Bagaimana Databricks mendukung CI/CD untuk pembelajaran mesin?
CI/CD (integrasi berkelanjutan dan pengiriman berkelanjutan) mengacu pada proses otomatis untuk mengembangkan, menyebarkan, memantau, dan memelihara aplikasi Anda. Dengan mengotomatiskan pembuatan, pengujian, dan penyebaran kode, tim pengembangan dapat memberikan rilis yang lebih sering dan andal daripada proses manual yang masih lazim di banyak tim rekayasa data dan ilmu data. CI/CD untuk pembelajaran mesin menyatukan teknik MLOps, DataOps, ModelOps, dan DevOps.
Artikel ini menjelaskan bagaimana Databricks mendukung CI/CD untuk solusi pembelajaran mesin. Dalam aplikasi pembelajaran mesin, CI/CD penting tidak hanya untuk aset kode, tetapi juga diterapkan pada alur data, termasuk data input dan hasil yang dihasilkan oleh model.

Elemen pembelajaran mesin yang membutuhkan CI/CD
Salah satu tantangan pengembangan ML adalah bahwa tim yang berbeda memiliki berbagai bagian proses. Teams mungkin mengandalkan alat yang berbeda dan memiliki jadwal rilis yang berbeda. Azure Databricks menyediakan satu data terpadu dan platform ML dengan alat terintegrasi untuk meningkatkan efisiensi tim dan memastikan konsistensi dan pengulangan data dan alur ML.
Secara umum untuk tugas pembelajaran mesin, berikut ini harus dilacak dalam alur kerja CI/CD otomatis:
- Data pelatihan, termasuk kualitas data, perubahan skema, dan perubahan distribusi.
- Input alur data.
- Kode untuk pelatihan, validasi, dan penyajian model.
- Prediksi dan performa model.
Mengintegrasikan Databricks ke dalam proses CI/CD Anda
MLOps, DataOps, ModelOps, dan DevOps mengacu pada integrasi proses pengembangan dengan "operasi" - membuat proses dan infrastruktur dapat diprediksi dan dapat diandalkan. Kumpulan artikel ini menjelaskan cara mengintegrasikan prinsip operasi ("ops") ke dalam alur kerja ML Anda pada platform Databricks.
Databricks menggabungkan semua komponen yang diperlukan untuk siklus hidup ML termasuk alat untuk membangun "konfigurasi sebagai kode" untuk memastikan reproduksi dan "infrastruktur sebagai kode" untuk mengotomatiskan provisi layanan cloud. Ini juga termasuk layanan pengelogan dan pemberitahuan untuk membantu Anda mendeteksi dan memecahkan masalah saat terjadi.
DataOps: Data yang andal dan aman
Model ML yang baik tergantung pada alur dan infrastruktur data yang andal. Dengan Databricks Data Intelligence Platform, seluruh alur data dari menyerap data ke output dari model yang dilayani ada di satu platform dan menggunakan set alat yang sama, yang memfasilitasi produktivitas, reproduktifitas, berbagi, dan pemecahan masalah.

Tugas dan alat DataOps di Databricks
Tabel mencantumkan tugas dan alat DataOps umum di Databricks:
| Tugas DataOps | Alat di Databricks |
|---|---|
| Menyerap dan mengubah data | Autoloader dan Apache Spark |
| Melacak perubahan pada data termasuk penerapan versi dan silsilah data | Tabel Delta |
| Membangun, mengelola, dan memantau alur pemrosesan data | Tabel Delta Live |
| Memastikan keamanan dan tata kelola data | Katalog Unity |
| Analisis dan dasbor data eksploratif | Notebook Databricks SQL, Dasbor, dan Databricks |
| Pengkodan umum | Buku catatan Databricks SQL dan Databricks |
| Menjadwalkan alur data | Pekerjaan Databricks |
| Mengotomatiskan alur kerja umum | Pekerjaan Databricks |
| Membuat, menyimpan, mengelola, dan menemukan fitur untuk pelatihan model | Penyimpanan Fitur Databricks |
| Pemantauan data | Pemantauan Lakehouse |
ModelOps: Pengembangan model dan siklus hidup
Mengembangkan model memerlukan serangkaian eksperimen dan cara untuk melacak dan membandingkan kondisi dan hasil eksperimen tersebut. Platform Databricks Data Intelligence mencakup MLflow untuk pelacakan pengembangan model dan MLflow Model Registry untuk mengelola siklus hidup model termasuk penahapan, penyajian, dan penyimpanan artefak model.
Setelah model dirilis ke produksi, banyak hal dapat berubah yang mungkin memengaruhi performanya. Selain memantau performa prediksi model, Anda juga harus memantau data input untuk perubahan karakteristik kualitas atau statistik yang mungkin memerlukan pelatihan ulang model.
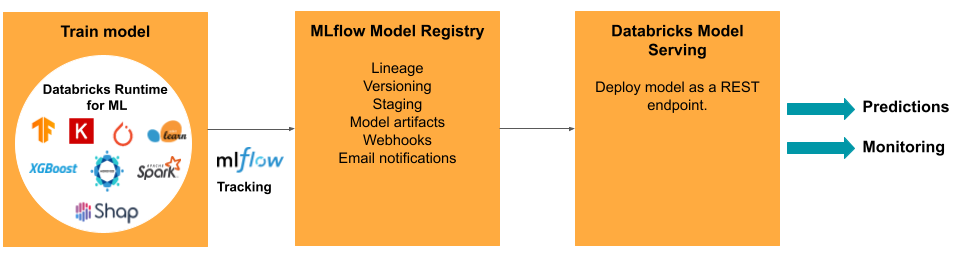
Tugas dan alat ModelOps di Databricks
Tabel mencantumkan tugas dan alat ModelOps umum yang disediakan oleh Databricks:
| Tugas ModelOps | Alat di Databricks |
|---|---|
| Lacak pengembangan model | Pelacakan model MLflow |
| Mengelola siklus hidup model | Model di Unity Catalog |
| Kontrol dan berbagi versi kode model | Folder Databricks Git |
| Pengembangan model tanpa kode | Databricks AutoML |
| Pemantauan model | Pemantauan Lakehouse |
DevOps: Produksi dan otomatisasi
Platform Databricks mendukung model ML dalam produksi dengan yang berikut:
- Data end-to-end dan silsilah model: Dari model dalam produksi kembali ke sumber data mentah, pada platform yang sama.
- Penyajian Model tingkat produksi: Secara otomatis meningkatkan atau menurunkan skala berdasarkan kebutuhan bisnis Anda.
- Pekerjaan: Mengotomatiskan pekerjaan dan membuat alur kerja pembelajaran mesin terjadwal.
- Folder Git: Penerapan versi dan berbagi kode dari ruang kerja, juga membantu tim mengikuti praktik terbaik rekayasa perangkat lunak.
- Penyedia Databricks Terraform: Mengotomatiskan infrastruktur penyebaran di seluruh cloud untuk pekerjaan inferensi ML, melayani titik akhir, dan pekerjaan fiturisasi.
Penyajian model
Untuk menyebarkan model ke produksi, MLflow secara signifikan menyederhanakan proses, menyediakan penyebaran klik tunggal sebagai pekerjaan batch untuk sejumlah besar data atau sebagai titik akhir REST pada kluster penskalaan otomatis. Integrasi Databricks Feature Store dengan MLflow juga memastikan konsistensi fitur untuk pelatihan dan penyajian; selain itu, model MLflow dapat secara otomatis mencari fitur dari Penyimpanan Fitur, bahkan untuk penyajian online latensi rendah.
Platform Databricks mendukung banyak opsi penyebaran model:
- Kode dan kontainer.
- Batch melayani.
- Penyajian online latensi rendah.
- Penyajian di perangkat atau tepi.
- Multi-cloud, misalnya, melatih model di satu cloud dan menyebarkannya dengan cloud lainnya.
Untuk informasi selengkapnya, lihat Mosaic AI Model Serving.
Pekerjaan
Pekerjaan Databricks memungkinkan Anda mengotomatiskan dan menjadwalkan semua jenis beban kerja, dari ETL ke ML. Databricks juga mendukung integrasi dengan orkestrator pihak ketiga populer seperti Airflow.
Folder Git
Platform Databricks mencakup dukungan Git di ruang kerja untuk membantu tim mengikuti praktik terbaik rekayasa perangkat lunak dengan melakukan operasi Git melalui UI. Administrator dan teknisi DevOps dapat menggunakan API untuk menyiapkan otomatisasi dengan alat CI/CD favorit mereka. Databricks mendukung semua jenis penyebaran Git termasuk jaringan privat.
Untuk informasi selengkapnya tentang praktik terbaik untuk pengembangan kode menggunakan folder Databricks Git, lihat alur kerja CI/CD dengan integrasi Git dan folder Databricks Git dan Gunakan CI/CD. Teknik-teknik ini, bersama dengan Databricks REST API, memungkinkan Anda membangun proses penyebaran otomatis dengan GitHub Actions, alur Azure DevOps, atau pekerjaan Jenkins.
Katalog Unity untuk tata kelola dan keamanan
Platform Databricks mencakup Unity Catalog, yang memungkinkan admin menyiapkan kontrol akses, kebijakan keamanan, dan tata kelola yang halus untuk semua data dan aset AI di seluruh Databricks.