Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Overview
Azure Data Factory dan mode debug aliran data pemetaan Synapse Analytics memungkinkan Anda untuk secara interaktif menonton transformasi bentuk data saat Anda membangun dan men-debug aliran data Anda. Sesi debug dapat digunakan baik dalam sesi desain Data Flow maupun selama eksekusi debug alur aliran data. Untuk mengaktifkan mode debug, gunakan tombol Data Flow Debug di bilah atas kanvas data flow atau kanvas alur saat Anda memiliki aktivitas data flow.
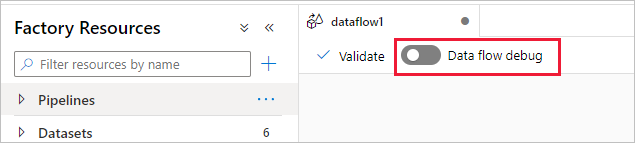

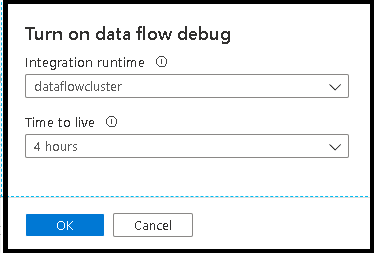
Setelah mengaktifkan penggeser, Anda akan diminta untuk memilih konfigurasi runtime integrasi mana yang ingin Anda gunakan. Jika AutoResolveIntegrationRuntime dipilih, kluster dengan delapan inti komputasi umum akan dibuat, dengan waktu hidup default 60 menit untuk dijalankan. Jika Anda ingin mengizinkan tim yang lebih menganggur sebelum waktu sesi habis, Anda dapat memilih pengaturan TTL yang lebih tinggi. Untuk informasi selengkapnya tentang integrasi aliran data dalam runtime, lihat performa Integration Runtime.
Saat mode Debug aktif, Anda akan membangun aliran data secara interaktif dengan kluster Spark aktif. Sesi ditutup setelah Anda menonaktifkan debug. Anda harus mengetahui biaya per jam yang dikeluarkan oleh Data Factory selama sesi debug diaktifkan.
Dalam kebanyakan kasus, ini adalah praktik yang baik untuk membangun Aliran Data Anda dalam mode debug sehingga Anda dapat memvalidasi logika bisnis Anda dan melihat transformasi data Anda sebelum menerbitkan pekerjaan Anda. Gunakan tombol "Debug" pada panel alur untuk menguji aliran data Anda dalam alur.
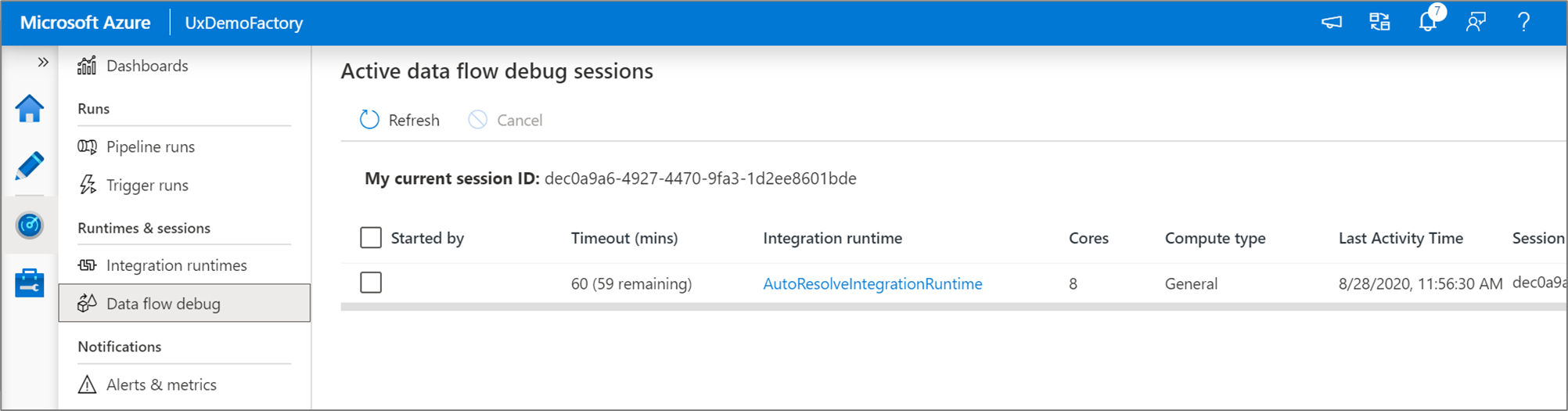
Catatan
Setiap sesi debug yang dimulai pengguna dari UI browser mereka adalah sesi baru dengan kluster Spark sendiri. Anda dapat menggunakan tampilan pemantauan untuk sesi debug yang ditampilkan di gambar sebelumnya untuk melihat dan mengelola sesi debug. Anda dikenakan biaya untuk setiap jam yang dijalankan setiap sesi debug termasuk waktu TTL.
Klip video ini berbicara tentang tips, trik, dan praktik yang baik untuk mode debug aliran data.
Status kluster
Indikator status kluster di bagian atas permukaan desain berubah menjadi hijau ketika kluster siap untuk debug. Jika kluster Anda sudah hangat, maka indikator hijau muncul hampir seketika. Jika kluster Anda belum berjalan saat Anda memasuki mode debug, maka kluster Spark melakukan boot dingin. Indikator berputar sampai lingkungan siap untuk penelusuran kesalahan interaktif.
Setelah selesai dengan penelusuran kesalahan, matikan sakelar Debug sehingga kluster Spark Anda dapat dihentikan dan Anda tidak akan lagi dikenakan biaya untuk aktivitas debug.
Pengaturan debug
Setelah mengaktifkan mode debug, Anda dapat mengedit cara aliran data mempratinjau data. Pengaturan debug dapat diedit dengan mengklik "Pengaturan Debug" pada toolbar kanvas Data Flow. Anda dapat memilih batas baris atau sumber file yang akan digunakan untuk setiap transformasi Sumber Anda di sini. Batas baris dalam pengaturan ini hanya untuk sesi debug saat ini. Anda juga dapat memilih layanan tertaut penahapan untuk digunakan sebagai sumber Azure Synapse Analytics.
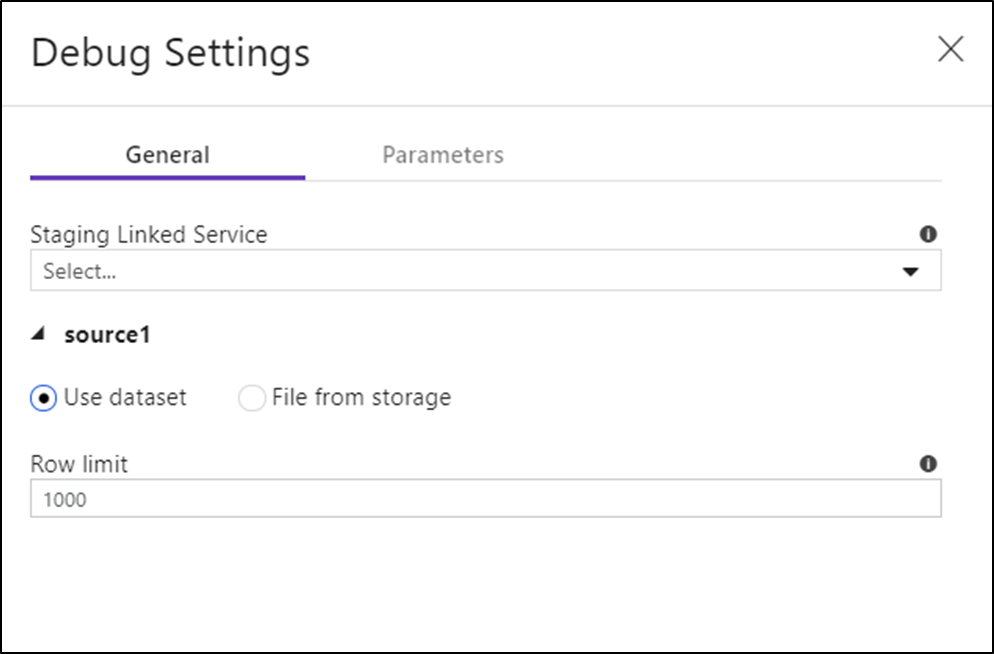
Jika Anda memiliki parameter di Data Flow atau himpunan data yang dirujuk, Anda dapat menentukan nilai apa yang akan digunakan selama penelusuran kesalahan dengan memilih tab Parameters.
Gunakan pengaturan pengambilan sampel di sini untuk menunjuk ke file sampel atau contoh tabel data sehingga Anda tidak perlu mengubah himpunan data sumber Anda. Dengan menggunakan file sampel atau tabel di sini, Anda dapat mempertahankan pengaturan logika dan properti yang sama dalam aliran data Anda saat menguji terhadap subkumpulan data.
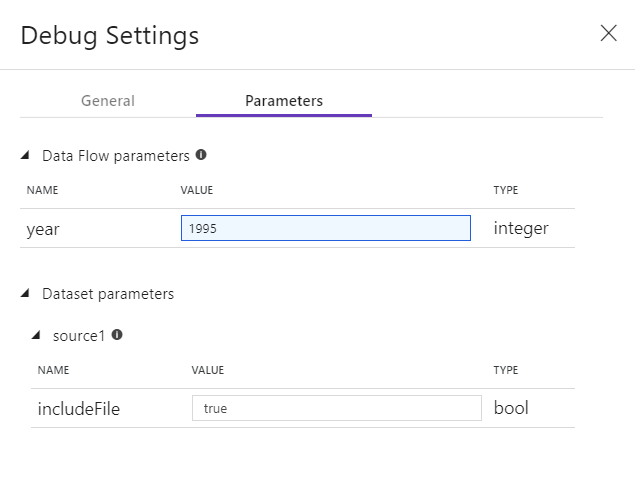
Runtime Integrasi default yang digunakan untuk mode debug dalam aliran data adalah sebuah node pekerja tunggal dengan 4 inti kecil dan sebuah node penggerak tunggal dengan 4 inti. Ini berfungsi dengan baik dengan sampel data yang lebih kecil saat menguji logika aliran data Anda. Jika Anda memperluas batas baris di pengaturan debug selama pratinjau data atau mengatur jumlah baris sampel yang lebih tinggi di sumber Anda selama debug alur, maka Anda mungkin ingin mempertimbangkan untuk mengatur lingkungan komputasi yang lebih besar di Azure Integration Runtime baru. Kemudian Anda dapat memulai ulang sesi debug menggunakan lingkungan komputasi yang lebih besar.
Pratinjau data
Dengan debug aktif, tab Pratinjau Data menyala di panel bawah. Tanpa mode debug aktif, Data Flow hanya menampilkan metadata saat ini masuk dan keluar dari setiap transformasi Anda di tab Inspeksi. Pratinjau data hanya akan mengkueri jumlah baris yang telah Anda tetapkan sebagai batas dalam pengaturan debug Anda. Pilih Refresh untuk memperbarui pratinjau data berdasarkan transformasi Anda saat ini. Jika data sumber Anda telah berubah, pilih Refresh Refetch > dari sumber.
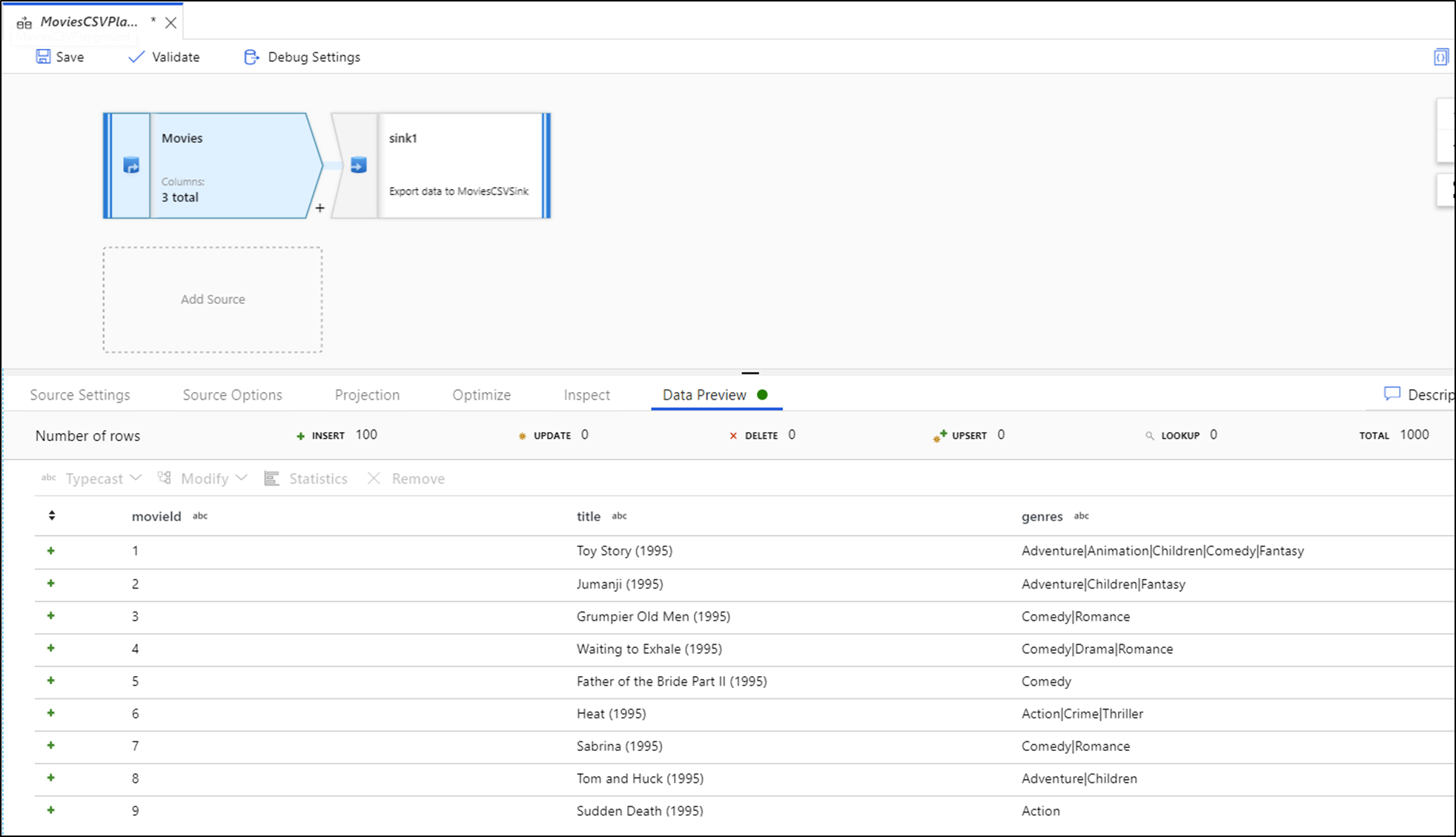
Anda bisa mengurutkan kolom dalam pratinjau data dan menyusun ulang kolom menggunakan seret dan lepas. Selain itu, ada tombol ekspor di bagian atas panel pratinjau data yang dapat Anda gunakan untuk mengekspor data pratinjau ke file CSV untuk eksplorasi data offline. Anda dapat menggunakan fitur ini untuk mengekspor hingga 1.000 baris data pratinjau.
Catatan
Sumber file hanya membatasi baris yang Anda lihat, bukan baris yang sedang dibaca. Untuk himpunan data yang sangat besar, disarankan agar Anda mengambil sebagian kecil file tersebut dan menggunakannya untuk pengujian Anda. Anda dapat memilih file sementara di Pengaturan Debug untuk setiap sumber yang merupakan jenis himpunan data file.
Saat menjalankan Data Flow dalam Mode Debug, data Anda tidak akan ditulis ke transformasi Sink. Sesi Debug dimaksudkan untuk berfungsi sebagai alat uji bagi transformasi Anda. Sink tidak diperlukan selama debug dan diabaikan dalam aliran data Anda. Jika Anda ingin menguji penulisan data di Sink Anda, jalankan Data Flow dari pipeline dan gunakan eksekusi Debug dari pipeline.
Pratinjau Data adalah cuplikan dari data anda yang telah diubah menggunakan batas baris dan pengambilan sampel data dari data frame yang berada di memori Spark. Oleh karena itu, driver sink tidak digunakan atau diuji dalam skenario ini.
Catatan
Pratinjau Data menampilkan waktu sesuai pengaturan lokal browser.
Menguji kondisi gabungan
Saat pengujian unit untuk Join, Exists, atau Transformasi Lookup, pastikan Anda menggunakan sekumpulan kecil data yang diketahui dalam pengujian Anda. Anda dapat menggunakan opsi Pengaturan Debug yang dijelaskan sebelumnya untuk mengatur file sementara yang akan digunakan untuk pengujian Anda. Ini diperlukan karena saat membatasi atau mengambil sampel baris dari himpunan data besar, Anda tidak dapat memprediksi baris mana dan kunci mana yang dibaca ke dalam alur untuk pengujian. Hasilnya adalah nondeterministik, yang berarti bahwa kondisi gabungan Anda mungkin gagal.
Tindakan cepat
Setelah melihat pratinjau data, Anda dapat menghasilkan transformasi cepat untuk mengetik, menghapus, atau melakukan modifikasi pada kolom. Pilih header kolom lalu pilih salah satu opsi dari toolbar pratinjau data.
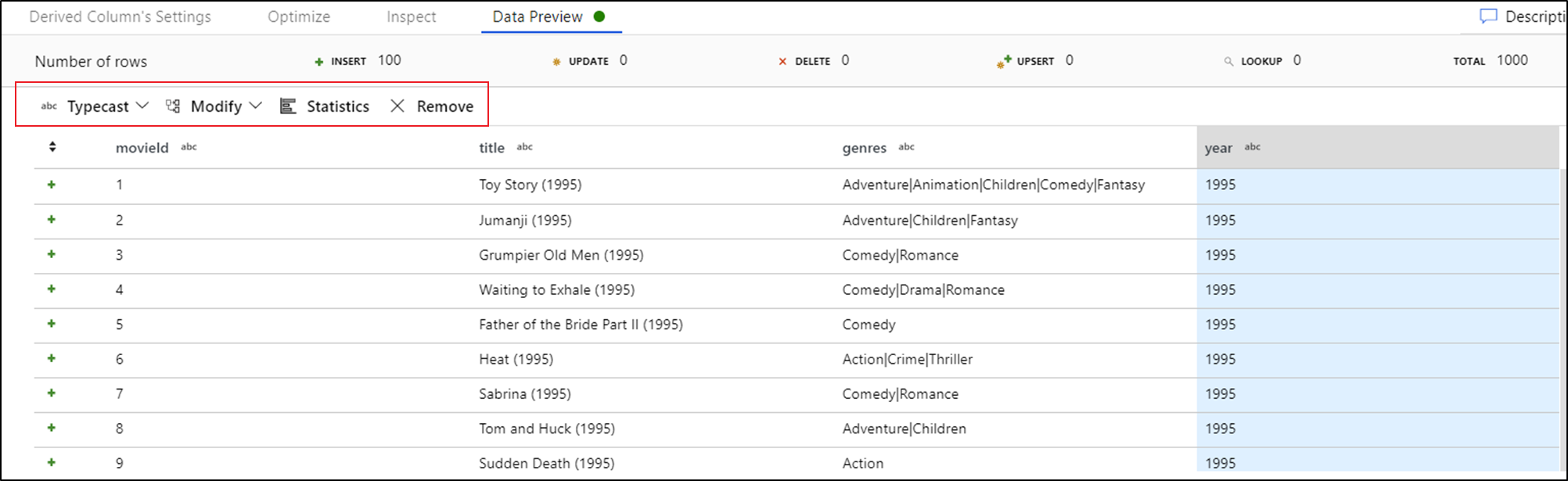
Setelah Anda memilih modifikasi, pratinjau data akan segera di-refresh. Pilih Konfirmasi di sudut kanan atas untuk menghasilkan transformasi baru.
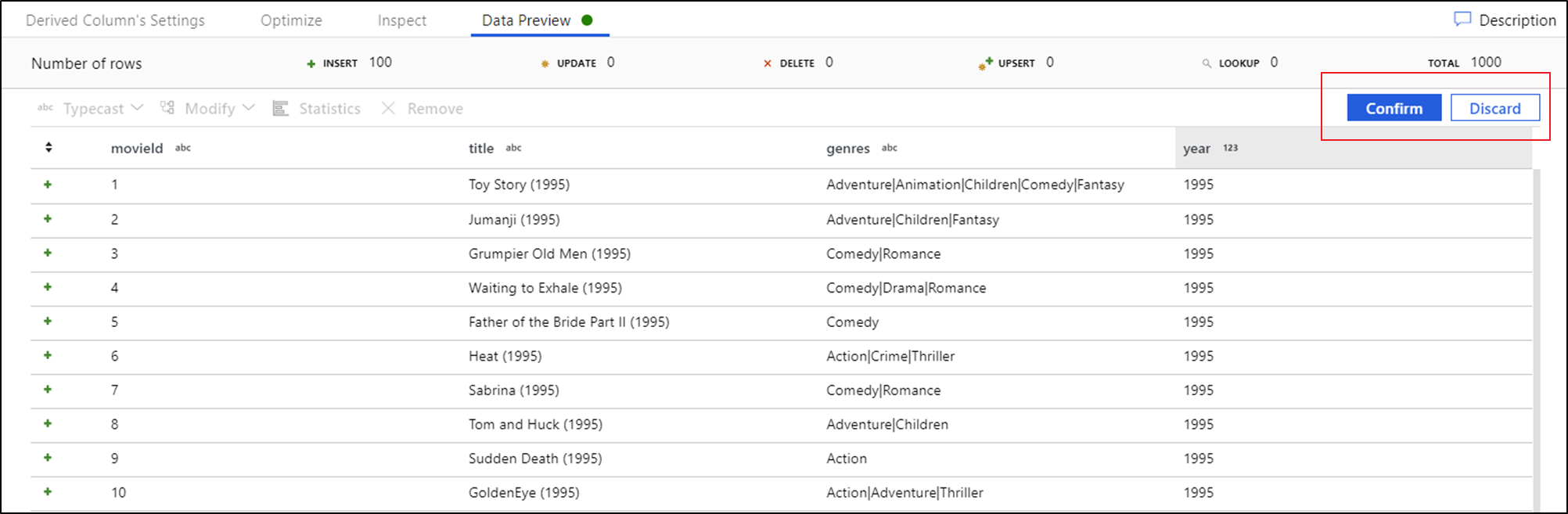
Typecast dan Modifikasi menghasilkan transformasi Kolom Turunan dan Hapus menghasilkan transformasi Pilih.
Catatan
Jika Anda mengedit Data Flow, Anda perlu memuat ulang pratinjau data sebelum menerapkan transformasi cepat.
Pemrofilan data
Memilih kolom di tab pratinjau data Anda dan mengklik Statistik di toolbar pratinjau data akan memunculkan bagan di ujung kanan kisi data Anda dengan statistik terperinci tentang setiap bidang. Layanan ini membuat basis penentuan pada pengambilan sampel data dari jenis bagan mana yang akan ditampilkan. Bidang kardinalitas tinggi default ke bagan NULL/NOT NULL sementara data kategoris dan numerik yang memiliki kardinalitas rendah menampilkan bagan batang yang memperlihatkan frekuensi nilai data. Anda juga melihat panjang maksimum/lensa bidang string, nilai min/maks dalam bidang numerik, dev standar, persentil, hitungan, dan rata-rata.
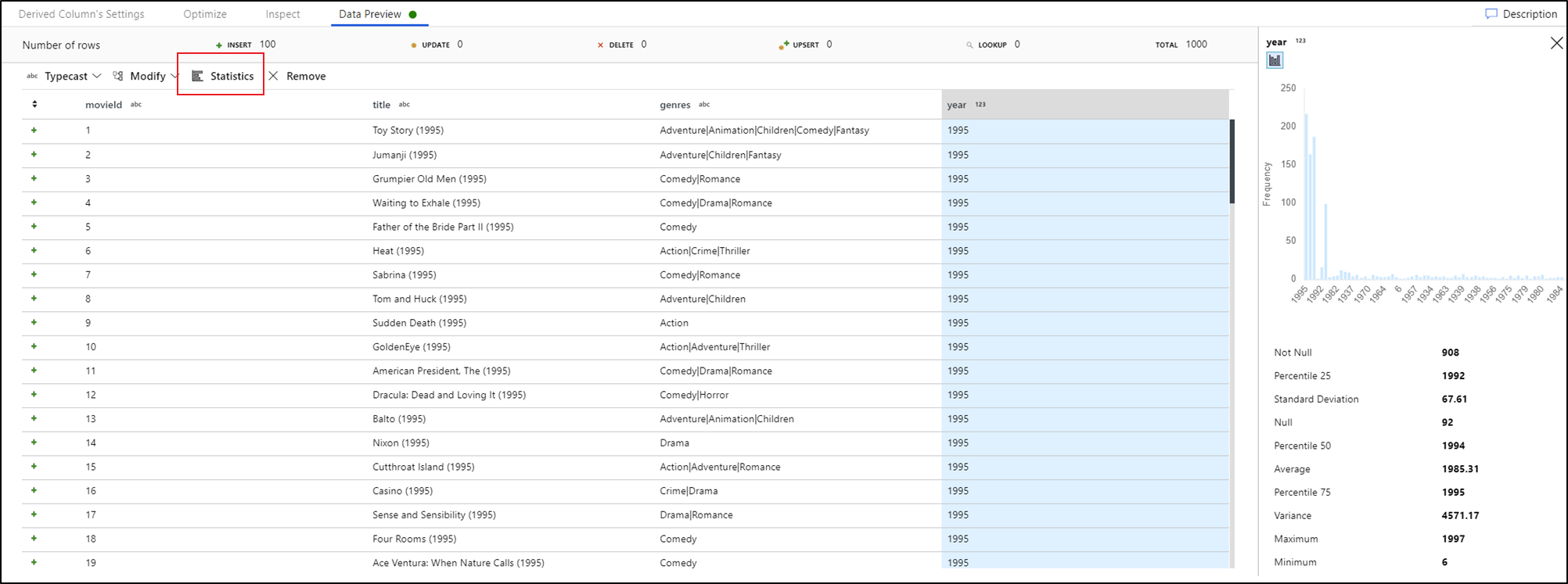
Konten terkait
- Setelah anda selesai membangun dan men-debug aliran data Anda, jalankan dari pipeline.
- Saat menguji pipeline Anda dengan aliran data, gunakan opsi eksekusi debug alur.