Memilah transformasi dalam memetakan aliran data
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Aliran data tersedia di Alur Azure Data Factory dan Azure Synapse. Artikel ini berlaku untuk memetakan aliran data. Jika Anda baru mengenal transformasi, silakan lihat artikel pengantar Transformasi data menggunakan aliran data pemetaan.
Menggunakan transformasi Pilah untuk memilah kolom dalam data Anda yang ada dalam formulir dokumen. Jenis dokumen tersemat yang saat ini didukung yang dapat diurai adalah JSON, XML, dan teks terbatas.
Konfigurasi
Di panel konfigurasi transformasi penguraian, Anda terlebih dahulu memilih jenis data yang terkandung dalam kolom yang ingin Anda uraikan sebaris. Transformasi pilah juga berisi pengaturan konfigurasi berikut.

Kolom
Mirip dengan kolom turunan dan agregat, properti Kolom adalah tempat Anda mengubah kolom yang ada dengan memilihnya dari pemilih drop-down. Atau Anda dapat mengetikkan nama kolom baru di sini. ADF menyimpan data sumber yang diurai di kolom ini. Dalam kebanyakan kasus, Anda ingin menentukan kolom baru yang mengurai bidang string dokumen yang disematkan masuk.
Ekspresi
Gunakan pembuat ekspresi untuk mengatur sumber pemilahan Anda. Mengatur sumber bisa sesederhana memilih kolom sumber dengan data mandiri yang ingin Anda uraikan, atau Anda dapat membuat ekspresi kompleks untuk diurai.
Contoh ekspresi
Sumber data untai (karakter):
chrome|steel|plastic- Ekspresi:
(desc1 as string, desc2 as string, desc3 as string)
- Ekspresi:
Data JSON sumber:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Ekspresi:
(level as string, registration as long)
- Ekspresi:
Sumber data JSON Berlapis:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Ekspresi:
(car as (model as string, year as integer), color as string, transmission as string)
- Ekspresi:
Data XML sumber:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Ekspresi:
(Customers as (Customer as integer, CompanyName as string))
- Ekspresi:
XML sumber dengan data Atribut:
<cars><car model="camaro"><year>1989</year></car></cars>- Ekspresi:
(cars as (car as ({@model} as string, year as integer)))
- Ekspresi:
Ekspresi dengan karakter yang dipesan:
{ "best-score": { "section 1": 1234 } }- Ekspresi di atas tidak berfungsi karena karakter '-' di ditafsirkan
best-scoresebagai operasi pengurangan. Gunakan variabel dengan notasi tanda kurung dalam kasus ini untuk memberi tahu mesin JSON untuk menginterpretasikan teks secara harfiah:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- Ekspresi di atas tidak berfungsi karena karakter '-' di ditafsirkan
Catatan: Jika Anda mengalami kesalahan saat mengekstrak atribut (khususnya, @model) dari jenis kompleks, solusinya adalah mengonversi jenis kompleks menjadi string, hapus simbol @ (khususnya, replace(toString(your_xml_string_parsed_column_name.cars.car),'@',''), lalu gunakan aktivitas transformasi JSON penguraian.
Jenis kolom output
Di sinilah Anda mengonfigurasi skema output target dari penguraian yang ditulis ke dalam satu kolom. Cara termudah untuk mengatur skema agar output Anda tidak mengurai adalah dengan memilih tombol 'Deteksi Tipe' di kanan atas pembuat ekspresi. ADF mencoba untuk memetakan otomatis skema dari bidang string, yang Anda uraikan dan atur untuk Anda dalam ekspresi output.
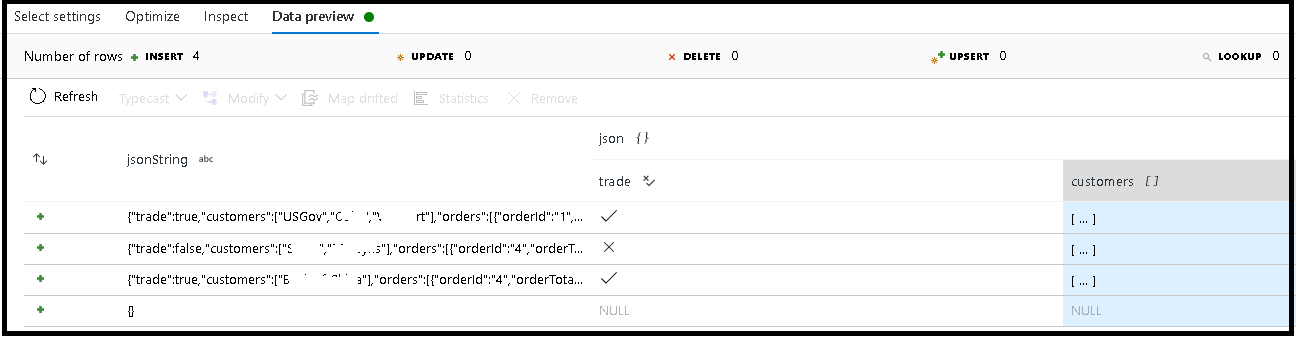
Dalam contoh ini, kami mendefinisikan penguraian bidang masuk "jsonString", yang merupakan teks biasa, tetapi diformat sebagai struktur JSON. Kita akan menyimpan hasil yang dipilah sebagai JSON di kolom baru yang disebut "json" dengan skema ini:
(trade as boolean, customers as string[])
Lihat tab inspeksi dan pratinjau data untuk memverifikasi bahwa output Anda dipetakan dengan benar.
Gunakan aktivitas Kolom Turunan untuk mengekstrak data hierarkis (yaitu, your_complex_column_name.car.model di bidang ekspresi)
Contoh
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Skrip aliran data
Sintaks
Contoh
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Konten terkait
- Gunakan transformasi Ratakan untuk pivot baris ke kolom.
- Gunakan Transformasi kolom turunan untuk mengubah baris.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk