Integrasi dan pengiriman berkelanjutan di Azure Data Factory
BERLAKU UNTUK:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Integrasi berkelanjutan adalah praktik untuk menguji setiap perubahan yang dilakukan pada basis kode Anda secara otomatis dan sedini mungkin. Pengiriman berkelanjutan mengikuti pengujian yang terjadi selama integrasi berkelanjutan dan mendorong perubahan pada sistem pentahapan atau produksi.
Di Azure Data Factory, integrasi dan pengiriman berkelanjutan (CI/CD) berarti memindahkan alur Data Factory dari satu lingkungan (pengembangan, pengujian, produksi) ke lingkungan lain. Azure Data Factory menggunakan templat Resource Manager untuk menyimpan konfigurasi berbagai entitas ADF (alur, himpunan data, aliran data, dan sebagainya). Ada dua metode yang disarankan untuk mendukung pabrik data ke lingkungan lain:
- Penyebaran otomatis menggunakan integrasi Data Factory dengan Azure Pipelines
- Unggah templat Resource Manager secara manual menggunakan integrasi UX Data Factory dengan Azure Resource Manager.
Catatan
Sebaiknya Anda menggunakan modul Azure Az PowerShell untuk berinteraksi dengan Azure. Untuk memulai, lihat Menginstal Azure PowerShell. Untuk mempelajari cara bermigrasi ke modul Az PowerShell, lihat Memigrasikan Azure PowerShell dari AzureRM ke Az.
Siklus hidup CI/CD
Catatan
Untuk informasi selengkapnya, lihat Peningkatan penyebaran berkelanjutan.
Di bawah ini adalah contoh ringkasan siklus hidup CI/CD di Azure Data Factory yang dikonfigurasi dengan Azure Repos Git. Untuk informasi selengkapnya tentang cara mengonfigurasi repositori Git, lihat Kontrol sumber di Azure Data Factory.
Pabrik data pengembangan dibuat dan dikonfigurasi dengan Azure Repos Git. Semua pengembang harus memiliki izin untuk menulis sumber daya Data Factory seperti alur dan himpunan data.
Pengembang membuat cabang fitur untuk melakukan perubahan. Mereka mendebug eksekusi alur dengan perubahan terbaru mereka. Untuk informasi selengkapnya tentang cara mendebug eksekusi alur, lihat Pengembangan dan debugging berulang dengan Azure Data Factory.
Setelah pengembang yakin dengan perubahan, mereka membuat permintaan pull dari cabang fitur mereka ke cabang utama atau kolaborasi agar perubahan mereka ditinjau oleh rekan-rekan.
Setelah permintaan pull disetujui dan perubahan digabungkan di cabang utama, perubahan tersebut akan diterbitkan ke pabrik pengembangan.
Saat tim siap untuk menyebarkan perubahan ke pabrik pengujian atau UAT (Pengujian Penerimaan Pengguna), tim pergi ke rilis Azure Pipelines dan menyebarkan versi pabrik pengembangan yang dikehendaki ke UAT. Penyebaran ini berlangsung sebagai bagian dari tugas Azure Pipelines dan menggunakan parameter templat Resource Manager untuk menerapkan konfigurasi yang sesuai.
Setelah perubahan telah diverifikasi di pabrik pengujian, sebarkan ke pabrik produksi dengan menggunakan tugas rilis alur berikutnya.
Catatan
Hanya pabrik pengembangan yang dikaitkan dengan repositori Git. Pabrik pengujian dan produksi tidak boleh memiliki repositori git yang terkait dengan pabrik tersebut dan hanya boleh diperbarui melalui alur Azure DevOps atau melalui templat Pengelolaan Sumber Daya.
Gambar di bawah menyoroti berbagai langkah siklus hidup ini.
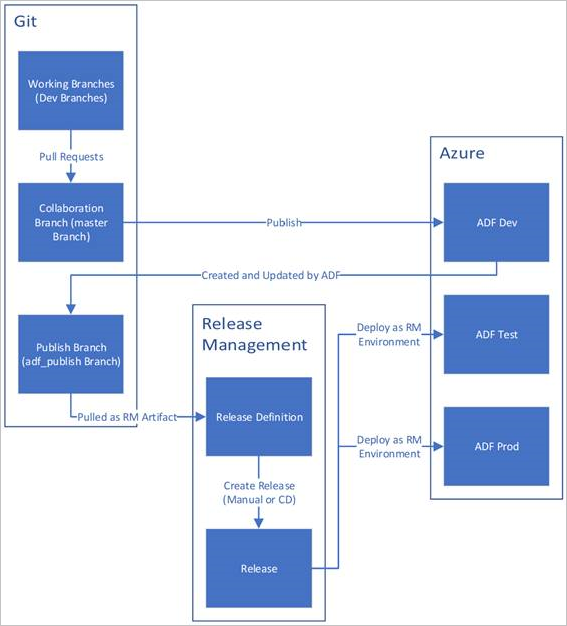
Praktik terbaik untuk CI/CD
Jika Anda menggunakan integrasi Git dengan pabrik data Anda dan memiliki alur CI/CD yang memindahkan perubahan dari pengembangan ke pengujian dan kemudian ke produksi, kami merekomendasikan praktik terbaik ini:
Integrasi Git. Konfigurasikan hanya pabrik data pengembangan Anda dengan integrasi Git. Perubahan pada pengujian dan produksi disebarkan melalui CI/CD dan tidak memerlukan integrasi Git.
Skrip pra- dan pasca-penyebaran. Sebelum langkah penyebaran Resource Manager di CI/CD, Anda perlu menyelesaikan tugas tertentu, seperti menghentikan dan memulai ulang pemicu dan melakukan pembersihan. Sebaiknya Anda menggunakan skrip PowerShell sebelum dan sesudah tugas penyebaran. Untuk informasi selengkapnya, lihat Memperbarui pemicu aktif. Tim pabrik data telah menyediakan skrip untuk digunakan yang berada di bagian bawah halaman ini.
Catatan
Gunakan PrePostDeploymentScript.Ver2.ps1 apabila Anda hanya ingin menonaktifkan/mengaktifkan pemicu yang telah dimodifikasi alih-alih menonaktifkan/mengaktifkan semua pemicu selama CI/CD.
Peringatan
Pastikan untuk menggunakan PowerShell Core dalam tugas ADO untuk menjalankan skrip.
Peringatan
Jika tidak menggunakan modul PowerShell dan Data Factory versi terbaru, Anda mungkin mengalami kesalahan deserialisasi saat menjalankan perintah.
Runtime integrasi dan berbagi. Runtime integrasi tidak sering berubah dan sama di semua tahap dalam CI/CD Anda. Jadi Data Factory mengharapkan Anda memiliki nama, jenis, dan subjenis runtime integrasi yang sama di semua tahap CI/CD. Jika Anda ingin berbagi runtime integrasi di semua tahap, pertimbangkan untuk menggunakan pabrik ternary hanya untuk mengisi runtime integrasi bersama. Anda dapat menggunakan pabrik bersama ini di semua lingkungan Anda sebagai jenis runtime integrasi tertaut.
Catatan
Berbagi runtime integrasi hanya tersedia untuk runtime integrasi yang dihost sendiri. Runtime integrasi Azure-SSIS tidak mendukung berbagi.
Penyebaran titik akhir privat terkelola. Jika titik akhir privat sudah ada di pabrik dan Anda mencoba untuk menyebarkan templat ARM yang berisi titik akhir privat dengan nama yang sama tetapi dengan properti yang diubah, penyebaran akan gagal. Dengan kata lain, Anda dapat berhasil menyebarkan titik akhir privat asalkan memiliki properti yang sama dengan yang sudah ada di pabrik. Jika properti berbeda di antara lingkungan, Anda dapat menggantinya dengan membuat parameter properti tersebut dan menyediakan nilai masing-masing selama penyebaran.
Key Vault. Jika Anda menggunakan layanan tertaut yang informasi koneksinya disimpan di Azure Key Vault, sebaiknya simpan brankas kunci terpisah untuk lingkungan yang berbeda. Anda juga dapat mengonfigurasi tingkat izin terpisah untuk setiap brankas kunci. Misalnya, Anda mungkin tidak ingin anggota tim Anda memiliki izin ke rahasia produksi. Jika Anda mengikuti pendekatan ini, sebaiknya Anda menyimpan nama rahasia yang sama di semua tahap. Jika menyimpan nama rahasia yang sama, Anda tidak perlu membuat parameter setiap string koneksi di seluruh lingkungan CI/CD karena satu-satunya hal yang berubah adalah nama brankas kunci, yang merupakan parameter terpisah.
Penamaan sumber daya. Dikarenakan batasan templat ARM, masalah dalam penyebaran mungkin terjadi jika sumber daya Anda berisi spasi dalam nama. Tim Azure Data Factory merekomendasikan penggunaan karakter '_' atau '-', bukan spasi untuk sumber daya. Misalnya, 'Alur_1' akan menjadi nama yang lebih disukai daripada 'Alur 1'.
Mengubah repositori. ADF mengelola konten repositori GIT secara otomatis. Mengubah atau menambahkan file atau folder yang tidak terkait secara manual ke mana saja di folder data repositori Git ADF dapat menyebabkan kesalahan pemuatan sumber daya. Misalnya, keberadaan file .bak dapat menyebabkan kesalahan CI/CD ADF, sehingga harus dihapus agar ADF dimuat.
Kontrol eksposur dan bendera fitur. Saat bekerja dalam tim, ada instans di mana Anda dapat menggabungkan perubahan, tetapi tidak ingin perubahan dijalankan di lingkungan yang ditinggikan seperti PROD dan QA. Untuk menangani skenario ini, tim ADF merekomendasikan konsep Azure DevOps menggunakan bendera fitur. Di ADF, Anda dapat menggabungkan parameter global dan aktivitas jika kondisi untuk menyembunyikan serangkaian logika berdasarkan bendera lingkungan ini.
Untuk mempelajari cara menyiapkan bendera fitur, lihat tutorial video di bawah:
Fitur yang tidak didukung
Dari segi desain, Data Factory tidak mengizinkan tindakan tebang pilih penerapan atau penerbitan selektif sumber daya. Terbitan akan mencakup semua perubahan yang dibuat di pabrik data.
- Entitas pabrik data bergantung pada satu sama lain. Misalnya, pemicu bergantung pada alur, dan alur bergantung pada himpunan data dan alur lainnya. Penerbitan selektif subset sumber daya dapat menyebabkan perilaku dan kesalahan yang tidak terduga.
- Pada kesempatan yang langka, saat Anda membutuhkan penerbitan selektif, pertimbangkan untuk menggunakan perbaikan. Untuk informasi selengkapnya, lihat Lingkungan produksi perbaikan.
Tim Azure Data Factory tidak merekomendasikan penetapan kontrol Azure RBAC ke entitas individual (alur, himpunan data, dan sebagainya) di pabrik data. Misalnya, jika pengembang memiliki akses ke pipeline atau set data, mereka harus dapat mengakses semua pipeline atau set data di pabrik data. Jika Anda merasa perlu menerapkan banyak peran Azure dalam pabrik data, lihat menerapkan pabrik data kedua.
Anda tidak dapat menerbitkan dari cabang privat.
Anda saat ini tidak dapat menghosting proyek di Bitbucket.
Anda saat ini tidak dapat mengekspor dan mengimpor pemberitahuan dan matriks sebagai parameter.
Dalam repositori kode di bawah cabang adf_publish, folder bernama 'PartialArmTemplates' saat ini ditambahkan di samping folder 'linkedTemplates', file 'ARMTemplateForFactory.json' dan 'ARMTemplateParametersForFactory.json' sebagai bagian dari penerbitan dengan kontrol sumber.
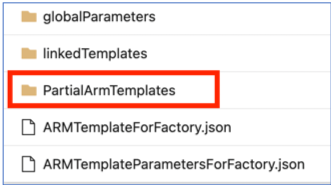
Kami tidak akan lagi menerbitkan 'PartialArmTemplates' ke cabang adf_publish mulai 1-November 2021.
Tidak ada tindakan yang diperlukan kecuali Anda menggunakan 'PartialArmTemplates'. Jika tidak, alihkan ke mekanisme yang didukung untuk penyebaran menggunakan: file 'ARMTemplateForFactory.json' atau 'linkedTemplates'.
Konten terkait
- Peningkatan penyebaran berkelanjutan
- Mengotomatiskan integrasi berkelanjutan menggunakan rilis Azure Pipelines
- Mempromosikan template Resource Manager secara manual ke setiap lingkungan
- Gunakan parameter kustom dengan template Resource Manager
- Templat Resource Manager tertaut
- Menggunakan lingkungan produksi perbaikan
- Sampel skrip pra dan pos penerapan
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk