Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan perbedaan utama antara batch dan streaming, dua semantik pemrosesan data yang berbeda yang digunakan untuk beban kerja rekayasa data, termasuk penyerapan, transformasi, dan pemrosesan real time.
Streaming biasanya dikaitkan dengan latensi rendah dan pemrosesan berkelanjutan dari bus pesan, seperti Apache Kafka.
Namun, di Azure Databricks memiliki definisi yang lebih ekspansif. Mesin dasar Alur Deklaratif Lakeflow Spark (Apache Spark dan Streaming Terstruktur) memiliki arsitektur terpadu untuk pemrosesan batch dan streaming:
- Mesin dapat memperlakukan sumber seperti penyimpanan objek cloud dan Delta Lake sebagai sumber streaming untuk pemrosesan bertahap yang efisien.
- Pemrosesan streaming dapat dijalankan dengan cara yang dipicu dan berkelanjutan, memberi Anda fleksibilitas untuk mengontrol tradeoff biaya dan performa untuk beban kerja streaming Anda.
Di bawah ini adalah perbedaan semantik mendasar yang membedakan batch dan streaming, termasuk kelebihan dan kekurangannya, dan pertimbangan untuk memilihnya untuk beban kerja Anda.
Semantik Batch
Dengan pemrosesan batch, mesin tidak melacak data apa yang sudah diproses di sumbernya. Semua data yang saat ini tersedia di sumber diproses pada saat pemrosesan. Dalam praktiknya, sumber data batch biasanya dipartisi secara logis, misalnya, berdasarkan hari atau wilayah, untuk membatasi pemrosesan ulang data.
Misalnya, menghitung harga penjualan item rata-rata, yang dikumpulkan pada tingkat per jam, untuk acara penjualan yang dilakukan oleh perusahaan e-commerce dapat dijadwalkan sebagai pemrosesan kelompok untuk menghitung harga penjualan rata-rata setiap jam. Dengan batch, data dari jam-jam sebelumnya diproses ulang setiap jam, dan hasil perhitungan sebelumnya digantikan untuk mencerminkan hasil terbaru.

Semantik streaming
Dengan pemrosesan streaming, mesin melacak data apa yang sedang diproses dan hanya memproses data baru dalam eksekusi berikutnya. Dalam contoh di atas, Anda dapat menjadwalkan pemrosesan streaming alih-alih pemrosesan batch untuk menghitung harga penjualan rata-rata setiap jam. Dengan streaming, hanya data baru yang ditambahkan ke sumber sejak proses terakhir diproses. Hasil yang baru dihitung harus ditambahkan ke hasil yang dihitung sebelumnya untuk memeriksa hasil lengkap.
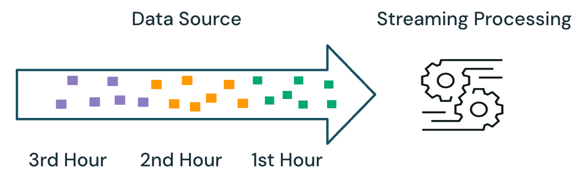
Pemrosesan berkelompok vs. Pengaliran data
Dalam contoh di atas, streaming lebih baik daripada pemrosesan batch karena tidak memproses data yang sama yang diproses dalam eksekusi sebelumnya. Namun, pemrosesan streaming menjadi lebih kompleks dengan skenario seperti data tidak berurutan dan kedatangan terlambat pada sumber.
Contoh data keterlambatan kedatangan adalah jika beberapa data penjualan dari jam pertama tidak tiba di sumber hingga jam kedua:
- Dalam pemrosesan batch, data keterlambatan kedatangan dari jam pertama akan diproses dengan data dari jam kedua dan data yang ada dari jam pertama. Hasil sebelumnya dari satu jam pertama akan ditimpa dan dikoreksi dengan data kedatangan terlambat.
- Dalam pemrosesan streaming, data yang tiba terlambat dari jam pertama akan diproses tanpa menyertakan data jam pertama lainnya yang sudah diproses. Logika pemrosesan harus menyimpan informasi jumlah dan hitungan dari perhitungan rata-rata jam pertama untuk memperbarui hasil sebelumnya dengan benar.
Kompleksitas streaming ini biasanya diperkenalkan ketika pemrosesan bersifat stateful, seperti gabungan, agregasi, dan deduplikasi.
Untuk pemrosesan streaming tanpa status, seperti menggabungkan data baru dari sumber, menangani data yang di luar urutan dan kedatangan terlambat lebih sederhana, karena data yang tiba terlambat dapat digabungkan ke hasil sebelumnya sesuai kedatangan data di sumber.
Tabel di bawah ini menguraikan pro dan kontra dari pemrosesan batch dan streaming dan berbagai fitur produk yang mendukung kedua semantik pemrosesan ini di Databricks Lakeflow.
| Memproses semantik | Kelebihan | Kekurangan | Produk rekayasa data |
|---|---|---|---|
| Batch |
|
|
|
| Siaran Langsung |
|
|
|
Rekomendasi
Tabel di bawah ini menguraikan semantik pemrosesan yang direkomendasikan berdasarkan karakteristik beban kerja pemrosesan data di setiap lapisan arsitektur medali.
| Lapisan medali | Karakteristik beban kerja | Rekomendasi |
|---|---|---|
| Perunggu |
|
|
| Perak |
|
|
| Emas |
|
|