Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Fitur ini ada di Pratinjau Publik. Untuk informasi tentang kelayakan dan pengaktifan, lihat Mengaktifkan komputasi tanpa server.
Artikel ini menjelaskan cara menggunakan komputasi tanpa server untuk buku catatan. Untuk informasi tentang menggunakan komputasi tanpa server untuk alur kerja, lihat Menjalankan pekerjaan Azure Databricks Anda dengan komputasi tanpa server untuk alur kerja.
Untuk informasi harga, lihat Harga Databricks.
Persyaratan
Ruang kerja Anda harus diaktifkan untuk Katalog Unity.
Ruang kerja Anda harus berada di wilayah yang didukung. Lihat Wilayah Azure Databricks.
Akun Anda harus diaktifkan untuk komputasi tanpa server. Lihat Mengaktifkan komputasi tanpa server.
Melampirkan buku catatan ke komputasi tanpa server
Jika ruang kerja Anda diaktifkan untuk komputasi interaktif tanpa server, semua pengguna di ruang kerja memiliki akses ke komputasi tanpa server untuk buku catatan. Tidak diperlukan izin tambahan.
Untuk melampirkan ke komputasi tanpa server, klik menu drop-down Sambungkan di buku catatan dan pilih Tanpa Server. Untuk notebook baru, komputasi terlampir secara otomatis default ke tanpa server setelah eksekusi kode jika tidak ada sumber daya lain yang dipilih.
Menginstal dependensi buku catatan
Anda dapat menginstal dependensi Python untuk notebook tanpa server menggunakan panel sisi Lingkungan , yang menyediakan satu tempat untuk mengedit, menampilkan, dan mengekspor persyaratan pustaka untuk buku catatan. Dependensi ini dapat ditambahkan menggunakan lingkungan dasar atau secara individual.
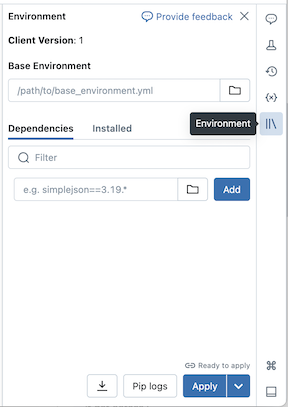
Mengonfigurasi lingkungan dasar
Lingkungan dasar adalah file YAML yang disimpan sebagai file ruang kerja atau pada volume Katalog Unity yang menentukan dependensi lingkungan tambahan. Lingkungan dasar dapat dibagikan di antara buku catatan. Untuk mengonfigurasi lingkungan dasar:
Buat file YAML yang menentukan pengaturan untuk lingkungan virtual Python. Contoh YAML berikut, yang didasarkan pada spesifikasi lingkungan proyek MLflow, menentukan lingkungan dasar dengan beberapa dependensi pustaka:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Unggah file YAML sebagai file ruang kerja atau ke volume Katalog Unity. Lihat Mengimpor file atau Mengunggah file ke volume Katalog Unity.
Di sebelah kanan buku catatan, klik tombol
 untuk memperluas panel Lingkungan . Tombol ini hanya muncul ketika buku catatan tersambung ke komputasi tanpa server.
untuk memperluas panel Lingkungan . Tombol ini hanya muncul ketika buku catatan tersambung ke komputasi tanpa server.Di bidang Lingkungan Dasar, masukkan jalur file YAML yang diunggah atau navigasikan ke dalamnya dan pilih.
Klik Terapkan. Ini menginstal dependensi di lingkungan virtual notebook dan memulai ulang proses Python.
Pengguna dapat mengambil alih dependensi yang ditentukan di lingkungan dasar dengan menginstal dependensi satu per satu.
Menambahkan dependensi satu per satu
Anda juga dapat menginstal dependensi pada buku catatan yang tersambung ke komputasi tanpa server menggunakan tab Dependensi panel Lingkungan :
- Di sebelah kanan buku catatan, klik tombol untuk memperluas panel Lingkungan . Tombol ini hanya muncul ketika buku catatan tersambung ke komputasi tanpa server.
- Di bagian Dependensi , klik Tambahkan Dependensi dan masukkan jalur dependensi pustaka di bidang . Anda dapat menentukan dependensi dalam format apa pun yang valid dalam file requirements.txt .
- Klik Terapkan. Ini menginstal dependensi di lingkungan virtual notebook dan memulai ulang proses Python.
Catatan
Pekerjaan yang menggunakan komputasi tanpa server akan menginstal spesifikasi lingkungan notebook sebelum menjalankan kode notebook. Ini berarti bahwa tidak perlu menambahkan dependensi saat menjadwalkan notebook sebagai pekerjaan. Lihat Mengonfigurasi lingkungan dan dependensi notebook.
Menampilkan dependensi dan log pip yang terinstal
Untuk melihat dependensi yang terinstal, klik Terinstal di panel sisi Lingkungan untuk buku catatan. Log penginstalan pip untuk lingkungan notebook juga tersedia dengan mengklik log Pip di bagian bawah panel.
Mengatur ulang lingkungan
Jika buku catatan Anda tersambung ke komputasi tanpa server, Databricks secara otomatis menyimpan konten lingkungan virtual notebook. Ini berarti Anda umumnya tidak perlu menginstal ulang dependensi Python yang ditentukan di panel Lingkungan saat Anda membuka notebook yang ada, bahkan jika telah terputus karena tidak aktif.
Penembolokan lingkungan virtual Python juga berlaku untuk pekerjaan. Ini berarti bahwa eksekusi pekerjaan berikutnya lebih cepat karena dependensi yang diperlukan sudah tersedia.
Catatan
Jika Anda mengubah implementasi paket Python kustom yang digunakan dalam pekerjaan tanpa server, Anda juga harus memperbarui nomor versinya untuk pekerjaan guna mengambil implementasi terbaru.
Untuk menghapus cache lingkungan dan melakukan penginstalan baru dependensi yang ditentukan di panel Lingkungan buku catatan yang dilampirkan ke komputasi tanpa server, klik panah di samping Terapkan lalu klik Atur ulang lingkungan.
Catatan
Atur ulang lingkungan virtual jika Anda menginstal paket yang merusak atau mengubah notebook inti atau lingkungan Apache Spark. Melepaskan notebook dari komputasi tanpa server dan memasangnya kembali tidak selalu menghapus seluruh cache lingkungan.
Menampilkan wawasan kueri
Komputasi tanpa server untuk buku catatan dan alur kerja menggunakan wawasan kueri untuk menilai performa eksekusi Spark. Setelah menjalankan sel di buku catatan, Anda bisa menampilkan wawasan yang terkait dengan kueri SQL dan Python dengan mengklik tautan Lihat performa .
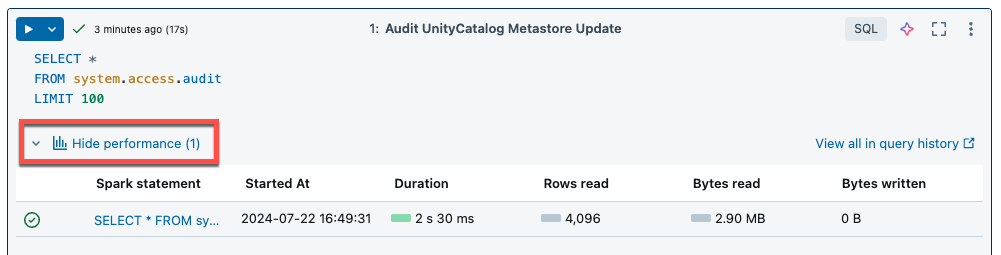
Anda dapat mengklik salah satu pernyataan Spark untuk menampilkan metrik kueri. Dari sana Anda bisa mengklik Lihat profil kueri untuk melihat visualisasi eksekusi kueri. Untuk informasi selengkapnya tentang profil kueri, lihat Profil kueri.
Catatan
Untuk melihat wawasan performa untuk eksekusi pekerjaan Anda, lihat Menampilkan wawasan kueri eksekusi pekerjaan.
Riwayat Kueri
Semua kueri yang dijalankan pada komputasi tanpa server juga akan direkam di halaman riwayat kueri ruang kerja Anda. Untuk informasi tentang riwayat kueri, lihat Riwayat kueri.
Batasan wawasan kueri
- Profil kueri hanya tersedia setelah eksekusi kueri berakhir.
- Metrik diperbarui secara langsung meskipun profil kueri tidak ditampilkan selama eksekusi.
- Hanya status kueri berikut yang tercakup: BERJALAN, DIBATALKAN, GAGAL, SELESAI.
- Menjalankan kueri tidak dapat dibatalkan dari halaman riwayat kueri. Mereka dapat dibatalkan di buku catatan atau pekerjaan.
- Metrik verbose tidak tersedia.
- Unduhan Profil Kueri tidak tersedia.
- Akses ke antarmuka pengguna Spark tidak tersedia.
- Teks pernyataan hanya berisi baris terakhir yang dijalankan. Namun, mungkin ada beberapa baris sebelum baris ini yang dijalankan sebagai bagian dari pernyataan yang sama.
Batasan
Untuk daftar batasan, lihat Batasan komputasi tanpa server.