Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Gunakan aktivitas Data Flow untuk mengubah dan memindahkan data melalui aliran data pemetaan. Jika Anda baru menggunakan aliran data, lihat gambaran umum Mapping Data Flow
Membuat aktivitas Data Flow dengan UI
Untuk menggunakan aktivitas Data Flow dalam alur, selesaikan langkah-langkah berikut:
Cari Data Flow di panel Aktivitas alur, dan seret aktivitas Data Flow ke kanvas alur.
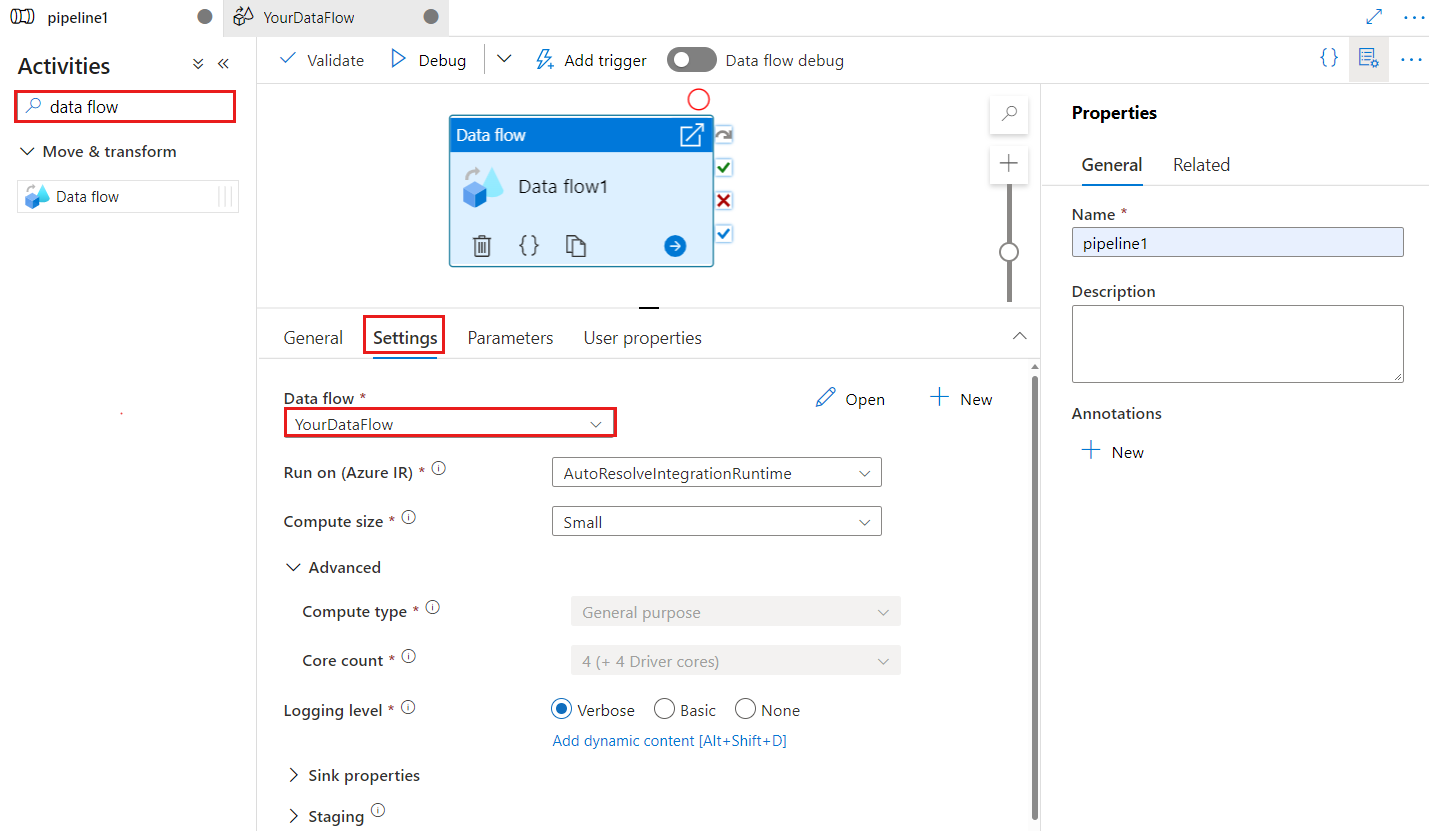
Pilih aktivitas Data Flow baru di kanvas jika belum dipilih, dan tab Settings, untuk mengedit detailnya.
Kunci titik pemeriksaan digunakan untuk mengatur titik pemeriksaan saat aliran data digunakan untuk changed data capture. Anda bisa menggantinya. Aktivitas aliran data menggunakan nilai guid sebagai kunci titik pemeriksaan alih-alih "nama alur + nama aktivitas" sehingga selalu dapat terus melacak status penangkapan data perubahan pelanggan meskipun ada tindakan penggantian nama. Semua aktivitas aliran data yang ada menggunakan kunci pola lama untuk kompatibilitas mundur. Opsi kunci titik pemeriksaan setelah menerbitkan aktivitas aliran data baru dengan mengubah sumber daya aliran data yang diaktifkan pengambilan data ditampilkan seperti di bawah ini.
Menampilkan UI untuk aktivitas Data Flow dengan kunci titik pemeriksaan.
Pilih aliran data yang sudah ada atau buat yang baru menggunakan tombol Baru. Pilih opsi lain yang diperlukan untuk menyelesaikan konfigurasi Anda.
Sintaks
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Properti jenis
| Properti | Deskripsi | Nilai yang diizinkan | Wajib |
|---|---|---|---|
| aliran data | Referensi ke Data Flow yang sedang dieksekusi | DataFlowReference | Ya |
| integrationRuntime | Lingkungan komputasi tempat aliran data berjalan. Jika tidak ditentukan, runtime integrasi Azure autoresolve digunakan. | IntegrationRuntimeReference | Tidak |
| compute.coreCount | Jumlah inti yang digunakan dalam kluster Spark. Hanya dapat ditentukan jika runtime integrasi Azure autoresolve digunakan | 8, 16, 32, 48, 80, 144, 272 | Tidak |
| compute.computeType | Jenis komputasi yang digunakan dalam kluster spark. Hanya dapat ditentukan jika Azure Integration runtime dengan fitur autoresolve digunakan | Umum | Tidak |
| staging.linkedService | Jika Anda menggunakan sumber atau sink Azure Synapse Analytics, tentukan akun penyimpanan yang digunakan untuk proses penahapan PolyBase. Jika Azure Storage Anda dikonfigurasi dengan titik akhir layanan VNet, Anda harus menggunakan autentikasi identitas terkelola dengan "mengizinkan layanan Microsoft yang tepercaya" diaktifkan pada akun penyimpanan, lihat Dampak menggunakan Titik Akhir Layanan VNet dengan Azure Storage. Konfigurasi yang diperlukan untuk Azure Blob dan Azure Data Lake Storage Gen2 masing-masing harus dipelajari juga. |
LinkedServiceReference | Hanya jika aliran data melakukan pembacaan atau penulisan ke Azure Synapse Analytics |
| staging.folderPath | Jika Anda menggunakan sumber atau sink Azure Synapse Analytics, jalur folder di akun penyimpanan blob yang digunakan untuk penahapan PolyBase | String | Hanya jika aliran data membaca atau menulis ke Azure Synapse Analytics |
| traceLevel | Mengatur tingkat pengelogan eksekusi aktivitas aliran data Anda | Halus, Kasar, Tidak ada | Tidak |
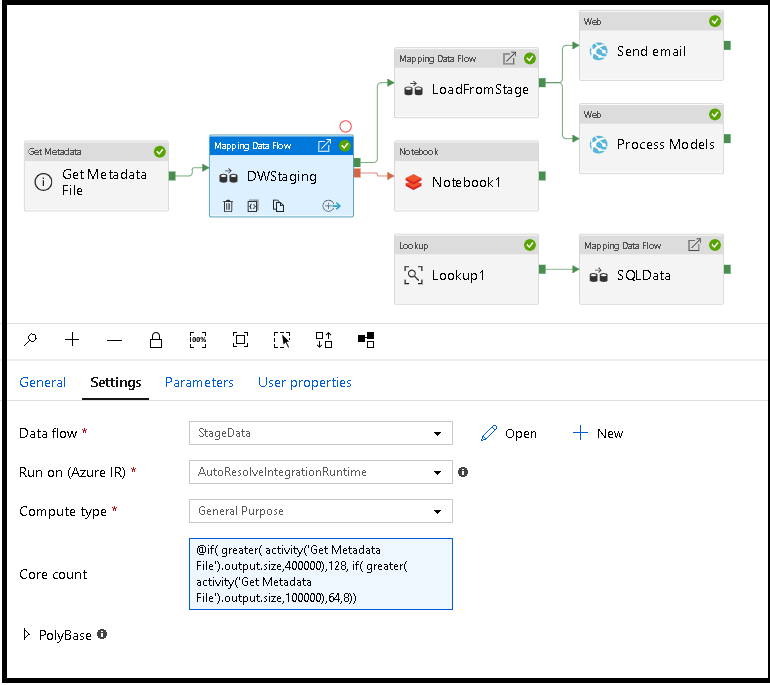
Menyesuaikan komputasi aliran data secara dinamis pada saat runtime
Properti Core Count dan Compute Type dapat diatur secara dinamis untuk menyesuaikan dengan ukuran data sumber masuk Anda pada runtime. Gunakan aktivitas alur seperti Pencarian atau Dapatkan Metadata untuk menemukan ukuran data himpunan data sumber. Kemudian, gunakan Tambahkan Konten Dinamis di properti aktivitas Data Flow. Anda dapat memilih ukuran komputasi kecil, sedang, atau besar. Secara opsional, pilih "Kustom" dan konfigurasikan jenis komputasi dan jumlah inti secara manual.
Berikut adalah tutorial video singkat yang menjelaskan teknik ini
Data Flow runtime integrasi
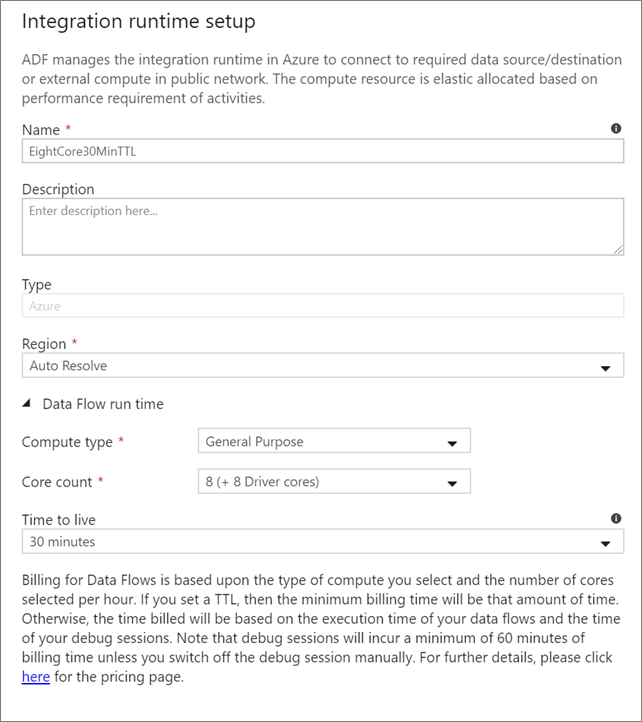
Pilih Integration Runtime mana yang akan digunakan untuk eksekusi aktivitas Data Flow Anda. Secara default, layanan menggunakan runtime integrasi Azure autoresolve dengan empat inti pekerja. Runtime integrasi ini memiliki tipe komputasi tujuan umum dan beroperasi di wilayah yang sama dengan instans layanan Anda. Untuk alur yang dioprasikan, sangat disarankan agar Anda membuat runtime integrasi Azure Anda sendiri yang menentukan wilayah tertentu, jenis komputasi, jumlah inti, dan TTL untuk eksekusi aktivitas aliran data Anda.
Jenis komputasi minimum untuk Tujuan Umum dengan konfigurasi 8+8 (16 total v-core) dan Time to live (TTL) 10 menit adalah rekomendasi minimum untuk sebagian besar beban kerja produksi. Dengan mengatur TTL kecil, Azure IR dapat menjaga kluster tetap hangat sehingga tidak memerlukan beberapa menit waktu mulai seperti kluster dingin. Untuk informasi selengkapnya, lihat Azure integration runtime.
Penting
Pilihan Integration Runtime dalam aktivitas Data Flow hanya berlaku untuk eksekusi yang dipicu dari alur Anda. Mendebug alur kerja Anda dengan menjalankan aliran data pada kluster yang ditentukan dalam sesi debug.
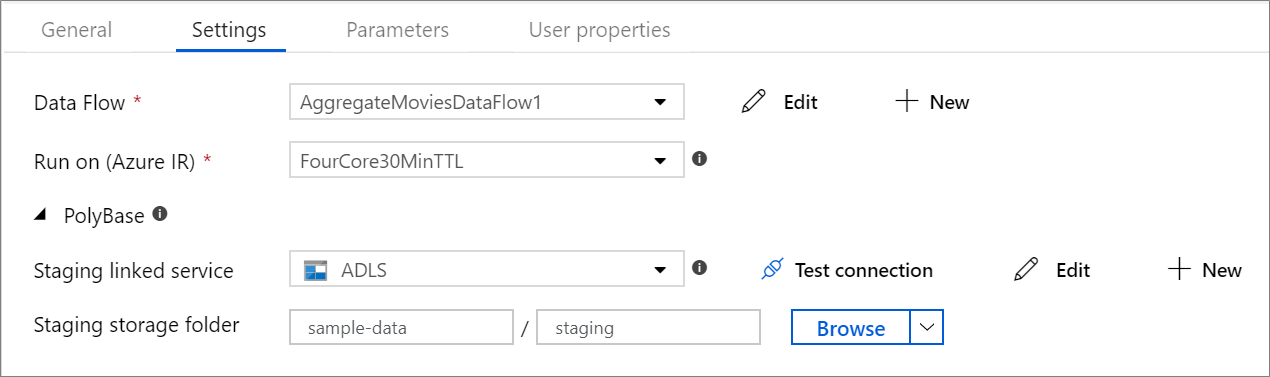
PolyBase
Jika Anda menggunakan Azure Synapse Analytics sebagai sink atau sumber, Anda harus memilih lokasi penahapan untuk beban batch PolyBase Anda. PolyBase memungkinkan pemuatan batch secara massal alih-alih memuat baris demi baris data. PolyBase secara drastis mengurangi waktu muat ke Azure Synapse Analytics.
Kunci titik pemeriksaan
Saat menggunakan opsi tangkapan perubahan untuk sumber aliran data, ADF mempertahankan dan mengelola titik pemeriksaan untuk Anda secara otomatis. Kunci titik pemeriksaan default adalah hash dari nama aliran data dan nama alur pipa. Jika Anda menggunakan pola dinamis untuk tabel atau folder sumber, Anda mungkin ingin mengambil alih hash ini dan mengatur nilai kunci titik pemeriksaan Anda sendiri di sini.
Tingkat pengelogan
Jika Anda tidak mengharuskan setiap eksekusi alur aktivitas aliran data Anda untuk sepenuhnya mencatat semua log telemetri verbose, Anda dapat secara opsional mengatur tingkat pengelogan Anda ke "Dasar" atau "Tidak Ada". Saat menjalankan aliran data Anda dalam mode "Verbose" (default), Anda meminta layanan untuk sepenuhnya mencatat aktivitas di setiap tingkat partisi individu selama transformasi data Anda. Ini bisa menjadi operasi yang mahal, jadi aktifkan verbose hanya saat pemecahan masalah dapat meningkatkan aliran data dan performa alur Anda secara keseluruhan. Mode "Dasar" hanya mencatat durasi transformasi sementara "Tidak Ada" hanya menyediakan ringkasan durasi.

Properti pembuangan
Fitur pengelompokan dalam aliran data memungkinkan Anda mengatur urutan eksekusi sink Anda serta mengelompokkan sink bersama-sama menggunakan nomor grup yang sama. Untuk membantu mengelola grup, Anda dapat meminta layanan untuk menjalankan sink, dalam grup yang sama, secara paralel. Anda juga dapat mengatur grup sink untuk melanjutkan bahkan setelah salah satu sink mengalami kesalahan.
Perilaku bawaan sink aliran data adalah mengeksekusi setiap sink secara berurutan, dalam urutan serial, dan menghentikan aliran data ketika terjadi kesalahan pada sink. Selain itu, semua sink ditetapkan secara default ke grup yang sama kecuali Anda masuk ke properti aliran data dan menetapkan prioritas berbeda untuk sink.

Baris pertama saja
Opsi ini hanya tersedia untuk aliran data yang memiliki sink cache yang diaktifkan untuk "Output ke aktivitas". Output dari aliran data yang dimasukkan langsung ke pipeline Anda dibatasi hingga 2MB. Pengaturan "baris pertama saja" membantu Anda membatasi output data dari aliran data saat memasukkan output aktivitas aliran data langsung ke pipeline anda.
Parameterisasi Aliran Data
Himpunan data berparameter
Jika aliran data Anda menggunakan himpunan data berparameter, atur nilai parameter di tab Pengaturan.
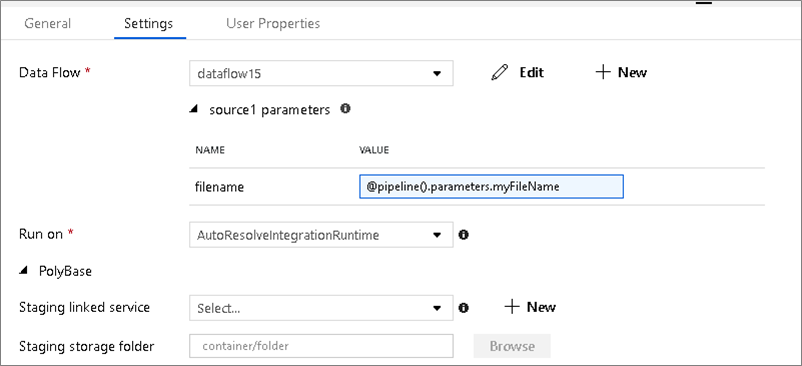
Aliran data parameterisasi
Jika aliran data Anda berparameter, atur nilai dinamis parameter aliran data di tab Parameter. Anda dapat menggunakan bahasa ekspresi alur atau bahasa ekspresi aliran data untuk menetapkan nilai parameter dinamis atau literal. Untuk informasi selengkapnya, lihat Parameter Data Flow.
Properti komputasi yang diparameterisasi.
Anda dapat membuat parameter jumlah inti atau jenis komputasi jika Anda menggunakan runtime integrasi Azure autoresolve dan menentukan nilai untuk compute.coreCount dan compute.computeType.
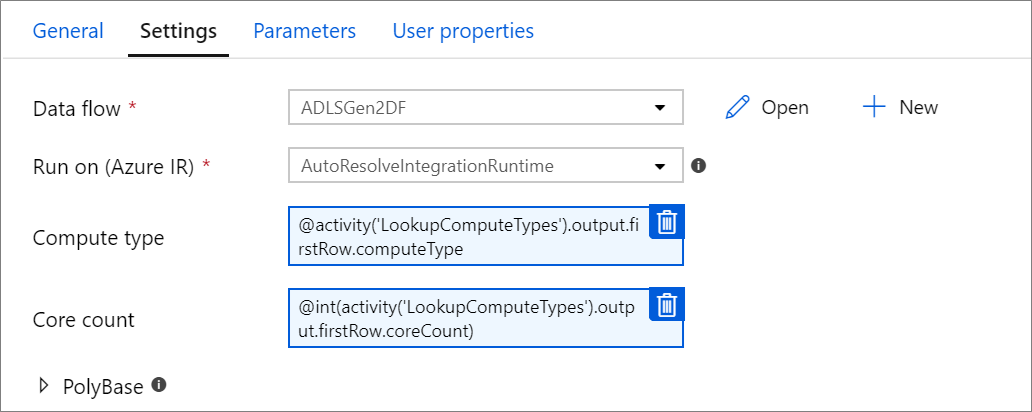
Debug alur aktivitas Data Flow
Untuk menjalankan eksekusi alur debug dengan aktivitas Data Flow, Anda harus mengaktifkan mode debug data flow melalui Data Flow Debug slider di bilah atas. Mode debug memungkinkan Anda menjalankan aliran data terhadap kluster Spark aktif. Untuk informasi selengkapnya, lihat Mode Debug.

Alur debug berjalan terhadap kluster debug aktif, bukan lingkungan runtime integrasi yang ditentukan dalam pengaturan aktivitas Data Flow. Anda dapat memilih lingkungan komputasi debug saat memulai mode debug.
Memantau aktivitas Data Flow
Aktivitas Data Flow memiliki pengalaman pemantauan khusus di mana Anda dapat melihat informasi partisi, waktu tahap, dan silsilah data. Buka panel pemantauan melalui ikon kacamata di bawah Tindakan. Untuk mengetahui informasi selengkapnya, lihat Memantau Aliran Data.
Gunakan hasil aktivitas Data Flow dalam aktivitas berikutnya
Aktivitas aliran data menghasilkan metrik tentang jumlah baris yang ditulis ke masing-masing sink dan baris yang dibaca dari setiap sumber. Hasil ini dikembalikan di bagian output dari hasil eksekusi aktivitas. Metrik yang dikembalikan dalam format json di bawah ini.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Misalnya, untuk mendapatkan jumlah baris yang ditulis ke sink bernama 'sink1' dalam aktivitas bernama 'dataflowActivity', gunakan @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Untuk mendapatkan jumlah baris yang dibaca dari sumber bernama 'source1' yang digunakan dalam sink tersebut, gunakan @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Catatan
Jika sink memiliki baris nol yang ditulis, sink tidak akan muncul dalam metrik. Keberadaan dapat diverifikasi menggunakan fungsi contains. Misalnya, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') memeriksa apakah ada baris yang ditulis ke sink1.
Konten terkait
Lihat aktivitas alur kontrol yang didukung: