Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Artikel ini menguraikan cara menggunakan Aktivitas Salin dalam alur Azure Data Factory atau Synapse Analytics untuk menyalin data dari Spark. Artikel tersebut dibuat berdasarkan artikel gambaran umum aktivitas salin yang menyajikan gambaran umum aktivitas salin.
Penting
Konektor Spark versi 1.0 berada pada tahap penghapusan. Anda disarankan untuk meningkatkan konektor Spark dari versi 1.0 ke 2.0.
Kemampuan yang didukung
Konektor Spark ini didukung untuk kemampuan berikut:
| Kemampuan yang didukung | IR |
|---|---|
| Aktivitas menyalin (sumber/-) | (1) (2) |
| Aktivitas pencarian | (1) (2) |
(1) Azure runtime integrasi (2) Runtime integrasi yang dihost sendiri
Untuk daftar penyimpanan data yang didukung sebagai sumber/sink oleh aktivitas salin, lihat tabel Penyimpanan data yang didukung.
Layanan ini menyediakan driver bawaan untuk mengaktifkan konektivitas, oleh karena itu Anda tidak perlu memasang driver apa pun secara manual menggunakan konektor ini.
Prasyarat
Jika penyimpanan data Anda terletak di dalam jaringan lokal, jaringan virtual Azure, atau Amazon Virtual Private Cloud, Anda perlu mengonfigurasi runtime integrasi yang dihosting sendiri self-hosted integration runtime untuk menyambungkannya.
Jika penyimpanan data Anda adalah layanan data cloud terkelola, Anda dapat menggunakan Azure Integration Runtime. Jika akses dibatasi untuk IP yang disetujui dalam aturan firewall, Anda dapat menambahkan IP Azure Integration Runtime ke daftar izinkan.
Anda juga dapat menggunakan fitur managed virtual network integration runtime di Azure Data Factory untuk mengakses jaringan di lokasi tanpa menginstal dan mengonfigurasi runtime integrasi yang dihosting sendiri.
Untuk informasi selengkapnya tentang mekanisme dan opsi keamanan jaringan yang didukung oleh Data Factory, lihat Strategi akses data.
Memulai Langkah Pertama
Untuk melakukan aktivitas salin dengan alur, Anda dapat menggunakan salah satu alat atau SDK berikut:
- Alat Salin Data
- Portal Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- templat Azure Resource Manager
Membuat layanan tertaut ke Spark menggunakan UI
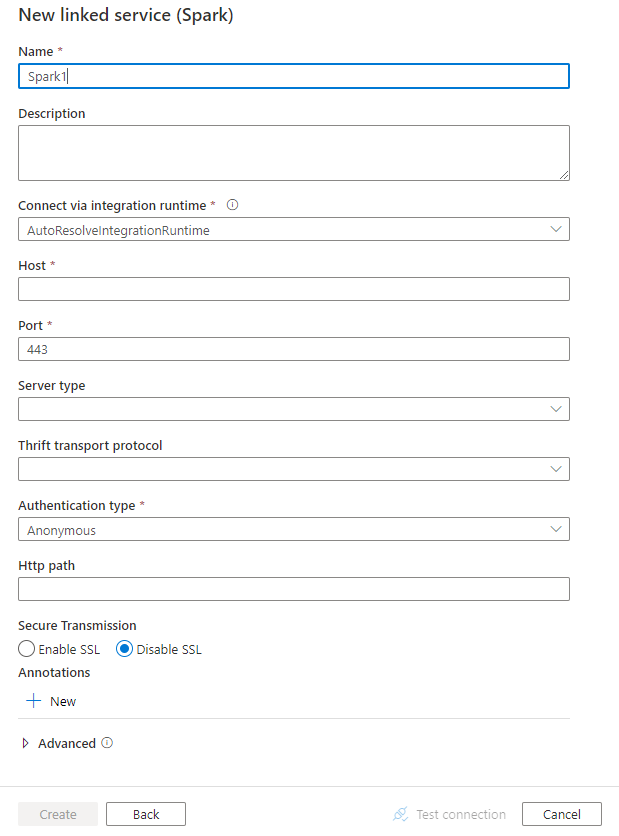
Gunakan langkah-langkah berikut untuk membuat layanan tertaut ke Spark di UI portal Azure.
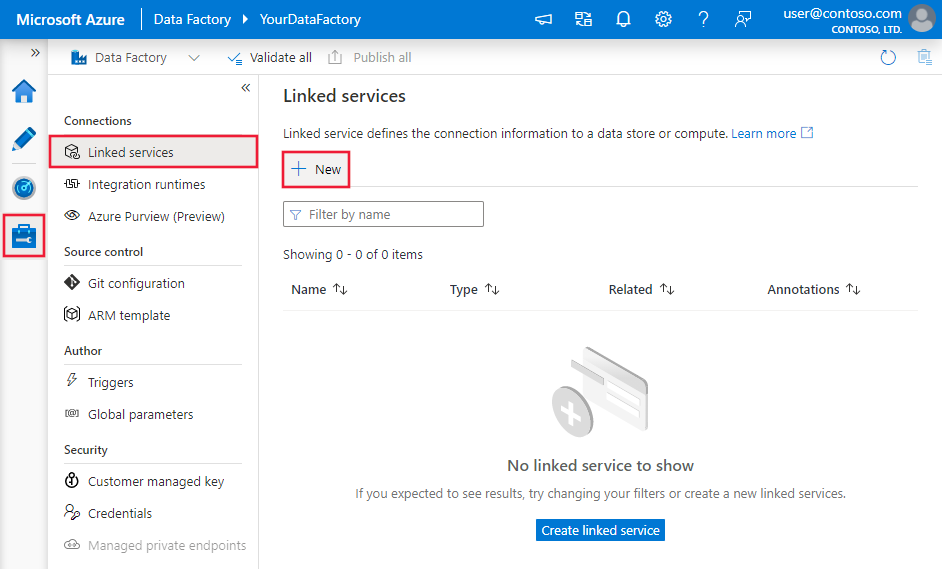
Telusuri ke tab Kelola di ruang kerja Azure Data Factory atau Synapse Anda dan pilih Layanan Tertaut, lalu klik Baru:
Cari Spark dan pilih konektor Spark.

Konfigurasikan detail layanan, uji koneksi, dan buat layanan tertaut baru.
Detail konfigurasi konektor
Bagian berikut ini menyediakan detail tentang properti yang digunakan untuk menentukan entitas Data Factory khusus untuk konektor Spark.
Properti layanan yang terhubung
Konektor Spark sekarang mendukung versi 2.0. Lihat bagian ini untuk meningkatkan versi konektor Spark Anda dari versi 1.0. Untuk detail properti, lihat bagian yang sesuai.
Versi 2.0
Properti berikut ini didukung untuk layanan tertaut Spark versi 2.0:
| Harta benda | Deskripsi | Diperlukan |
|---|---|---|
| jenis | Properti jenis harus diatur ke: Spark | Ya |
| versi | Versi yang Anda tentukan. Nilainya adalah 2.0. |
Ya |
| host | Alamat IP atau nama host server Spark | Ya |
| port | Port TCP yang digunakan server Spark untuk mendengarkan koneksi klien. Jika Anda tersambung ke Azure HDInsight, tentukan port sebagai 443. | Ya |
| tipeServer | Jenis server Spark. Nilai yang diizinkan adalah: SparkThriftServer |
Tidak. |
| Protokol Transportasi Thrift | Protokol transportasi yang digunakan dalam lapisan Thrift. Nilai yang diizinkan adalah: HTTP |
Tidak. |
| tipe autentikasi | Metode autentikasi yang digunakan untuk mengakses server Spark. Nilai yang diizinkan adalah: Anonim, UsernameAndPassword, WindowsAzureHDInsightService |
Ya |
| nama pengguna | Nama pengguna yang Anda gunakan untuk mengakses Spark Server. | Tidak. |
| kata sandi | Kata sandi yang sesuai dengan pengguna. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman, atau referensi rahasia yang disimpan di Azure Key Vault. | Tidak. |
| httpPath | URL parsial yang sesuai dengan server Spark. Untuk jenis autentikasi WindowsAzureHDInsightService, nilai defaultnya adalah /sparkhive2. |
Tidak. |
| aktifkan SSL | Menentukan apakah koneksi ke server dienkripsi menggunakan TLS. Nilai defaultnya adalah true. | Tidak. |
| aktifkanValidasiSertifikatServer | Tentukan apakah akan mengaktifkan validasi sertifikat SSL server saat Anda tersambung. Selalu gunakan Toko Kepercayaan Sistem. Nilai defaultnya adalah true. |
Tidak. |
| hubungkan melalui | Integration Runtime yang akan digunakan untuk menyambungkan ke penyimpanan data. Pelajari selengkapnya dari bagian Prasyarat. Jika tidak ditentukan, ia menggunakan Azure Integration Runtime default. | Tidak. |
Contoh:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"version": "2.0",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Versi 1.0
Properti berikut ini didukung untuk layanan tertaut Spark versi 1.0:
| Harta benda | Deskripsi | Diperlukan |
|---|---|---|
| jenis | Properti jenis harus diatur ke: Spark | Ya |
| host | Alamat IP atau nama host server Spark | Ya |
| port | Port TCP yang digunakan server Spark untuk mendengarkan koneksi klien. Jika Anda tersambung ke Azure HDInsight, tentukan port sebagai 443. | Ya |
| tipeServer | Jenis server Spark. Nilai yang diizinkan adalah: SharkServer, SharkServer2, SparkThriftServer |
Tidak. |
| Protokol Transportasi Thrift | Protokol transportasi yang digunakan dalam lapisan Thrift. Nilai yang diizinkan adalah: Biner, SASL, HTTP |
Tidak. |
| tipe autentikasi | Metode autentikasi yang digunakan untuk mengakses server Spark. Nilai yang diizinkan adalah: Anonim, Nama Pengguna, Nama PenggunaAndPassword, WindowsAzureHDInsightService |
Ya |
| nama pengguna | Nama pengguna yang Anda gunakan untuk mengakses Spark Server. | Tidak. |
| kata sandi | Kata sandi yang sesuai dengan pengguna. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman, atau referensi rahasia yang disimpan di Azure Key Vault. | Tidak. |
| httpPath | URL parsial yang sesuai dengan server Spark. | Tidak. |
| aktifkan SSL | Menentukan apakah koneksi ke server dienkripsi menggunakan TLS. Nilai defaultnya adalah false. | Tidak. |
| jalurSertifikatTepercaya | Jalur lengkap file .pem yang berisi sertifikat CA tepercaya untuk memverifikasi server saat menghubungkan melalui TLS. Properti ini hanya dapat diatur saat menggunakan TLS pada runtime integrasi yang dihosting sendiri. Nilai default yang digunakan adalah file cacerts.pem yang diinstal dengan Integrasi Runtime (IR). | Tidak. |
| useSystemTrustStore | Menentukan apakah akan menggunakan sertifikat CA dari penyimpanan kepercayaan sistem atau dari file PEM tertentu. Nilai defaultnya adalah false. | Tidak. |
| izinkanKetidakcocokanNamaHostCN | Menentukan apakah akan mewajibkan sertifikat TLS/SSL yang diterbitkan CA agar nama sertifikat sesuai dengan nama host server saat menghubungkan melalui TLS. Nilai defaultnya adalah false. | Tidak. |
| izinkanSertifikatServerTertandatanganiSendiri | Menentukan apakah akan mengizinkan sertifikat yang ditandatangani sendiri dari server. Nilai defaultnya adalah false. | Tidak. |
| hubungkan melalui | Integration Runtime yang akan digunakan untuk menyambungkan ke penyimpanan data. Pelajari selengkapnya dari bagian Prasyarat. Jika tidak ditentukan, ia menggunakan Azure Integration Runtime default. | Tidak. |
Contoh:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Properti kumpulan data
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan himpunan data, lihat artikel himpunan data. Bagian ini menyediakan daftar properti yang didukung oleh himpunan data Spark.
Untuk menyalin data dari Spark, atur properti jenis himpunan data ke SparkObject. Properti berikut didukung:
| Harta benda | Deskripsi | Diperlukan |
|---|---|---|
| jenis | Properti jenis himpunan data harus diatur ke: SparkObject | Ya |
| skema | Nama skema. | Tidak (jika "kueri" di sumber aktivitas spesifik) |
| tabel | Nama tabel tersebut. | Tidak (jika "kueri" di sumber aktivitas spesifik) |
| tableName (nama tabel) | Nama tabel dengan skema. Properti ini didukung untuk kompatibilitas ke belakang. Gunakan schema dan table untuk beban kerja baru. |
Tidak (jika "kueri" di sumber aktivitas spesifik) |
Contoh
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Properti Aktivitas Salin
Untuk daftar lengkap bagian dan properti yang tersedia guna mendefinisikan aktivitas, silakan lihat artikel Pipeline. Bagian ini menyediakan daftar properti yang didukung oleh sumber Spark.
Spark sebagai sumber
Untuk menyalin data dari Spark, atur jenis sumber dalam aktivitas salin ke SparkSource. Bagian sumber dari aktivitas salin ini mendukung properti berikut:
| Harta benda | Deskripsi | Diperlukan |
|---|---|---|
| jenis | Properti jenis sumber aktivitas salin harus diatur ke: SparkSource | Ya |
| kueri | Gunakan kueri SQL kustom untuk membaca data. Misalnya: "SELECT * FROM MyTable". |
Tidak (jika "tableName" ditentukan dalam himpunan data) |
Contoh:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Pemetaan jenis data untuk Spark
Saat Anda menyalin data dari dan ke Spark, pemetaan jenis data sementara berikut digunakan dalam layanan. Untuk memahami bagaimana aktivitas penyalinan memetakan skema sumber dan jenis data ke tujuan, lihat Pemetaan skema dan jenis data.
| Jenis data Spark | Jenis data layanan sementara (untuk versi 2.0) | Jenis data layanan sementara (untuk versi 1.0) |
|---|---|---|
| BooleanType | Boolean | Boolean |
| ByteType | Sbyte | Int16 |
| ShortType | Int16 | Int16 |
| IntegerType | Int32 | Int32 |
| Tipe Panjang | Int64 | Int64 |
| FloatType | Satu | Satu |
| DoubleType | Dobel | Dobel |
| JenisTanggal | TanggalWaktu | TanggalWaktu |
| TimestampType | DateTimeOffset | TanggalWaktu |
| StringType | string | string |
| BinaryType | Byte[] | Byte[] |
| Tipe Desimal | Desimal | Desimal String (presisi > 28) |
| ArrayType | string | string |
| StructType | string | string |
| JenisPeta | string | string |
| TimestampNTZType | TanggalWaktu | TanggalWaktu |
| Tipe Interval Tahun Bulan | string | Tidak didukung. |
| JenisIntervalWaktuHari | string | Tidak didukung. |
Properti aktivitas pencarian data
Untuk mempelajari detail tentang properti, lihat Aktivitas pencarian.
Siklus hidup dan peningkatan konektor Spark
Tabel berikut memperlihatkan tahap-tahap rilis dan log perubahan untuk versi konektor Spark yang berbeda:
| Versi | Tahap rilis | Riwayat Perubahan |
|---|---|---|
| Versi 1.0 | Removed | Tidak dapat diterapkan. |
| Versi 2.0 | Versi GA tersedia | • enableServerCertificateValidation didukung. • Nilai enableSSL default adalah benar. • Untuk jenis autentikasi WindowsAzureHDInsightService, nilai httpPath defaultnya adalah /sparkhive2.• DecimalType dibaca sebagai Jenis data desimal. • TimestampType ditafsirkan sebagai tipe data DateTimeOffset. • YearMonthIntervalType, DayTimeIntervalType dibaca sebagai jenis data String. • trustedCertPath, useSystemTrustStore, allowHostNameCNMismatch dan allowSelfSignedServerCert tidak didukung. • SharkServer dan SharkServer2 tidak didukung untuk serverType. • Biner dan SASL tidak didukung untuk thriftTransportProtocl. • Jenis autentikasi nama pengguna tidak didukung. |
Tingkatkan konektor Spark dari versi 1.0 ke versi 2.0
Di halaman Edit layanan tertaut , pilih 2.0 untuk versi dan konfigurasikan layanan tertaut dengan merujuk ke Properti layanan tertaut versi 2.0.
Pemetaan jenis data untuk layanan tertaut Spark versi 2.0 berbeda dari yang untuk versi 1.0. Untuk mempelajari pemetaan jenis data terbaru, lihat Pemetaan jenis data untuk Spark.
Konten terkait
Untuk daftar penyimpanan data yang didukung sebagai sumber dan pengumpan oleh aktivitas penyalinan, lihat penyimpanan data yang didukung.