Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini memandu Anda menggunakan notebook Azure Databricks untuk mengimpor data dari file CSV yang berisi data nama bayi dari health.data.ny.gov ke volume Unity Catalog Anda menggunakan Python, Scala, dan R. Anda juga belajar mengubah nama kolom, memvisualisasikan data, dan menyimpan ke tabel.
Nota
Jika Anda menggunakan Databricks Edisi Gratis, pilih tab Python untuk semua contoh kode dalam tutorial ini. Edisi Gratis tidak mendukung R atau Scala. Selain itu, Edisi Gratis membatasi akses internet keluar, jadi Anda harus mengunggah file CSV menggunakan UI ruang kerja alih-alih mengunduhnya dengan kode. Lihat Langkah 3 untuk instruksi terperinci.
Persyaratan
Untuk menyelesaikan tugas dalam artikel ini, Anda harus memenuhi persyaratan berikut:
- Ruang kerja Anda harus mengaktifkan Unity Catalog. Untuk informasi tentang mulai menggunakan Katalog Unity, lihat Mulai menggunakan Katalog Unity. Azure Databricks Edisi Gratis dan ruang kerja uji coba gratis memiliki Unity Catalog yang diaktifkan secara default.
- Anda harus memiliki hak istimewa
WRITE VOLUMEpada volume, hak istimewaUSE SCHEMApada skema induk, dan hak istimewaUSE CATALOGpada katalog induk. Pengguna Edisi Gratis memiliki hak istimewa ini pada katalog dandefaultskema ruang kerja secara default. - Anda harus memiliki izin untuk menggunakan sumber daya komputasi yang sudah ada atau membuat sumber daya komputasi baru. Lihat Compute atau hubungi administrator Azure Databricks Anda.
Petunjuk / Saran
Untuk buku catatan lengkap untuk artikel ini, lihat Mengimpor dan memvisualisasikan buku catatan data.
Langkah 1: Membuat buku catatan baru
Untuk membuat buku catatan di ruang kerja Anda, klik ![]() Baru di bilah samping, lalu klik Buku Catatan. Buku catatan kosong terbuka di ruang kerja.
Baru di bilah samping, lalu klik Buku Catatan. Buku catatan kosong terbuka di ruang kerja.
Untuk mempelajari selengkapnya tentang membuat dan mengelola buku catatan, lihat Mengelola buku catatan.
Langkah 2: Tentukan variabel
Dalam langkah ini, Anda menentukan variabel untuk digunakan dalam contoh buku catatan yang Anda buat di artikel ini. Anda memerlukan nama katalog, skema, dan volume dari Unity Catalog.
Petunjuk / Saran
Jika Anda tidak mengetahui nama katalog dan skema Anda, klik ![]() Katalog di bilah samping. Katalog ruang kerja memiliki nama yang sama dengan ruang kerja Anda dan tercantum di panel katalog. Perluas untuk melihat skema yang tersedia. Pengguna Edisi Gratis dan uji coba gratis dapat menggunakan katalog ruang kerja dan
Katalog di bilah samping. Katalog ruang kerja memiliki nama yang sama dengan ruang kerja Anda dan tercantum di panel katalog. Perluas untuk melihat skema yang tersedia. Pengguna Edisi Gratis dan uji coba gratis dapat menggunakan katalog ruang kerja dan default skema.
Jika Anda tidak memiliki volume, buat dengan menjalankan perintah berikut ini di sel buku catatan (ganti <catalog_name> dan <schema_name> dengan nilai Anda):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Salin dan tempel kode berikut ke dalam sel buku catatan kosong baru. Ganti
<catalog-name>,<schema-name>, dan<volume-name>dengan katalog, skema, dan nama volume untuk volume Katalog Unity. Secara opsional ganti nilaitable_namedengan nama tabel pilihan Anda. Anda menyimpan data nama bayi ke dalam tabel ini nanti di artikel ini.Tekan
Shift+Enteruntuk menjalankan sel dan buat sel kosong baru.Phyton
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Langkah 3: Impor file CSV
Dalam langkah ini, Anda mengimpor file CSV yang berisi data nama bayi dari health.data.ny.gov ke dalam volume Katalog Unity Anda. Pilih salah satu metode berikut:
- Unggah menggunakan UI ruang kerja — Gunakan metode ini jika Anda berada di Databricks Free Edition, atau jika pengunduhan kode dalam opsi B gagal dengan kesalahan jaringan. Edisi Gratis dan lingkungan komputasi tanpa server lainnya membatasi akses internet keluar, jadi Anda harus mengunggah file dari komputer lokal Anda.
- Unduh menggunakan kode — Gunakan metode ini jika lingkungan komputasi Anda memiliki akses internet keluar.
Opsi A: Unggah menggunakan UI ruang kerja
- Di komputer lokal Anda, buka health.data.ny.gov/api/views/jxy9-yhdk/rows.csv di browser Anda. File diunduh ke komputer Anda sebagai
rows.csv. - Temukan file yang diunduh di komputer Anda dan ganti namanya dari
rows.csvmenjadibaby_names.csv. Ini cocok dengan variabel yangfile_nameAnda tentukan di Langkah 2. - Kembali ke ruang kerja Azure Databricks Anda. Di bar samping, klik
 > Tambahkan atau unggah data Baru.
> Tambahkan atau unggah data Baru. - Klik Unggah file ke volume.
- Klik telusuri dan pilih
baby_names.csvfile, atau seret dan letakkan ke area unggahan. - Di bawah Volume tujuan, pilih volume yang Anda tentukan di Langkah 2.
- Setelah unggahan selesai, kembali ke buku catatan Anda dan lanjutkan dengan Langkah 4.
Untuk detail selengkapnya tentang mengunggah file, lihat Bekerja dengan file di volume Katalog Unity.
Opsi B: Unduh menggunakan kode
Salin dan tempel kode berikut ke dalam sel buku catatan kosong baru. Kode ini menyalin
rows.csvfile dari health.data.ny.gov ke volume Unity Catalog Anda menggunakan perintah Databricks dbutils.Tekan
Shift+Enteruntuk menjalankan sel lalu berpindah ke sel berikutnya.Phyton
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Langkah 4: Muat data CSV ke dalam DataFrame
Dalam langkah ini, Anda membuat DataFrame bernama df dari file CSV yang sebelumnya Anda muat ke dalam volume Unity Catalog Anda dengan menggunakan metode spark.read.csv.
Salin dan tempel kode berikut ke dalam sel buku catatan kosong baru. Kode ini memuat data nama bayi ke dalam DataFrame
dfdari file CSV.Tekan
Shift+Enteruntuk menjalankan sel lalu berpindah ke sel berikutnya.Phyton
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Anda dapat memuat data dari banyak format file yang didukung.
Langkah 5: Memvisualisasikan data dari buku catatan
Dalam langkah ini, Anda menggunakan metode display() untuk menampilkan konten DataFrame dalam tabel di buku catatan, lalu memvisualisasikan data dalam bagan awan kata di buku catatan.
Salin dan tempel kode berikut ke dalam sel buku catatan kosong baru, lalu klik Jalankan sel untuk menampilkan data dalam tabel.
Phyton
display(df)Scala
display(df)R
display(df)Tinjau hasil dalam tabel.
Di samping tab Tabel
, klik lalu klik Visualisasi .Di editor visualisasi, klik Visualisasi Tipe, dan verifikasi bahwa Word cloud dipilih.
Di kolom Kata , periksa bahwa
First Namedipilih.Dalam batas frekuensi , klik
35.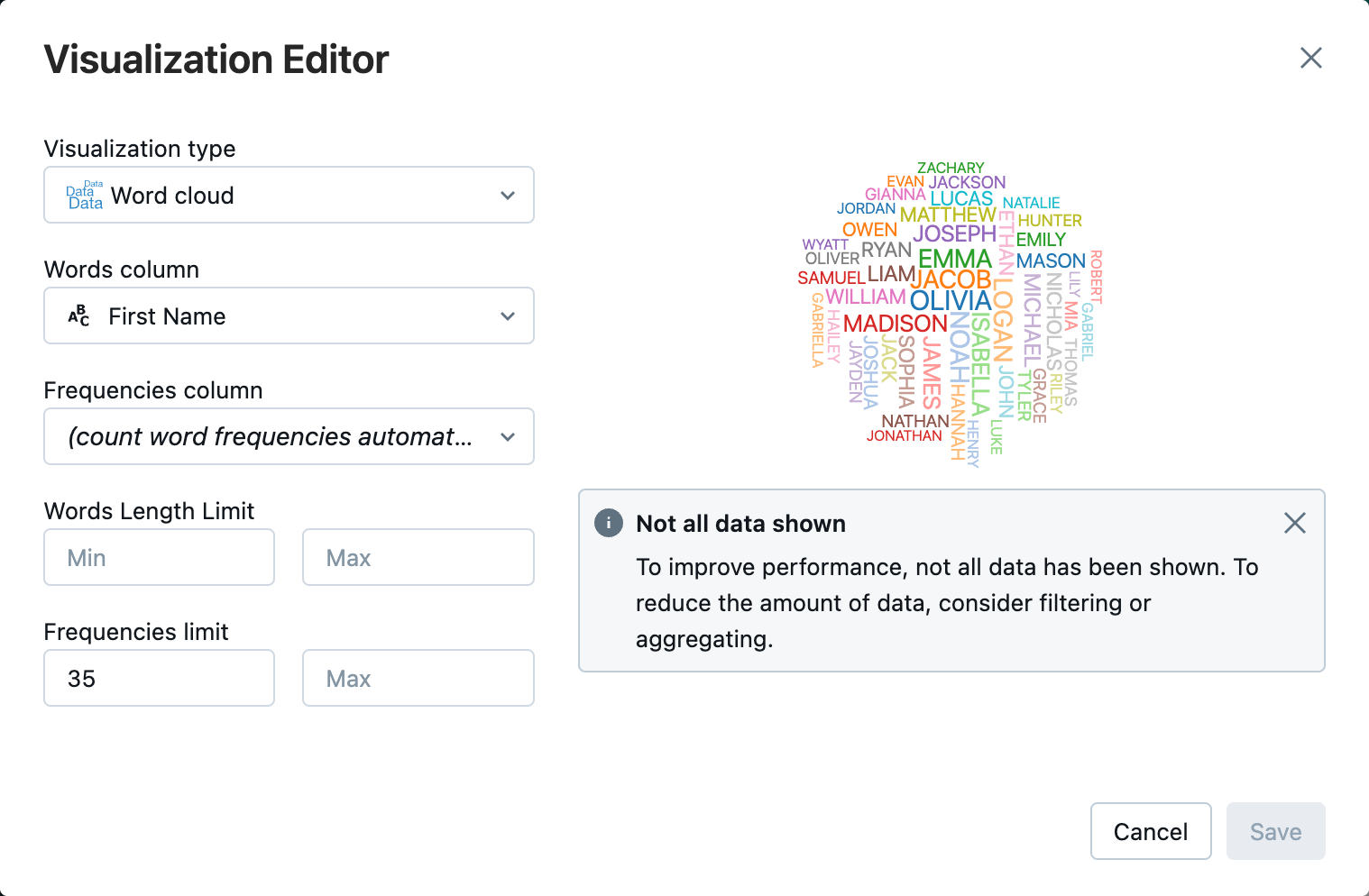
Klik Simpan.
Langkah 6: Simpan DataFrame ke tabel
Penting
Untuk menyimpan DataFrame Anda di Unity Catalog, Anda harus memiliki hak istimewa tabel CREATE pada katalog dan skema. Untuk informasi tentang izin di Unity Catalog, lihat Hak Istimewa dan Objek Terproteksi di Unity Catalog dan Mengelola Hak Istimewa di Unity Catalog.
Salin dan tempel kode berikut ke dalam sel buku catatan kosong. Kode ini menggantikan spasi dalam nama kolom. Karakter khusus, seperti spasi tidak diperbolehkan dalam nama kolom. Kode ini menggunakan metode Apache Spark
withColumnRenamed().Phyton
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Salin dan tempel kode berikut ke dalam sel buku catatan kosong. Kode ini menyimpan konten DataFrame ke tabel di Unity Catalog menggunakan variabel nama tabel yang Anda tentukan di awal artikel ini.
Phyton
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Untuk memverifikasi bahwa tabel disimpan, klik Katalog di bar samping kiri untuk membuka UI Catalog Explorer. Buka katalog Anda lalu skema Anda untuk memverifikasi bahwa tabel muncul.
Klik tabel Anda untuk melihat skema tabel pada tab Gambaran Umum
. Klik Data Sampel untuk menampilkan 100 baris data dari tabel.
Mengimpor dan memvisualisasikan buku catatan data
Gunakan salah satu buku catatan berikut untuk melakukan langkah-langkah dalam artikel ini. Ganti <catalog-name>, <schema-name>, dan <volume-name> dengan katalog, skema, dan nama volume untuk volume Katalog Unity. Secara opsional ganti nilai table_name dengan nama tabel pilihan Anda.
Phyton
Mengimpor data dari CSV menggunakan Python
Dapatkan buku catatan
Scala
Mengimpor data dari CSV menggunakan Scala
Dapatkan buku catatan
R
Mengimpor data dari CSV menggunakan R
Dapatkan buku catatan
Langkah berikutnya
- Untuk mempelajari tentang teknik analisis data eksploratif (EDA), lihat Tutorial: Teknik EDA menggunakan notebook Databricks.
- Untuk mempelajari tentang membangun alur ETL (extract, transform, dan load), lihat Tutorial: Membangun alur ETL dengan Lakeflow Spark Declarative Pipelines dan Tutorial: Membangun alur ETL dengan Apache Spark pada platform Databricks