untuk format Parquet, gunakan mekanisme kompresi Parquet internal yang memadatkan grup kolom secara terpisah, memungkinkan Anda membacanya secara terpisah. Untuk memvalidasi penggunaan mekanisme kompresi, periksa apakah file diberi nama sebagai berikut: < atau > dan bukan<>
Partisi
Atur data Anda menggunakan partisi "folder" yang memungkinkan kueri melewati jalur yang tidak relevan. Saat merencanakan pemartisian, pertimbangkan ukuran file dan filter umum dalam kueri Anda seperti tanda waktu atau ID penyewa.
Ukuran komputer virtual
Pilih SKU VM dengan lebih banyak inti dan throughput jaringan yang lebih tinggi (memori kurang penting). Untuk informasi selengkapnya, lihat Memilih SKU VM yang benar untuk kluster Azure Data Explorer Anda.