Mentransformasi data di cloud menggunakan aktivitas Spark di Azure Data Factory
BERLAKU UNTUK: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Dalam tutorial ini, Anda menggunakan portal Microsoft Azure untuk membuat alur Azure Data Factory. Alur ini mentransformasi data menggunakan aktivitas Spark dan layanan tertaut Microsoft Azure HDInsight sesuai permintaan.
Anda akan melakukan langkah-langkah berikut dalam tutorial ini:
- Membuat pabrik data.
- Buat alur yang menggunakan aktivitas Spark.
- Memicu eksekusi alur.
- Pantau eksekusi alur.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
Catatan
Sebaiknya Anda menggunakan modul Azure Az PowerShell untuk berinteraksi dengan Azure. Lihat Menginstal Azure PowerShell untuk memulai. Untuk mempelajari cara bermigrasi ke modul Az PowerShell, lihat Memigrasikan Azure PowerShell dari AzureRM ke Az.
- Akun Microsoft Azure Storage. Anda membuat skrip Python dan file input, serta Anda mengunggahnya ke Azure Storage. Output dari program Spark disimpan di akun penyimpanan ini. Kluster Spark sesuai permintaan menggunakan akun penyimpanan yang sama dengan penyimpanan utamanya.
Catatan
HdInsight hanya mendukung akun penyimpanan tujuan umum dengan tingkat standar. Pastikan akun tersebut bukan akun penyimpanan premium atau blob saja.
- Azure PowerShell. Ikuti instruksi di Cara menginstal dan mengonfigurasi Azure PowerShell.
Mengunggah skrip Python ke akun penyimpanan Blob Anda
Buat file Python bernama WordCount_Spark.py dengan konten berikut:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Ganti <storageAccountName> dengan nama akun penyimpanan Azure Anda. Lalu simpan file.
Di Azure Blob storage Anda, buat kontainer bernama adftutorial jika tidak ada.
Buat folder bernama spark.
Buat subfolder bernama skrip di bawah folder spark.
Unggah file WordCount_Spark.py ke subfolder skrip.
Unggah file input
- Buat file bernama minecraftstory.txt dengan teks. Program Spark menghitung jumlah kata dalam teks ini.
- Buat subfolder bernama inputfiles di folder spark.
- Unggah file minecraftstory.txt ke subfolder inputfiles.
Membuat pabrik data
Ikuti langkah-langkah dalam artikel Mulai Cepat: Membuat pabrik data dengan menggunakan portal Azure untuk membuat pabrik data jika Anda belum memilikinya untuk dikerjakan.
Membuat layanan tertaut
Anda menulis dua layanan tertaut di bagian ini:
- Layanan tertaut Azure Storage menautkan akun penyimpanan Azure Anda ke pabrik data. Penyimpanan ini digunakan oleh kluster Microsoft Azure HDInsight sesuai permintaan. Ini juga berisi skrip Spark yang akan dijalankan.
- Layanan terhubung HDInsight sesuai permintaan. Azure Data Factory secara otomatis akan membuat kluster Microsoft Azure HDInsight dan menjalankan program Spark. Kemudian menghapus kluster HDInsight setelah kluster tidak aktif dalam jangka waktu yang telah dikonfigurasi sebelumnya.
Membuat layanan tertaut Azure Storage
Di halaman beranda, beralih ke tab Kelola di panel kiri.
Pilih Koneksi di bagian bawah jendela, lalu pilih +Baru.
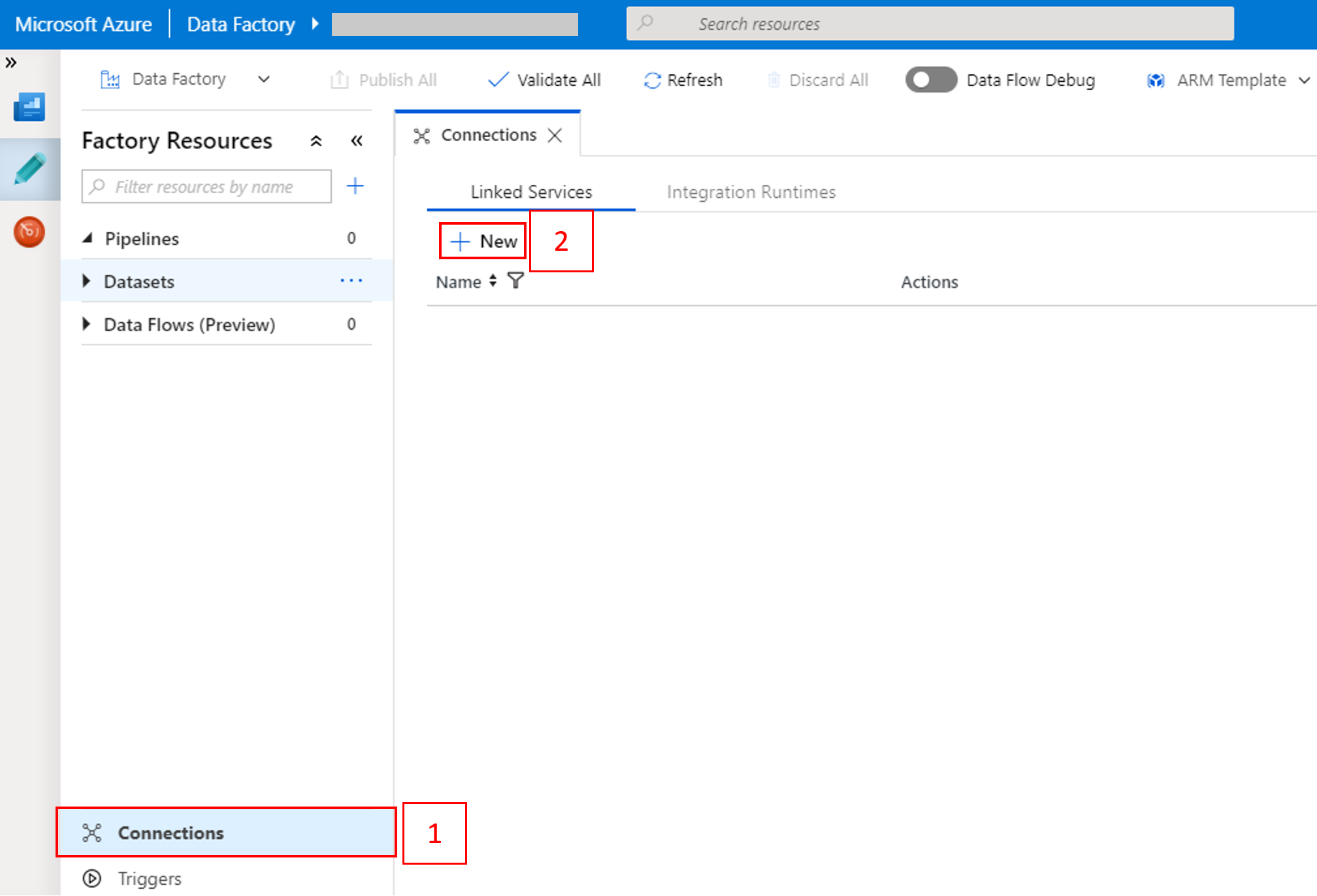
Di jendela Layanan Tertaut Baru, pilih Penyimpanan Data>Azure Blob Storage, lalu pilih Lanjutkan.

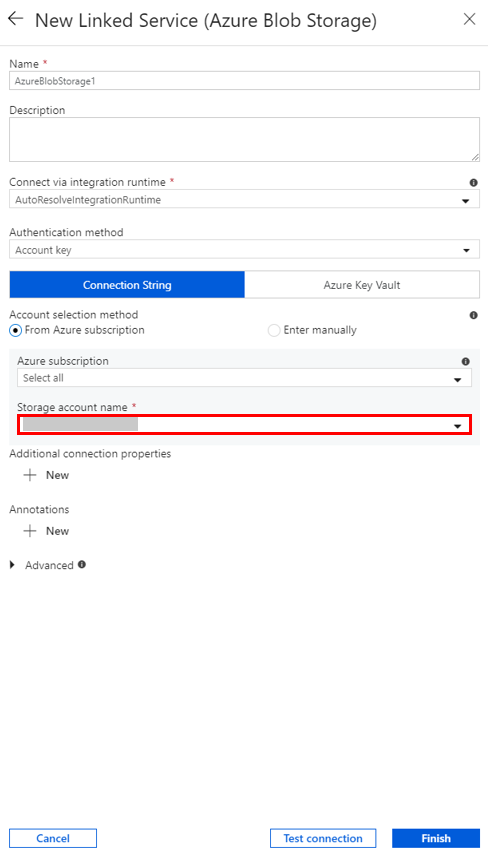
Untuk Nama akun penyimpanan, pilih nama dari daftar, lalu pilih Simpan.
Membuat layanan terhubung Microsoft Azure HDInsight sesuai permintaan
Pilih lagi tombol + Baru untuk membuat layanan tertaut lainnya.
Di jendela Layanan Tertaut Baru, pilih Komputasi>Microsoft Azure HDInsight, lalu pilih Lanjutkan.

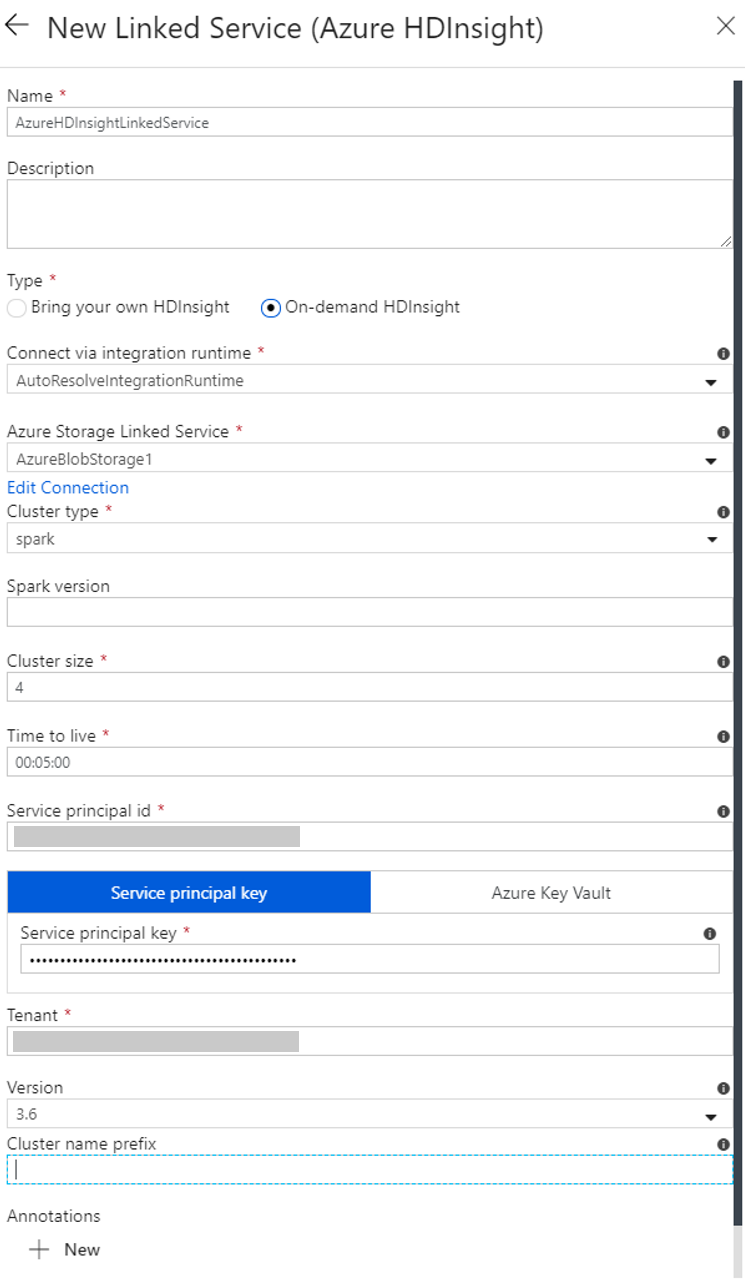
Di jendela Layanan Tertaut baru, lakukan langkah-langkah berikut:
a. Untuk Nama, masukkan AzureHDInsightLinkedService.
b. Untuk Jenis, konfirmasikan Microsoft Azure HDInsight sesuai permintaan dipilih.
c. Untuk Layanan Tertaut Azure Storage, pilih AzureBlobStorage1. Anda sudah membuat layanan tertaut ini sebelumnya. Jika Anda menggunakan nama yang berbeda, tentukan nama yang benar di sini.
d. Untuk Jenis kluster, pilih Spark.
e. Untuk ID perwakilan layanan, masukkan ID perwakilan layanan yang memiliki izin untuk membuat kluster Microsoft Azure HDInsight.
Perwakilan layanan ini harus menjadi anggota dengan peran Kontributor dari langganan atau grup sumber daya tempat kluster dibuat. Untuk informasi selengkapnya, lihat Membuat aplikasi Microsoft Entra dan perwakilan layanan. ID perwakilan layanan sama dengan ID Aplikasi, dan Kunci perwakilan layanan sama dengan nilai untuk Rahasia klien.
f. Untuk Kunci perwakilan layanan, masukkan kunci.
g. Untuk Grup sumber daya, pilih grup sumber daya yang sama dengan yang Anda gunakan saat Anda membuat pabrik data. Kluster Spark dibuat dalam grup sumber daya ini.
h. Perluas Jenis OS.
i. Masukkan nama untukNama pengguna kluster.
j. Masukkan Kata sandi kluster untuk pengguna.
k. Pilih Selesai.
Catatan
Microsoft Azure HDInsight membatasi jumlah total inti yang dapat Anda gunakan di setiap tiap Azure yang didukungnya. Untuk layanan terkait Microsoft Azure HDInsight sesuai permintaan, kluster Microsoft Azure HDInsight dibuat di lokasi Azure Storage yang sama dengan yang digunakan sebagai penyimpanan utamanya. Pastikan Anda memiliki kuota inti yang cukup untuk kluster yang berhasil dibuat. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan kluster di Microsoft Azure HDInsight dengan Hadoop, Spark, Kafka, dan lainnya.
Buat alur
Pilih tombol (plus) +, lalu pilih Alur pada menu.
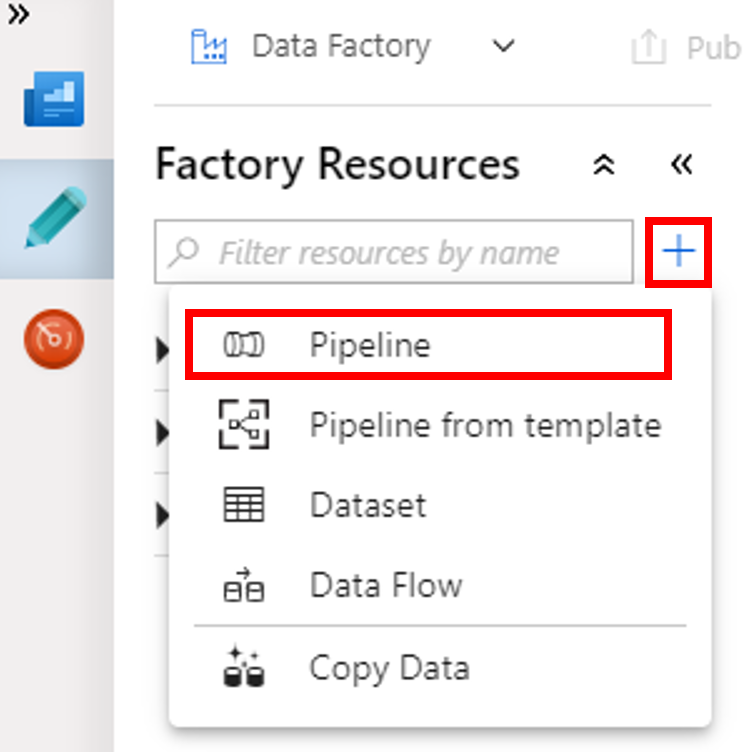
Di kotak alat Aktivitas, luaskan Microsoft Azure HDInsight. Tarik aktivitas Spark dari kotak alat Aktivitas ke permukaan perancang alur.
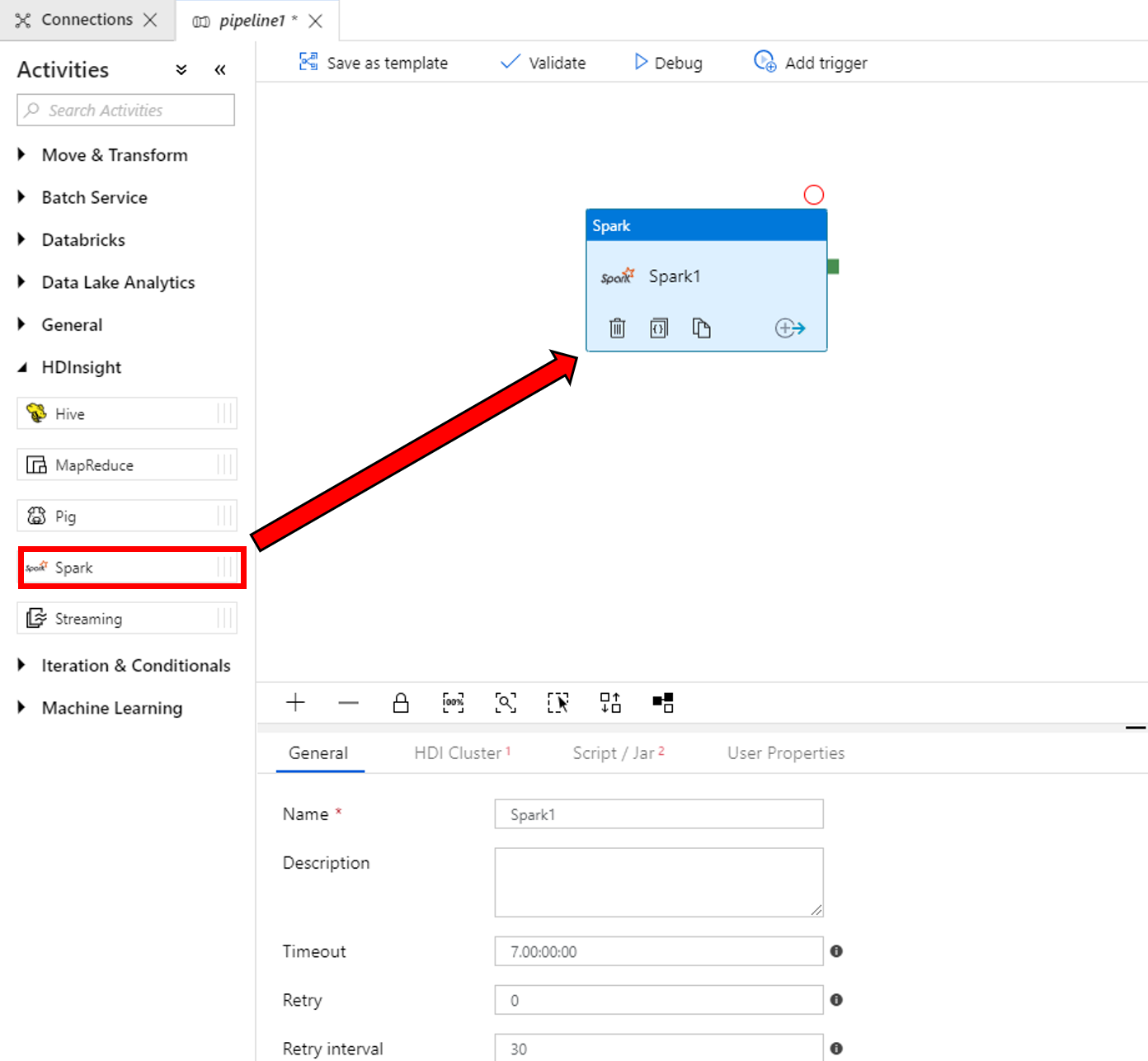
Di properti untuk jendela aktivitas Spark di bagian bawah, selesaikan langkah-langkah berikut ini:
a. Beralih ke tab Kluster HDI.
b. Pilih AzureHDInsightLinkedService (yang Anda buat di prosedur sebelumnya).
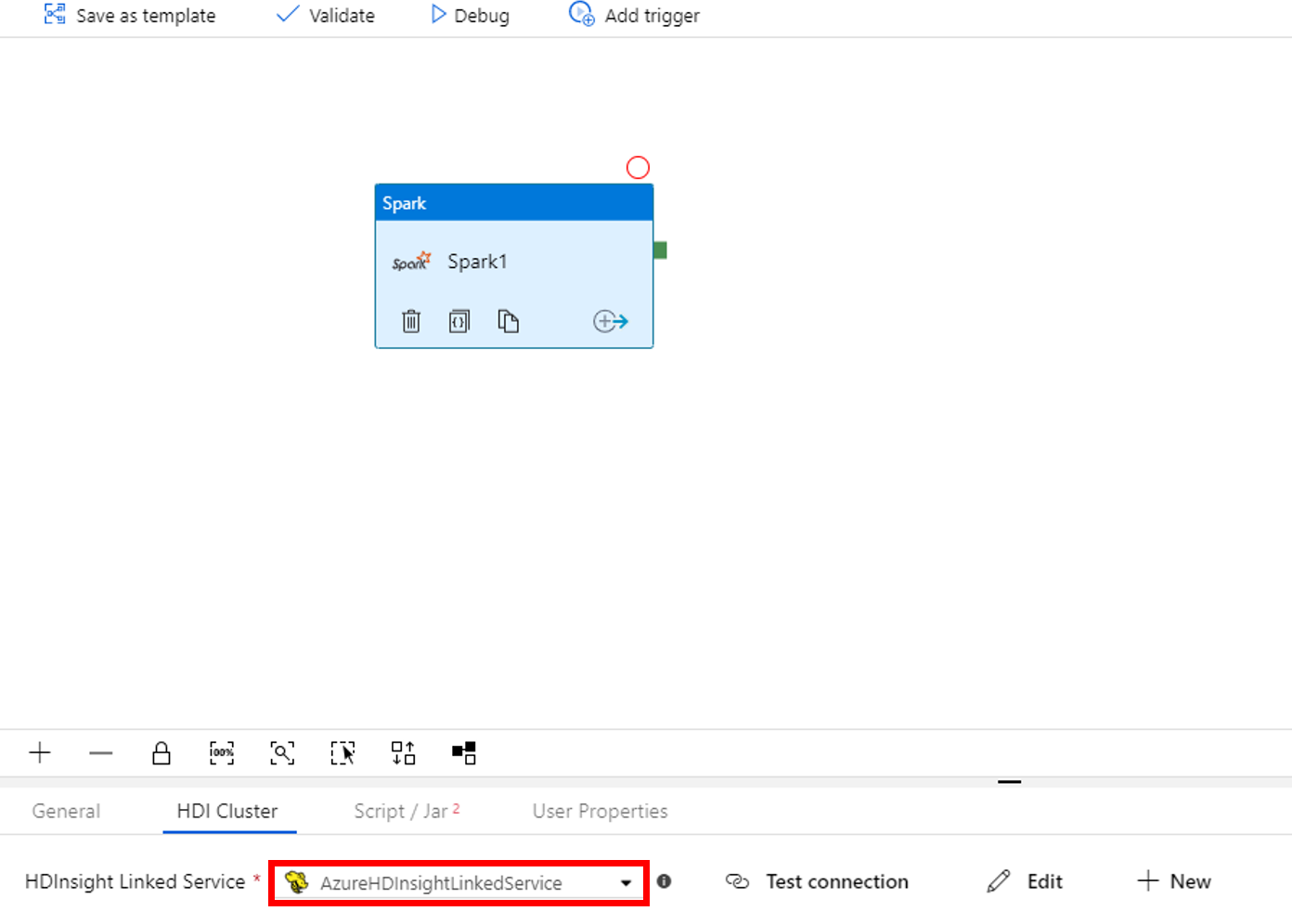
Beralih ke tab Skrip/Jar, dan selesaikan langkah-langkah berikut:
a. Untuk Layanan Tertaut Pekerjaan, pilih AzureBlobStorage1.
b. Pilih Telusuri Penyimpanan.

c. Telusuri ke folder adftutorial/spark/script, pilih WordCount_Spark.py, lalu pilih Selesai.
Untuk memvalidasi alur, klik tombol Validasi pada toolbar. Pilih tombol >> (panah kanan) untuk menutup jendela validasi.
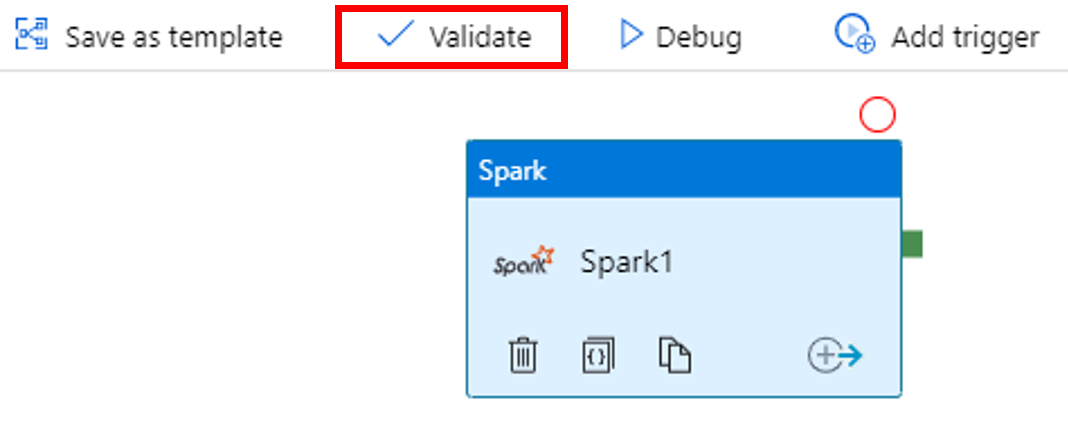
Pilih Terbitkan Semua. Antarmuka pengguna Data Factory menerbitkan entitas (layanan dan alur tertaut) ke layanan Azure Data Factory.
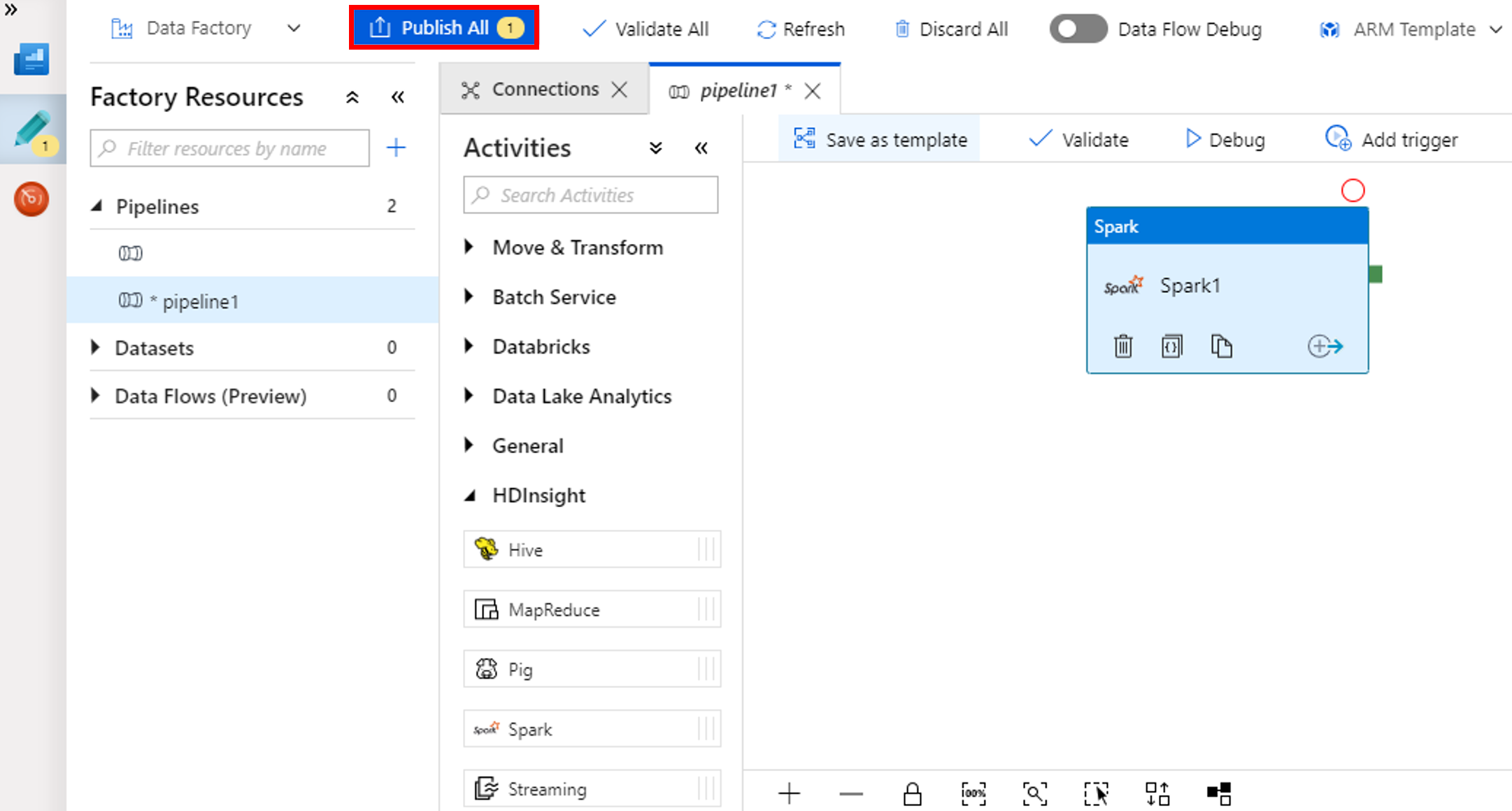
Memicu proses alur
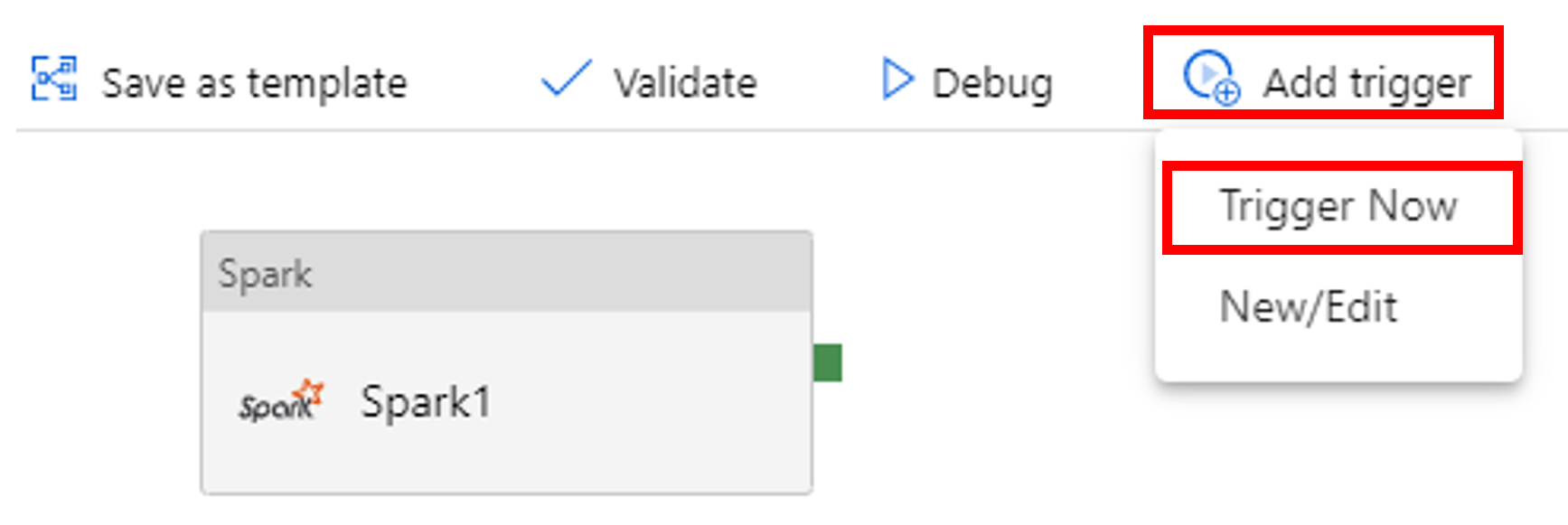
Pilih Tambahkan Pemicu pada toolbar, lalu pilih Picu Sekarang.
Memantau eksekusi alur
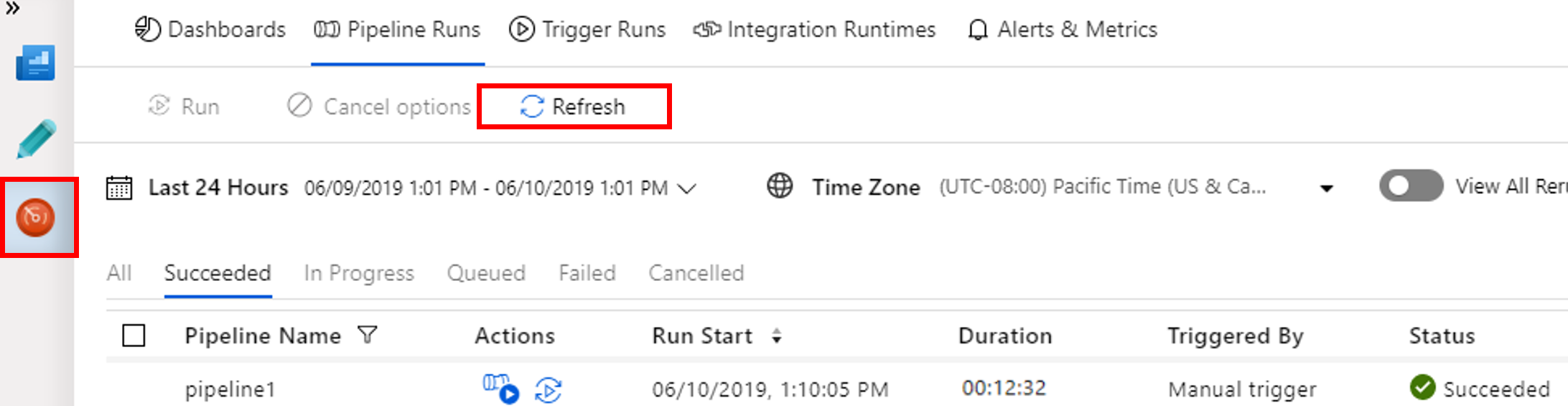
Beralih ke tab Monitor. Pastikan Anda melihat eksekusi alur. Dibutuhkan sekitar 20 menit untuk membuat kluster Spark.
Pilih Refresh secara berkala untuk memeriksa status eksekusi alur.
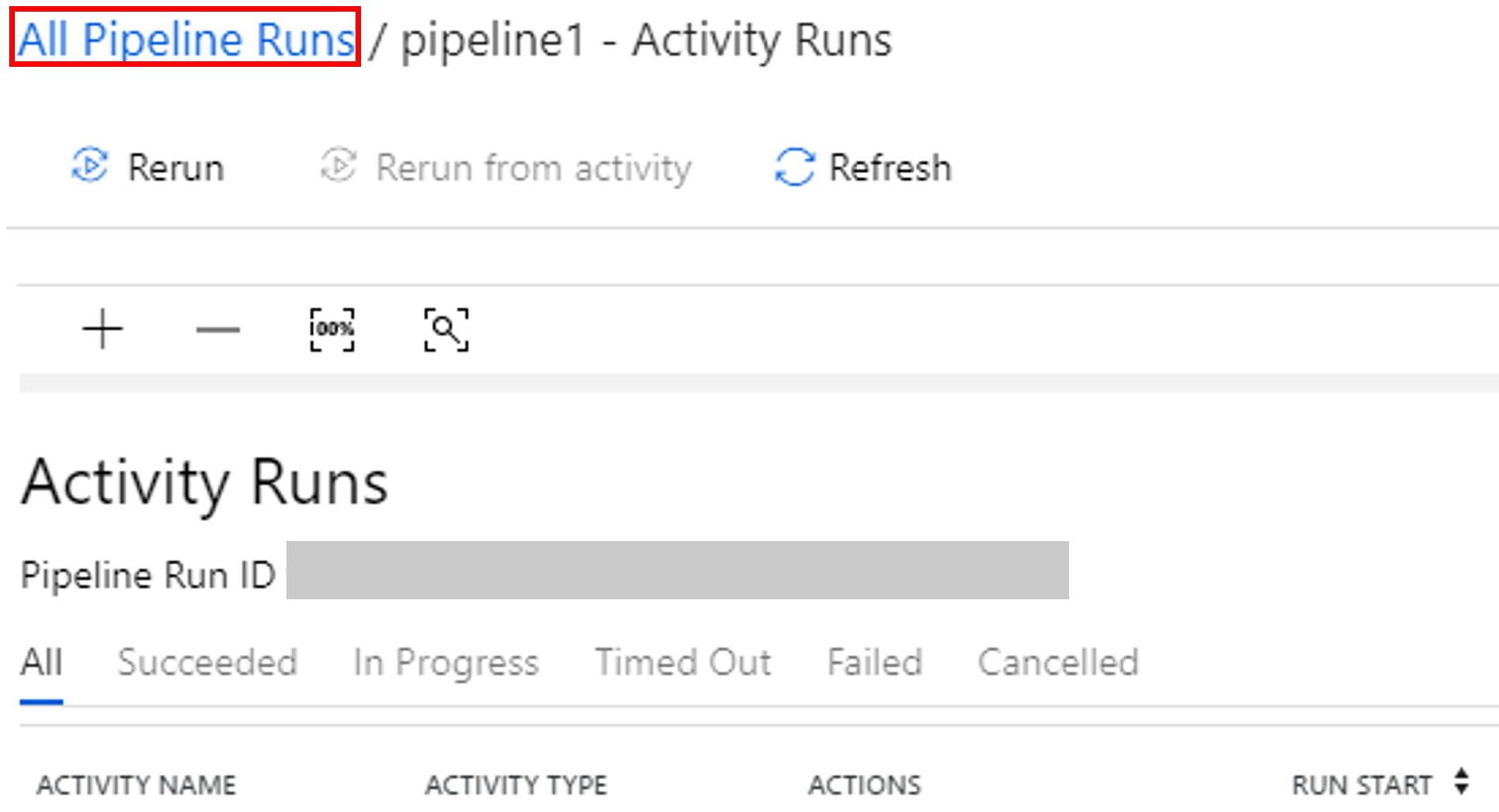
Untuk melihat eksekusi aktivitas yang terkait dengan eksekusi alur, pilih Tampilkan Eksekusi Aktivitas di kolom Tindakan.
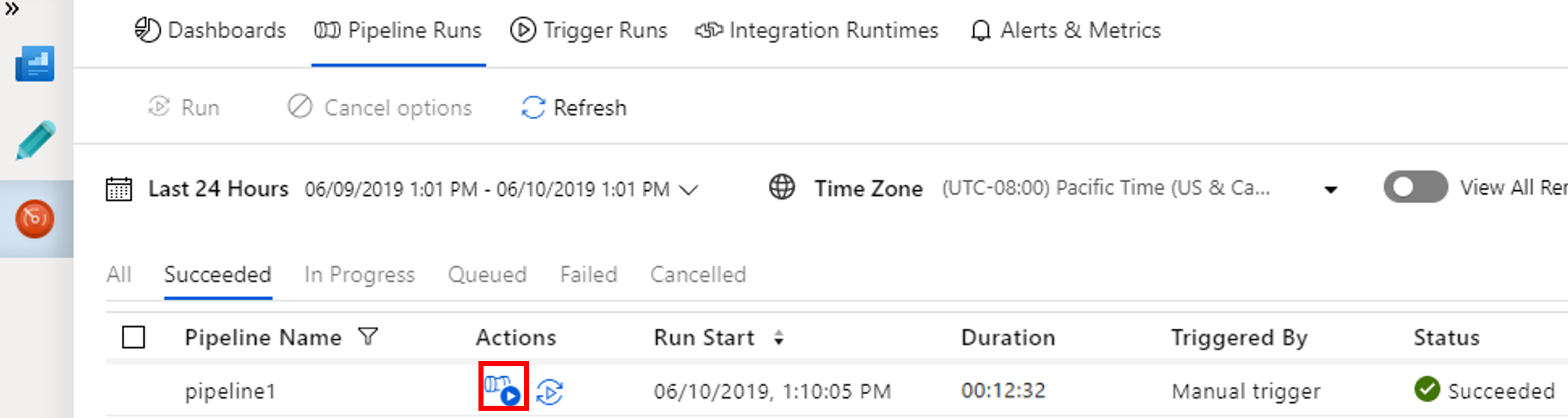
Anda dapat beralih kembali ke tampilan eksekusi alur dengan memilih tautan Semua Eksekusi Alur di bagian atas.
Verifikasi output
Verifikasi bahwa file output dibuat di folder spark/otuputfiles/wordcount dari kontainer adftutorial.
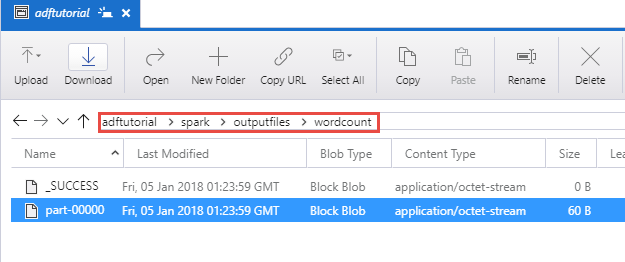
File harus memiliki tiap kata dari file teks input dan berapa kali kata muncul dalam file. Misalnya:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Konten terkait
Alur dalam sampel ini mentransformasi data menggunakan aktivitas Spark dan layanan tertaut Microsoft Azure HDInsight sesuai permintaan. Anda mempelajari cara untuk:
- Membuat pabrik data.
- Buat alur yang menggunakan aktivitas Spark.
- Memicu eksekusi alur.
- Pantau eksekusi alur.
Untuk mempelajari cara mentransformasi data dengan menjalankan skrip Apache Hive pada kluster Microsoft Azure HDInsight yang berada dalam jaringan virtual, lanjutkan ke tutorial beirkutnya: