Penyimpangan skema dalam aliran data pemetaan
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Penyimpangan skema adalah kasus saat sumber Anda sering mengubah metadata. Bidang, kolom, dan, tipe bisa ditambahkan, dihapus, atau diubah saat dalam perjalanan. Tanpa penanganan untuk penyimpangan skema, aliran data Anda menjadi rentan terhadap perubahan sumber data hulu. Pola ETL yang khas gagal saat kolom dan bidang yang masuk berubah karena cenderung terikat dengan nama sumber tersebut.
Untuk melindungi dari penyimpangan skema, Anda harus memiliki fasilitas di alat aliran data agar Anda, sebagai Teknisi Data, dapat:
- Menentukan sumber yang memiliki nama bidang, jenis data, nilai, dan ukuran yang dapat diubah
- Menentukan parameter transformasi yang dapat berfungsi dengan pola data, bukan bidang dan nilai yang dikodekan secara permanen
- Menentukan ekspresi yang memahami pola untuk mencocokkan bidang masuk, bukan menggunakan bidang bernama
Azure Data Factory secara native mendukung skema fleksibel yang berubah dari eksekusi ke eksekusi sehingga Anda dapat menyusun logika transformasi data generik tanpa perlu menyusun ulang aliran data.
Anda perlu membuat keputusan arsitektur dalam aliran data untuk menerima penyimpangan skema di seluruh aliran Anda. Jika melakukannya, Anda dapat melindungi terhadap perubahan skema dari sumber. Namun, Anda akan kehilangan pengikatan awal kolom dan tipe di seluruh aliran data Anda. Azure Data Factory memperlakukan alur penyimpangan skema sebagai alur pengikatan akhir, jadi saat Anda menyusun transformasi, nama kolom yang menyimpang tidak akan tersedia untuk Anda dalam tampilan skema di seluruh aliran.
Video ini berisi pengantar beberapa solusi kompleks yang dapat Anda susun dengan mudah di Azure Data Factory atau Azure Synapse Analytics dengan penyimpangan skema fitur aliran data. Dalam contoh ini, kami menyusun pola yang dapat digunakan kembali berdasarkan skema database yang fleksibel:
Penyimpangan skema di sumber
Kolom yang masuk ke alur data Anda dari definisi sumber Anda didefinisikan sebagai "menyimpang" saat kolom tidak ada dalam proyeksi sumber Anda. Anda dapat melihat proyeksi sumber dari tab proyeksi dalam transformasi sumber. Saat Anda memilih himpunan data untuk sumber Anda, layanan akan otomatis mengambil skema dari himpunan data dan membuat proyeksi dari definisi skema himpunan data tersebut.
Dalam transformasi sumber, penyimpangan skema didefinisikan sebagai kolom baca yang tidak ditentukan dalam skema himpunan data Anda. Untuk mengaktifkan penyimpangan skema, centang Izinkan penyimpangan skema di transformasi sumber.
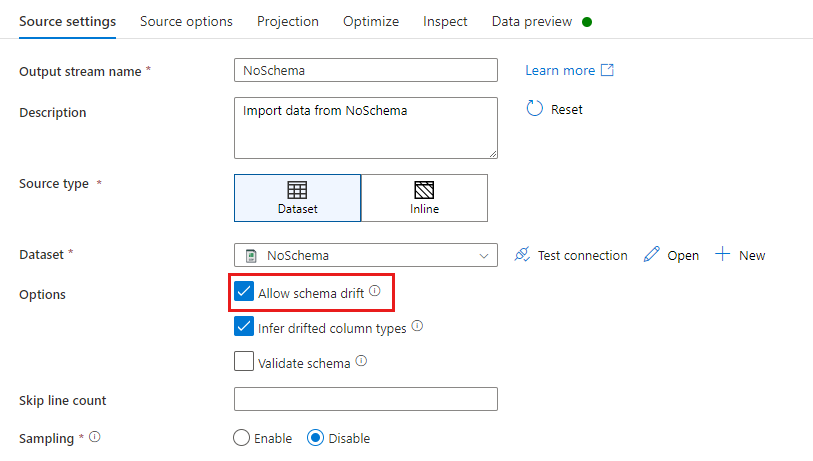
Saat penyimpangan skema diaktifkan, semua bidang masuk dibaca dari sumber Anda selama eksekusi dan melewati seluruh aliran ke Sink. Secara default, semua kolom yang baru terdeteksi, yang dikenal sebagai kolom menyimpang, tiba sebagai jenis data untai. Jika Anda menginginkan aliran data Anda secara otomatis menyimpulkan jenis data kolom yang menyimpang, centang Simpulkan jenis kolom yang menyimpang di pengaturan sumber Anda.
Penyimpangan skema dalam sink
Dalam transformasi sink, penyimpangan skema adalah saat Anda menulis kolom tambahan di bagian atas dari apa yang didefinisikan dalam skema data sink. Untuk mengaktifkan penyimpangan skema, centang Izinkan penyimpangan skema dalam transformasi sink Anda.
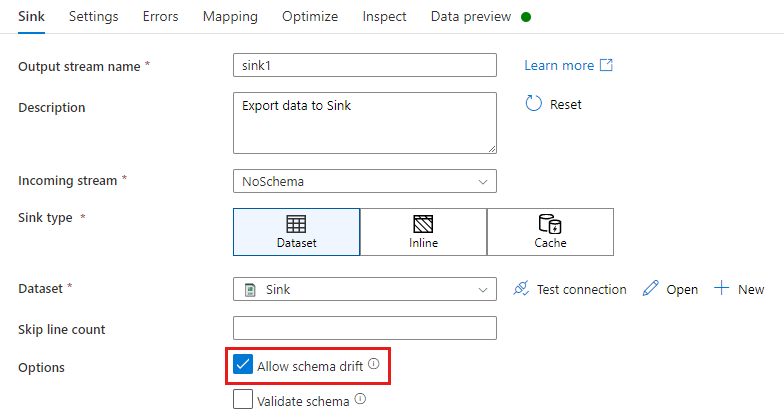
Jika penyimpangan skema diaktifkan, pastikan penggeser Pemetaan otomatis di tab Pemetaan diaktifkan. Dengan mengaktifkan penggeser ini, semua kolom masuk ditulis ke tujuan Anda. Jika tidak, Anda harus menggunakan pemetaan berbasis aturan untuk menulis kolom yang menyimpang.
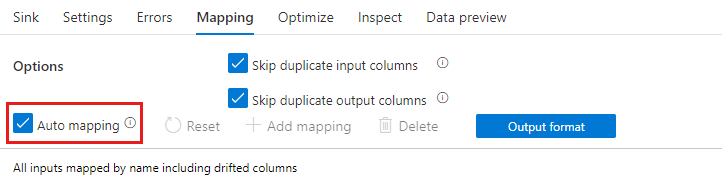
Mengubah kolom yang menyimpang
Saat aliran data Anda memiliki kolom yang menyimpang, Anda dapat mengaksesnya dalam transformasi Anda dengan metode berikut:
- Gunakan ekspresi
byPositiondanbyNameuntuk mereferensikan kolom secara eksplisit menurut nama atau nomor posisi. - Tambahkan pola kolom dalam Kolom Turunan atau Transformasi agregat agar cocok dengan kombinasi nama, aliran, posisi, asal, atau jenis apa pun
- Tambahkan pemetaan berbasis aturan dalam transformasi Pilih atau Sink untuk mencocokkan kolom yang menyimpang ke alias kolom melalui pola
Untuk informasi selengkapnya tentang cara menerapkan pola kolom, lihat Pola kolom dalam aliran data pemetaan.
Memetakan tindakan cepat kolom yang menyimpang
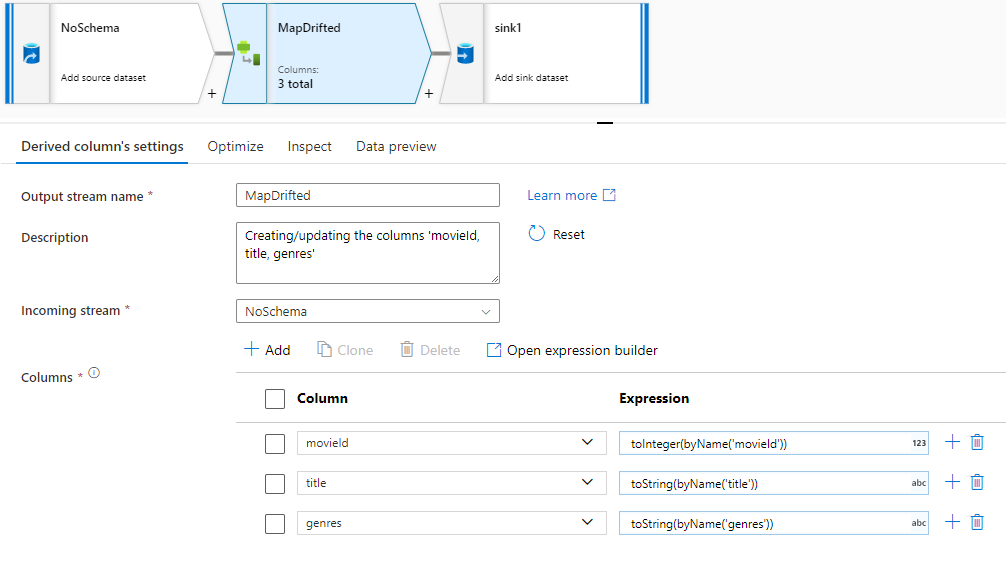
Untuk mereferensikan kolom yang menyimpang secara eksplisit, Anda dapat dengan cepat menghasilkan pemetaan untuk kolom ini melalui tindakan cepat pratinjau data. Setelah mode debug aktif, buka tab Pratinjau Data dan klik Refresh untuk mengambil pratinjau data. Jika pabrik data mendeteksi adanya kolom yang menyimpang, Anda dapat mengklik Petakan Penyimpangan dan menghasilkan kolom turunan yang memungkinkan Anda mereferensikan semua kolom yang menyimpang dalam tampilan skema di hilir.
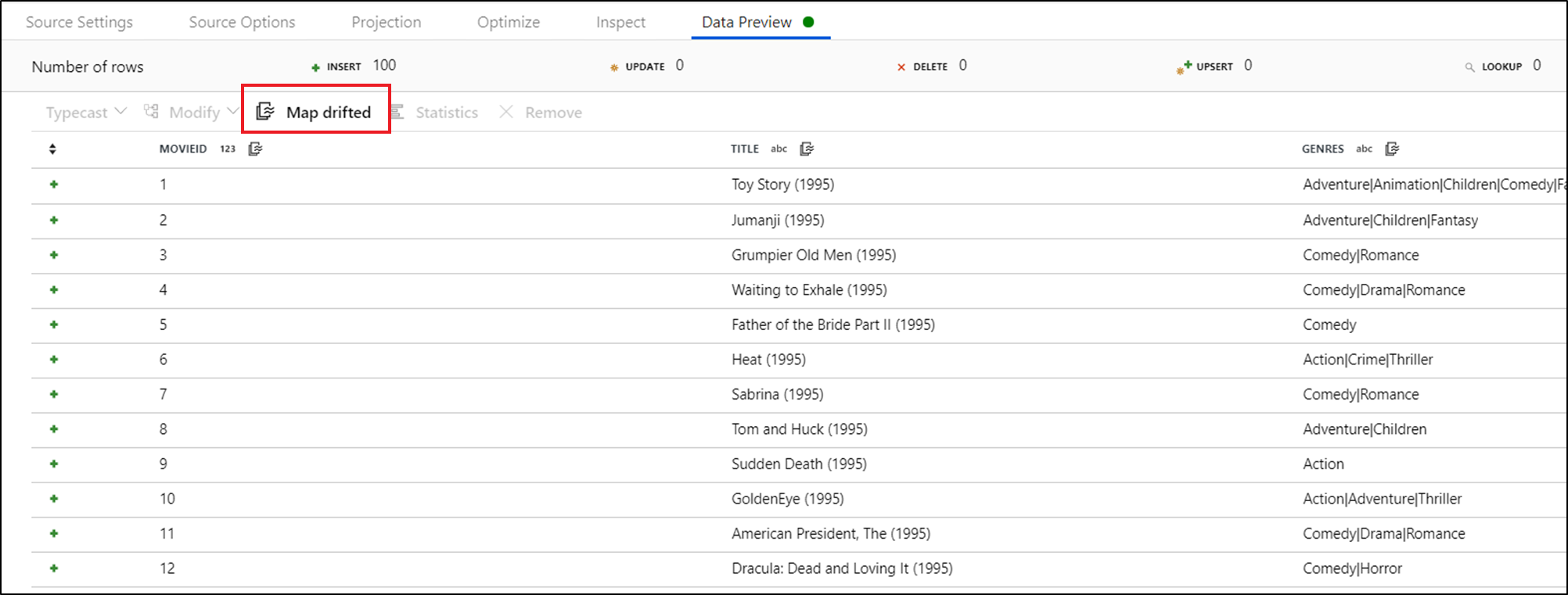
Dalam transformasi Kolom Turunan yang dihasilkan, setiap kolom yang menyimpang dipetakan ke jenis data dan nama yang terdeteksi. Di pratinjau data di atas, kolom 'movieId' dideteksi sebagai bilangan bulat. Setelah Petakan Penyimpangan diklik, movieId ditentukan dalam Kolom Turunan sebagai toInteger(byName('movieId')) dan disertakan dalam tampilan skema dalam transformasi hilir.
Konten terkait
Dalam Bahasa Ekspresi Aliran Data, Anda akan menemukan fasilitas tambahan untuk pola kolom dan penyimpangan skema termasuk "byName" dan "byPosition".