Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menunjukkan cara memulai Databricks Connect for Scala menggunakan IntelliJ IDEA dan plugin Scala.
Dalam tutorial ini Anda membuat proyek di IntelliJ IDEA, menginstal Databricks Connect untuk Databricks Runtime 13.3 LTS ke atas, dan menjalankan kode sederhana pada komputasi di ruang kerja Databricks Anda dari IntelliJ IDEA.
Petunjuk / Saran
Untuk mempelajari cara menggunakan Bundel Otomatisasi Deklaratif untuk membuat proyek Scala yang menjalankan kode pada komputasi tanpa server, lihat Membangun JAR Scala menggunakan Bundel Otomatisasi Deklaratif.
Persyaratan
Untuk menyelesaikan tutorial ini, Anda harus memenuhi persyaratan berikut:
Ruang kerja, lingkungan lokal, dan komputasi Anda memenuhi persyaratan untuk Databricks Connect for Scala. Lihat Persyaratan penggunaan Databricks Connect.
Anda harus memiliki ID kluster Anda yang tersedia. Untuk mendapatkan ID kluster Anda, di ruang kerja Anda, klik Komputasi di bar samping, lalu klik nama kluster Anda. Di bilah alamat browser web Anda, salin string karakter antara
clustersdanconfigurationdi URL.Anda memiliki Java Development Kit (JDK) yang diinstal pada komputer pengembangan Anda. Untuk informasi tentang versi yang akan diinstal, lihat matriks dukungan versi.
Nota
Jika Anda tidak memiliki JDK yang terinstal, atau jika Anda memiliki beberapa penginstalan JDK di komputer pengembangan, Anda dapat menginstal atau memilih JDK tertentu nanti di Langkah 1. Memilih penginstalan JDK yang berada di bawah atau di atas versi JDK pada kluster Anda mungkin menghasilkan hasil yang tidak terduga, atau kode Anda mungkin tidak berjalan sama sekali.
Anda telah menginstal IntelliJ IDEA . Tutorial ini diuji dengan IntelliJ IDEA Community Edition 2023.3.6. Jika Anda menggunakan versi atau edisi IntelliJ IDEA yang berbeda, instruksi berikut mungkin bervariasi.
Anda memiliki plugin Scala untuk IntelliJ IDEA yang terinstal.
Langkah 1: Mengonfigurasi autentikasi Azure Databricks
Tutorial ini menggunakan autentikasi pengguna-ke-mesin (U2M) Azure Databricks OAuth dan profil konfigurasi Azure Databricks untuk mengautentikasi dengan ruang kerja Azure Databricks Anda. Untuk menggunakan jenis autentikasi yang berbeda, lihat Mengonfigurasi properti koneksi.
Mengonfigurasi autentikasi OAuth U2M memerlukan Databricks CLI, sebagai berikut:
Instal Databricks CLI:
Linux, macOS
Gunakan Homebrew untuk menginstal Databricks CLI dengan menjalankan dua perintah berikut:
brew tap databricks/tap brew install databricksWindows
Anda dapat menggunakan winget, Chocolatey atau Subsistem Windows untuk Linux (WSL) untuk menginstal Databricks CLI. Jika Anda tidak dapat menggunakan
winget, Chocolatey, atau WSL, Anda harus melewati prosedur ini dan menggunakan Prompt Perintah atau PowerShell untuk menginstal Databricks CLI dari sumber sebagai gantinya.Nota
Menginstal Databricks CLI dengan Chocolatey bersifat Eksperimental.
Untuk menggunakan
wingetuntuk menginstal Databricks CLI, jalankan dua perintah berikut, lalu mulai ulang Command Prompt Anda.winget search databricks winget install Databricks.DatabricksCLIUntuk menggunakan Chocolatey untuk menginstal Databricks CLI, jalankan perintah berikut:
choco install databricks-cliUntuk menggunakan WSL untuk menginstal Databricks CLI:
Instal
curldanzipmelalui WSL. Untuk informasi selengkapnya, lihat dokumentasi sistem operasi Anda.Gunakan WSL untuk menginstal Databricks CLI dengan menjalankan perintah berikut:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Konfirmasikan bahwa Databricks CLI diinstal dengan menjalankan perintah berikut, yang menampilkan versi CLI Databricks yang diinstal saat ini. Versi ini harus 0.205.0 atau lebih tinggi:
databricks -v
Mulai autentikasi OAuth U2M, sebagai berikut:
Gunakan Databricks CLI untuk memulai manajemen token OAuth secara lokal dengan menjalankan perintah berikut untuk setiap ruang kerja target.
Dalam perintah berikut, ganti
<workspace-url>dengan URL per ruang kerja Azure Databricks Anda, misalnyahttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Databricks CLI meminta Anda untuk menyimpan informasi yang Anda masukkan sebagai profil konfigurasi Azure Databricks. Tekan
Enteruntuk menerima nama profil yang disarankan, atau masukkan nama profil baru atau yang sudah ada. Profil yang sudah ada dengan nama yang sama akan digantikan dengan informasi yang Anda masukkan. Anda dapat menggunakan profil untuk mengalihkan konteks autentikasi dengan cepat di beberapa ruang kerja.Untuk mendapatkan daftar profil yang ada, di terminal atau prompt perintah terpisah, gunakan Databricks CLI untuk menjalankan perintah
databricks auth profiles. Untuk melihat pengaturan profil tertentu yang sudah ada, jalankan perintahdatabricks auth env --profile <profile-name>.Di browser web Anda, selesaikan instruksi di layar untuk masuk ke ruang kerja Azure Databricks Anda.
Dalam daftar kluster yang tersedia yang muncul di terminal atau prompt perintah Anda, gunakan tombol panah atas dan panah bawah Anda untuk memilih kluster Azure Databricks target di ruang kerja Anda, lalu tekan
Enter. Anda juga dapat mengetik bagian mana pun dari nama tampilan kluster untuk memfilter daftar kluster yang tersedia.Untuk melihat nilai token OAuth profil saat ini dan tanda waktu kedaluwarsa token yang akan datang, jalankan salah satu perintah berikut:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Jika Anda memiliki beberapa profil dengan nilai yang sama
--host, Anda mungkin perlu menentukan--hostopsi dan-pbersama-sama untuk membantu Databricks CLI menemukan informasi token OAuth yang cocok dengan benar.
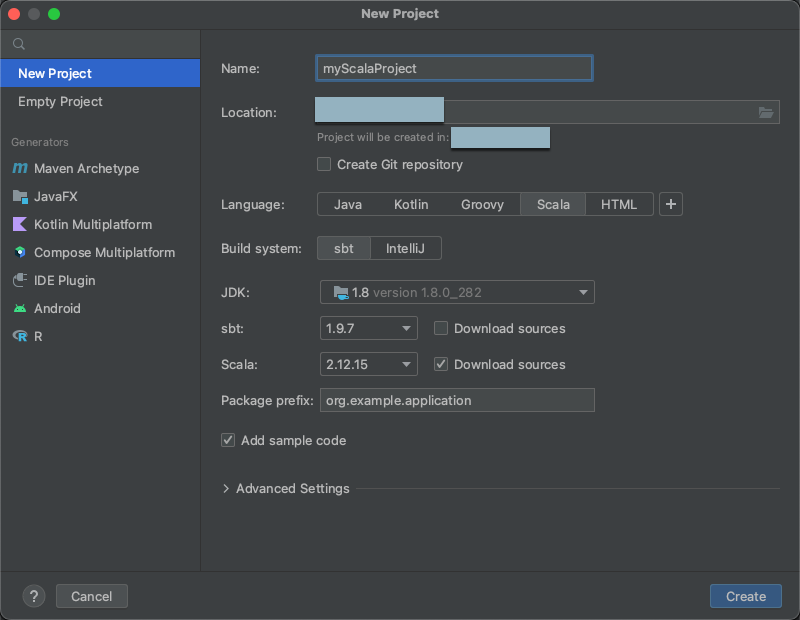
Langkah 2: Membuat proyek
Mulai IntelliJ IDEA.
Pada menu utama, klik File > Baru > Proyek.
Beri proyek Anda beberapa Nama yang bermakna.
Untuk Lokasi, klik ikon folder, dan selesaikan petunjuk arah di layar untuk menentukan jalur ke proyek Scala baru Anda.
Untuk Bahasa, klik Scala.
Untuk Build system, klik sbt.
Dalam daftar drop-down JDK, pilih penginstalan JDK yang ada pada komputer pengembangan Anda yang cocok dengan versi JDK pada kluster Anda, atau pilih Unduh JDK dan ikuti instruksi di layar untuk mengunduh JDK yang cocok dengan versi JDK pada kluster Anda. Lihat Persyaratan.
Nota
Memilih penginstalan JDK yang berada di atas atau di bawah versi JDK pada kluster Anda mungkin menghasilkan hasil yang tidak terduga, atau kode Anda mungkin tidak berjalan sama sekali.
Di menu tarik-turun sbt, pilih versi terbaru.
Pada daftar drop-down Scala, pilih versi Scala yang cocok dengan versi Scala di kluster Anda. Lihat Persyaratan.
Nota
Memilih versi Scala yang berada di bawah atau di atas versi Scala pada kluster Anda mungkin menghasilkan hasil yang tidak terduga, atau kode Anda mungkin tidak berjalan sama sekali.
Pastikan kotak Unduh sumber di samping Scala dicentang.
Untuk Awalan paket, masukkan beberapa nilai awalan paket untuk sumber proyek Anda, misalnya
org.example.application.Pastikan kotak Tambahkan kode sampel dicentang.
Klik Buat.
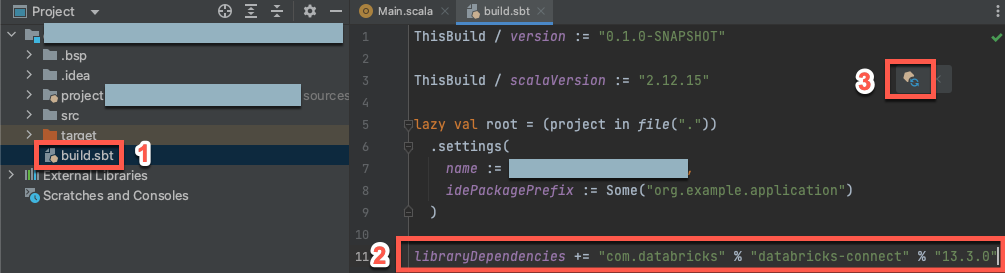
Langkah 3: Tambahkan paket Databricks Connect
Dengan proyek Scala baru Anda terbuka, di jendela alat
Proyek Anda (LihatJendela Alat Proyek ), buka file yang bernama , di dalam nama-proyek target. Tambahkan kode berikut ke akhir
build.sbtfile, yang menyatakan dependensi proyek Anda pada versi tertentu dari pustaka Databricks Connect untuk Scala, kompatibel dengan versi Databricks Runtime kluster Anda:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"Ganti
17.3dengan versi pustaka Databricks Connect yang cocok dengan versi Databricks Runtime pada kluster Anda. Misalnya, Databricks Connect 17.3.+ cocok dengan Databricks Runtime 17.3 LTS. Anda dapat menemukan nomor versi pustaka Databricks Connect di repositori pusat Maven (untuk Databricks Runtime 16.4 LTS dan di bawahnya) atau repositori pusat Maven (untuk Databricks Runtime 17.0 ke atas).Nota
Saat membangun dengan Databricks Connect, jangan sertakan artefak Apache Spark seperti
org.apache.spark:spark-coredalam proyek Anda. Sebagai gantinya, kompilasi langsung terhadap Databricks Connect.Klik ikon pemberitahuan Muat perubahan sbt untuk memperbarui proyek Scala Anda ke lokasi dan dependensi pustaka baru.
Tunggu hingga indikator kemajuan
sbtdi bagian bawah IDE menghilang. Prosessbtpemuatan mungkin perlu waktu beberapa menit untuk diselesaikan.
Langkah 4: Tambahkan kode
Di jendela alat Proyek Anda, buka file bernama , di
Main.scala.Ganti kode yang ada dalam file dengan kode berikut lalu simpan file, tergantung pada nama profil konfigurasi Anda.
Jika profil konfigurasi Anda dari Langkah 1 diberi nama
DEFAULT, ganti kode yang ada dalam file dengan kode berikut, lalu simpan file:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Jika profil konfigurasi Anda dari Langkah 1 tidak bernama
DEFAULT, ganti kode yang ada dalam file dengan kode berikut sebagai gantinya. Ganti tempat penampung<profile-name>dengan nama profil konfigurasi Anda dari Langkah 1, lalu simpan file:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Langkah 5: Mengonfigurasi opsi VM
Imporlah direktori saat ini di IntelliJ Anda di mana
build.sbtberada.Pilih Java 17 di IntelliJ. Buka File>Project Structure>SDK.
Buka
src/main/scala/com/examples/Main.scala.Navigasikan ke konfigurasi untuk Main untuk menambahkan opsi VM:
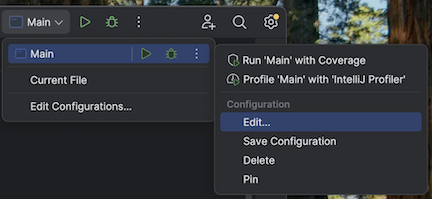
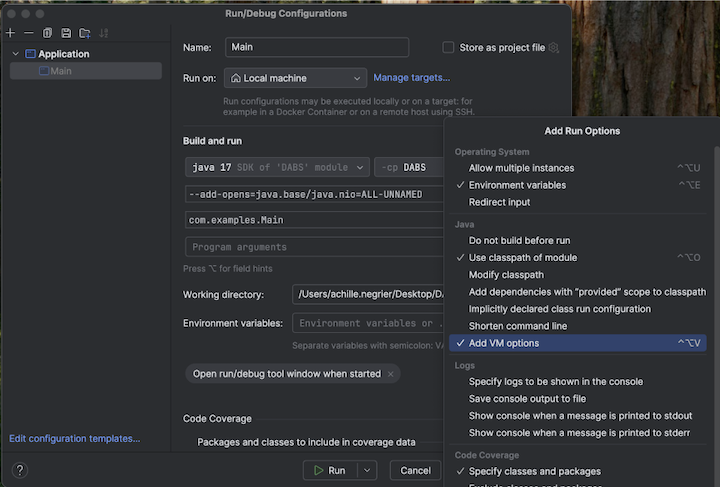
Tambahkan yang berikut ini ke opsi VM Anda:
--add-opens=java.base/java.nio=ALL-UNNAMED
Petunjuk / Saran
Atau, atau jika Anda menggunakan Visual Studio Code, tambahkan yang berikut ini ke file build sbt Anda:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Kemudian jalankan aplikasi Anda dari terminal:
sbt run
Langkah 6: Jalankan kode
- Mulai kluster target di ruang kerja Azure Databricks jarak jauh Anda.
- Setelah kluster dimulai, pada menu utama, klik Jalankan 'Main'>.
- Di jendela alat Jalankan (Tampilkan > Jendela Alat > Jalankan), pada tab Utama, 5 baris pertama tabel
samples.nyctaxi.tripsmuncul.
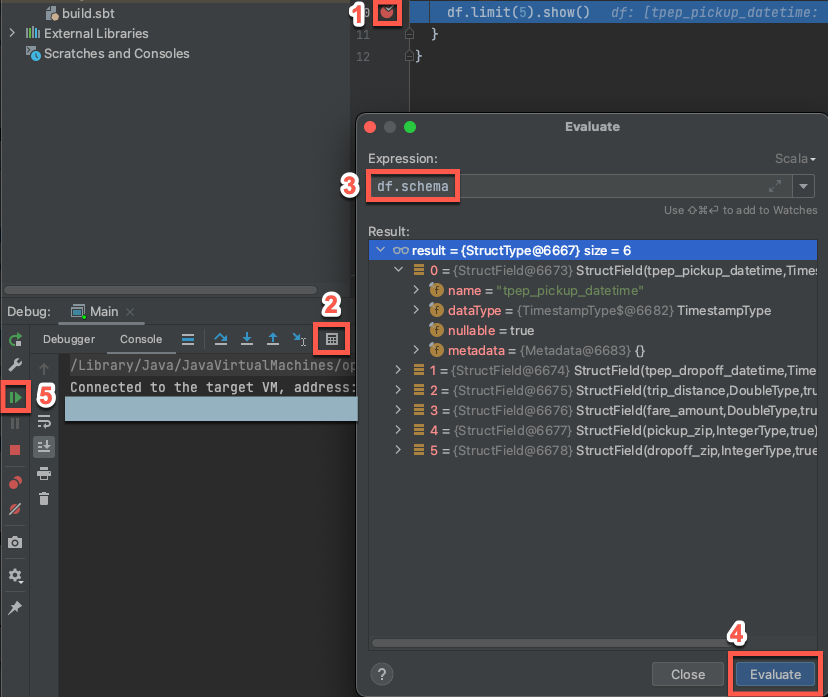
Langkah 7: Debug kode
Dengan kluster target yang masih berjalan, dalam kode sebelumnya, klik pada gutter di sebelah
df.limit(5).show()untuk mengatur titik henti.Pada menu utama, klik Jalankan > Debug 'Main'. Di jendela alat Debug (Lihat > Alat Windows > Debug), pada tab Konsol , klik ikon kalkulator (Evaluasi Ekspresi).
Masukkan ekspresi
df.schema.Klik Evaluasi untuk memperlihatkan skema DataFrame.
Di bilah samping jendela alat Debug , klik ikon panah hijau (Lanjutkan Program). Baris pertama sebanyak 5 dari tabel
samples.nyctaxi.tripsmuncul di panel Konsol.