Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Gunakan Python dalam buku catatan Azure Databricks untuk melakukan analisis data eksploratif (EDA): memuat dan membersihkan himpunan data, menjelajahi karakteristiknya, dan memvisualisasikan tren untuk menghasilkan wawasan.
Notebook yang digunakan dalam tutorial ini memeriksa data energi dan emisi global dan menunjukkan cara memuat, membersihkan, dan menjelajahi data.
Anda bisa mengikuti menggunakan contoh notebook atau membuat buku catatan Anda sendiri dari awal.
Apa itu EDA?
Analisis data eksploratif (EDA) adalah langkah awal penting dalam proses ilmu data yang melibatkan analisis dan visualisasi data untuk:
- Mengungkap karakteristik utamanya.
- Identifikasi pola dan tren.
- Mendeteksi anomali.
- Memahami hubungan antar variabel.
EDA memberikan wawasan tentang himpunan data, memfasilitasi keputusan berdasarkan informasi tentang analisis atau pemodelan statistik lebih lanjut.
Dengan buku catatan Azure Databricks, ilmuwan data dapat melakukan EDA menggunakan alat yang sudah dikenal. Misalnya, tutorial ini menggunakan beberapa pustaka Python umum untuk menangani dan memplot data, termasuk:
- Numpy: pustaka dasar untuk komputasi numerik, memberikan dukungan untuk array, matriks, dan berbagai fungsi matematika untuk beroperasi pada struktur data ini.
- pandas: pustaka manipulasi dan analisis data yang kuat, dibangun di atas NumPy, yang menawarkan struktur data seperti DataFrame untuk menangani data terstruktur secara efisien.
- Plotly: pustaka grafik interaktif yang memungkinkan pembuatan visualisasi interaktif berkualitas tinggi untuk analisis dan presentasi data.
- Matplotlib: pustaka komprehensif untuk membuat visualisasi statis, animasi, dan interaktif di Python.
Azure Databricks juga menyediakan fitur bawaan untuk membantu Anda menjelajahi data Anda dalam output buku catatan, seperti memfilter dan mencari data dalam tabel, dan memperbesar visualisasi. Anda juga dapat menggunakan Kode Genie untuk membantu Anda menulis kode untuk EDA.
Sebelum Anda mulai
Untuk menyelesaikan tutorial ini, Anda memerlukan hal berikut:
- Anda harus memiliki izin untuk menggunakan sumber daya komputasi yang sudah ada atau membuat sumber daya komputasi baru. Lihat Komputasi.
- [Opsional] Tutorial ini menjelaskan cara menggunakan Kode Genie untuk membantu Anda menghasilkan kode. Lihat Menggunakan Kode Genie untuk informasi selengkapnya.
Mengunduh himpunan data dan mengimpor file CSV
Tutorial ini menunjukkan teknik EDA dengan memeriksa data energi dan emisi global. Untuk mengikutinya, unduh Himpunan Data Konsumsi Energi oleh Our World in Data dari Kaggle. Tutorial ini menggunakan file owid-energy-data.csv.
Untuk mengimpor himpunan data ke ruang kerja Azure Databricks Anda:
Di bilah samping ruang kerja, klik Workspace untuk menavigasi ke browser ruang kerja.
Seret dan letakkan file CSV,
owid-energy-data.csv, ke ruang kerja Anda.Ini membuka modal Impor. Perhatikan folder target yang tercantum di sini. Ini diatur ke folder Anda saat ini di browser ruang kerja dan menjadi tujuan file yang diimpor.
Klik Impor. File akan muncul di folder target di ruang kerja Anda.
Anda memerlukan jalur file untuk memuat file ke buku catatan Anda nanti. Temukan file di browser ruang kerja Anda. Untuk menyalin jalur file ke clipboard Anda, klik kanan pada nama file, lalu pilih Salin URL/jalur>Jalur lengkap.
Membuat buku catatan baru
Untuk membuat buku catatan baru di folder beranda pengguna Anda, klik ![]() Baru di bilah samping dan pilih Notebook dari menu.
Baru di bilah samping dan pilih Notebook dari menu.
Di bagian atas, di samping nama buku catatan, pilih Python sebagai bahasa default untuk buku catatan.
Untuk mempelajari selengkapnya tentang membuat dan mengelola buku catatan, lihat Mengelola buku catatan.
Tambahkan setiap sampel kode dalam artikel ini ke sel baru di buku catatan Anda. Atau, gunakan notebook contoh yang disediakan untuk mengikuti tutorial.
Muat file CSV
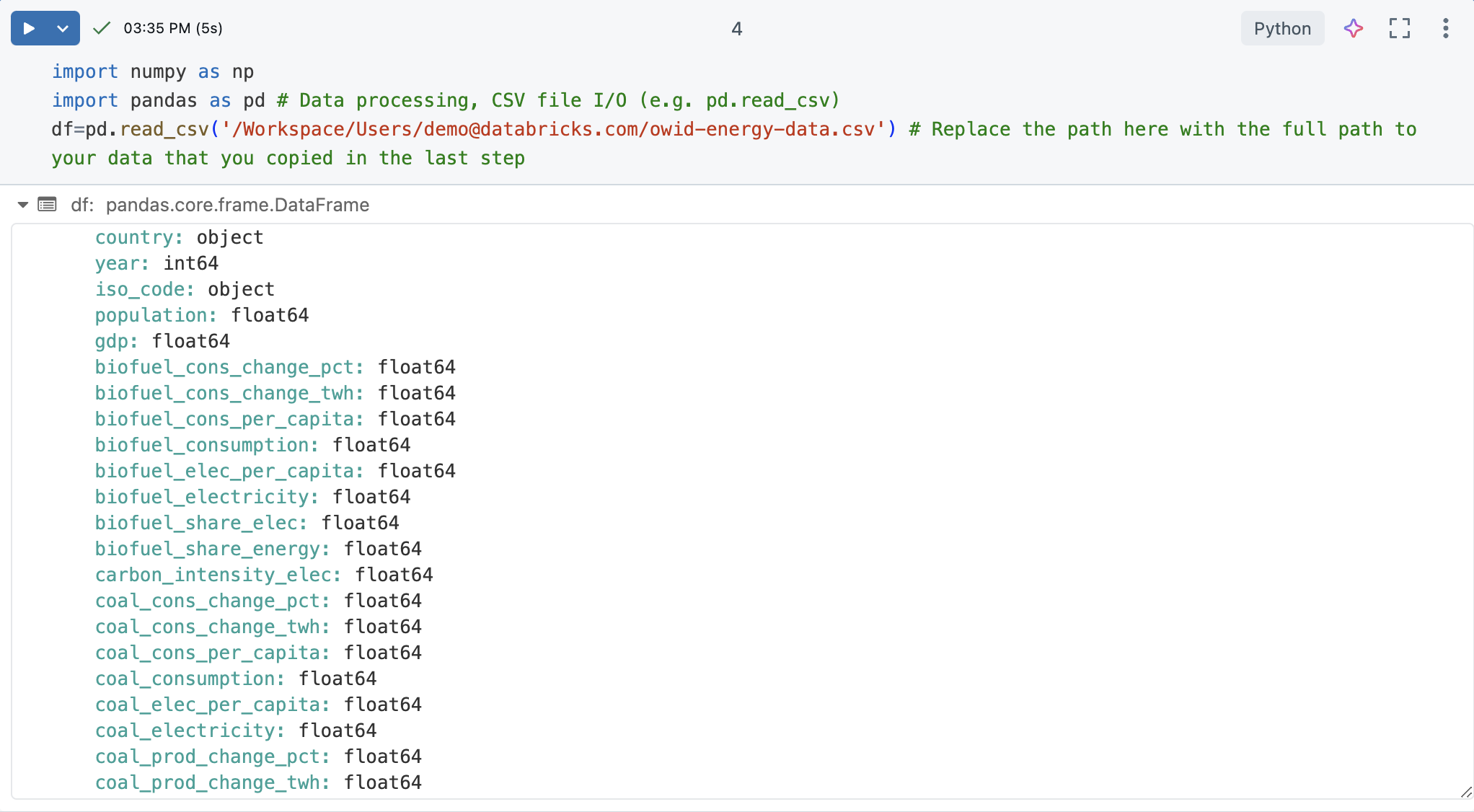
Di sel buku catatan baru, muat file CSV. Untuk melakukan ini, impor numpy dan pandas. Ini adalah pustaka Python yang berguna untuk ilmu dan analisis data.
Buat Pandas DataFrame dari himpunan data untuk pemrosesan dan visualisasi yang lebih mudah. Ganti jalur file di bawah ini dengan jalur yang Anda salin sebelumnya.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
Jalankan sel. Output harus mengembalikan Pandas DataFrame, termasuk daftar setiap kolom dan jenisnya.
Memahami data
Memahami dasar-dasar himpunan data sangat penting untuk setiap proyek ilmu data. Ini melibatkan membiasakan diri dengan struktur, jenis, dan kualitas data yang ada.
Di buku catatan Azure Databricks, Anda bisa menggunakan perintah display(df) untuk menampilkan himpunan data.
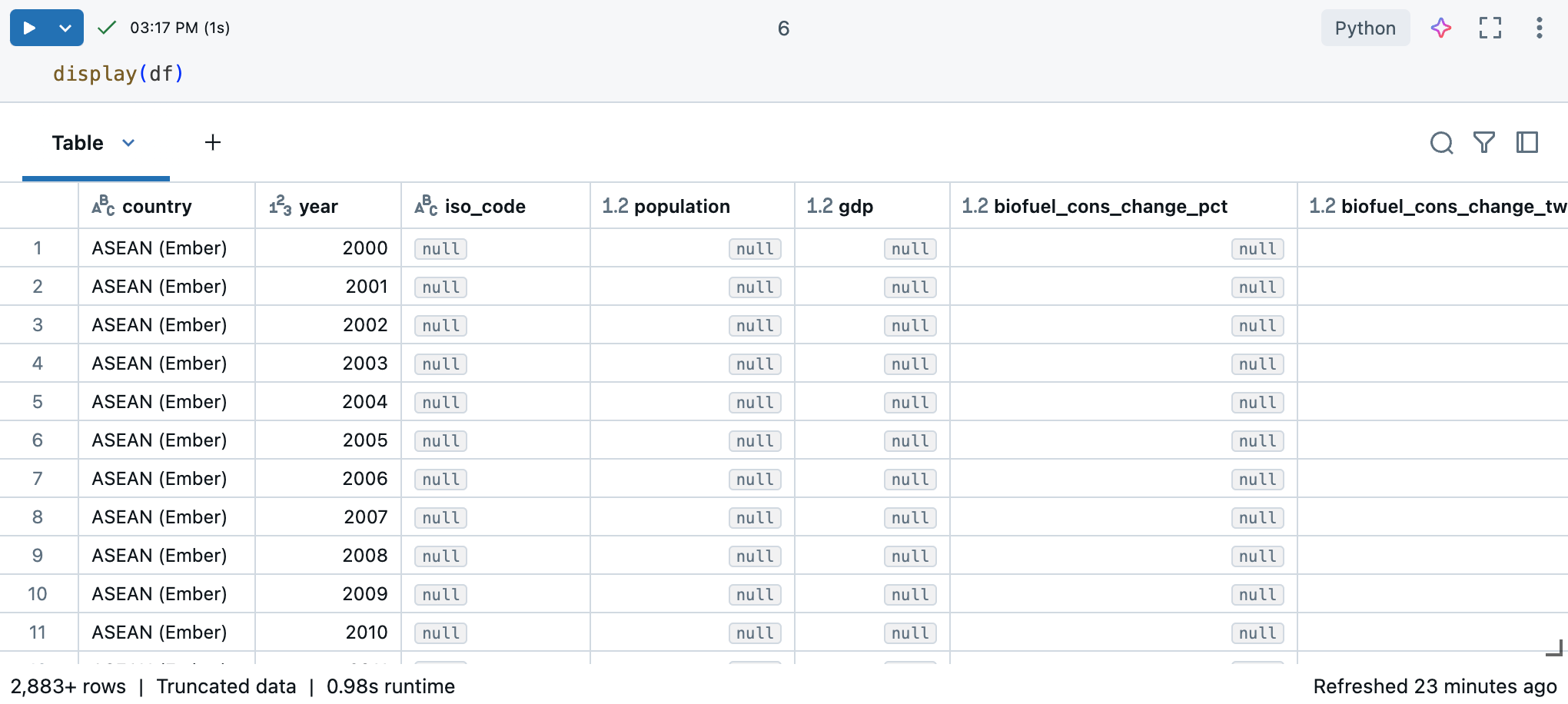
Karena himpunan data memiliki lebih dari 10.000 baris, perintah ini mengembalikan himpunan data yang dipotong. Di sebelah kiri setiap kolom, Anda bisa melihat jenis data kolom. Untuk mempelajari selengkapnya, lihat kolom Format .
Gunakan Pandas untuk wawasan data
Untuk memahami himpunan data Anda secara efektif, gunakan perintah panda berikut:
Perintah
df.shapemengembalikan dimensi DataFrame, memberi Anda gambaran umum singkat tentang jumlah baris dan kolom.
Perintah
df.dtypesmenyediakan jenis data setiap kolom, membantu Anda memahami jenis data yang sedang Anda hadapi. Anda juga dapat melihat jenis data untuk setiap kolom dalam tabel hasil.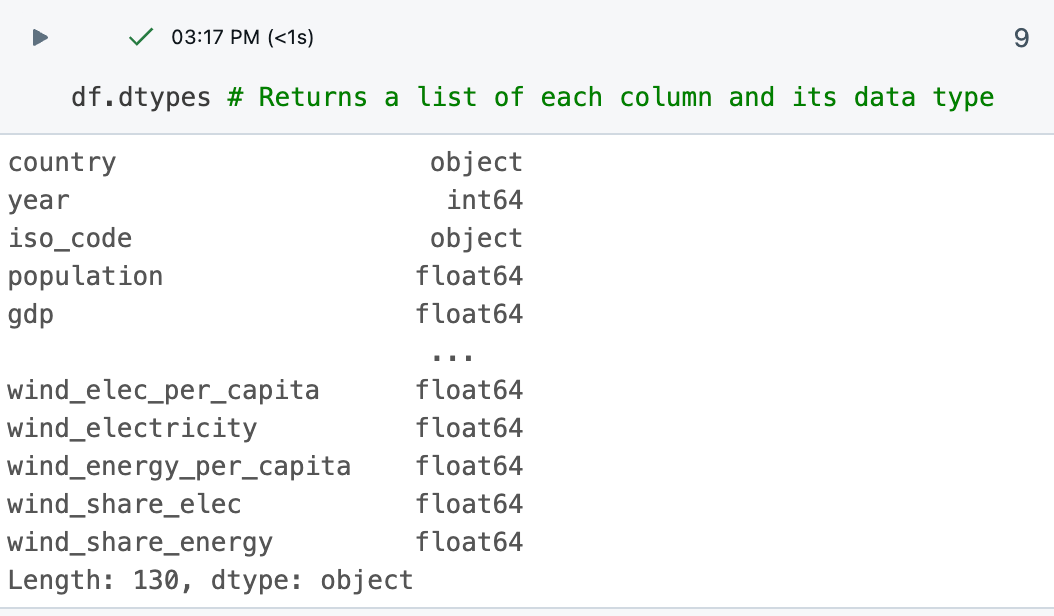
Perintah
df.describe()menghasilkan statistik deskriptif untuk kolom numerik, seperti rata-rata, simpangan baku, dan persentil, yang dapat membantu Anda mengidentifikasi pola, mendeteksi anomali, dan memahami distribusi data Anda. Gunakan dengandisplay()untuk melihat statistik ringkasan dalam format tabel yang dapat Anda gunakan untuk berinteraksi. Lihat Menjelajahi data menggunakan tabel output buku catatan Databricks.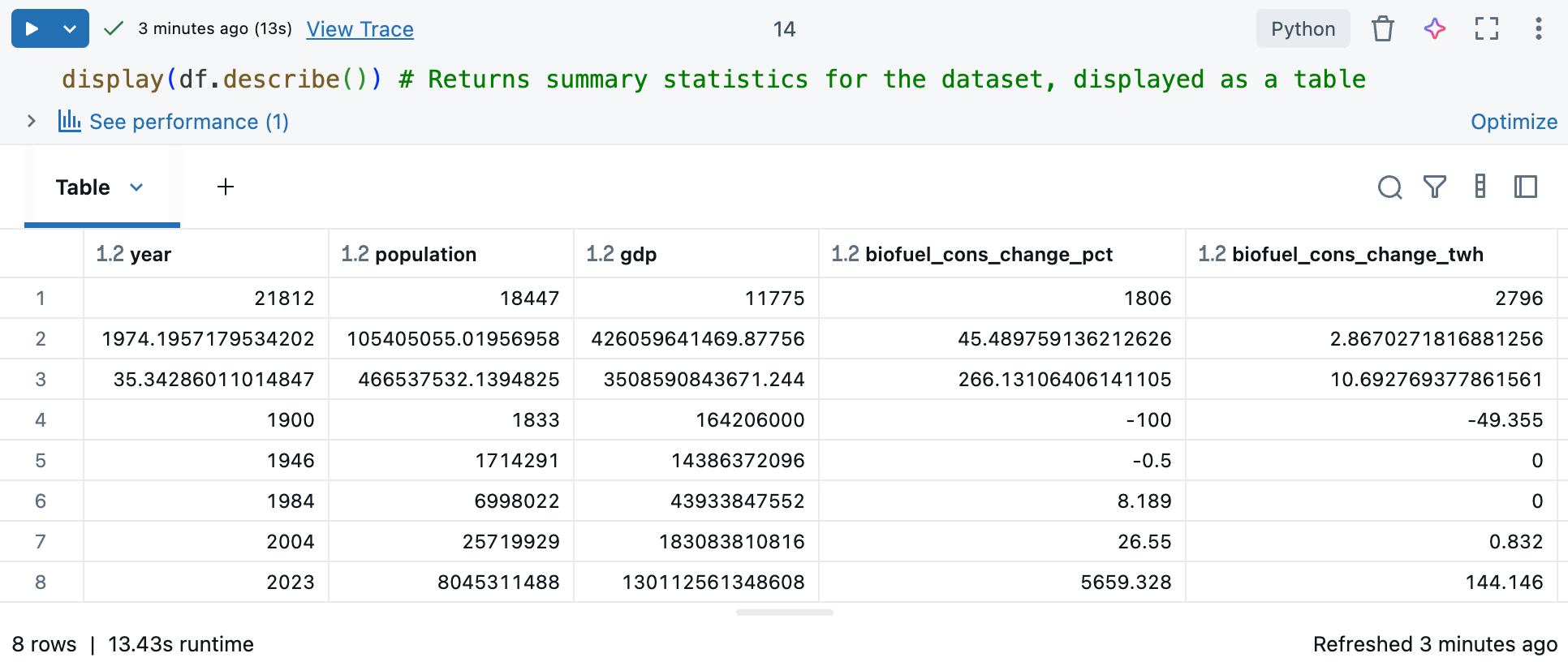
Membuat profil data
Nota
Tersedia di Databricks Runtime 9.1 LTS ke atas.
Azure Databricks notebook menyertakan kemampuan pembuatan profil data bawaan. Saat melihat DataFrame dengan fungsi tampilan Azure Databricks, Anda dapat membuat profil data dari output tabel.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
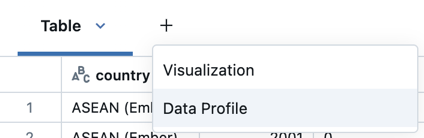
Klik +>Profil Data di samping Tabel dalam output. Ini menjalankan perintah baru yang menghasilkan profil data di DataFrame.
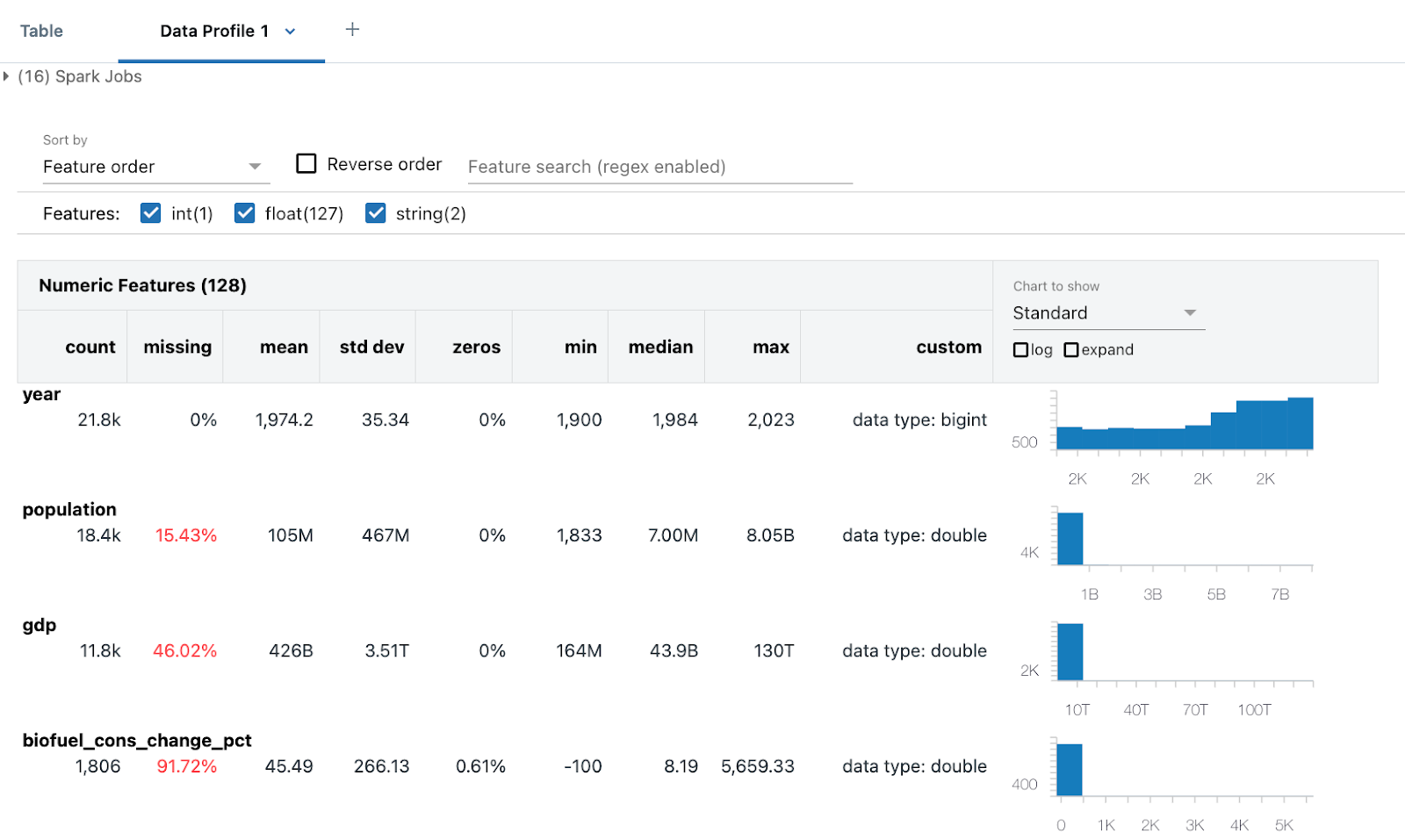
Profil data mencakup statistik ringkasan untuk kolom numerik, string, dan tanggal serta histogram distribusi nilai untuk setiap kolom. Anda juga dapat membuat profil data secara terprogram; lihat meringkas perintah (dbutils.data.summarize).
Bersihkan data
Membersihkan data adalah langkah penting dalam EDA untuk memastikan himpunan data akurat, konsisten, dan siap untuk analisis yang bermakna. Proses ini melibatkan beberapa tugas utama untuk memastikan data siap untuk analisis, termasuk:
- Mengidentifikasi dan menghapus data duplikat apa pun.
- Menangani nilai yang hilang, yang mungkin melibatkan menggantinya dengan nilai tertentu atau menghapus baris yang terpengaruh.
- Menstandarkan jenis data (misalnya, mengonversi string menjadi
datetime) melalui konversi dan transformasi untuk memastikan konsistensi. Anda mungkin juga ingin mengonversi data ke format yang lebih mudah untuk Anda kerjakan.
Fase pembersihan ini sangat penting karena meningkatkan kualitas dan keandalan data, memungkinkan analisis yang lebih akurat dan berwawasan.
Tips: Gunakan Kode Genie untuk membantu tugas pembersihan data
Anda dapat menggunakan Genie Code untuk membantu Anda menghasilkan kode. Buat sel kode baru dan klik tautan hasilkan atau gunakan ikon Kode Genie di kanan atas untuk membuka Kode Genie. Masukkan kueri untuk Kode Genie. Kode Genie dapat menghasilkan kode Python atau SQL atau menghasilkan deskripsi teks. Untuk hasil yang berbeda, klik Regenerasi.
Misalnya, coba perintah berikut untuk menggunakan Kode Genie untuk membantu Anda membersihkan data:
- Periksa apakah
dfberisi kolom atau baris duplikat. Cetak duplikat. Kemudian, hapus duplikat. - Dalam format apa kolom tanggal? Ubah menjadi
'YYYY-MM-DD'. - Aku tidak akan menggunakan kolom
XXX. Hapus itu.
Lihat Mendapatkan bantuan pengkodean dari Genie Code.
Menghapus data duplikat
Periksa apakah data memiliki baris atau kolom duplikat. Jika demikian, hapus.
Saran
Gunakan Kode Genie untuk menghasilkan kode untuk Anda.
Coba masukkan perintah: "Periksa apakah df berisi kolom atau baris duplikat. Cetak duplikat. Kemudian, hapus duplikat." Kode Genie mungkin menghasilkan kode seperti sampel di bawah ini.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
Dalam hal ini, himpunan data tidak memiliki data duplikat.
Menangani data null atau nilai yang hilang
Cara umum untuk memperlakukan nilai NaN atau Null adalah dengan menggantinya dengan 0 untuk pemrosesan matematika yang lebih mudah.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Ini memastikan bahwa setiap data yang hilang di DataFrame diganti dengan 0, yang dapat berguna untuk analisis data berikutnya atau langkah-langkah pemrosesan di mana nilai yang hilang dapat menyebabkan masalah.
Format ulang tanggal
Tanggal sering diformat dengan berbagai cara dalam himpunan data yang berbeda. Nilai mungkin dalam format tanggal, string, atau bilangan bulat.
Untuk analisis ini, perlakukan kolom year sebagai bilangan bulat. Kode berikut adalah salah satu cara untuk melakukan ini:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Ini memastikan bahwa kolom year hanya berisi nilai tahun bilangan bulat, dan mengonversi entri yang tidak valid ke NaT (Bukan Waktu).
Menjelajahi data menggunakan tabel output buku catatan Databricks
Azure Databricks menyediakan fitur bawaan untuk membantu Anda menjelajahi data menggunakan tabel output.
Di sel baru, gunakan display(df) untuk menampilkan himpunan data sebagai tabel.
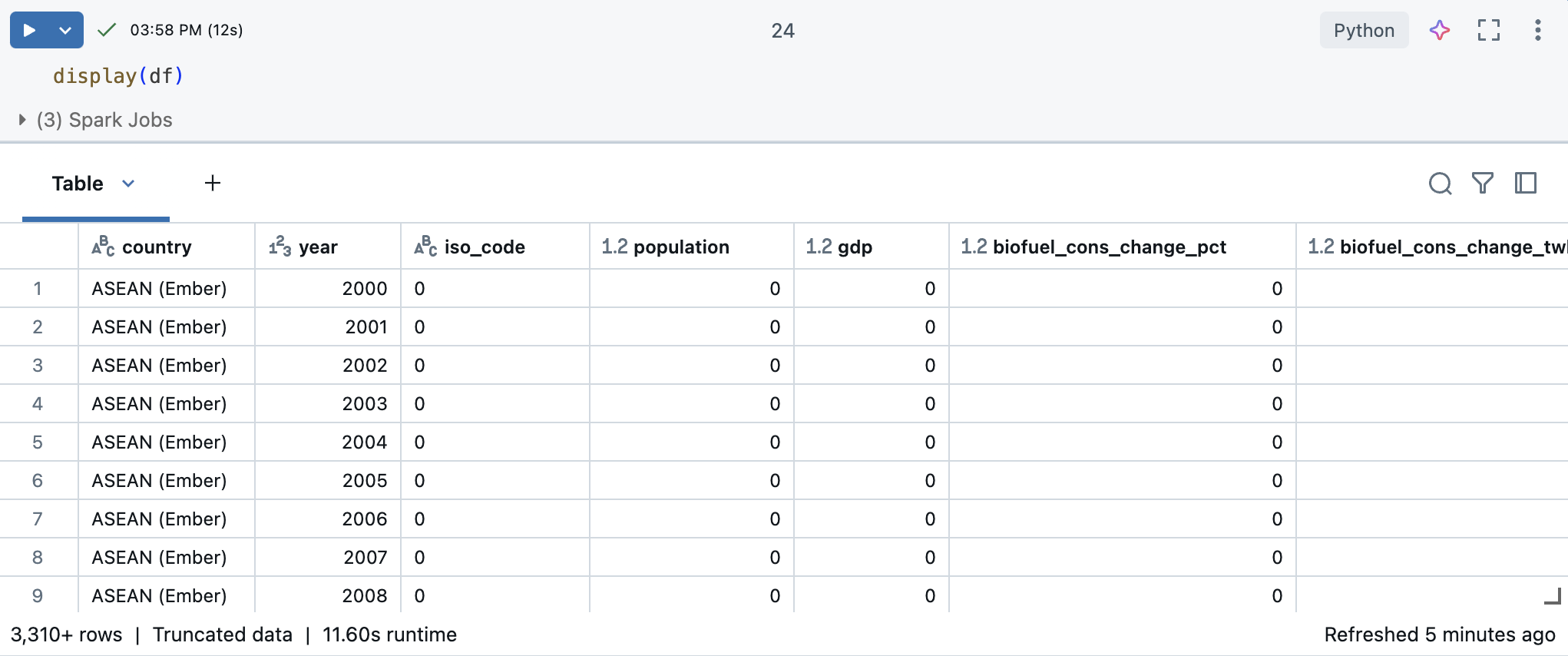
Dengan menggunakan tabel output, Anda dapat menjelajahi data dengan beberapa cara:
- Mencari data untuk string atau nilai tertentu
- Filter untuk kondisi tertentu
- Membuat visualisasi menggunakan himpunan data
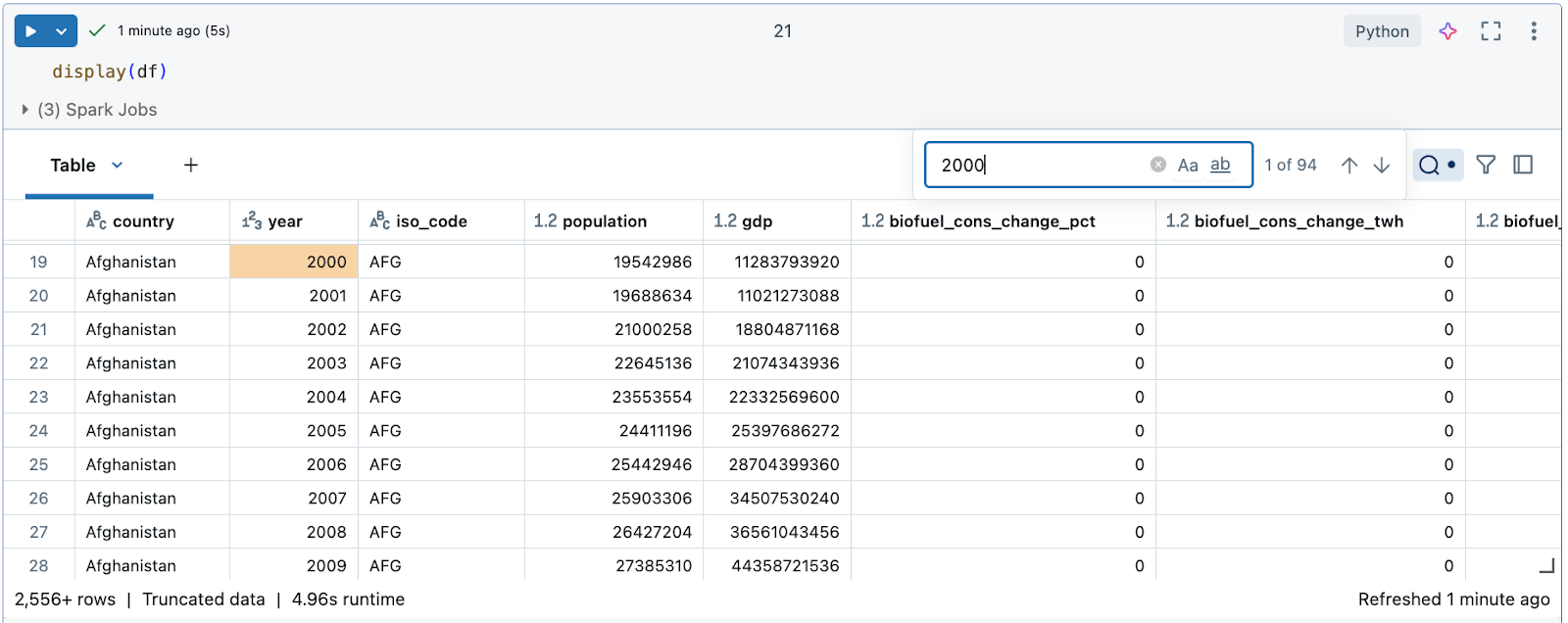
Mencari data untuk string atau nilai tertentu
Klik ikon pencarian di kanan atas tabel dan masukkan pencarian Anda.
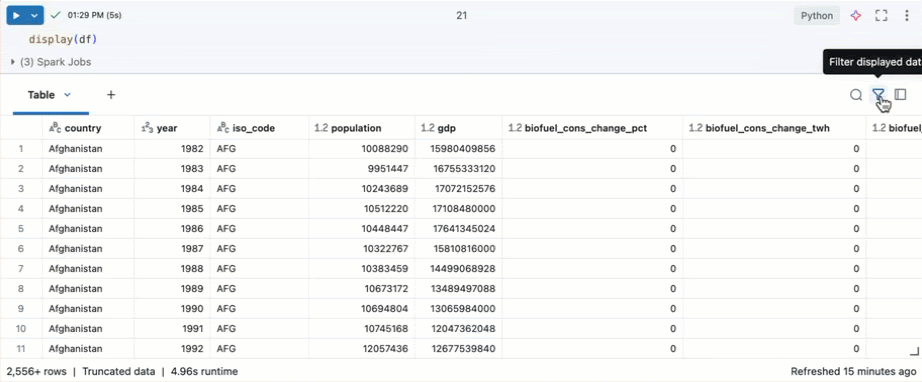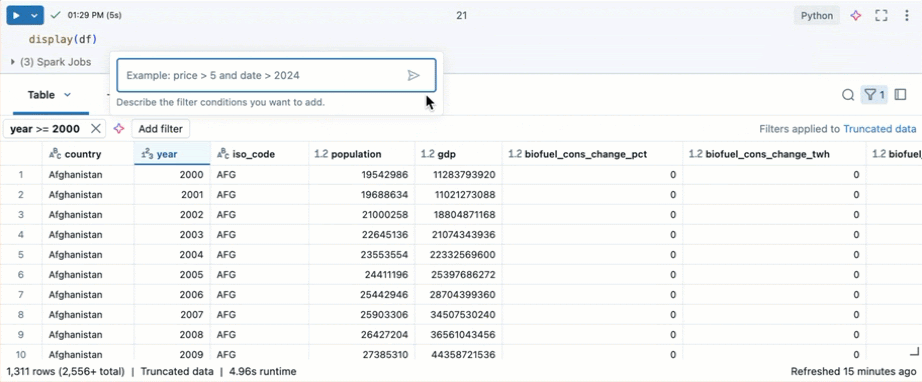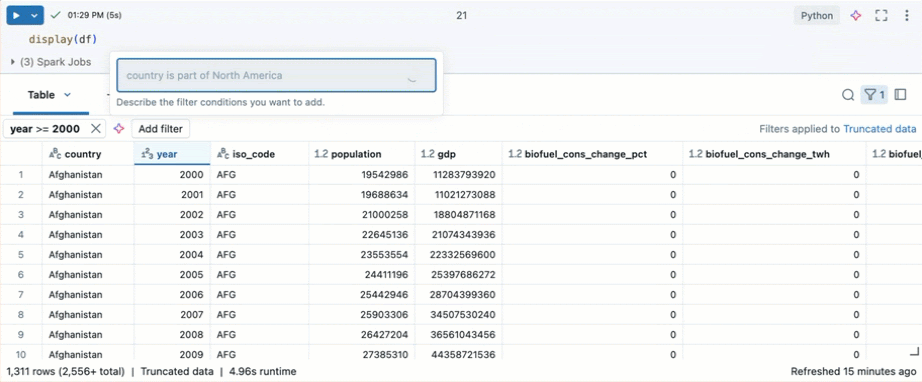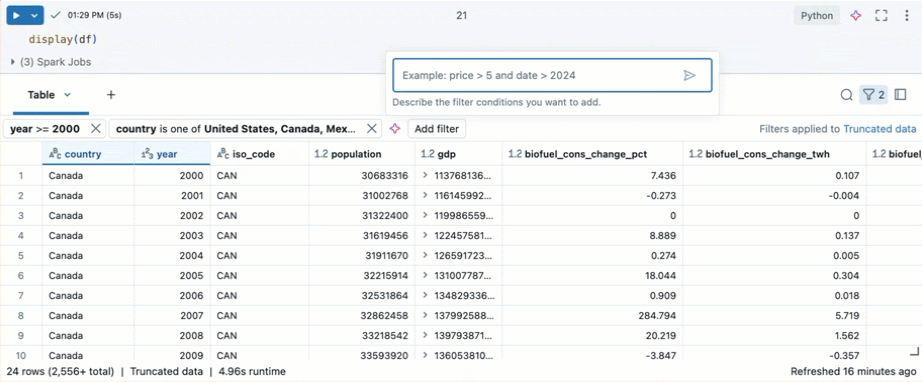
Filter untuk kondisi tertentu
Anda bisa menggunakan filter tabel bawaan untuk memfilter kolom Anda untuk kondisi tertentu. Ada beberapa cara untuk membuat filter. Lihat Hasil Filter.
Saran
Gunakan Kode Genie untuk membuat filter. Klik ikon filter di sudut kanan atas tabel. Masukkan kondisi filter Anda. Genie Code secara otomatis menghasilkan filter untuk Anda.
Membuat visualisasi menggunakan himpunan data
Di bagian atas tabel output, klik +>Visualisasi untuk membuka editor visualisasi.
Pilih jenis visualisasi dan kolom yang ingin Anda visualisasikan. Pengedit menampilkan pratinjau bagan berdasarkan pada konfigurasi Anda. Misalnya, gambar di bawah ini menunjukkan cara menambahkan beberapa bagan garis untuk melihat konsumsi berbagai sumber energi terbarukan dari waktu ke waktu.
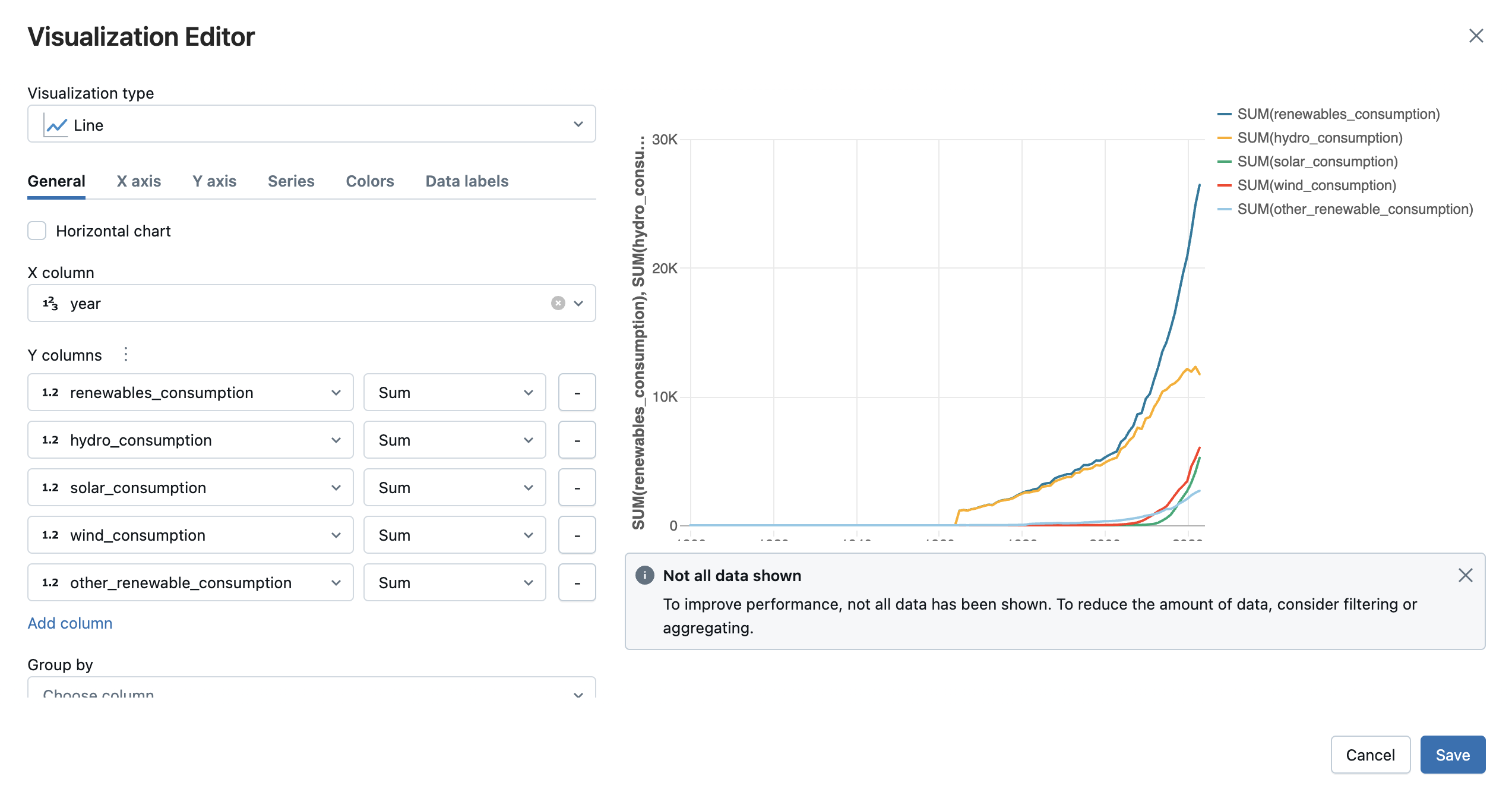
Klik Simpan untuk menambahkan visualisasi sebagai tab dalam output sel.
Lihat Buat visualisasi baru.
Menjelajahi dan memvisualisasikan data menggunakan pustaka Python
Menjelajahi data menggunakan visualisasi adalah aspek mendasar dari EDA. Visualisasi membantu mengungkap pola, tren, dan hubungan dalam data yang mungkin tidak segera terlihat melalui analisis numerik saja. Gunakan pustaka seperti Plotly atau Matplotlib untuk teknik visualisasi umum termasuk plot sebar, bagan batang, grafik garis, dan histogram. Alat visual ini memungkinkan ilmuwan data mengidentifikasi anomali, memahami distribusi data, dan mengamati korelasi antar variabel. Misalnya, plot sebar dapat menyoroti penyimpangan, sementara plot rangkaian waktu dapat mengungkapkan tren dan pola musiman.
- Membuat array untuk negara-negara unik
- Bagan tren emisi untuk 10 pengemisi teratas (2000-2022)
- Memfilter dan membuat bagan emisi menurut wilayah
- Menghitung dan membuat grafik pertumbuhan berbagi energi terbarukan
- Diagram Sebar: Dampak energi terbarukan untuk pengemisi terbesar
- model memproyeksikan konsumsi energi global
Buat array untuk negara-negara unik
Periksa negara yang disertakan dalam himpunan data dengan membuat array untuk negara unik. Membuat array akan menunjukkan entitas yang tercantum sebagai country.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
Hasil:

Wawasan :
Kolom country mencakup berbagai entitas, termasuk Dunia, negara berpenghasilan tinggi, Asia, dan Amerika Serikat, yang tidak selalu sebanding secara langsung. Mungkin lebih berguna untuk memfilter data menurut wilayah.
Tren emisi bagan untuk 10 emiter teratas (2000-2022)
Katakanlah Anda ingin memfokuskan penyelidikan Anda pada 10 negara dengan emisi gas rumah kaca tertinggi pada tahun 2000-an. Anda dapat memfilter data selama bertahun-tahun yang ingin Anda lihat dan 10 negara teratas dengan emisi terbanyak, lalu menggunakan plotly untuk membuat bagan garis yang memperlihatkan emisinya dari waktu ke waktu.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
Hasil:
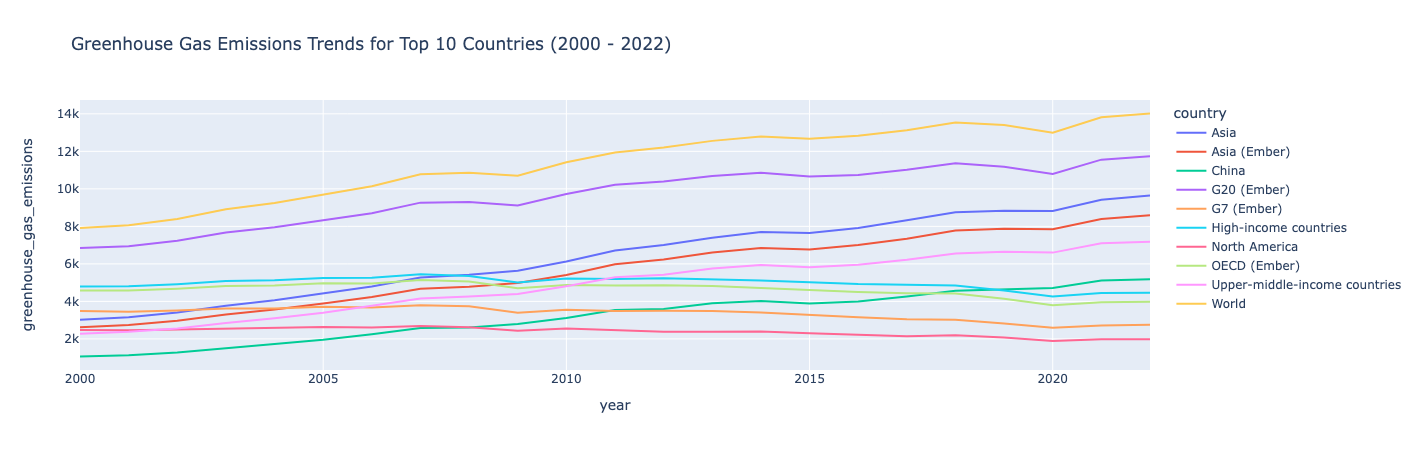
Wawasan :
Emisi gas rumah kaca tren naik dari 2000-2022, dengan pengecualian beberapa negara di mana emisi relatif stabil dengan sedikit penurunan selama jangka waktu tersebut.
Memfilter dan membuat bagan emisi berdasarkan wilayah
Filter data menurut wilayah dan hitung total emisi untuk setiap wilayah. Kemudian plot data sebagai bagan batang:
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
Hasil:
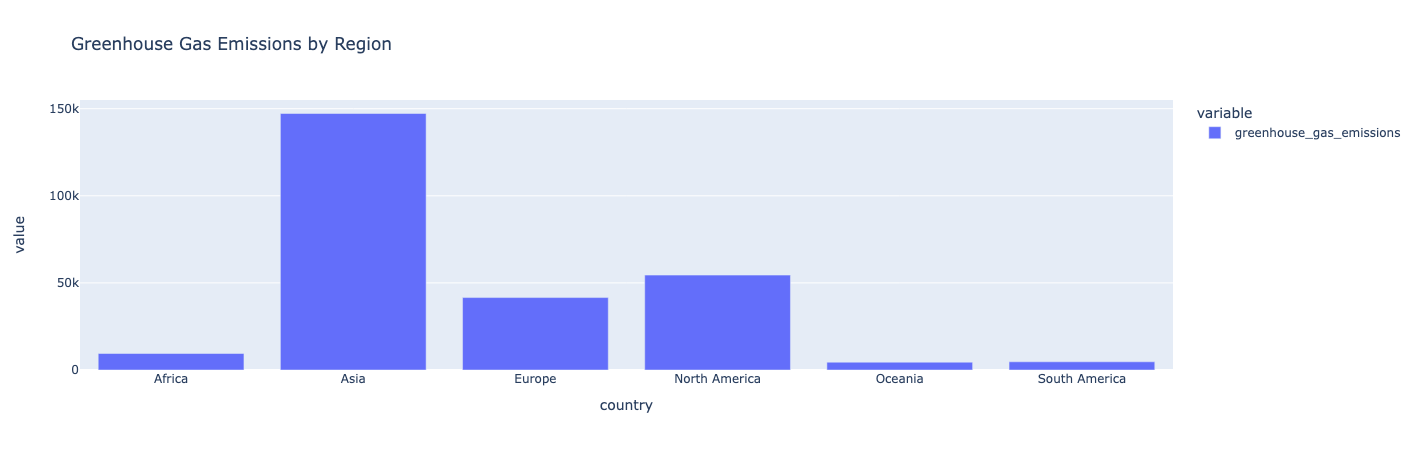
Wawasan:
Asia memiliki emisi gas rumah kaca tertinggi. Oseania, Amerika Selatan, dan Afrika menghasilkan emisi gas rumah kaca terendah.
Menghitung dan membuat grafik pertumbuhan berbagi energi terbarukan
Buat fitur/kolom baru yang menghitung pembagian energi terbarukan sebagai rasio konsumsi energi terbarukan atas konsumsi energi utama. Kemudian, urutkan negara-negara berdasarkan porsi rata-rata energi terbarukan mereka. Untuk 10 negara teratas, gambarkan porsi energi terbarukan mereka dari waktu ke waktu.
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
Hasil:
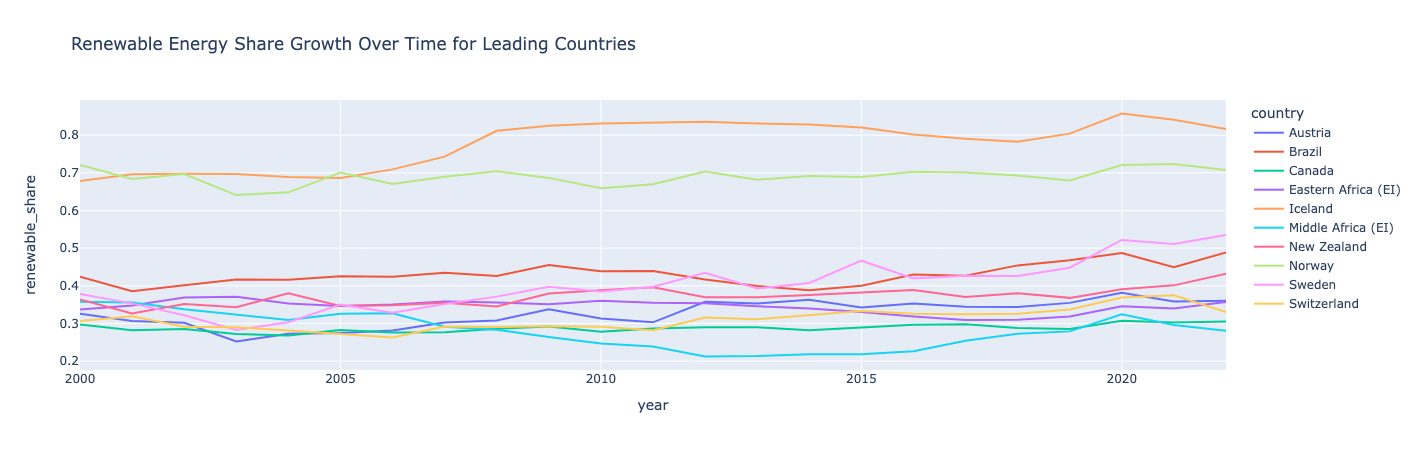
Wawasan :
Norwegia dan Islandia memimpin dunia dalam energi terbarukan, dengan lebih dari setengah konsumsi mereka berasal dari energi terbarukan.
Islandia dan Swedia melihat pertumbuhan terbesar dalam berbagi energi terbarukan mereka. Semua negara melihat penurunan dan kenaikan sesekali, menunjukkan bagaimana pertumbuhan berbagi energi terbarukan belum tentu linier. Afrika Tengah melihat penurunan pada awal 2010-an tetapi terpental kembali pada tahun 2020.
Diagram sebar: Tampilkan dampak energi terbarukan untuk penghasil emisi utama
Filter data untuk 10 emiter teratas, lalu gunakan plot sebar untuk melihat berbagi energi terbarukan vs. emisi gas rumah kaca dari waktu ke waktu.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
Hasil:
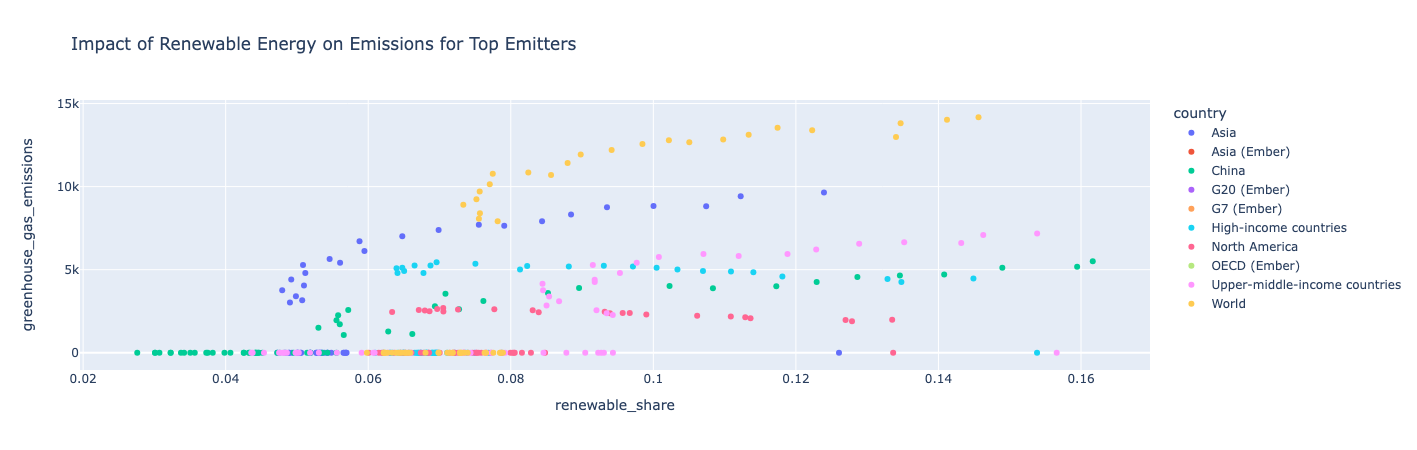
Wawasan :
Sebagai negara menggunakan lebih banyak energi terbarukan, ia juga memiliki lebih banyak emisi gas rumah kaca, yang berarti bahwa total konsumsi energinya naik lebih cepat daripada konsumsi terbarukannya. Amerika Utara adalah pengecualian dalam hal emisi gas rumah kacanya tetap relatif konstan selama bertahun-tahun karena porsinya dalam energi terbarukan terus meningkat.
Model memproyeksikan konsumsi energi global
Agregat konsumsi energi primer global berdasarkan tahun, lalu bangun model rata-rata bergerak terintegrasi (ARIMA) otomatis untuk memproyeikan total konsumsi energi global selama beberapa tahun ke depan. Plot konsumsi energi historis dan prakiraan menggunakan Matplotlib.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
Hasil:
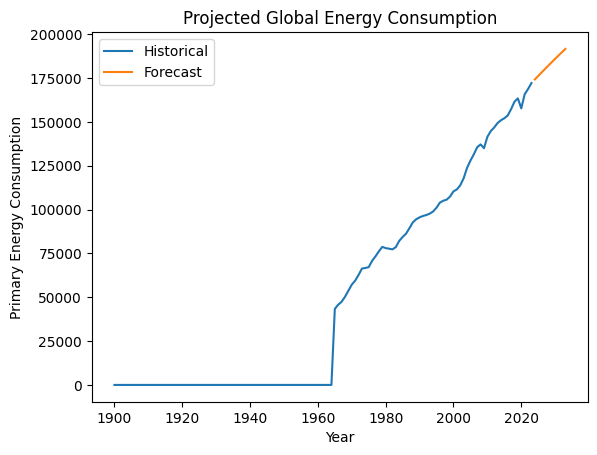
Wawasan :
Model ini memproyeksikan konsumsi energi global akan terus meningkat.
Contoh buku catatan
Gunakan buku catatan berikut untuk melakukan langkah-langkah dalam artikel ini. Untuk instruksi tentang mengimpor buku catatan ke ruang kerja Azure Databricks, lihat Apor buku catatan.
Tutorial: EDA dengan data energi global
Ambil buku catatan
Langkah berikutnya
Sekarang setelah Anda melakukan beberapa analisis data eksploratif awal pada himpunan data Anda, coba langkah-langkah berikutnya:
- Lihat Lampiran dalam contoh buku catatan untuk contoh visualisasi EDA tambahan.
- Jika Anda mengalami kesalahan saat melalui tutorial ini, coba gunakan debugger bawaan untuk menelusuri kode Anda. Lihat notebook debug.
- Bagikan buku catatan Anda dengan tim Anda sehingga mereka dapat memahami analisis Anda. Bergantung pada izin apa yang Anda berikan kepada mereka, mereka dapat membantu mengembangkan kode untuk lebih lanjut analisis atau menambahkan komentar dan saran untuk penyelidikan lebih lanjut.
- Setelah Menyelesaikan analisis, buat dasbor buku catatan atau dasbor AI/BI dengan visualisasi utama untuk dibagikan dengan pemangku kepentingan.