Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini melengkapi alur kerja MLOps pada Databricks dengan menambahkan informasi khusus untuk alur kerja LLMOps. Untuk detail selengkapnya, lihat Buku Besar MLOps.
Bagaimana alur kerja MLOps berubah untuk LLM?
LLM adalah kelas model pemrosesan bahasa alami (NLP) yang telah secara signifikan melampaui ukuran dan performa pendahulunya di berbagai tugas, seperti jawaban atas pertanyaan terbuka, ringkasan, dan eksekusi instruksi.
Pengembangan dan evaluasi LLM berbeda dalam beberapa cara penting dari model ML tradisional. Bagian ini secara singkat meringkas beberapa properti utama LLM dan implikasi untuk MLOps.
| Properti utama LLM | Implikasi bagi MLOps |
|---|---|
LLM tersedia dalam banyak bentuk.
|
Proses pengembangan: Proyek sering berkembang secara bertahap, mulai dari model pihak ketiga atau sumber terbuka yang ada dan berakhir dengan model kustom yang disempurnakan. |
| Banyak LLM mengambil kueri dan instruksi bahasa alami umum sebagai input. Kueri tersebut dapat berisi permintaan yang direkayasa dengan hati-hati untuk memunculkan respons yang diinginkan. |
Proses pengembangan: Merancang templat teks untuk mengkueri LLM sering menjadi bagian penting untuk mengembangkan alur LLM baru. Pengemasan artefak ML: Banyak alur LLM menggunakan LLM yang ada atau titik akhir layanan LLM. Logika ML yang dikembangkan untuk alur tersebut mungkin berfokus pada templat prompt, agen, atau rangkaian, bukan pada model itu sendiri. Artefak ML yang dipaketkan dan dimajukan ke tahap produksi mungkin adalah alur kerja ini, bukan model. |
| Banyak LLM dapat diberikan perintah dengan contoh, konteks, atau informasi lainnya untuk membantu menjawab kueri. | Melayani infrastruktur: Saat menambah kueri LLM dengan konteks, Anda mungkin menggunakan alat tambahan seperti indeks vektor untuk mencari konteks yang relevan. |
| API pihak ketiga menyediakan model kepemilikan dan sumber terbuka. | tata kelola API: Menggunakan tata kelola API terpusat memberikan kemampuan untuk beralih dengan mudah antar penyedia API. |
| LLM adalah model pembelajaran mendalam yang sangat besar, sering kali mulai dari gigabyte hingga ratusan gigabyte. |
Infrastruktur penyajian: LLM mungkin memerlukan GPU untuk penyajian model real time, dan penyimpanan cepat untuk model yang perlu dimuat secara dinamis. Tradeoff biaya/performa: Karena model yang lebih besar membutuhkan lebih banyak komputasi dan lebih mahal untuk dijalankan, mungkin diperlukan teknik untuk mengurangi ukuran model dan komputasi. |
| LLM sulit dievaluasi menggunakan metrik ML tradisional karena sering kali tidak ada satu jawaban "kanan". | Umpan balik manusia: Umpan balik manusia sangat penting untuk mengevaluasi dan menguji LLM. Anda harus memasukkan umpan balik pengguna langsung ke dalam proses MLOps, termasuk untuk pengujian, pemantauan, dan penyempurnaan di masa mendatang. |
Kesamaan antara MLOps dan LLMOps
Banyak aspek proses MLOps tidak berubah untuk LLM. Misalnya, panduan berikut juga berlaku untuk LLM:
- Gunakan lingkungan terpisah untuk pengembangan, penahapan, dan produksi.
- Gunakan Git untuk kontrol versi.
- Kelola pengembangan model dengan MLflow, dan gunakan Model di Unity Catalog untuk mengelola siklus hidup model.
- Simpan data menggunakan arsitektur lakehouse dengan tabel Delta.
- Infrastruktur CI/CD yang ada seharusnya tidak memerlukan perubahan apa pun.
- Struktur modular MLOps tetap sama, dengan alur untuk fiturisasi, pelatihan model, inferensi model, dan sebagainya.
Diagram arsitektur referensi
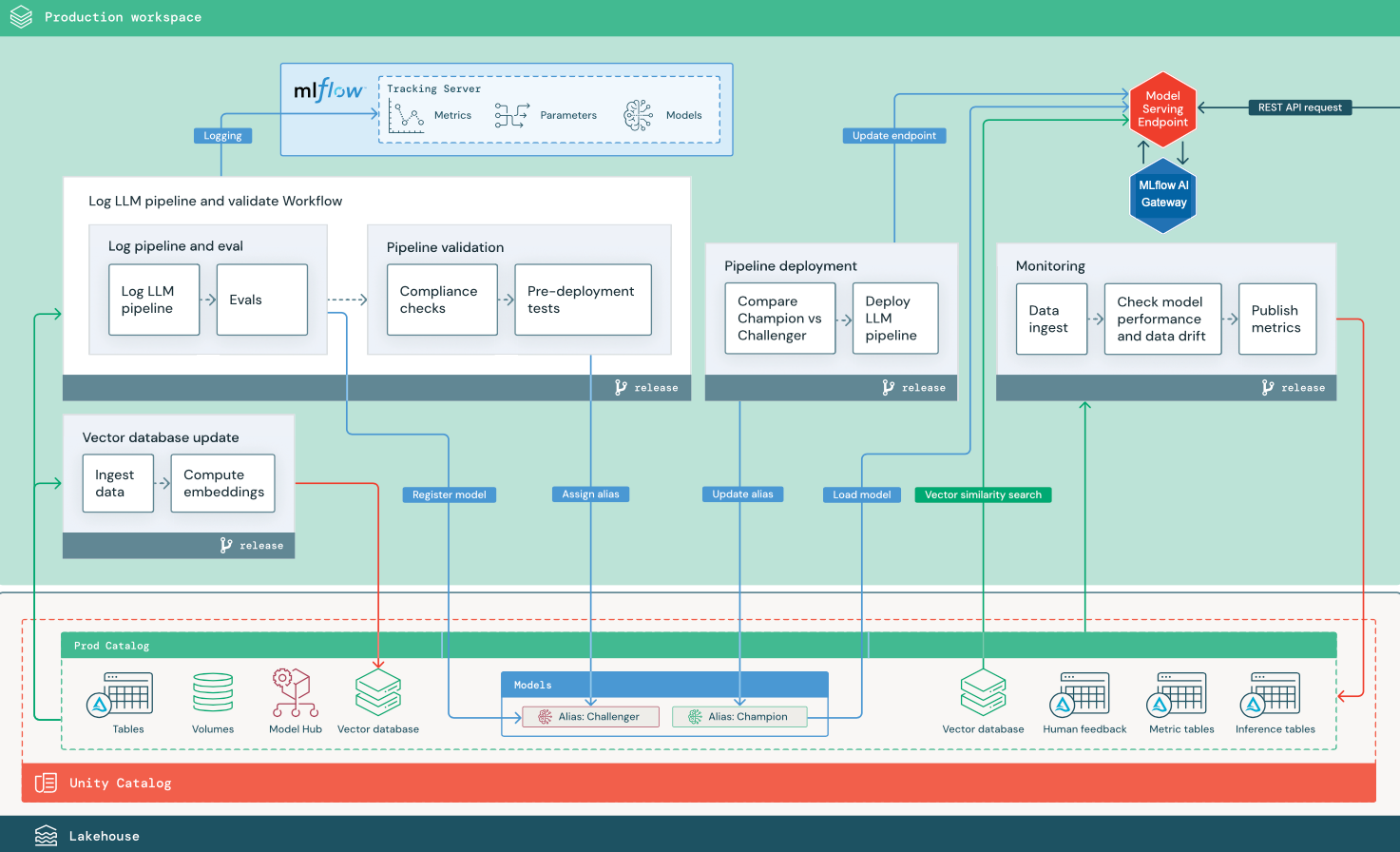
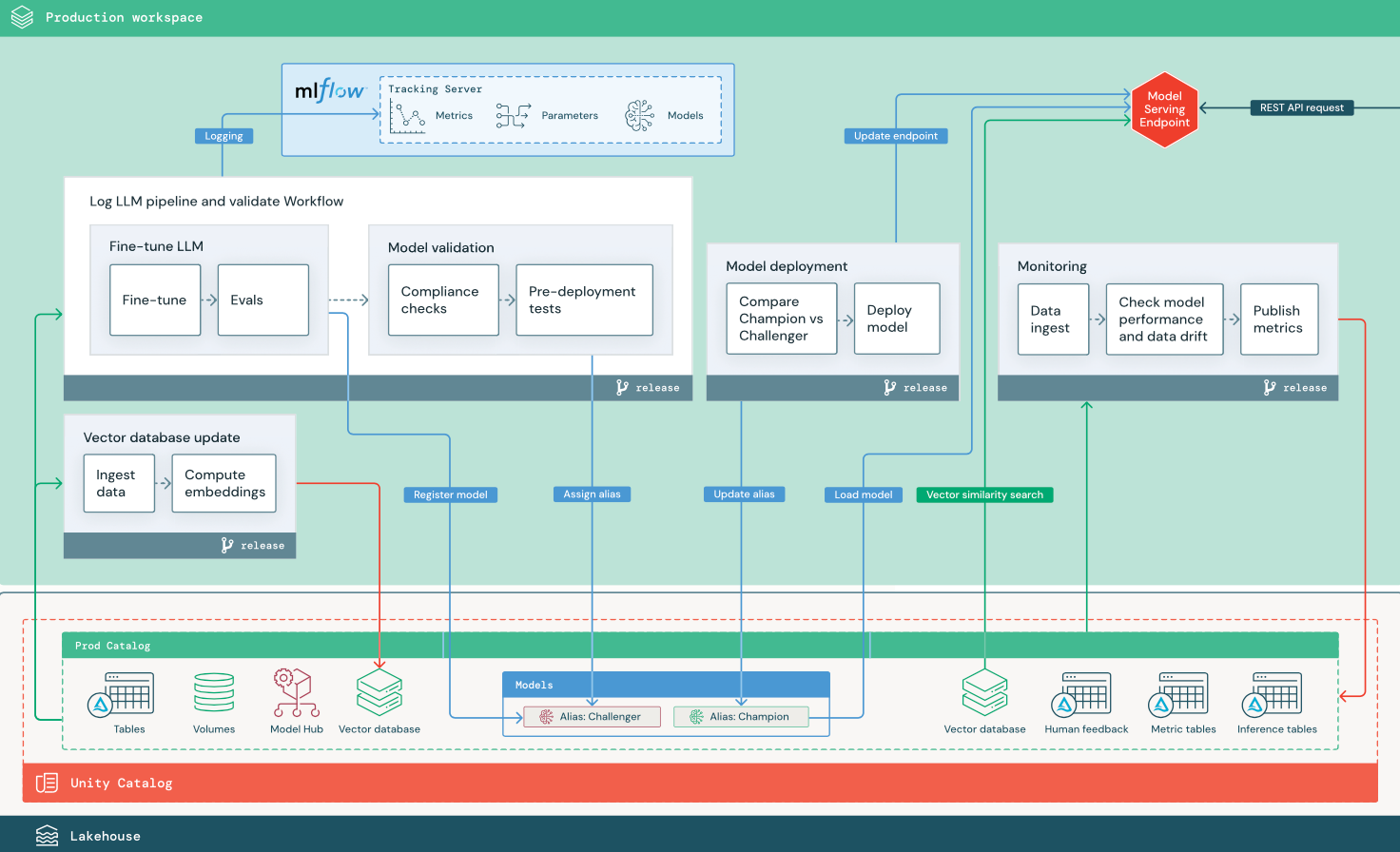
Bagian ini menggunakan dua aplikasi berbasis LLM untuk mengilustrasikan beberapa penyesuaian arsitektur referensi MLOps tradisional. Diagram menunjukkan arsitektur produksi untuk 1) aplikasi retrieval-augmented generation (RAG) menggunakan API pihak ketiga, dan 2) aplikasi RAG menggunakan model yang di-host sendiri yang telah disesuaikan. Kedua diagram memperlihatkan database vektor opsional — item ini dapat diganti dengan langsung mengajukan kueri ke LLM melalui endpoint Model Serving.
RAG dengan LLM API pihak ketiga
Diagram menunjukkan arsitektur produksi untuk aplikasi RAG yang terhubung ke API LLM pihak ketiga menggunakan Model Eksternal Databricks.
RAG dengan model sumber terbuka yang disempurnakan
Diagram menunjukkan arsitektur produksi untuk aplikasi RAG yang menyempurnakan model sumber terbuka.
LLMOps mengalami perubahan pada arsitektur produksi MLOps
Bagian ini menyoroti perubahan besar pada arsitektur referensi MLOps untuk aplikasi LLMOps.
Pusat model
Aplikasi LLM sering menggunakan model yang sudah ada dan telah dilatih yang dipilih dari hub model internal atau eksternal. Model dapat digunakan apa adanya atau disempurnakan.
Databricks mencakup pilihan model dasar berkualitas tinggi dan pra-terlatih di Unity Catalog dan di Databricks Marketplace. Anda dapat menggunakan model yang telah dilatih sebelumnya ini untuk mengakses kemampuan AI canggih, menghemat waktu dan biaya untuk membangun model kustom Anda sendiri. Untuk detailnya, lihat Mendapatkan model AI dan LLM generatif dari Unity Catalog dan Marketplace.
Indeks vektor
Beberapa aplikasi LLM menggunakan indeks vektor untuk pencarian kesamaan cepat, misalnya untuk memberikan pengetahuan konteks atau domain dalam kueri LLM. Databricks menyediakan fungsionalitas pencarian vektor terintegrasi yang memungkinkan Anda menggunakan tabel Delta apa pun di Unity Catalog sebagai indeks vektor. Indeks pencarian vektor secara otomatis disinkronkan dengan tabel Delta. Untuk detailnya, lihat Pencarian Vektor.
Anda dapat membuat artefak model yang merangkum logika untuk mengambil informasi dari indeks vektor dan menyediakan data yang dikembalikan sebagai konteks ke LLM. Anda kemudian dapat mencatat model dengan menggunakan jenis model MLflow LangChain atau PyFunc.
Mengoptimalkan LLM
Karena model LLM mahal dan memakan waktu untuk dibuat dari awal, aplikasi LLM sering menyempurnakan model yang ada untuk meningkatkan performanya dalam skenario tertentu. Dalam arsitektur referensi, penyempurnaan dan penerapan model diwakili sebagai Pekerjaan Lakeflow yang terpisah. Memvalidasi model yang disempurnakan sebelum menyebarkan sering kali merupakan proses manual.
Databricks menyediakan Penyempurnaan Model Foundation, yang memungkinkan Anda menggunakan data Anda sendiri untuk menyesuaikan LLM yang ada untuk mengoptimalkan performanya untuk aplikasi spesifik Anda. Untuk detailnya, lihat Penyesuaian Halus Model Foundation.
Pelayanan model
Dalam RAG menggunakan skenario API pihak ketiga, perubahan arsitektur penting adalah bahwa alur LLM melakukan panggilan API eksternal, dari titik akhir Model Serving ke API LLM internal atau pihak ketiga. Ini menambahkan kompleksitas, latensi potensial, dan manajemen kredensial tambahan.
Databricks menyediakan Mosaic AI Model Serving, yang menyediakan antarmuka terpadu untuk menyebarkan, mengatur, dan mengkueri model AI. Untuk detailnya, lihat Mosaic AI Model Serving.
Umpan balik manusia dalam pemantauan dan evaluasi
Perulangan umpan balik manusia sangat penting di sebagian besar aplikasi LLM. Umpan balik manusia harus dikelola seperti data lain, idealnya dimasukkan ke dalam pemantauan berdasarkan streaming hampir waktu nyata.
Aplikasi ulasan Mosaic AI Agent Framework membantu Anda mengumpulkan umpan balik dari peninjau manusia. Untuk informasi lebih lanjut, lihat Gunakan aplikasi ulasan untuk tinjauan manusia terhadap aplikasi gen AI (MLflow 2).