Mengonfigurasi komputasi (warisan)
Catatan
Ini adalah instruksi untuk UI kluster buat warisan, dan hanya disertakan untuk akurasi historis. Semua pelanggan harus menggunakan UI buat kluster yang diperbarui.
Artikel ini menjelaskan opsi konfigurasi yang tersedia saat Anda membuat dan mengedit kluster Azure Databricks. Ini berfokus pada pembuatan dan pengeditan kluster menggunakan UI. Untuk metode lain, lihat penyedia Databricks CLI, Clusters API, dan Databricks Terraform.
Untuk bantuan menentukan kombinasi opsi konfigurasi apa yang paling sesuai dengan kebutuhan Anda, lihat praktik terbaik konfigurasi kluster.

Kebijakan kluster
Kebijakan kluster membatasi kemampuan untuk mengonfigurasi kluster berdasarkan set aturan. Aturan kebijakan membatasi atribut atau nilai atribut yang tersedia untuk pembuatan kluster. Kebijakan kluster memiliki ACL yang membatasi penggunaannya untuk pengguna dan grup tertentu dan dengan demikian membatasi kebijakan mana yang dapat Anda pilih saat membuat kluster.
Untuk mengonfigurasi kebijakan kluster, pilih kebijakan kluster di drop-down Kebijakan.

Catatan
Jika tidak ada kebijakan yang sudah dibuat di ruang kerja, drop-down Kebijakan tidak ditampilkan.
Jika Anda memiliki:
- Izin membuat kluster, Anda dapat memilih kebijakan Tidak Terbatas dan membuat kluster yang sepenuhnya dikonfigurasi. Kebijakan Tidak Terbatas tidak membatasi atribut kluster atau nilai atribut apa pun.
- Baik kebijakan izin membuat kluster dan akses ke kluster, Anda dapat memilih kebijakan Tidak Terbatas dan kebijakan yang dapat mereka akses.
- Akses ke kebijakan kluster saja, Anda dapat memilih kebijakan yang dapat Anda akses.
Mode kluster
Catatan
Artikel ini menjelaskan antarmuka pengguna kluster warisan. Untuk informasi tentang antarmuka pengguna kluster baru (dalam pratinjau), lihat Referensi konfigurasi komputasi. Ini termasuk beberapa perubahan terminologi untuk jenis dan mode akses kluster. Untuk perbandingan jenis kluster baru dan warisan, lihat Perubahan antarmuka pengguna kluster dan mode akses kluster. Di antarmuka pengguna pratinjau:
- Kluster mode standar sekarang disebut Tidak ada kluster mode akses Bersama Isolasi.
- Konkurensi Tinggi dengan ACL Tabel sekarang disebut kluster mode akses bersama.
Azure Databricks mendukung tiga mode kluster: Standar, Konkurensi Tinggi, dan Node Tunggal. Mode kluster default adalah Standar.
Penting
- Jika ruang kerja Anda ditetapkan ke metastore Unity Catalog, kluster Konkurensi Tinggi tidak tersedia. Sebagai gantinya, Anda menggunakan mode akses untuk memastikan integritas kontrol akses dan menerapkan jaminan isolasi yang kuat. Lihat juga Mode akses.
- Anda tidak dapat mengubah mode kluster setelah kluster dibuat. Jika Anda menginginkan mode kluster yang berbeda, Anda harus membuat kluster baru.
Konfigurasi kluster mencakup pengaturan penghentian otomatis yang nilai defaultnya bergantung pada mode kluster:
- Kluster Node Standar dan Tunggal berakhir secara otomatis setelah 120 menit secara default.
- Kluster Konkurensi Tinggi tidak berakhir secara otomatis secara default.
Kluster standar
Peringatan
Kluster mode standar (terkadang disebut Tidak Ada kluster Bersama Isolasi) dapat dibagikan oleh beberapa pengguna, tanpa isolasi antar pengguna. Jika Anda menggunakan mode kluster Konkurensi Tinggi tanpa pengaturan keamanan tambahan seperti ACL Tabel atau Passthrough Kredensial, pengaturan yang sama digunakan sebagai kluster mode Standar. Admin akun dapat mencegah kredensial internal dibuat secara otomatis untuk admin ruang kerja Databricks pada jenis kluster ini. Untuk opsi yang lebih aman, Databricks merekomendasikan alternatif seperti kluster konkurensi tinggi dengan ACL Tabel.
Kluster Standar hanya direkomendasikan untuk satu pengguna. Kluster standar dapat menjalankan beban kerja yang dikembangkan di Python, SQL, R, dan Scala.
Kluster Konkurensi Tinggi
Kluster Konkurensi Tinggi adalah sumber daya cloud terkelola. Manfaat utama dari kluster Konkurensi Tinggi adalah mereka menyediakan berbagi berbutir halus untuk pemanfaatan sumber daya maksimum dan latensi kueri minimum.
Kluster Konkurensi Tinggi dapat menjalankan beban kerja yang dikembangkan di SQL, Python, dan R. Kinerja dan keamanan kluster Konkurensi Tinggi disediakan dengan menjalankan kode pengguna dalam proses terpisah, yang tidak dimungkinkan di Scala.
Selain itu, hanya kluster Konkurensi Tinggi yang mendukung kontrol akses tabel.
Untuk membuat kluster Konkurensi Tinggi, atur Mode Kluster ke Konkurensi Tinggi.

Kluster Node Tunggal
Kluster Node Tunggal tidak memiliki pekerja dan menjalankan pekerjaan Spark di node driver.
Sebaliknya, kluster Standar memerlukan setidaknya satu node pekerja Spark selain node driver untuk menjalankan pekerjaan Spark.
Untuk membuat kluster Node Tunggal, atur Mode Kluster ke Node Tunggal.

Untuk mempelajari selengkapnya tentang bekerja dengan kluster Node Tunggal, lihat Komputasi simpul tunggal atau multi-simpul.
Kumpulan
Untuk mengurangi waktu mulai kluster, Anda dapat melampirkan kluster ke kumpulan instans idle yang telah ditentukan, untuk node driver dan pekerja. Kluster dibuat menggunakan instans di kumpulan. Jika kumpulan tidak memiliki sumber daya tidak aktif yang cukup untuk membuat node driver atau pekerja yang diminta, kumpulan akan diperluas dengan mengalokasikan instans baru dari penyedia instans. Ketika kluster terlampir dihentikan, instans yang digunakan dikembalikan ke kumpulan dan dapat digunakan kembali oleh kluster yang berbeda.
Jika Anda memilih kumpulan untuk node pekerja tetapi tidak untuk node driver, simpul driver mewarisi kumpulan dari konfigurasi node pekerja.
Penting
Jika Anda mencoba memilih kumpulan untuk node driver tetapi tidak untuk node pekerja, kesalahan terjadi dan kluster Anda tidak dibuat. Persyaratan ini mencegah situasi saat node driver harus menunggu node pekerja dibuat, atau sebaliknya.
Lihat Referensi konfigurasi kumpulan untuk mempelajari selengkapnya tentang bekerja dengan kumpulan di Azure Databricks.
Databricks Runtime
Waktu proses Databricks adalah kumpulan komponen inti yang berjalan di kluster Anda. Semua runtime bahasa umum Databricks menyertakan Apache Spark dan menambahkan komponen serta pembaruan yang meningkatkan kegunaan, kinerja, dan keamanan. Untuk detailnya, lihat Versi dan kompatibilitas catatan rilis Databricks Runtime.
Azure Databricks menawarkan beberapa jenis runtime bahasa umum dan beberapa versi jenis runtime bahasa umum tersebut di drop-down Databricks Runtime Version saat Anda membuat atau mengedit kluster.

Akselerasi foton
Photon tersedia untuk kluster yang menjalankan Databricks Runtime 9.1 LTS ke atas.
Untuk mengaktifkan akselerasi Photon, pilih kotak centang Gunakan Akselerasi Foton.
Jika perlu, Anda dapat menentukan jenis instans di drop-down Jenis Pekerja dan Jenis Driver.
Databricks merekomendasikan jenis instans berikut untuk harga dan kinerja yang optimal:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
Anda dapat melihat aktivitas Foton di UI Spark. Tangkapan layar berikut menunjukkan detail kueri DAG. Ada dua indikasi Foton di DAG. Pertama, operator Foton dimulai dengan "Photon", misalnya, PhotonGroupingAgg. Kedua, dalam DAG, operator foton dan tahapan berwarna peach, sedangkan yang non-Photon berwarna biru.

Citra Docker
Untuk beberapa versi Runtime Bahasa Umum Databricks, Anda dapat menentukan gambar Docker saat membuat kluster. Contoh kasus penggunaan termasuk kustomisasi pustaka, lingkungan kontainer emas yang tidak berubah, dan integrasi Docker CI/CD.
Anda juga dapat menggunakan gambar Docker untuk membuat lingkungan pembelajaran mendalam khusus pada kluster dengan perangkat GPU.
Untuk petunjuknya, lihat Menyesuaikan kontainer dengan Databricks Container Service dan Databricks Container Services pada komputasi GPU.
Jenis node kluster
Cluster terdiri dari satu node driver dan node pekerja nol atau lebih.
Anda dapat memilih jenis instans penyedia cloud terpisah untuk node driver dan pekerja, meskipun secara default node driver menggunakan jenis instans yang sama dengan node pekerja. Keluarga yang berbeda dari jenis instans sesuai dengan kasus penggunaan yang berbeda, seperti beban kerja intensif memori atau komputasi intensif.
Catatan
Jika persyaratan keamanan Anda menyertakan isolasi komputasi, pilih instans Standard_F72s_V2 sebagai jenis pekerja Anda. Jenis instans ini mewakili mesin virtual terisolasi yang menggunakan seluruh host fisik dan menyediakan tingkat isolasi yang diperlukan untuk mendukung, misalnya, beban kerja Tingkat Dampak 5 (IL5) Departemen Pertahanan AS.
Node driver
Node driver mempertahankan informasi status semua notebook yang terpasang ke kluster. Node driver juga mempertahankan SparkContext dan menafsirkan semua perintah yang Anda jalankan dari notebook atau pustaka pada kluster, dan menjalankan master Apache Spark yang berkoordinasi dengan pelaksana Spark.
Nilai default dari tipe node driver sama dengan tipe node pekerja. Anda dapat memilih jenis node driver yang lebih besar dengan lebih banyak memori jika Anda berencana untuk collect() banyak data dari pekerja Spark dan menganalisisnya di notebook.
Tip
Karena node driver mempertahankan semua informasi status notebook yang terpasang, pastikan untuk melepaskan notebook yang tidak digunakan dari node driver.
Simpul pekerja
Node pekerja Azure Databricks menjalankan eksekutor Spark dan layanan lain yang diperlukan untuk berfungsinya kluster. Saat Anda mendistribusikan beban kerja dengan Spark, semua pemrosesan terdistribusi terjadi pada node pekerja. Azure Databricks menjalankan satu eksekutor per node pekerja; oleh karena itu istilah eksekutor dan pekerja digunakan secara bergantian dalam konteks arsitektur Azure Databricks.
Tip
Untuk menjalankan pekerjaan Spark, Anda setidaknya membutuhkan satu node worker. Jika kluster tidak memiliki pekerja, Anda dapat menjalankan perintah non-Spark pada node driver, tetapi perintah Spark akan gagal.
Jenis instans GPU
Untuk tugas komputasi yang menantang yang menuntut kinerja tinggi, seperti yang terkait dengan pembelajaran mendalam, Azure Databricks mendukung kluster yang dipercepat dengan unit pemrosesan grafis (GPU). Untuk informasi selengkapnya, lihat Komputasi berkemampuan GPU.
Instans spot
Untuk menghemat biaya, Anda dapat memilih untuk menggunakan instans spot, juga dikenal sebagai VM Azure Spot dengan mencentang kotak centang Instans spot.

Instans pertama akan selalu sesuai permintaan (node driver selalu sesuai permintaan) dan instans berikutnya akan menjadi instans spot. Jika instans spot digusur karena tidak tersedia, instans sesuai permintaan disebarkan untuk mengganti instans yang digusur.
Ukuran kluster dan autoscaling
Saat membuat kluster Azure Databricks, Anda dapat menyediakan jumlah pekerja tetap untuk kluster atau menyediakan jumlah pekerja minimum dan maksimum untuk kluster.
Saat Anda menyediakan kluster ukuran tetap, Azure Databricks memastikan bahwa kluster Anda memiliki jumlah pekerja yang ditentukan. Ketika Anda memberikan jangkauan untuk jumlah pekerja, Databricks memilih jumlah pekerja yang sesuai yang diperlukan untuk menjalankan pekerjaan Anda. Ini disebut sebagai autoscaling.
Dengan autoscalling, Azure Databricks secara dinamis mengalokasikan ulang pekerja ke akun untuk karakteristik pekerjaan Anda. Bagian-bagian tertentu dari alur Anda mungkin lebih menuntut komputasi daripada yang lain, dan Databricks secara otomatis menambahkan pekerja tambahan selama fase pekerjaan Anda ini (dan menghapusnya ketika mereka tidak lagi diperlukan).
Penskalaan otomatis mempermudah pencapaian penggunaan kluster yang tinggi, karena Anda tidak perlu menyediakan kluster agar sesuai dengan beban kerja. Ini berlaku terutama untuk beban kerja yang persyaratannya berubah dari waktu ke waktu (seperti menjelajahi himpunan data selama sehari), tetapi juga dapat berlaku untuk beban kerja satu kali lebih pendek yang persyaratan provisinya tidak diketahui. Autoscaling dengan demikian menawarkan dua keuntungan:
- Beban kerja dapat berjalan lebih cepat dibandingkan dengan kluster yang kurang disediakan berukuran konstan.
- Kluster autoscaling dapat mengurangi biaya keseluruhan dibandingkan dengan kluster berukuran statis.
Bergantung pada ukuran konstan kluster dan beban kerja, autoscaling memberi Anda satu atau kedua manfaat ini pada saat yang bersamaan. Ukuran kluster dapat berada di bawah jumlah minimum pekerja yang dipilih saat penyedia cloud mengakhiri instans. Dalam hal ini, Azure Databricks terus mencoba untuk menyediakan kembali instans untuk mempertahankan jumlah minimum pekerja.
Catatan
Penskalaan otomatis tidak tersedia untuk pekerjaan spark-submit.
Cara kerja penskalaan otomatis
- Skalakan dari min ke maks dalam 2 langkah.
- Dapat menurunkan skala bahkan jika kluster tidak menganggur dengan melihat status file shuffle.
- Skala turun berdasarkan persentase node saat ini.
- Pada kluster pekerjaan, skala diturunkan jika cluster kurang dimanfaatkan selama 40 detik terakhir.
- Pada kluster serba guna, skala diturunkan jika kluster kurang dimanfaatkan selama 150 detik terakhir.
- Properti konfigurasi Spark
spark.databricks.aggressiveWindowDownSmenentukan dalam hitungan detik seberapa sering kluster membuat keputusan penskalaan turun. Meningkatkan nilai menyebabkan kluster untuk menurunkan skala lebih lambat. Nilai maksimumnya adalah 600.
Mengaktifkan dan mengonfigurasi penskalaan otomatis
Untuk memungkinkan Azure Databricks mengubah ukuran kluster Anda secara otomatis, Anda mengaktifkan autoscaling untuk kluster dan menyediakan rentang pekerja min dan max.
Aktifkan penskalaan otomatis.
Kluster serba guna - Pada halaman Buat Kluster, pilih kotak centang Aktifkan autoscaling di kotak Opsi Autopilot:

Kluster serba guna - Pada halaman Konfigurasi Kluster, pilih kotak centang Aktifkan autoscaling di kotak Opsi Autopilot:

Konfigurasikan pekerja min dan max.

Saat kluster berjalan, halaman detail kluster menampilkan jumlah pekerja yang dialokasikan. Anda dapat membandingkan jumlah pekerja yang dialokasikan dengan konfigurasi pekerja dan melakukan penyesuaian sesuai kebutuhan.
Penting
Jika Anda menggunakan kumpulan instans:
- Pastikan ukuran kluster yang diminta kurang dari atau sama dengan jumlah minimum instans idle di kumpulan. Jika lebih besar, waktu startup kluster akan setara dengan kluster yang tidak menggunakan pool.
- Pastikan ukuran kluster maksimum kurang dari atau sama dengan kapasitas maksimum kumpulan. Jika lebih besar, pembuatan kluster akan gagal.
Contoh autoscaling
Jika Anda mengonfigurasi ulang kluster statis menjadi kluster autoscaling, Azure Databricks segera mengubah ukuran kluster dalam batas minimum dan maksimum dan kemudian mulai melakukan autoscaling. Sebagai contoh, tabel berikut menunjukkan apa yang terjadi pada kluster dengan ukuran awal tertentu jika Anda mengonfigurasi ulang kluster ke skala otomatis antara 5 dan 10 node.
| Ukuran awal | 'Ukuran setelah konfigurasi ulang |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Penyimpanan lokal autoscaling
Seringkali sulit untuk memperkirakan berapa banyak ruang disk yang akan diambil pekerjaan tertentu. Untuk menyelamatkan Anda dari keharusan memperkirakan berapa gigabyte disk terkelola untuk dilampirkan ke kluster Anda pada saat pembuatan, Azure Databricks secara otomatis mengaktifkan penyimpanan lokal penskalaan otomatis di semua kluster Azure Databricks.
Dengan autoscaling penyimpanan lokal, Azure Databricks memantau jumlah ruang disk kosong yang tersedia pada pekerja Spark kluster Anda. Jika pekerja mulai kehabisan disk, Azure Databricks otomatis melampirkan disk terkelola baru ke pekerja sebelum ruang disk habis. Disk dilampirkan hingga batas 5 TB dari total ruang disk per mesin virtual (termasuk penyimpanan lokal awal mesin virtual).
Disk terkelola yang dilampirkan ke mesin virtual terlepas hanya ketika mesin virtual dikembalikan ke Azure. Artinya, disk yang dikelola tidak pernah terlepas dari mesin virtual selama itu adalah bagian dari kluster berjalan. Untuk menurunkan skala penggunaan disk terkelola, Azure Databricks merekomendasikan penggunaan fitur ini dalam kluster yang dikonfigurasi dengan ukuran Kluster dan penskalaan otomatis atau Penghentian tidak terduga.
Enkripsi disk lokal
Penting
Fitur ini ada di Pratinjau Publik.
Beberapa jenis instans yang Anda gunakan untuk menjalankan kluster mungkin memiliki disk yang terpasang secara lokal. Azure Databricks dapat menyimpan data acak atau data sementara pada disk yang dilampirkan secara lokal ini. Untuk memastikan bahwa semua data tidak aktif dienkripsi untuk semua jenis penyimpanan, termasuk data shuffle yang disimpan sementara pada disk lokal kluster Anda, Anda dapat mengaktifkan enkripsi disk lokal.
Penting
Beban kerja Anda mungkin berjalan lebih lambat karena dampak kinerja membaca dan menulis data terenkripsi ke dan dari volume lokal.
Ketika enkripsi disk lokal diaktifkan, Azure Databricks menghasilkan kunci enkripsi secara lokal yang unik untuk setiap node kluster dan digunakan untuk mengenkripsi semua data yang disimpan pada disk lokal. Ruang lingkup kunci bersifat lokal untuk setiap node kluster dan dihancurkan bersama dengan node kluster itu sendiri. Selama masa pakainya, kunci berada dalam memori untuk enkripsi dan dekripsi dan disimpan dienkripsi pada disk.
Untuk mengaktifkan enkripsi disk lokal, Anda harus menggunakan API Kluster. Selama pembuatan atau pengeditan kluster, atur:
{
"enable_local_disk_encryption": true
}
Lihat API Kluster untuk contoh cara memanggil API ini.
Berikut adalah contoh panggilan pembuatan kluster yang memungkinkan enkripsi disk lokal:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Mode keamanan
Jika ruang kerja Anda ditetapkan ke metastore Unity Catalog, Anda menggunakan mode keamanan alih-alih mode kluster Konkurensi Tinggi untuk memastikan integritas kontrol akses dan menegakkan jaminan isolasi yang kuat. Mode kluster Konkurensi Tinggi tidak tersedia dengan Katalog Unity.
Di bawah Opsi tingkat lanjut, pilih dari mode keamanan kluster berikut ini:
- Tidak ada: Tidak ada isolasi. Tidak memberlakukan kontrol akses tabel ruang kerja-lokal atau penelusuran kredensial. Tidak dapat mengakses data Katalog Unity.
- Pengguna Tunggal: Hanya dapat digunakan oleh satu pengguna (secara default, pengguna yang membuat kluster). Pengguna lain tidak dapat melampirkan ke kluster. Saat mengakses tampilan dari kluster dengan mode keamanan Pengguna Tunggal, tampilan dijalankan dengan izin pengguna. Kluster pengguna tunggal mendukung beban kerja menggunakan skrip Python, Scala, dan R. Init, penginstalan pustaka, dan pemasangan DBFS didukung pada kluster pengguna tunggal. Pekerjaan otomatis harus menggunakan kluster pengguna-tunggal.
- Isolasi Pengguna: Dapat digunakan oleh beberapa pengguna. Hanya beban SQL yang tidak didukung. Instalasi pustaka, skrip init, dan pemasangan DBFS dinonaktifkan untuk memberlakukan isolasi ketat di antara pengguna kluster.
- Hanya Tabel ACL (Warisan: Menerapkan kontrol akses tabel ruang kerja-lokal, tetapi tidak dapat mengakses data Katalog Unity.
- Hanya penelusuran (Warisan): Memberlakukan penelusuran kredensial ruang kerja-lokal, tetapi tidak dapat mengakses data Katalog Unity.
Satu-satunya mode keamanan yang didukung untuk beban kerja Katalog Unity adalah Single User dan User Isolation.
Untuk informasi selengkapnya, lihat Mode akses.
Konfigurasi Spark
Untuk menyempurnakan pekerjaan Spark, Anda dapat menyediakan properti konfigurasi Spark kustom dalam konfigurasi kluster.
Pada halaman konfigurasi kluster, klik tombol Opsi Lanjutan.
Klik tab Spark.
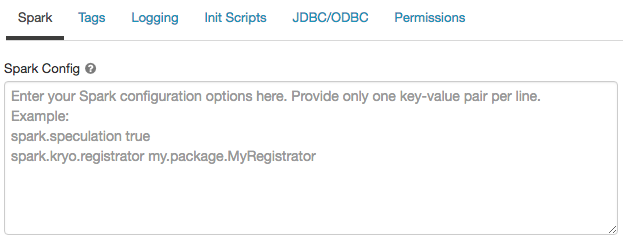
Di Konfigurasi Spark, masukkan properti konfigurasi sebagai satu pasangan nilai kunci per baris.
Saat Anda mengonfigurasi kluster menggunakan API Kluster, atur properti Spark di spark_conf bidang di API buat kluster baru atau Perbarui API konfigurasi kluster.
Databricks tidak merekomendasikan penggunaan skrip init global.
Untuk mengatur properti Spark untuk semua kluster, buat skrip init global:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Ambil properti konfigurasi Spark dari rahasia
Databricks merekomendasikan untuk menyimpan informasi sensitif, seperti kata sandi, secara rahasia, bukan teks biasa. Untuk mereferensikan rahasia dalam konfigurasi Spark, gunakan sintaks berikut:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Misalnya, untuk mengatur properti konfigurasi Spark yang dipanggil password ke nilai rahasia yang disimpan di secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Untuk informasi selengkapnya, lihat Sintaksis untuk mereferensikan rahasia di properti konfigurasi Spark atau variabel lingkungan.
Variabel lingkungan
Anda dapat mengonfigurasi variabel lingkungan kustom yang dapat Anda akses dari skrip init yang berjalan di kluster. Databricks juga menyediakan variabel lingkungan yang telah ditentukan sebelumnya yang dapat Anda gunakan dalam skrip init. Anda tidak dapat mengganti variabel lingkungan yang telah ditentukan sebelumnya ini.
Pada halaman konfigurasi kluster, klik tombol Opsi Lanjutan.
Klik tab Spark.
Atur variabel lingkungan di bidang Variabel Lingkungan.
Anda juga dapat mengatur variabel lingkungan menggunakan spark_env_vars bidang di API Buat kluster baru atau Perbarui API konfigurasi kluster.
Tag kluster
Tag kluster memungkinkan Anda untuk dengan mudah memantau biaya sumber daya cloud yang digunakan oleh pengguna dan grup di organisasi Anda. Anda dapat menentukan tag sebagai pasangan nilai kunci saat membuat kluster, dan Azure Databricks menerapkan tag ini ke sumber daya cloud seperti VM dan volume disk, begitu juga Laporan penggunaan DBU.
Untuk kluster yang diluncurkan dari kumpulan, tag kluster kustom hanya diterapkan ke laporan penggunaan DBU dan tidak disebarkan ke sumber daya cloud.
Untuk informasi terperinci tentang cara kumpulan dan jenis tag kluster bekerja sama, lihat Memantau penggunaan menggunakan tag.
Untuk kenyamanan, Azure Databricks menerapkan empat tag default ke setiap kluster: Vendor, Creator, ClusterName, dan ClusterId.
Selain itu, pada kluster pekerjaan, Azure Databricks menerapkan dua tag default: RunName dan JobId.
Pada sumber daya yang digunakan oleh Databricks SQL, Azure Databricks juga menerapkan tag default SqlWarehouseId.
Peringatan
Jangan tetapkan tag kustom dengan kunci Name ke kluster. Setiap kluster memiliki tag Name yang nilainya ditetapkan oleh Azure Databricks. Jika Anda mengubah nilai yang terkait dengan kunci Name, kluster tidak dapat lagi dilacak oleh Azure Databricks. Akibatnya, kluster mungkin tidak dihentikan setelah menganggur dan akan terus dikenakan biaya penggunaan.
Anda dapat menambahkan tag kustom saat membuat kluster. Untuk mengonfigurasi tag kluster:
Pada halaman konfigurasi kluster, klik tombol Opsi Lanjutan.
Pada bagian bawah halaman, klik tab Tag.
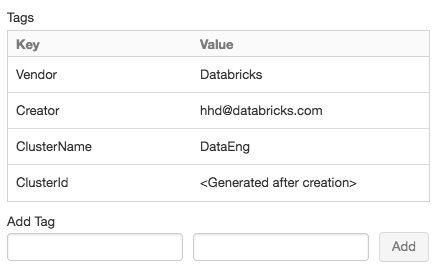
Tambahkan pasangan nilai kunci untuk setiap tag kustom. Anda dapat menambahkan hingga 43 tag kustom.
Akses SSH ke kluster
Untuk alasan keamanan, di Azure Databricks port SSH ditutup secara default. Jika Anda ingin mengaktifkan akses SSH ke kluster Spark Anda, hubungi dukungan Azure Databricks.
Catatan
SSH hanya dapat diaktifkan jika ruang kerja Anda disebarkan di jaringan virtual Azure Anda sendiri.
Pengiriman log yang lebih cepat
Saat membuat kluster, Anda dapat menentukan lokasi untuk mengirimkan log untuk node driver Spark, node pekerja, dan peristiwa. Log dikirim setiap lima menit ke tujuan yang Anda pilih. Ketika kluster dihentikan, Azure Databricks menjamin untuk mengirimkan semua log yang dihasilkan hingga kluster dihentikan.
Tujuan log tergantung pada ID kluster. Jika tujuan yang ditentukan adalah dbfs:/cluster-log-delivery, log kluster untuk 0630-191345-leap375 dikirim ke dbfs:/cluster-log-delivery/0630-191345-leap375.
Untuk mengonfigurasi lokasi pengiriman log:
Pada halaman konfigurasi kluster, klik tombol Opsi Lanjutan.
Klik tab Pengelogan.

Pilih jenis tujuan.
Masukkan jalur log kluster.
Catatan
Fitur ini juga tersedia di REST API. Lihat API Kluster.
Skrip Init
Inisialisasi node kluster - atau init-script adalah skrip shell yang berjalan selama startup untuk setiap node kluster sebelum driver Spark atau Worker JVM mulai. Anda dapat menggunakan skrip init untuk menginstal paket dan pustaka yang tidak termasuk dalam runtime bahasa umum Databricks, memodifikasi classpath sistem JVM, mengatur properti sistem dan variabel lingkungan yang digunakan oleh JVM, atau memodifikasi parameter konfigurasi Spark, di antara tugas konfigurasi lainnya.
Anda dapat melampirkan skrip init ke kluster dengan memperluas bagian Opsi Lanjutan dan mengklik tab Skrip Init.
Untuk petunjuk terperinci, lihat Apa itu skrip init?.