Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk / Saran
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Dalam tutorial ini, Anda menggunakan antarmuka pengguna (UX) Azure Data Factory untuk membuat alur yang menyalin dan mengubah data dari sumber Azure Data Lake Storage (ADLS) Gen2 ke sink ADLS Gen2 menggunakan aliran data pemetaan. Pola konfigurasi dalam tutorial ini dapat diperluas saat mentransformasikan data menggunakan alur data pemetaan
Tutorial ini dimaksudkan untuk memetakan aliran data secara umum. Aliran data tersedia baik di alur Azure Data Factory maupun Synapse. Jika Anda baru menggunakan aliran data di Alur Azure Synapse, ikuti Data Flow menggunakan Alur Azure Synapse.
Dalam tutorial ini, Anda melakukan tugas-tugas berikut:
- Membuat pabrik data.
- Buat alur dengan aktivitas Data Flow.
- Bangun aliran data pemetaan dengan empat transformasi.
- Uji coba jalur pipa.
- Memantau aktivitas Data Flow
Prasyarat
- langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun Azure free sebelum Memulai.
- Azure Data Lake Storage Gen2 account. Anda menggunakan penyimpanan ADLS sebagai penyimpanan data sumber dan sink. Jika Anda tidak memiliki akun penyimpanan, lihat Buat akun penyimpanan Azure untuk langkah-langkah membuatnya.
- Unduh MoviesDB.csv di sini. Untuk mengambil file dari GitHub, salin konten ke editor teks pilihan Anda untuk disimpan secara lokal sebagai file .csv. Unggah file ke akun penyimpanan Anda dalam kontainer bernama 'sample-data'.
Membuat pabrik data
Dalam langkah ini, Anda membuat sebuah data factory dan membuka antarmuka pengguna Data Factory untuk membuat pipeline di data factory.
Buka Microsoft Edge atau Chrome. Saat ini, UI Data Factory hanya didukung di browser web Microsoft Edge dan Google Chrome.
Di menu atas, pilih Buat sumber daya>Analitik>Pabrik Data :
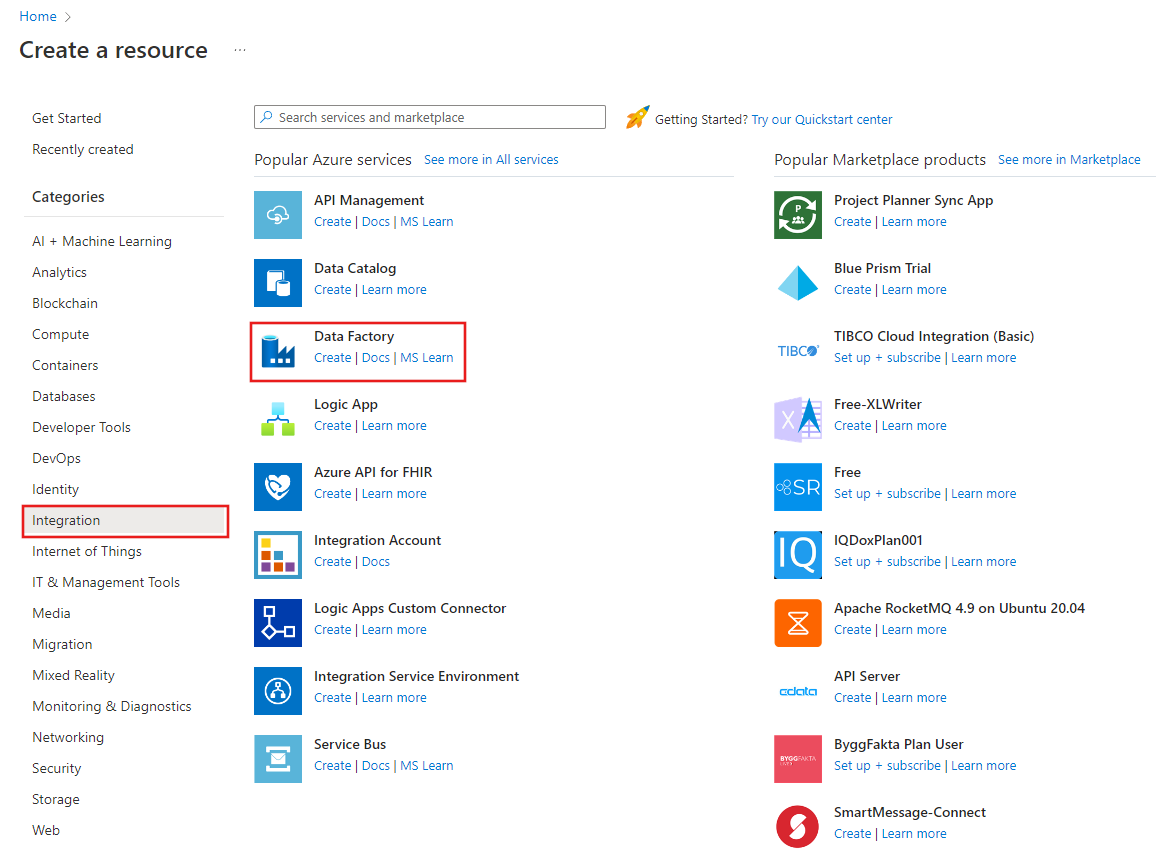
Di halaman Pabrik data baru, di bawah Nama, masukkan ADFTutorialDataFactory.
Nama pabrik data Azure harus unik secara global. Jika Anda menerima pesan kesalahan tentang nilai nama, masukkan nama yang berbeda untuk pabrik data. (misalnya, yournameADFTutorialDataFactory). Untuk aturan penamaan artefak Data Factory, lihat artikel aturan penamaan Data Factory.
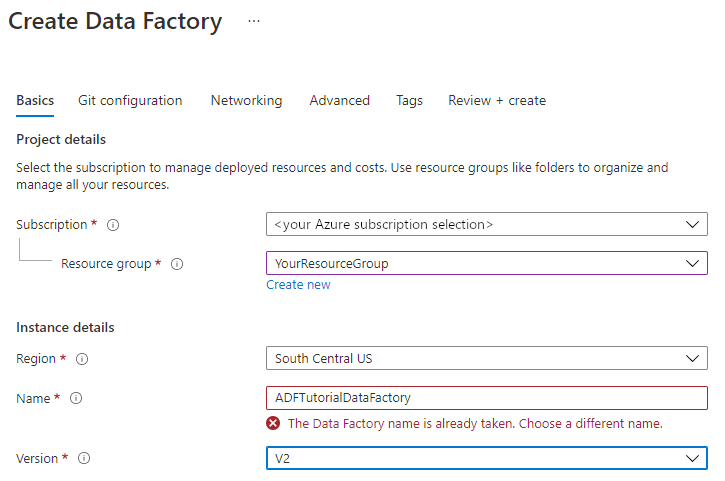
Pilih Azure subscription tempat Anda ingin membuat pabrik data.
Untuk Grup Sumber Daya, lakukan salah satu langkah berikut:
Pilih Gunakan yang ada, lalu pilih grup sumber daya yang ada dari menu drop-down.
Pilih Buat baru, lalu masukkan nama grup sumber daya.
Untuk mempelajari tentang grup sumber daya, lihat Gunakan grup sumber daya untuk mengelola sumber daya Azure Anda.
Di bawah Versi, pilih V2.
Pada bagian Wilayah, pilih lokasi untuk pabrik data. Hanya lokasi yang didukung yang ditampilkan di daftar drop-down. Penyimpanan data (misalnya, Azure Storage dan SQL Database) dan komputasi (misalnya, Azure HDInsight) yang digunakan oleh pabrik data dapat berada di wilayah lain.
Pilih Ulas + buat, lalu pilih Buat.
Setelah pembuatan selesai, Anda akan melihat pemberitahuan di pusat Pemberitahuan. Pilih Buka halaman sumber daya untuk masuk ke halaman Data Factory.
Pilih Luncurkan studio untuk meluncurkan studio Data Factory di tab terpisah.
Membuat alur dengan aktivitas Data Flow
Dalam langkah ini, Anda membuat alur yang berisi aktivitas Data Flow.
Pada beranda Azure Data Factory, pilih Orchestrate.
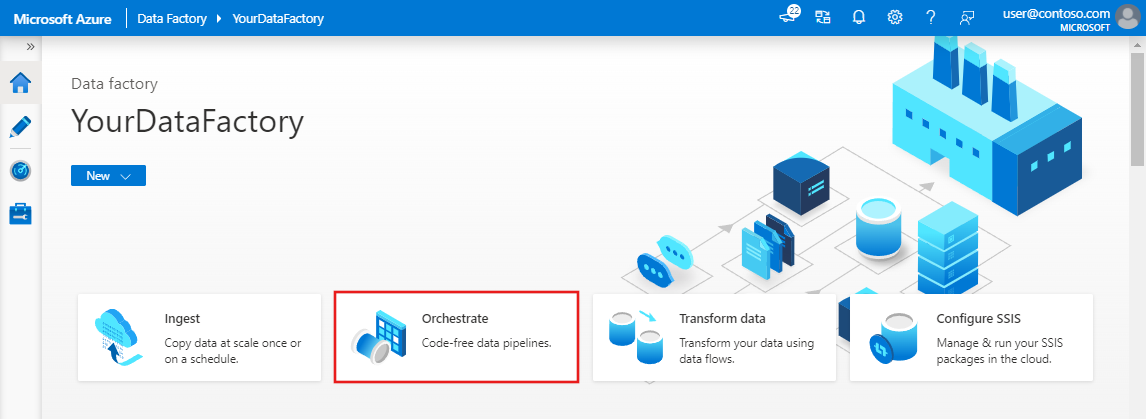
Sekarang peluang terbuka untuk jalur baru. Di tab Umum untuk properti alur, masukkan TransformMovies untuk Nama alur.
Di panel Aktivitas, perluas akordeon Pindah dan Transformasi. Seret dan letakkan aktivitas Data Flow dari panel ke kanvas alur.
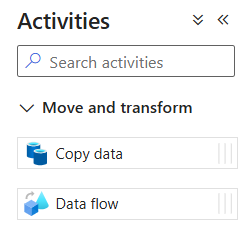
Beri nama aktivitas aliran data Anda DataFlow1.
Di bilah atas kanvas alur kerja, geser slider Data Flow debug untuk mengaktifkan. Mode debug memungkinkan pengujian interaktif logika transformasi terhadap kluster Spark langsung. Data Flow kluster membutuhkan waktu 5-7 menit untuk pemanasan dan pengguna disarankan untuk mengaktifkan debug terlebih dahulu jika mereka berencana untuk melakukan pengembangan Data Flow. Untuk informasi selengkapnya, lihat Mode Debug.

Bangun logika transformasi di kanvas aliran data
Dalam langkah ini, Anda membangun aliran data yang mengambil moviesDB.csv dalam penyimpanan ADLS dan menggabungkan peringkat rata-rata komedi dari 1910 hingga 2000. Anda kemudian menulis file ini kembali ke penyimpanan ADLS.
Di panel di bawah kanvas, buka Pengaturan aktivitas aliran data Anda dan pilih Baru, yang terletak di samping bidang aliran data. Ini membuka kanvas aliran data.
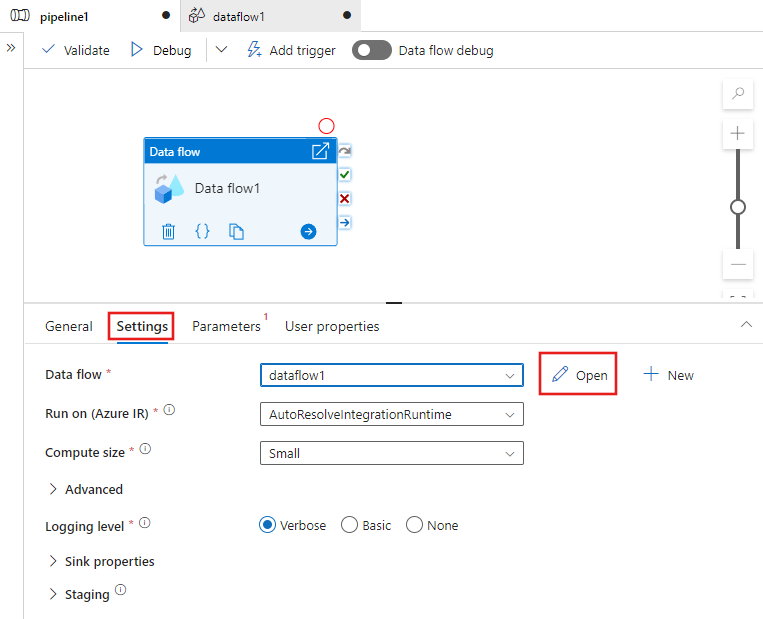
Di panel Properti di bawah Umum, beri nama aliran data Anda: TransformMovies.
Di kanvas aliran data, tambahkan sumber dengan memilih kotak Tambahkan Sumber .
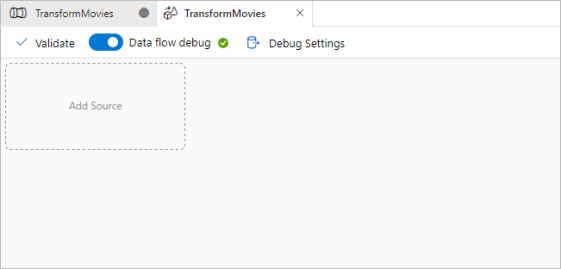
Beri nama sumber Anda MoviesDB. Klik Baru untuk membuat himpunan data sumber baru.
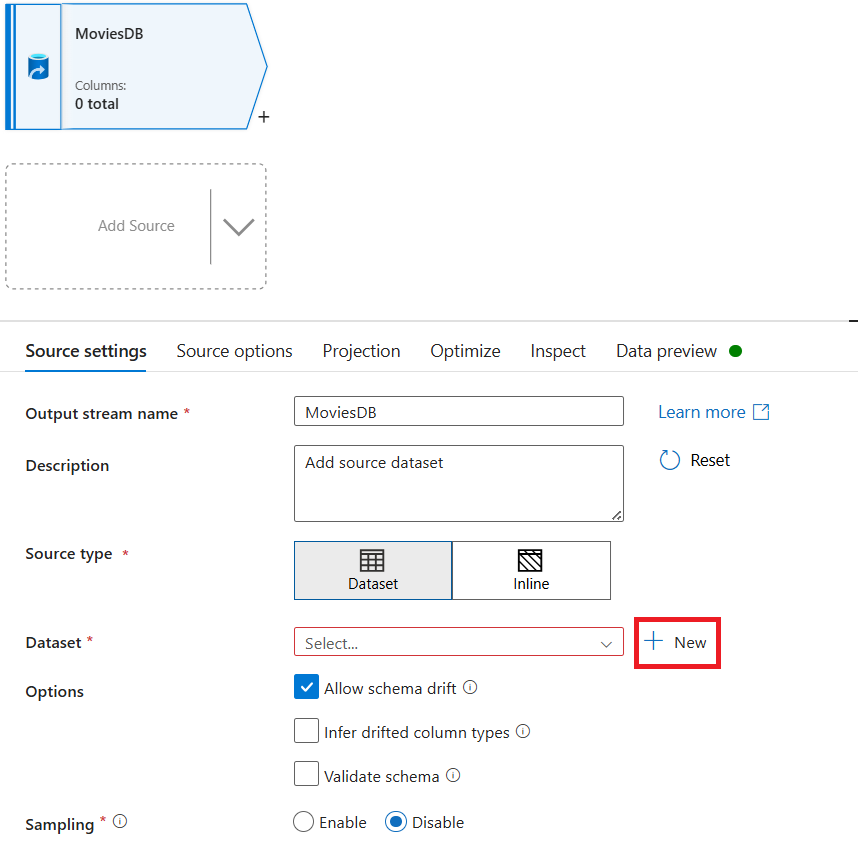
Pilih Azure Data Lake Storage Gen2. Pilih Lanjutkan.
Pilih DelimitedText. Pilih Lanjutkan.
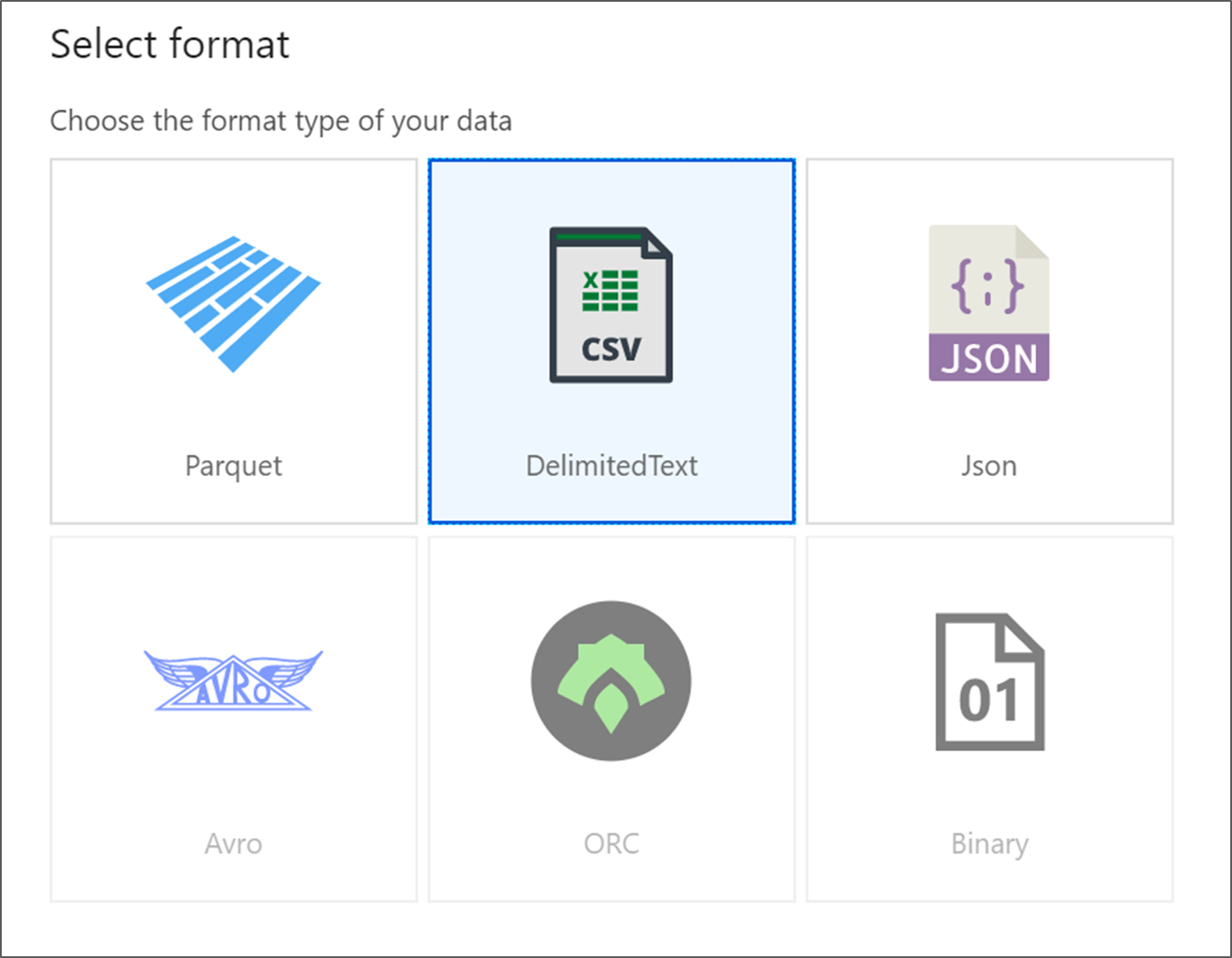
Beri nama himpunan data Anda MoviesDB. Di dropdown layanan tertaut, pilih Baru.

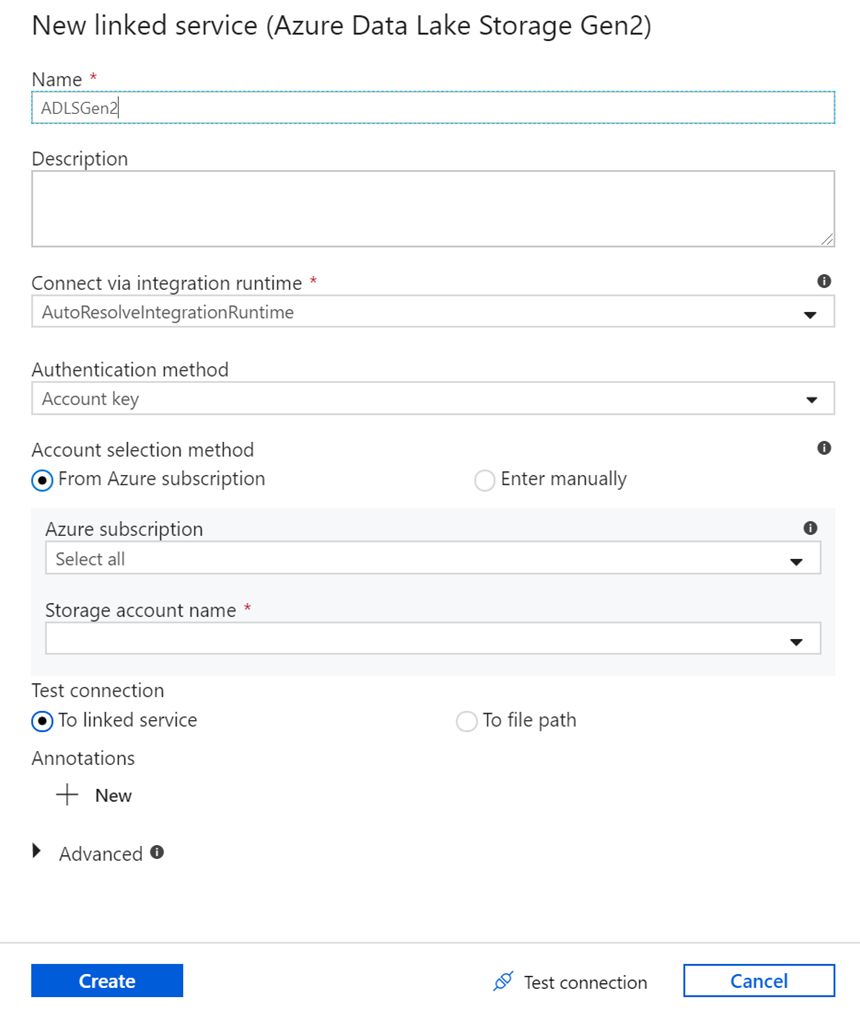
Di layar pembuatan layanan yang ditautkan, beri nama layanan tertaut ADLS gen2 Anda ADLSGen2 dan tentukan metode autentikasi Anda. Lalu masukkan informasi masuk koneksi Anda. Dalam tutorial ini, kami menggunakan Kunci akun untuk terhubung ke akun penyimpanan kami. Anda dapat memilih Uji koneksi untuk memverifikasi kredensial Anda dimasukkan dengan benar. Pilih Buat setelah selesai.
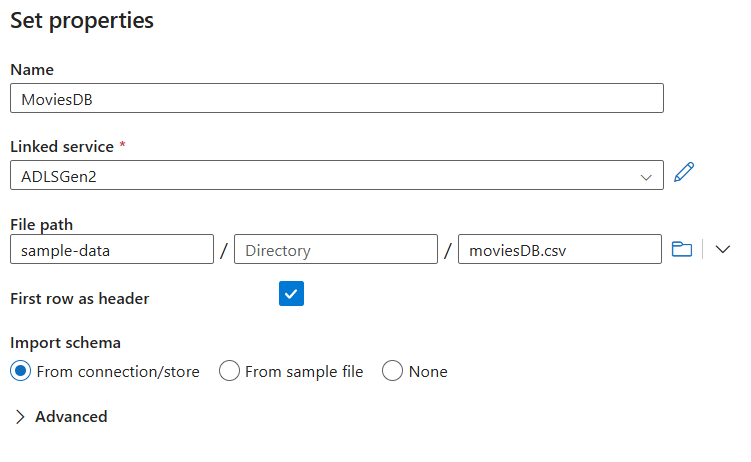
Setelah Anda kembali ke layar pembuatan himpunan data, masukkan lokasi file Anda di bawah bidang Jalur file. Dalam tutorial ini, file moviesDB.csv terletak di sampel-data kontainer. Saat file memiliki header, centang Baris pertama sebagai header. Pilih Dari koneksi/penyimpanan untuk mengimpor skema header langsung dari file dalam penyimpanan. Pilih OK setelah selesai.
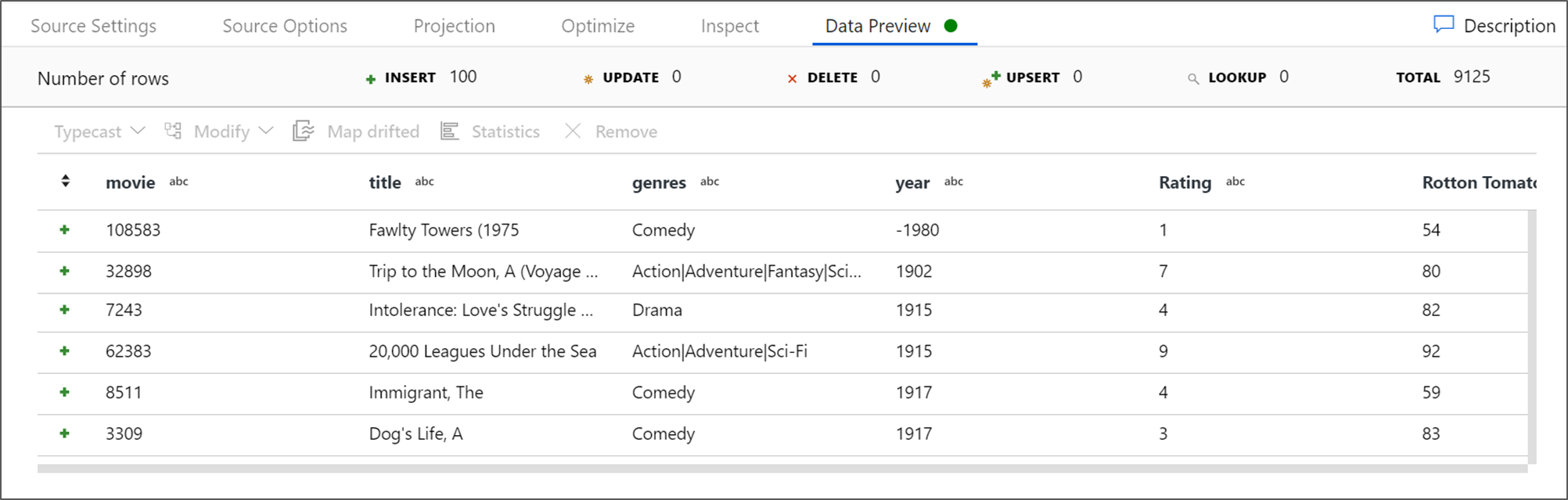
Jika kluster debug Anda telah dimulai, buka tab Pratinjau Data dari transformasi sumber dan pilih Refresh untuk mendapatkan rekam jepret data. Anda dapat menggunakan pratinjau data untuk memverifikasi bahwa transformasi Anda dikonfigurasi dengan benar.
Di samping simpul sumber Anda pada kanvas aliran data, klik ikon plus untuk menambahkan transformasi baru. Transformasi pertama yang Anda tambahkan adalah Filter.
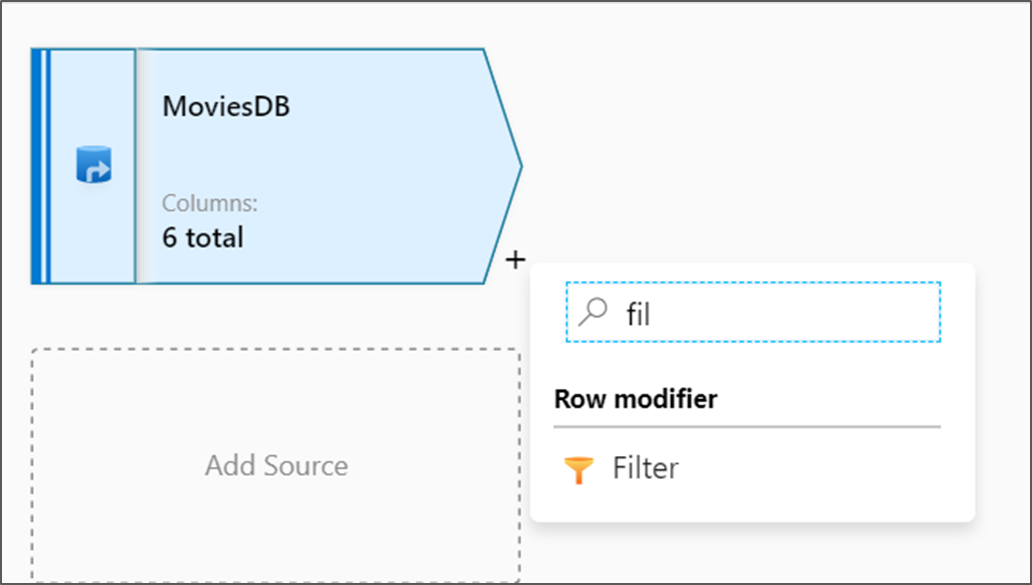
Beri nama filter transformasi Anda FilterYears. Pilih kotak ekspresi di samping Filter aktif lalu Buka penyusun ekspresi. Di sini Anda menentukan kondisi pemfilteran Anda.
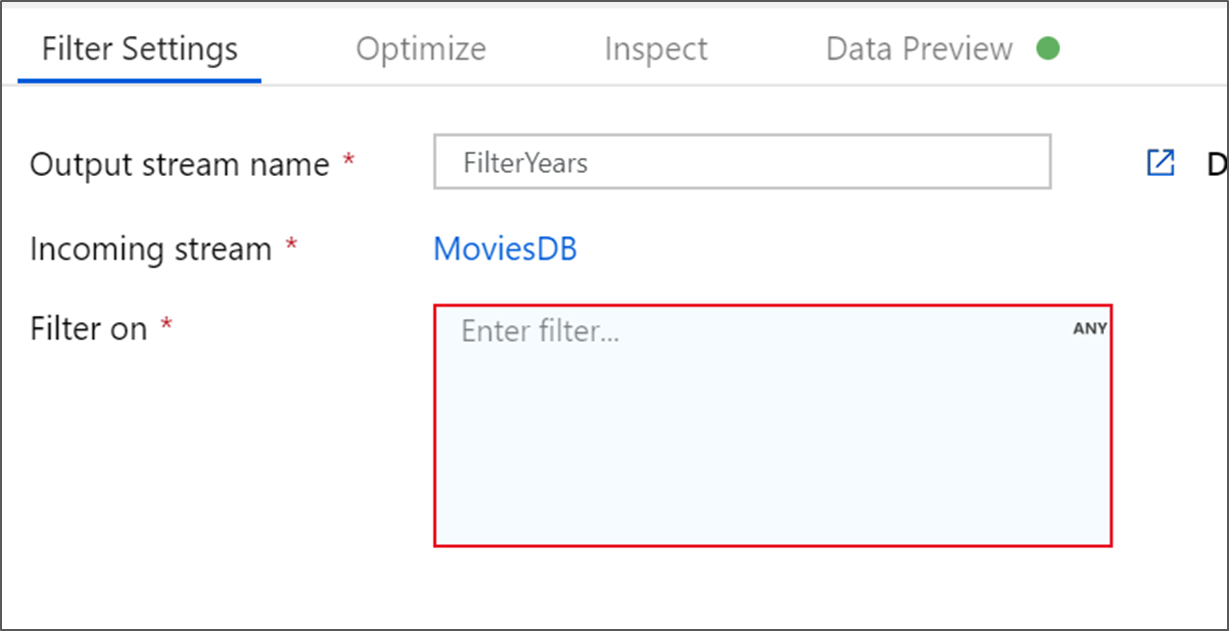
Penyusun ekspresi aliran data memungkinkan Anda membangun ekspresi secara interaktif yang digunakan dalam berbagai transformasi. Ekspresi dapat menyertakan fungsi bawaan, kolom dari skema input, dan parameter yang ditentukan pengguna. Untuk informasi selengkapnya tentang cara membuat ekspresi, lihat penyusun ekspresi Data Flow.
Dalam tutorial ini, Anda ingin memfilter film genre komedi yang keluar antara tahun 1910 dan 2000. Karena tahun saat ini adalah untai (karakter), Anda perlu mengonversinya menjadi bilangan bulat menggunakan fungsi
toInteger(). Gunakan operator yang lebih besar dari atau sama dengan (>=) dan lebih kecil dari atau sama dengan (<=) untuk membandingkan dengan nilai tahun harfiah 1910 dan 2000. Gabungkan ekspresi-ekspresi ini dengan operator &&. Ekspresi akan keluar sebagai:toInteger(year) >= 1910 && toInteger(year) <= 2000Untuk menemukan film mana yang merupakan komedi, Anda dapat menggunakan fungsi
rlike()untuk menemukan pola 'Komedi' dalam genre kolom. Satukan ekspresirlikedengan perbandingan tahun untuk mendapatkan:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Jika Anda memiliki kluster debug aktif, Anda dapat memverifikasi logika Anda dengan memilih Refresh untuk melihat output ekspresi dibandingkan dengan input yang digunakan. Ada lebih dari satu jawaban yang tepat tentang bagaimana Anda dapat menyelesaikan logika ini menggunakan bahasa ekspresi aliran data.
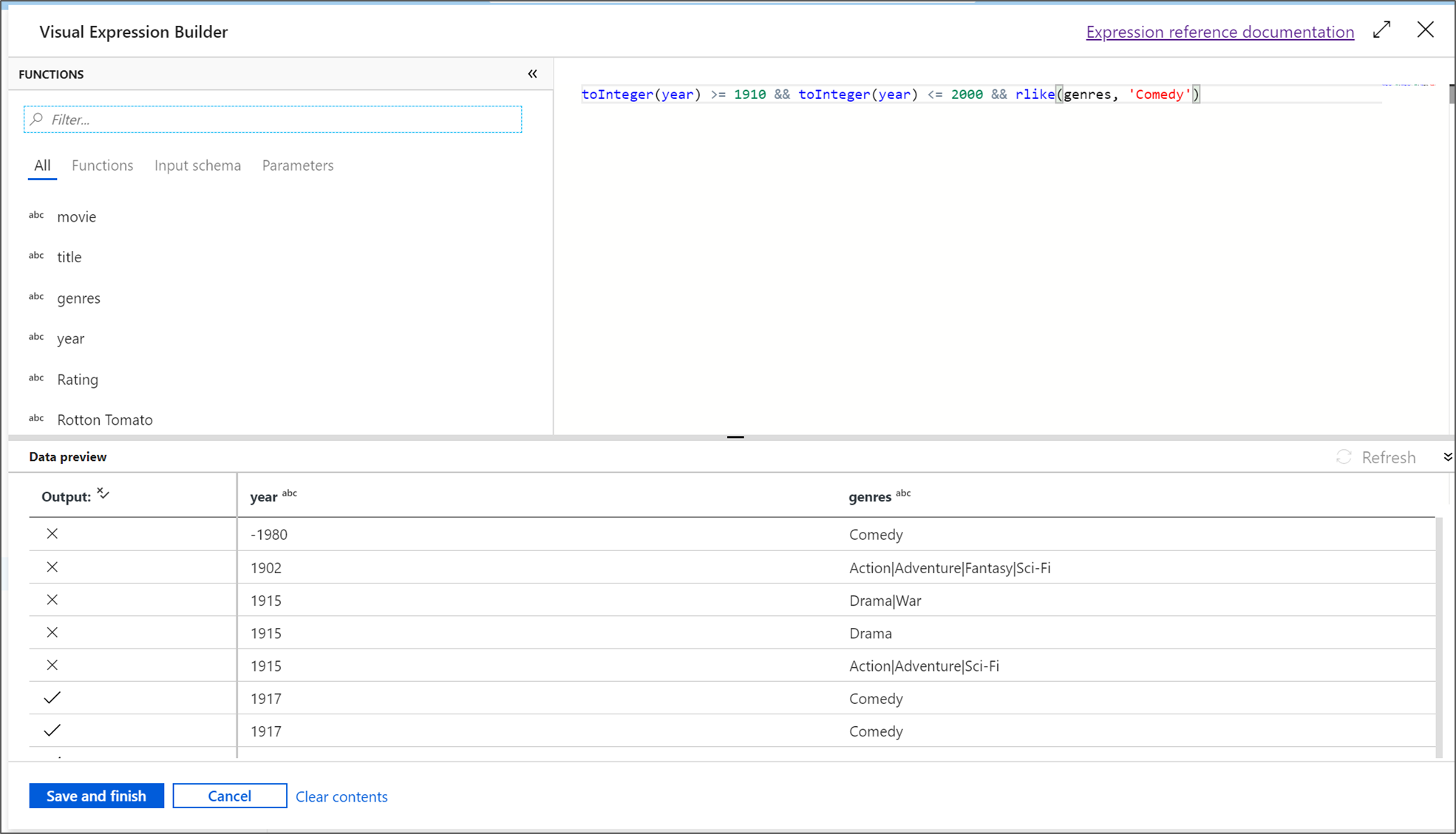
Pilih Simpan dan Selesai setelah Anda selesai dengan ekspresi Anda.
Ambil Pratinjau Data untuk memverifikasi bahwa filter berfungsi dengan benar.
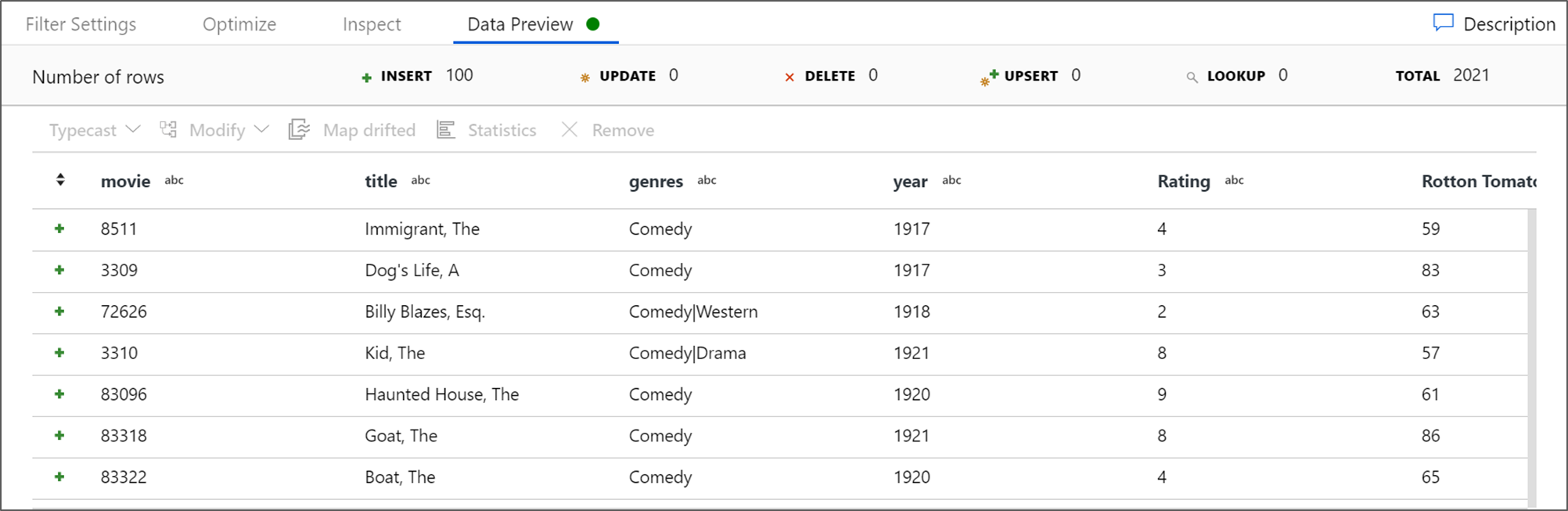
Transformasi berikutnya yang akan Anda tambahkan adalah transformasi Agregat di bawah pengubah Skema.
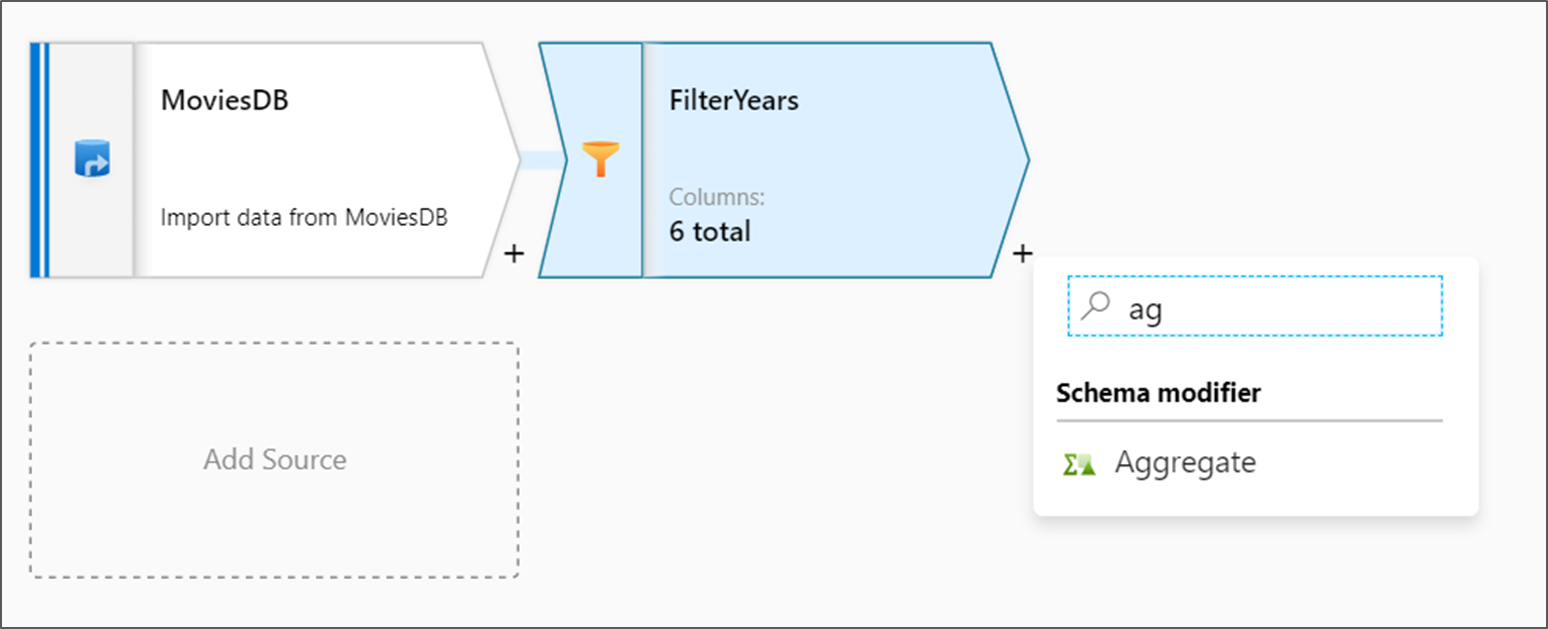
Beri nama transformasi agregat Anda AggregateComedyRatings. Di tab Kelompokkan menurut, pilih tahun dari dropdown untuk mengelompokkan agregasi menurut tahun film yang telah keluar.
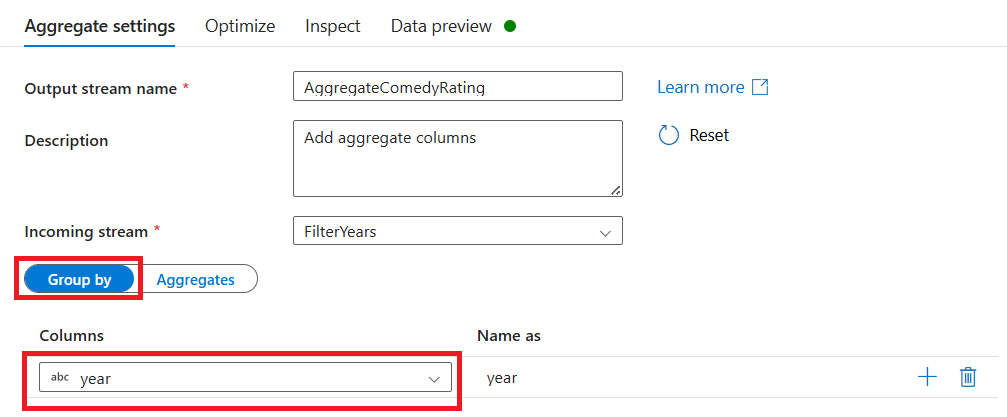
Masuk ke tab Agregat. Di kotak teks kiri, beri nama kolom agregat AverageComedyRating. Pilih kotak ekspresi kanan untuk memasukkan ekspresi agregat melalui pembuat ekspresi.
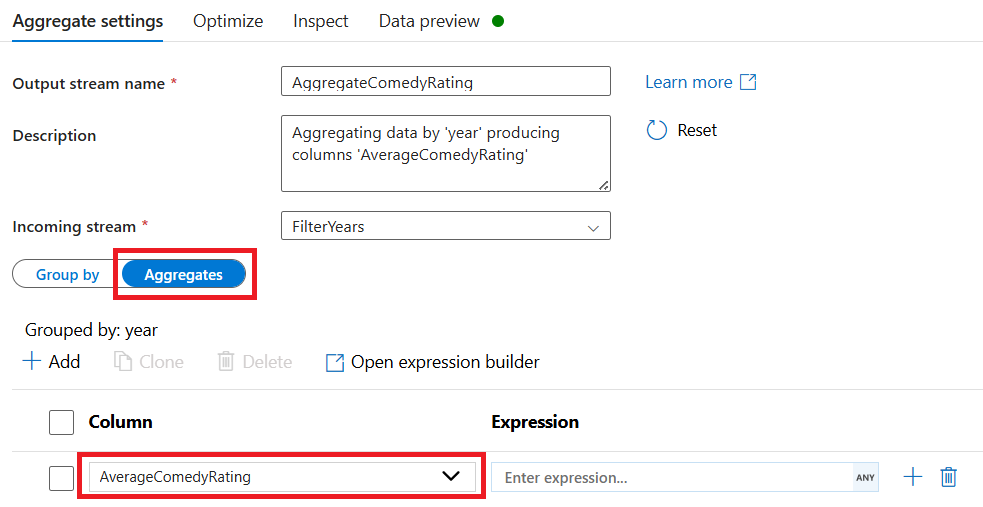
Untuk mendapatkan rata-rata kolom Peringkat, gunakan
avg()fungsi agregat. Karena Peringkat adalah untai (karakter) danavg()mengambil input numerik, kita harus mengonversi nilai ke angka melalui fungsitoInteger(). Ekspresi ini terlihat seperti:avg(toInteger(Rating))Pilih Simpan dan Selesai setelah selesai.

Masuk ke tab Pratinjau Data untuk melihat output transformasi. Perhatikan hanya dua kolom yang ada di sana, tahun dan AverageComedyRating.
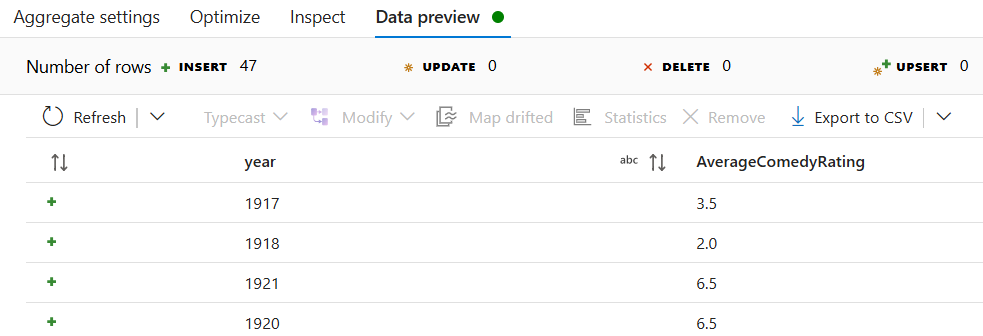
Selanjutnya, Anda ingin menambahkan transformasi Sink di bawah Tujuan.
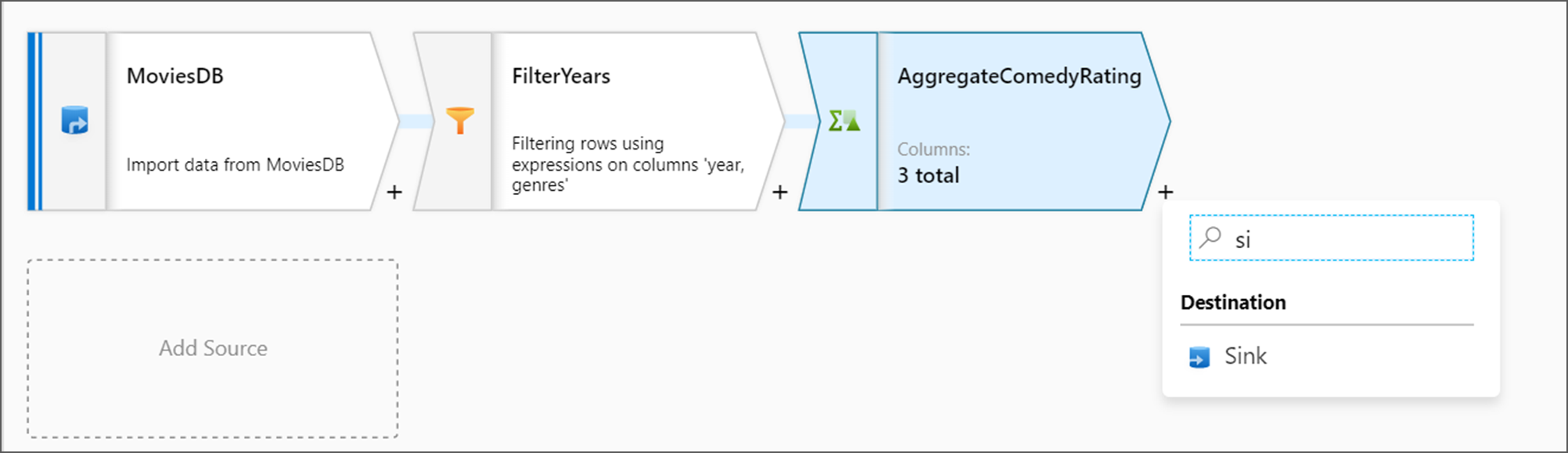
Beri nama sink Anda Sink. Klik Baru untuk membuat himpunan data sink Anda.
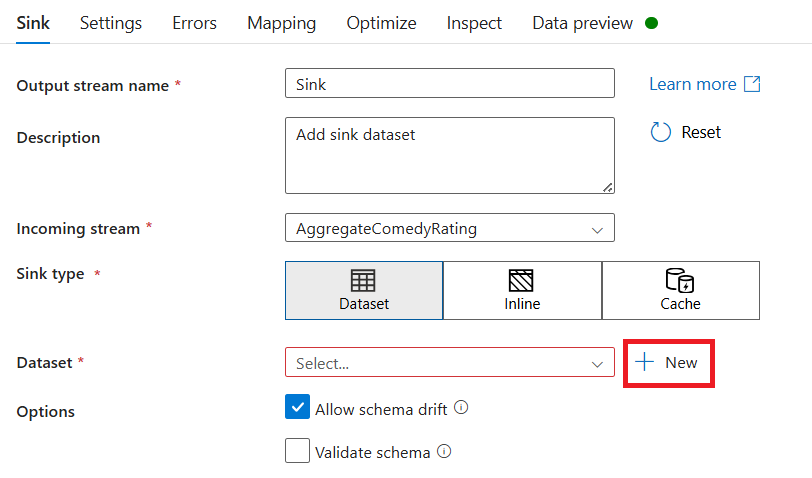
Pilih Azure Data Lake Storage Gen2. Pilih Lanjutkan.
Pilih DelimitedText. Pilih Lanjutkan.
Beri nama dataset sink Anda MoviesSink. Untuk layanan tertaut, pilih layanan tertaut ADLS gen2 yang Anda buat di langkah 6. Masukkan folder output untuk menulis data Anda. Dalam tutorial ini, kita menulis ke folder 'output' dalam kontainer 'sample-data'. Folder tidak perlu ada sebelumnya dan dapat dibuat secara dinamis. Atur Baris pertama sebagai header ke true dan pilih Tidak ada untuk Skema impor. Pilih Selesai.
Sekarang Anda sudah selesai membangun aliran data Anda. Anda siap untuk menjalankannya pada pipeline.
Menjalankan dan memantau Data Flow
Anda dapat men-debug alur sebelum memublikasikannya. Dalam langkah ini, Anda akan memicu proses debug dari pipeline aliran data. Meskipun pratinjau data tidak menulis data, menjalankan debug menulis data ke tujuan keluaran Anda.
Pergi ke kanvas alur. Klik Debug untuk memicu eksekusi debug.

Debug alur aktivitas Data Flow menggunakan kluster debug aktif tetapi masih membutuhkan waktu setidaknya satu menit untuk diinisialisasi. Anda dapat melacak kemajuan melalui tab Output . Setelah eksekusi berhasil, arahkan mouse ke atas eksekusi dan pilih ikon kacamata untuk membuka panel pemantauan.
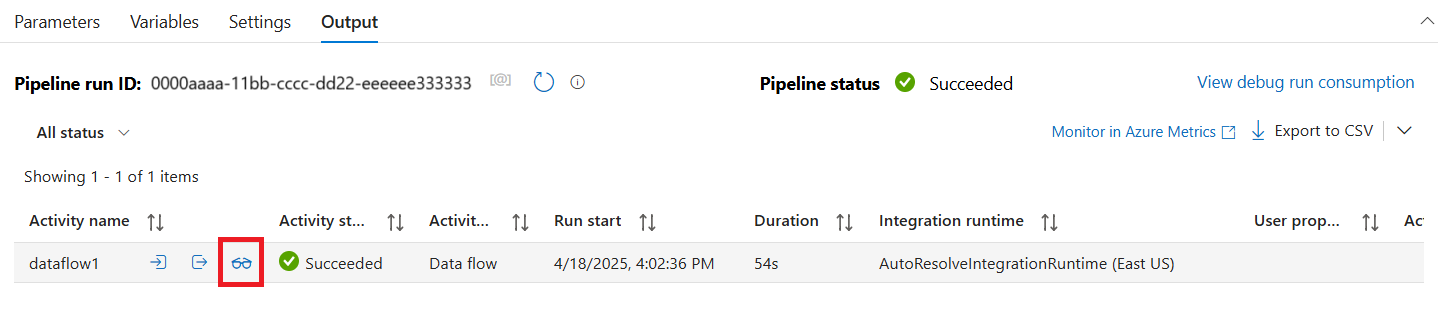
Di panel pemantauan, pilih tombol Tahapan untuk melihat jumlah baris dan waktu yang dihabiskan di setiap langkah transformasi.
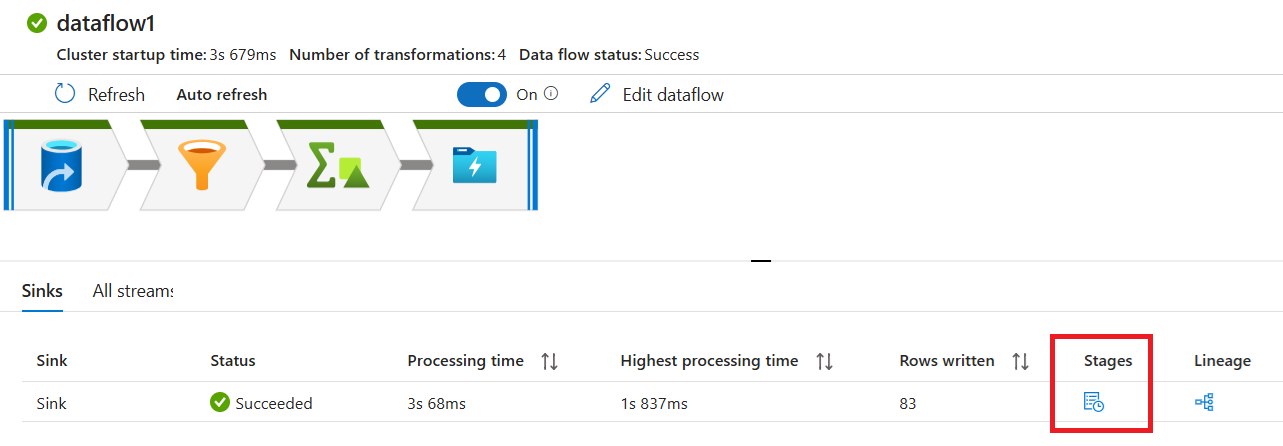
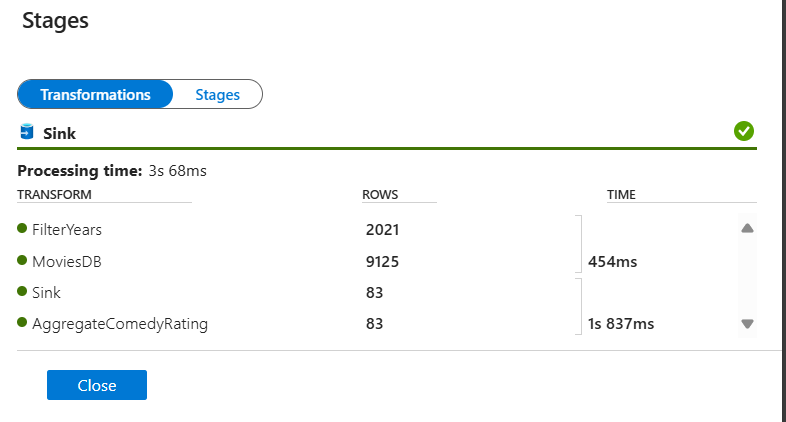
Klik transformasi untuk mendapatkan informasi terperinci tentang kolom dan pemartisian data.
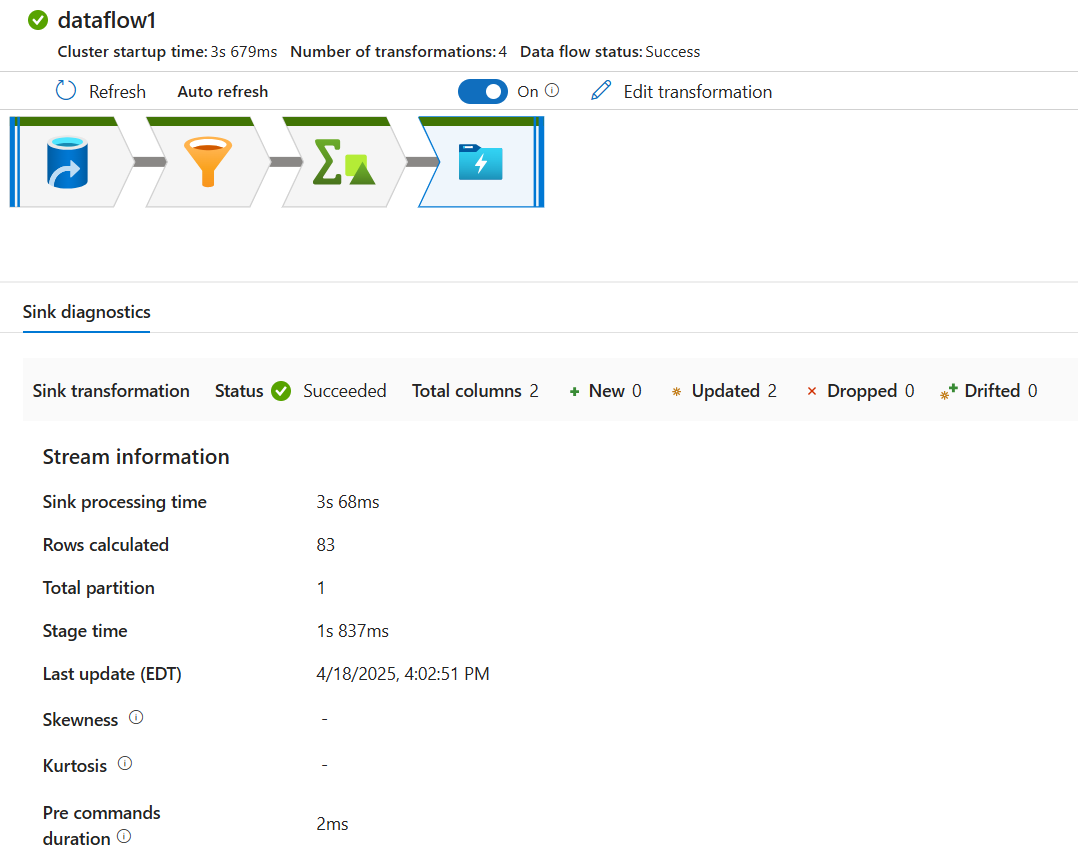
Jika Anda mengikuti tutorial ini dengan benar, Anda seharusnya sudah menulis 83 baris dan 2 kolom ke dalam folder sink Anda. Anda dapat memverifikasi bahwa data sudah benar dengan memeriksa penyimpanan blob Anda.
Konten terkait
Alur dalam tutorial ini menjalankan aliran data yang menggabungkan peringkat rata-rata komedi dari 1910 hingga 2000 dan menulis data ke ADLS. Anda mempelajari cara untuk:
- Membuat pabrik data.
- Buat alur dengan aktivitas Data Flow.
- Bangun aliran data pemetaan dengan empat transformasi.
- Uji coba jalur pipa.
- Memantau aktivitas Data Flow
Pelajari selengkapnya tentang bahasa ekspresi aliran data.