Kontrol akses halus pada komputasi pengguna tunggal
Penting
Fitur ini ada di Pratinjau Publik.
Artikel ini memperkenalkan fungsionalitas pemfilteran data yang memungkinkan kontrol akses halus pada kueri yang berjalan pada komputasi pengguna tunggal (komputasi semua tujuan atau pekerjaan yang dikonfigurasi dengan Mode akses pengguna tunggal). Lihat Mode akses.
Pemfilteran data ini dilakukan di belakang layar menggunakan komputasi tanpa server.
Mengapa beberapa kueri pada komputasi pengguna tunggal memerlukan pemfilteran data?
Unity Catalog memungkinkan Anda mengontrol akses ke data tabular di tingkat kolom dan baris (juga dikenal sebagai kontrol akses terperinci) menggunakan fitur berikut:
Saat pengguna mengkueri tampilan yang mengecualikan data dari tabel yang dirujuk atau tabel kueri yang menerapkan filter dan masker, mereka dapat menggunakan salah satu sumber daya komputasi berikut tanpa batasan:
- Gudang SQL
- Komputasi bersama
Namun, jika Anda menggunakan komputasi pengguna tunggal untuk menjalankan kueri tersebut, komputasi dan ruang kerja Anda harus memenuhi persyaratan tertentu:
Sumber daya komputasi pengguna tunggal harus berada di Databricks Runtime 15.4 LTS atau lebih tinggi.
Ruang kerja harus diaktifkan untuk komputasi tanpa server untuk pekerjaan, buku catatan, dan Tabel Langsung Delta.
Untuk mengonfirmasi bahwa wilayah ruang kerja Anda mendukung komputasi tanpa server, lihat Fitur dengan ketersediaan regional terbatas.
Jika sumber daya komputasi pengguna tunggal dan ruang kerja Anda memenuhi persyaratan ini, pemfilteran data dijalankan secara otomatis setiap kali Anda mengkueri tampilan atau tabel yang menggunakan kontrol akses mendetail.
Dukungan untuk tampilan materialisasi, tabel streaming, dan tampilan standar
Selain tampilan dinamis, filter baris, dan masker kolom, pemfilteran data juga memungkinkan kueri pada tampilan dan tabel berikut yang tidak didukung pada komputasi pengguna tunggal yang menjalankan Databricks Runtime 15.3 ke bawah:
-
Pada komputasi pengguna tunggal yang menjalankan Databricks Runtime 15.3 ke bawah, pengguna yang menjalankan kueri pada tampilan harus memiliki
SELECTpada tabel dan tampilan yang direferensikan oleh tampilan, yang berarti Anda tidak dapat menggunakan tampilan untuk menyediakan kontrol akses mendetail. Pada Databricks Runtime 15.4 dengan pemfilteran data, pengguna yang mengkueri tampilan tidak memerlukan akses ke tabel dan tampilan yang direferensikan.
Bagaimana cara kerja pemfilteran data pada komputasi pengguna tunggal?
Setiap kali kueri mengakses objek database berikut, sumber daya komputasi pengguna tunggal meneruskan kueri ke komputasi tanpa server untuk melakukan pemfilteran data:
- Tampilan yang dibangun di atas tabel yang tidak memiliki
SELECThak istimewa pengguna - Tampilan dinamis
- Tabel dengan filter baris atau masker kolom yang ditentukan
- Tampilan materialisasi dan tabel streaming
Dalam diagram berikut, pengguna memiliki SELECT , table_1, view_2dan table_w_rls, yang memiliki filter baris yang diterapkan. Pengguna tidak memiliki SELECT pada , yang dirujuk table_2oleh view_2.

Kueri pada ditangani table_1 sepenuhnya oleh sumber daya komputasi pengguna tunggal, karena tidak diperlukan pemfilteran. Kueri pada view_2 dan table_w_rls memerlukan pemfilteran data untuk mengembalikan data yang dapat diakses pengguna. Kueri ini ditangani oleh kemampuan pemfilteran data pada komputasi tanpa server.
Biaya apa yang dikeluarkan?
Pelanggan dikenakan biaya untuk sumber daya komputasi tanpa server yang digunakan untuk melakukan operasi pemfilteran data. Untuk informasi harga, lihat Tingkat platform dan Add-On.
Anda bisa mengkueri tabel penggunaan penagihan sistem untuk melihat berapa banyak Anda telah ditagih. Misalnya, kueri berikut memecah biaya komputasi oleh pengguna:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Menampilkan performa kueri saat pemfilteran data terlibat
Antarmuka pengguna Spark untuk komputasi pengguna tunggal menampilkan metrik yang dapat Anda gunakan untuk memahami performa kueri Anda. Untuk setiap kueri yang Anda jalankan pada sumber daya komputasi, tab SQL/Dataframe menampilkan representasi grafik kueri. Jika kueri terlibat dalam pemfilteran data, UI menampilkan simpul operator RemoteSparkConnectScan di bagian bawah grafik. Simpul tersebut menampilkan metrik yang bisa Anda gunakan untuk menyelidiki performa kueri. Lihat Menampilkan informasi komputasi di UI Apache Spark.
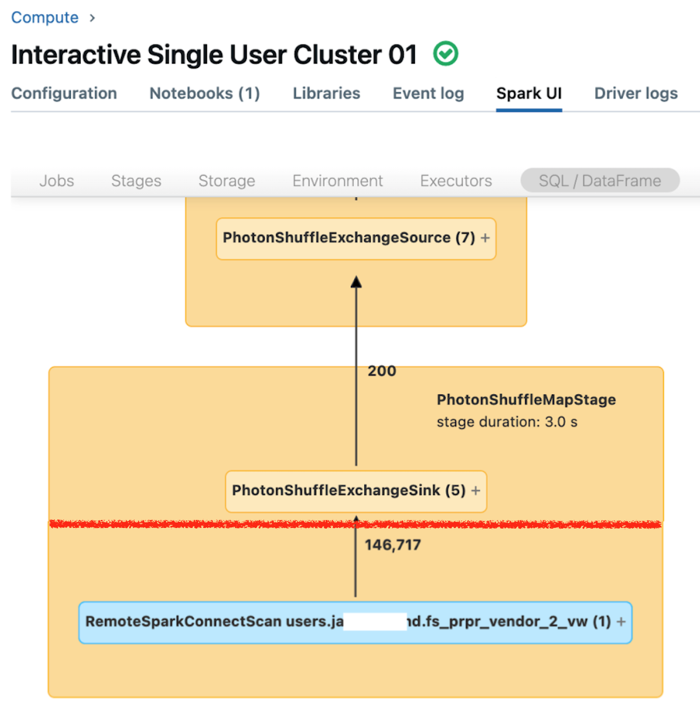
Perluas simpul operator RemoteSparkConnectScan untuk melihat metrik yang membahas pertanyaan seperti berikut:
- Berapa lama waktu yang dibutuhkan pemfilteran data? Lihat "total waktu eksekusi jarak jauh."
- Berapa banyak baris yang tersisa setelah pemfilteran data? Lihat "output baris."
- Berapa banyak data (dalam byte) yang dikembalikan setelah pemfilteran data? Lihat "ukuran output baris."
- Berapa banyak file data yang dipupuk partisi dan tidak harus dibaca dari penyimpanan? Lihat "File diprajakan" dan "Ukuran file yang dipungut."
- Berapa banyak file data yang tidak dapat dipupuk dan harus dibaca dari penyimpanan? Lihat "File dibaca" dan "Ukuran file yang dibaca."
- Dari file yang harus dibaca, berapa banyak yang sudah ada di cache? Lihat "Ukuran hit cache" dan "Cache melewatkan ukuran."
Batasan
Selama Pratinjau Umum, batasan berikut berlaku:
Tidak ada dukungan untuk operasi tulis atau refresh tabel pada tabel yang menerapkan filter baris atau masker kolom.
Secara khusus, operasi DML, seperti
INSERT,DELETE, ,UPDATEREFRESH TABLE, danMERGE, tidak didukung. Anda hanya dapat membaca (SELECT) dari tabel ini.Gabungan mandiri diblokir secara default saat pemfilteran data dipanggil, tetapi Anda dapat mengizinkannya dengan mengatur
spark.databricks.remoteFiltering.blockSelfJoinske false pada komputasi tempat Anda menjalankan perintah ini.Sebelum Anda mengaktifkan gabungan mandiri pada sumber daya komputasi pengguna tunggal, ketahuilah bahwa kueri gabungan mandiri yang ditangani oleh kemampuan pemfilteran data dapat mengembalikan rekam jepret yang berbeda dari tabel jarak jauh yang sama.