Menggunakan Browser Tugas dan Tampilan Pekerjaan untuk Analitik Azure Data Lake
Penting
Azure Data Lake Analytics pensiun pada 29 Februari 2024. Pelajari lebih lanjut dengan pengumuman ini.
Untuk analitik data, organisasi Anda dapat menggunakan Azure Synapse Analytics atau Microsoft Fabric.
Arsip layanan Azure Data Lake Analytics mengirimkan pekerjaan di penyimpanan kueri. Di artikel ini, Anda mempelajari cara menggunakan Browser Pekerjaan dan Tampilan Pekerjaan di Azure Data Lake Tools untuk Visual Studio untuk menemukan informasi pekerjaan historis.
Secara default, layanan Data Lake Analytics mengarsipkan pekerjaan selama 30 hari. Periode kedaluwarsa dapat dikonfigurasi dari portal Azure dengan mengonfigurasi kebijakan kedaluwarsa yang disesuaikan. Anda tidak akan dapat mengakses informasi pekerjaan setelah kedaluwarsa.
Prasyarat
Lihat Persyaratan Data Lake Tools untuk Visual Studio.
Membuka Browser Pekerjaan
Akses Browser Pekerjaan melalui Server Explorer>Azure> Data Lake Analytics> Jobs di Visual Studio. Menggunakan Browser Pekerjaan, Anda dapat mengakses penyimpanan kueri akun Data Lake Analytics. Browser Pekerjaan menampilkan Penyimpanan Kueri di sebelah kiri, menampilkan informasi pekerjaan dasar, dan Tampilan Pekerjaan di sebelah kanan menampilkan informasi detail pekerjaan.
Tampilan Pekerjaan
Tampilan Pekerjaan menampilkan informasi terperinci dari suatu pekerjaan. Untuk membuka pekerjaan, Anda dapat mengklik dua kali pekerjaan di Browser Pekerjaan, atau membukanya dari menu Data Lake dengan mengklik Tampilan Pekerjaan. Anda akan melihat dialog yang diisi dengan URL pekerjaan.
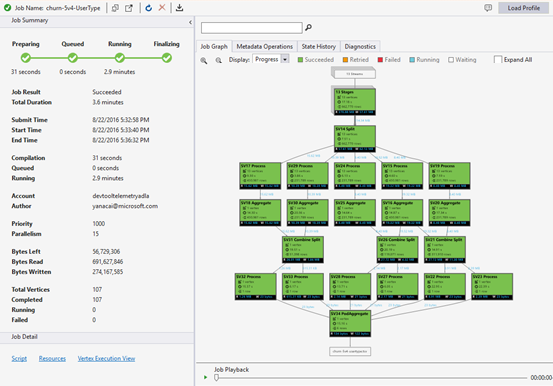
Tampilan Pekerjaan berisi:
Ringkasan pekerjaan
Refresh Tampilan Pekerjaan untuk melihat informasi terbaru tentang menjalankan pekerjaan.
Status Pekerjaan (grafik):
Status Pekerjaan menguraikan fase pekerjaan:
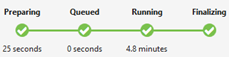
Persiapan: Unggah skrip Anda ke cloud, kompilasi dan optimalkan skrip menggunakan layanan kompilasi.
Diantrekan: Pekerjaan diantrekan saat menunggu sumber daya yang cukup, atau pekerjaan melebihi batas maksimal pekerjaan bersamaan per akun. Pengaturan prioritas menentukan urutan pekerjaan yang antre - semakin rendah angkanya, semakin tinggi prioritasnya.
Menjalankan: Sebenarnya, pekerjaan berjalan di akun Data Lake Analytics Anda.
Menyelesaikan: Pekerjaan sedang diselesaikan (misalnya, menyelesaikan file).
Pekerjaan bisa gagal di setiap fase. Misalnya, kesalahan kompilasi dalam fase Persiapan, kesalahan batas waktu di fase Antrean, dan kesalahan eksekusi di fase Menjalankan, dll.
Informasi Dasar
Informasi pekerjaan dasar ditampilkan di bagian bawah panel Ringkasan Pekerjaan.
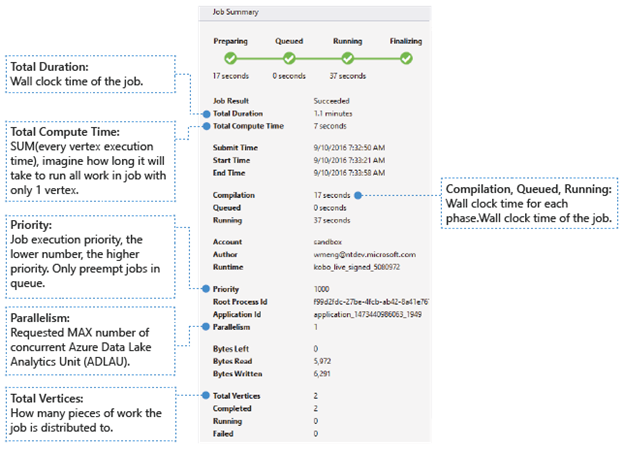
- Hasil Pekerjaan: Berhasil atau gagal. Pekerjaan mungkin gagal di setiap fase.
- Durasi Total: Waktu jam dinding (durasi) antara waktu pengiriman dan waktu berakhir.
- Total Waktu Komputasi: Jumlah dari setiap waktu eksekusi puncak, Anda dapat menganggapnya sebagai waktu pekerjaan dijalankan hanya dalam satu puncak. Lihat Total Puncak untuk menemukan informasi selengkapnya tentang puncak.
- Waktu Kirim/Mulai/Berakhir: Waktu ketika layanan Data Lake Analytics menerima pengiriman pekerjaan/mulai menjalankan pekerjaan/menyelesaikan pekerjaan dengan berhasil atau tidak.
- Kompilasi/Antrean/Berjalan: Waktu jam dinding yang dihabiskan selama fase Persiapan/Antrean/Berjalan.
- Akun: Akun Data Lake Analytics yang digunakan untuk menjalankan pekerjaan.
- Penulis: Pengguna yang mengirimkan pekerjaan, dapat berupa akun orang asli atau akun sistem.
- Prioritas: Prioritas pekerjaan. Semakin rendah angkanya, semakin tinggi prioritasnya. Itu hanya memengaruhi urutan pekerjaan dalam antrean. Mengatur prioritas yang lebih tinggi tidak mendahului pekerjaan yang sedang berjalan.
- Paralelisme: Jumlah maksimum yang diminta dari Azure Data Lake Analytics Unit (ADLAU), juga dikenal sebagai puncak. Saat ini, satu puncak sama dengan satu VM dengan dua core virtual dan RAM enam GB, meskipun ini dapat ditingkatkan di masa mendatang Data Lake Analytics pembaruan.
- Bytes Tersisa: Bytes yang perlu diproses sampai pekerjaan selesai.
- Bytes dibaca/ditulis: Bytes yang telah dibaca/ditulis sejak pekerjaan mulai berjalan.
- Total puncak: Pekerjaan dipecah menjadi banyak bagian pekerjaan, setiap bagian pekerjaan disebut puncak. Nilai ini menggambarkan berapa banyak bagian pekerjaan yang terdiri dari pekerjaan. Anda dapat mempertimbangkan puncak sebagai unit proses dasar, juga dikenal sebagai Azure Data Lake Analytics Unit (ADLAU), dan puncak dapat dijalankan secara paralelisme.
- Selesai/Berjalan/Gagal: Jumlah puncak yang selesai/berjalan/gagal. Puncak dapat gagal karena kode pengguna dan kegagalan sistem, tetapi sistem mencoba ulang puncak yang gagal secara otomatis beberapa kali. Jika puncak masih gagal setelah mencoba lagi, seluruh pekerjaan akan gagal.
Grafik Pekerjaan
Skrip U-SQL mewakili logika mengubah data input menjadi data output. Skrip dikompilasi dan dioptimalkan ke rencana eksekusi fisik pada fase Persiapan. Grafik Pekerjaan bertujuan untuk menampilkan rencana eksekusi fisik. Diagram berikut menggambarkan proses tersebut:
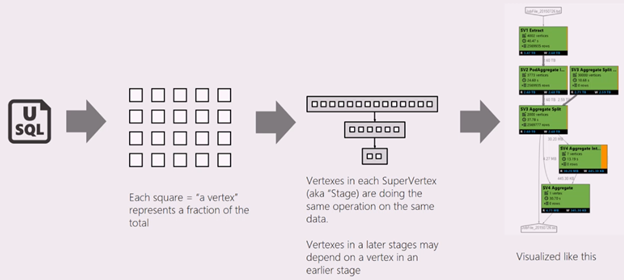
Sebuah pekerjaan dipecah menjadi banyak bagian pekerjaan. Setiap bagian dari pekerjaan disebut Puncak. Puncak dikelompokkan sebagai Puncak Super (juga dikenal sebagai tahap), dan divisualisasikan sebagai Grafik Pekerjaan. Plakat tahap hijau di grafik pekerjaan menunjukkan tahap.
Setiap puncak dalam sebuah tahap melakukan pekerjaan yang sama dengan bagian yang berbeda dari data yang sama. Misalnya, jika Anda memiliki file dengan data satu TB, dan ada ratusan simpul yang membacanya, masing-masing membaca gugus. Simpul tersebut dikelompokkan dalam tahap yang sama dan melakukan pekerjaan yang sama pada bagian yang berbeda dari file input yang sama.
-
Pada tahap tertentu, beberapa nomor ditampilkan di plakat.
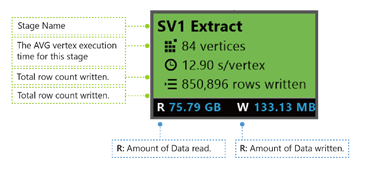
Ekstrak SV1: Nama panggung, dinamai dengan nomor dan metode operasi.
84 puncak: Jumlah total puncak dalam tahap ini. Gambar menunjukkan berapa banyak bagian pekerjaan yang dibagi dalam tahap ini.
12.90 dtk/puncak: Waktu eksekusi puncak rata-rata untuk tahap ini. Angka ini dihitung dengan SUM (setiap waktu eksekusi puncak)/(jumlah total Puncak). Yang berarti jika Anda dapat menetapkan semua puncak yang dieksekusi secara paralel, seluruh tahap selesai dalam 12,90 detik. Ini juga berarti jika semua pekerjaan dalam tahap ini dilakukan secara berurutan, biayanya adalah #vertices * waktu AVG.
850.895 baris ditulis: Jumlah baris ditulis dalam tahap ini.
R/W: Jumlah data yang dibaca/ditulis pada tahap ini dalam byte.
Warna: Warna digunakan di tahap untuk menunjukkan status puncak yang berbeda.
- Hijau menunjukkan puncak berhasil.
- Oranye menunjukkan puncak dicoba ulang. Titik yang dicoba ulang telah gagal tetapi dicoba ulang secara otomatis dan berhasil oleh sistem, dan tahap keseluruhan berhasil diselesaikan. Jika puncak dicoba ulang tetapi masih gagal, warnanya berubah menjadi merah dan seluruh pekerjaan gagal.
- Merah menunjukkan gagal, yang berarti puncak tertentu telah dicoba beberapa kali oleh sistem tetapi masih gagal. Skenario ini menyebabkan seluruh pekerjaan gagal.
- Biru berarti puncak tertentu sedang berjalan.
- Putih menunjukkan puncak sedang Menunggu. Puncak dapat menunggu untuk dijadwalkan setelah ADLAU tersedia, atau mungkin menunggu input karena data inputnya mungkin belum siap.
Anda dapat menemukan detail lebih lanjut untuk tahap dengan mengarahkan kursor mouse ke satu status:
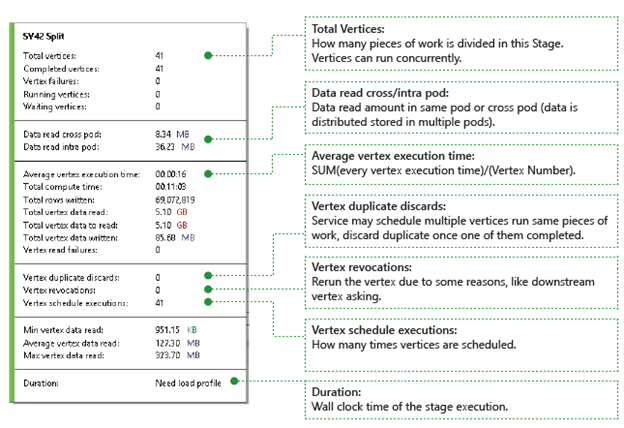
Puncak: Menjelaskan detail puncak, misalnya jumlah puncak total, berapa puncak yang telah diselesaikan, apakah gagal atau masih berjalan/menunggu, dll.
Pembacaan data lintas/intra pod: File dan data disimpan di beberapa pod dalam sistem file terdistribusi. Nilai di sini menjelaskan berapa banyak data yang telah dibaca di pod yang sama atau lintas pod.
Total waktu komputasi: Jumlah dari setiap waktu eksekusi puncak di panggung, Anda dapat menganggapnya sebagai waktu yang diperlukan jika semua pekerjaan di panggung dieksekusi hanya dalam satu puncak.
Data dan baris yang ditulis/dibaca: Menunjukkan berapa banyak data atau baris yang telah dibaca/ditulis, atau perlu dibaca.
Kegagalan membaca puncak: Menjelaskan berapa banyak puncak yang gagal saat membaca data.
Buang duplikat puncak: Jika vertex berjalan terlalu lambat, sistem mungkin menjadwalkan beberapa simpul untuk menjalankan pekerjaan yang sama. Simpul redundan akan dibuang setelah salah satu simpul berhasil diselesaikan. Puncak duplikat membuang mencatat jumlah puncak yang dibuang sebagai duplikasi di tahapan.
Pencabutan puncak: puncak berhasil, tetapi jalankan kembali nanti karena beberapa alasan. Misalnya, jika puncak downstream kehilangan data input perantara, ia akan meminta puncak upstream untuk menjalankan kembali.
Eksekusi jadwal puncak: Total waktu puncak telah dijadwalkan.
Pembacaan data Min/Rata-rata/Maks Puncak: Minimum/rata-rata/maksimum dari setiap data baca puncak.
Durasi: Waktu jam dinding yang dibutuhkan sebuah tahapan, Anda perlu memuat profil untuk melihat nilai ini.
Pemutaran Pekerjaan
Data Lake Analytics menjalankan pekerjaan dan mengarsipkan simpul yang menjalankan informasi pekerjaan, seperti ketika puncak dimulai, dihentikan, gagal, dan bagaimana mereka dicoba kembali, dll. Semua informasi secara otomatis dicatat di penyimpanan kueri dan disimpan di Profil Pekerjaannya. Anda dapat mengunduh Profil Pekerjaan melalui “Muat Profil” di Tampilan Pekerjaan, dan Anda dapat melihat Pemutaran Pekerjaan setelah mengunduh Profil Pekerjaan.
Pemutaran Pekerjaan adalah visualisasi epitome dari apa yang terjadi di kluster. Ini membantu Anda melihat kemajuan pelaksanaan pekerjaan dan secara visual mendeteksi anomali performa dan kemacetan dalam waktu yang sangat singkat (biasanya kurang dari 30 detik).
Tampilan Peta Panas Pekerjaan
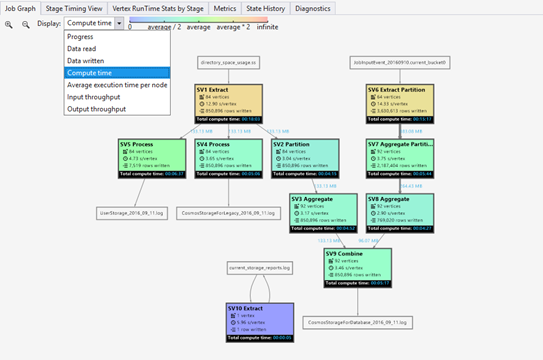
Peta Panas Pekerjaan dapat dipilih melalui dropdown Tampilan di Grafik Pekerjaan.
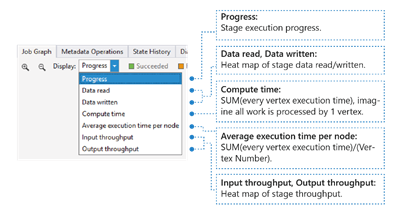
Ini menunjukkan peta panas I/O, waktu dan throughput dari pekerjaan, yang melaluinya Anda dapat menemukan tempat pekerjaan tersebut menghabiskan sebagian besar waktunya, atau apakah pekerjaan Anda merupakan pekerjaan batas I/O, dan seterusnya.
- Kemajuan: Kemajuan pelaksanaan pekerjaan, lihat Informasi dalam informasi tahap.
- Data baca/tulis: Peta panas dari total data yang dibaca/ditulis di setiap tahap.
- Waktu komputasi: Peta panas SUM (setiap waktu eksekusi puncak), Anda dapat mempertimbangkan ini sebagai berapa lama waktu yang dibutuhkan jika semua pekerjaan dalam tahap dijalankan hanya dengan satu puncak.
- Waktu eksekusi rata-rata per node: Peta panas SUM (setiap waktu eksekusi puncak)/(Nomor Puncak). Yang berarti jika Anda dapat menetapkan semua puncak yang dieksekusi secara paralel, seluruh tahap akan dilakukan dalam jangka waktu ini.
- Throughput Input/Output: Peta panas throughput input/output dari setiap tahap, Anda dapat mengonfirmasi apakah pekerjaan Anda adalah pekerjaan terikat I/O melalui ini.
-
Operasi Metadata
Anda dapat melakukan beberapa operasi metadata dalam skrip U-SQL Anda, seperti membuat database, menghilangkan tabel, dll. Operasi ini ditampilkan dalam Operasi Metadata setelah kompilasi. Anda dapat menemukan pernyataan, membuat entitas, menghilangkan entitas di sini.

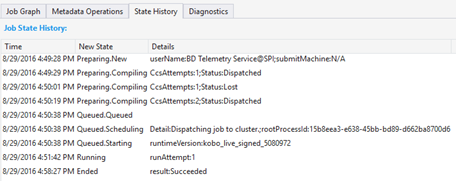
Riwayat Negara
Riwayat Negara juga divisualisasikan dalam Ringkasan Pekerjaan, tetapi Anda bisa mendapatkan detail lebih lanjut di sini. Anda dapat menemukan informasi terperinci seperti kapan pekerjaan disiapkan, diantrekan, mulai berjalan, berakhir. Anda juga dapat menemukan berapa kali pekerjaan telah dikompilasi (CcsAttempts: 1), kapan pekerjaan dikirim ke kluster sebenarnya (Detail: Mengirimkan pekerjaan ke kluster), dll.
Diagnostik
Alat ini mendiagnosis eksekusi pekerjaan secara otomatis. Anda akan menerima pemberitahuan saat ada beberapa kesalahan atau masalah performa dalam pekerjaan Anda. Harap dicatat bahwa Anda perlu mengunduh Profil untuk mendapatkan informasi lengkap di sini.
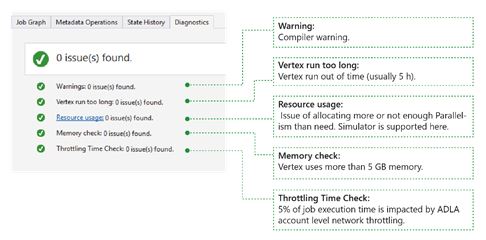
- Peringatan: Pemberitahuan muncul di sini dengan peringatan kompilator. Anda dapat memilih tautan "masalah x" untuk memiliki detail lebih lanjut setelah pemberitahuan muncul.
- Vertex berjalan terlalu lama: Jika ada puncak yang kehabisan waktu (misalnya 5 jam), masalah akan ditemukan di sini.
- Penggunaan sumber daya: Jika Anda mengalokasikan lebih banyak atau tidak cukup Paralelisme daripada kebutuhan, masalah akan ditemukan di sini. Anda juga dapat memilih Penggunaan sumber daya untuk melihat detail selengkapnya dan melakukan skenario bagaimana-jika untuk menemukan alokasi sumber daya yang lebih baik (untuk detail selengkapnya, lihat panduan ini).
- Pemeriksaan memori: Jika ada puncak yang menggunakan memori lebih dari 5 GB, masalah akan ditemukan di sini. Eksekusi pekerjaan dapat dimatikan oleh sistem jika menggunakan lebih banyak memori daripada batasan sistem.
Detail Pekerjaan
Detail Pekerjaan menunjukkan informasi detail tentang pekerjaan, termasuk Skrip, Sumber Daya, dan Tampilan Eksekusi Puncak.
Skrip
Skrip U-SQL pekerjaan disimpan di penyimpanan kueri. Anda dapat melihat skrip U-SQL asli dan mengirimkannya kembali jika diperlukan.
Sumber
Anda dapat menemukan output kompilasi pekerjaan yang disimpan di penyimpanan kueri melalui Sumber Daya. Misalnya, Anda dapat menemukan "algebra.xml" yang digunakan untuk menampilkan Grafik Pekerjaan, rakitan yang Anda daftarkan, dll., di sini.
Tampilan eksekusi puncak
Ini menunjukkan detail eksekusi puncak. Profil Pekerjaan mengarsipkan setiap log eksekusi puncak, seperti total data yang dibaca/ditulis, runtime, status, dll. Melalui tampilan ini, Anda bisa mendapatkan detail lebih lanjut tentang bagaimana suatu pekerjaan dijalankan. Untuk informasi selengkapnya, lihat Menggunakan Tampilan Eksekusi Puncak di Alat Data Lake untuk Visual Studio.
Langkah berikutnya
- Untuk mencatat informasi diagnostik, lihat Mengakses log diagnostik untuk Azure Data Lake Analytics
- Untuk melihat kueri yang lebih kompleks, lihat Menganalisis log Situs Web menggunakan Azure Data Lake Analytics.
- Untuk menggunakan tampilan eksekusi puncak, lihat Menggunakan Tampilan Eksekusi Puncak di Alat Data Lake untuk Visual Studio