Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Note
Fitur Lakebase Change Data Feed berada dalam Pratinjau Publik.
Apa itu Umpan Perubahan Data Lakebase?
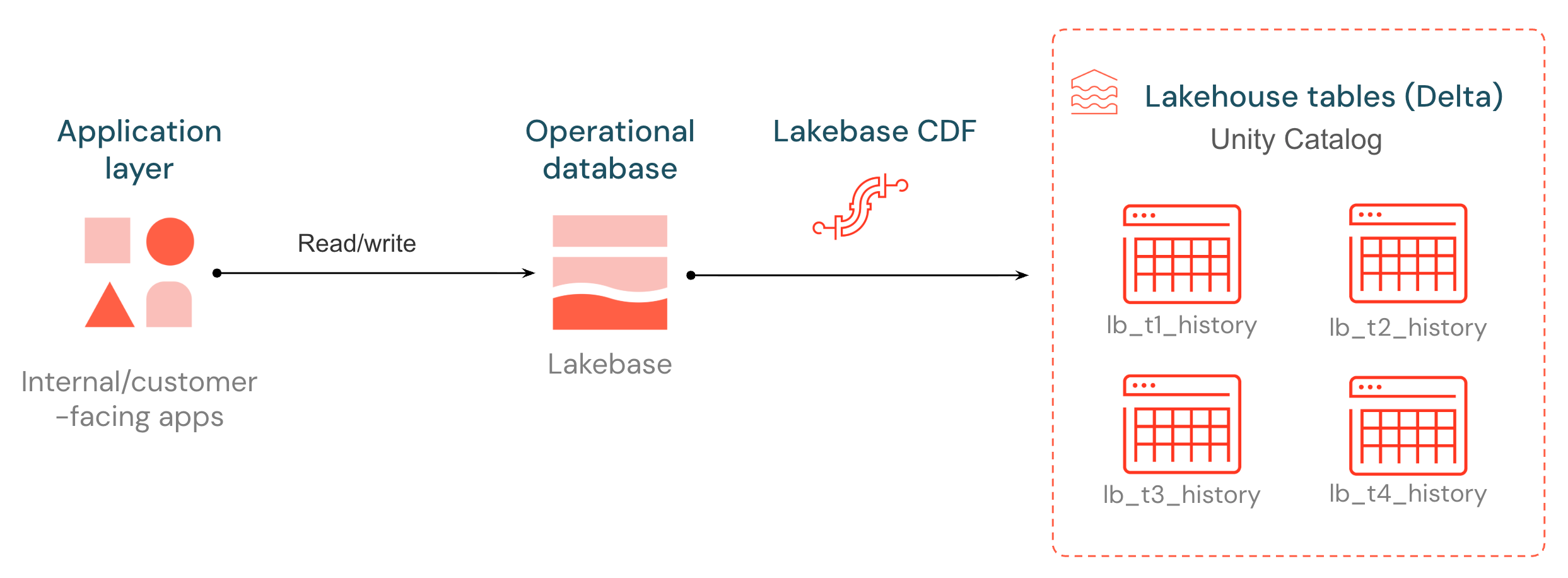
Lakebase memperkenalkan Change Data Feed (CDF) bawaan, yang membuka akses ke data operasional Anda untuk pipeline, model, dan aplikasi downstream. Setiap penyisipan, pembaruan, dan penghapusan pada tabel Postgres Lakebase dicatat dari log write-ahead dan disimpan sebagai baris baru dalam tabel Delta terkelola Unity Catalog, diproses secara batch dan ditulis setiap ~15 detik. Riwayat perubahan disimpan dalam format terbuka yang dapat dibaca oleh mesin komputasi apa pun.
Tabel tujuan mengikuti bentuk yang sama dengan Delta Change Data Feed: setiap baris membawa _pg_change_type, LSN, ID transaksi, dan tanda waktu. Perubahan operasional menjadi sumber utama untuk ETL, audit, dan konsumen downstream — tanpa perlu menyiapkan stack CDC eksternal.
Skenario penggunaan
Lakebase CDF membawa data operasional ke lakehouse sehingga pipeline dan aplikasi hilir dapat bereaksi terhadap perubahan secara real time.
| Skenario penggunaan | Description |
|---|---|
| Pipeline ETL | Gunakan Lakebase sebagai sumber perunggu untuk alur medali. Bangun pekerjaan SDP atau Spark Structured Streaming bertahap terhadap umpan perubahan dan perbarui tabel perak dan emas hilir. |
| Audit log | Pertahankan riwayat lengkap yang dapat dikueri dari setiap sisipan, pembaruan, dan penghapusan pada tabel Lakebase untuk kepatuhan dan forensik. Sejarahnya adalah Delta yang tidak dapat diubah. |
| Sistem eksternal | Simpan data perubahan Lakebase dalam format terbuka yang dapat dikonsumsi mesin apa pun. Karena tujuannya adalah tabel Delta di Unity Catalog, sistem eksternal dan pembaca non-Databricks dapat mengakses umpan secara langsung. |
Aktifkan pratinjau ini
Administrator ruang kerja harus mengaktifkan pratinjau Lakebase Change Data Feed dari halaman Pratinjau pada ruang kerja.
Requirements
- Autoscaling Lakebase:Proyek Autoscaling Lakebase yang menjalankan Postgres 17.
-
Database sumber: Tabel harus berada di
databricks_postgresdatabase di Lakebase. Setiap proyek dibuat dengan database default ini. Ini adalah keterbatasan yang diketahui. - Katalog Unity: Identitas yang mengonfigurasi CDF membutuhkan USE CATALOG, , USE SCHEMAdan CREATE TABLE pada katalog dan skema tujuan. Lihat Memberikan izin pada objek.
- Penyimpanan default: Katalog tujuan yang dikonfigurasi dengan penyimpanan default tidak didukung.
- Proyek Lakebase: Peran Postgres Anda memerlukan izin CAN MANAGE pada proyek Lakebase. Pemilik proyek memiliki DAPAT MENGELOLA secara bawaan. Lihat Mengelola izin proyek.
- Jenis data: Lihat Pemetaan jenis data. Tipe data yang tidak memiliki padanan langsung dalam Delta akan disimpan sebagai STRING.
Siapkan Lakebase CDF
Untuk memulai, atur identitas replika penuh pada tabel yang Anda inginkan di umpan (Langkah 1), lalu mulai CDF di aplikasi Lakebase (Langkah 2). Data Anda muncul sebagai lb_<table_name>_history tabel Delta di katalog dan skema Unity Catalog yang Anda pilih.
Langkah 1: Atur identitas replika penuh
Agar tabel Lakebase dapat berpartisipasi dalam CDF, tabel tersebut harus menetapkan REPLICA IDENTITY FULL. Secara default Postgres hanya mencatat kunci utama saat baris diperbarui atau dihapus. Menetapkan full identity memberi tahu Postgres untuk merekam status baris sebelum dan sesudah perubahan dalam write-ahead log, yang diperlukan CDF untuk membangun riwayat perubahan yang lengkap.
Anda dapat menjalankan perintah ini di Editor Lakebase SQL atau klien Postgres apa pun.
Tabel tunggal
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Semua tabel yang ada dalam skema
Untuk mengatur identitas replika pada setiap tabel yang ada dalam skema (public dalam contoh ini), jalankan:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Terapkan otomatis ke tabel mendatang
Untuk membuat setiap tabel yang baru dibuat secara otomatis menerima REPLICA IDENTITY FULL, instal pemicu peristiwa Postgres. Ini berjalan setelah setiap CREATE TABLE dan mengatur identitas pada tabel baru:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Gabungkan pemicu peristiwa dengan perulangan di tab sebelumnya untuk mencakup tabel yang sudah ada maupun yang akan datang dalam satu konfigurasi.
Periksa tabel mana yang memiliki set identitas replika
Untuk melihat tabel mana dalam skema yang memiliki identitas replika yang dikonfigurasi, jalankan:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Hanya baris dengan replica_identity = 'full' yang siap untuk CDF.
Langkah 2: Mulai umpan data perubahan
Lakebase CDF dikonfigurasi pada tingkat skema. Setelah dimulai, setiap tabel saat ini dan di masa mendatang dalam skema sumber disertakan dalam umpan.
- Di ruang kerja Azure Databricks Anda, buka Lakebase Postgres dari pengalih aplikasi (kanan atas).
- Pilih proyek Lakebase Anda dan cabang yang ingin Anda gunakan (misalnya, produksi atau utama).
- Buka Gambaran umum cabang dan klik tab Ubah Umpan Data .
- Klik Mulai.
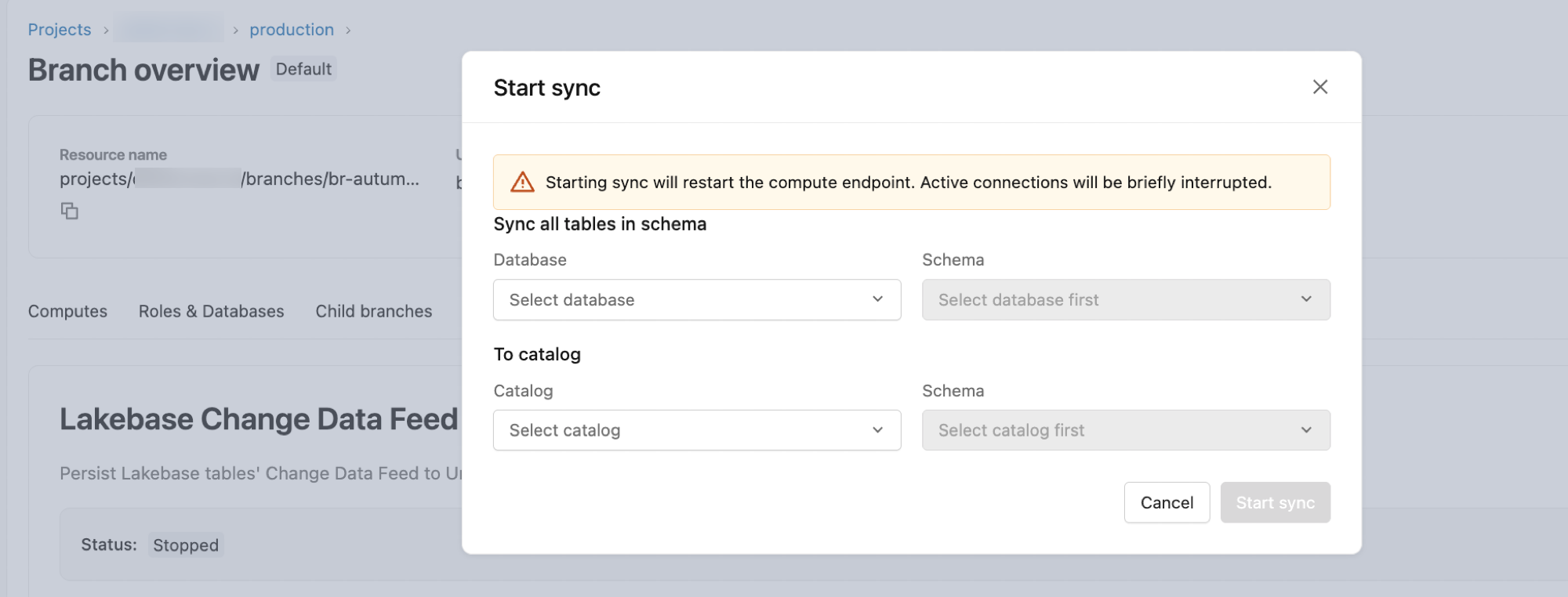
- Dalam dialog konfigurasi:
-
Database: Default ke nilai
databricks_postgres. - Skema: Pilih skema Postgres sumber.
- Katalog Tujuan: Pilih katalog tujuan Unity Catalog.
- Skema: Pilih skema Unity Catalog tujuan.
-
Database: Default ke nilai
- Klik Mulai untuk memulai umpan.
Tabel ditampilkan di tujuan sebagai lb_<table_name>_history. Untuk menemukannya, buka Katalog di bar samping, navigasikan ke katalog dan skema tujuan, dan buka tab Tabel .
Tab Ubah Umpan Data di Lakebase memiliki dua sub-tab:
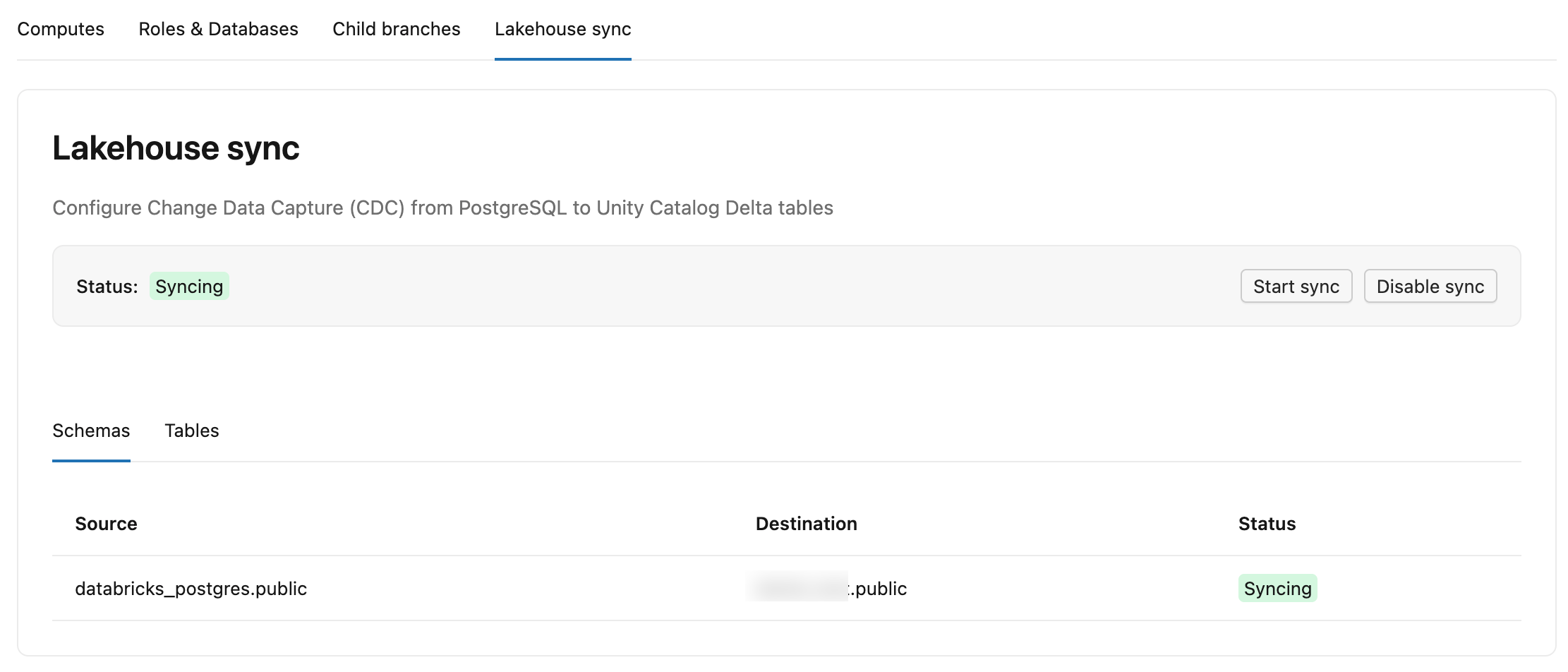
- Skema: Mencantumkan setiap skema sumber, katalog tujuan dan skemanya di Katalog Unity, dan status.
-
Tabel: Mencantumkan setiap tabel sumber, tabel tujuan
lb_<table_name>_history, status (StreamingatauSnapshotting), LSN yang diterapkan (seberapa jauh umpan telah ditulis ke Delta, ditampilkan saat-masih dalam rekam jepret awal), dan Pembaruan terakhir (terakhir kali tabel menerima perubahan).
Anda juga dapat memeriksa status umpan dari Postgres dengan menjalankan ini di Editor Lakebase SQL:
SELECT * FROM wal2delta.tables;
Hasilnya mencakup table_oid, (statusSTREAMING atau SNAPSHOTTING), committed_lsn, dan last_write_time per tabel.
Important
Apa itu wal2delta? Lakebase CDF didukung oleh ekstensi wal2delta Postgres, yang berjalan di dalam komputasi Lakebase. Ini menggunakan dekode logis untuk menangkap perubahan pada write-ahead log (WAL) dan menuliskannya ke tabel Delta di Unity Catalog.
Skema tabel tujuan
CDF menulis satu tabel Delta per tabel sumber, bernama lb_<table_name>_history di katalog dan skema tujuan Anda. Selain kolom sumber Anda, setiap baris memiliki kolom sistem berikut:
| kolom | Type | Description |
|---|---|---|
_pg_change_type |
TEKS | Jenis operasi: insert, delete, update_preimage, atau update_postimage. |
_pg_lsn |
BIGINT | Nomor Urutan Log Postgres. |
_pg_xid |
INTEGER | ID Transaksi Postgres. |
_timestamp |
TIMESTAMP | Tanda waktu ketika perubahan diproses (tanpa zona waktu). |
_sort_by |
BIGINT | Kunci pengurutan monotonik digunakan untuk mengurutkan semua perubahan. |
Pola perubahan umum
-
Rekam jepret awal: Pertama kali CDF berjalan pada tabel Lakebase yang ada, setiap baris yang ada ditulis dengan
_pg_change_type = 'insert'. -
Update: Pembaruan menghasilkan dua baris: satu dengan
_pg_change_type = 'update_preimage'(baris lama) dan satu dengan_pg_change_type = 'update_postimage'(baris baru). -
Menghapus: Penghapusan menghasilkan satu baris dengan
_pg_change_type = 'delete'.
Ini adalah peristiwa perubahan yang sama dengan Umpan Data Perubahan Delta, sehingga pola hilir yang sama berlaku.
Perilaku operasional
-
Konflik penamaan: Jika dua tabel sumber dipetakan ke nama tujuan yang sama (misalnya,
sales.usersdanmarketing.userskeduanya dipetakan kelb_users_history), CDF menulis yang pertama kelb_users_historydan secara otomatis menambahkan sufiks pada yang kedua menjadilb_users_history_1. Anda dapat mengganti nama tabel tujuan di Katalog Unity dan umpan terus berfungsi. - Cakupan tingkat skema: Saat Anda memulai CDF pada skema Lakebase, setiap tabel saat ini dan di masa mendatang dalam skema tersebut disertakan. Tabel kosong akan dilewati — tabel harus memiliki setidaknya satu baris agar ditampilkan di tujuan.
- Tabel sumber yang dihapus: Jika Anda menghapus tabel di Lakebase, tabel Delta tujuan di Unity Catalog tetap dipertahankan.
Membangun alur hilir
Lakebase CDF dirancang untuk alur hilir yang bereaksi terhadap perubahan operasional. Pola di bawah ini menunjukkan tiga cara untuk mengonsumsi umpan, diurutkan dari yang paling sederhana hingga yang paling fleksibel.
Contoh skenario. Aplikasi e-commerce mencatat pesanan ke dalam tabel Postgres orders, dengan setiap baris berisi item_id dan quantity. Tim logistik memerlukan tingkat stok secara real-time. Dengan CDF, setiap perubahan pada orders disimpan dalam tabel Delta lb_orders_history di Unity Catalog. Pipeline downstream membaca feed perubahan tersebut dan memperbarui tabel inventory_levels setiap kali pesanan dibuat, diedit, atau dibatalkan.
Menghitung inventarisasi saat ini dengan tampilan materialisasi
Pola paling sederhana adalah SQL materialized view pada tabel riwayat. MV diperbarui secara bertahap saat event perubahan baru tiba, dan konsumen hilir melakukan kueri padanya seperti pada tabel lain.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Dua baris yang dihasilkan untuk setiap pembaruan saling meniadakan satu sama lain kecuali pada perubahan neto, sehingga jumlah kumulatif tetap benar saat pesanan diedit.
Streaming perubahan dengan Spark Declarative Pipelines
Untuk arsitektur medali yang terstruktur, gunakan Spark Declarative Pipelines (SDP) untuk mendeklarasikan tabel perunggu, perak, dan emas. SDP menjalankannya sebagai pipeline yang saling terhubung, dengan checkpoint dan manajemen dependensi ditangani secara otomatis untuk Anda.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments membaca lb_orders_history secara inkremental dengan readStream dan menghasilkan delta per peristiwa.
inventory_levels mengagregasi dengan item_id untuk menghitung stok saat ini. Asumsinya menghapus baris yang akan membuat stok menjadi negatif, yang menandakan adanya bug di proses sebelumnya.
Untuk panduan lengkap menyeluruh, lihat Tutorial: Membangun alur ETL menggunakan change data capture.
Pemrosesan kustom dengan Streaming Terstruktur Spark
Saat Anda memerlukan kontrol penuh — misalnya, penggabungan kustom, efek samping, atau beberapa sink — baca tabel riwayat langsung dengan Spark Structured Streaming dan gunakan foreachBatch untuk menulis ke tujuan Anda.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Setiap microbatch mengagregasi peristiwa perubahan dengan item_id dan menggabungkan delta net menjadi inventory_levels.
Inkremental berdasarkan desain. Setiap lb_<table_name>_history tabel adalah tabel Delta yang hanya dapat ditambahkan. Setiap perubahan sumber dicatat sebagai baris baru dengan _pg_change_type menandai operasi. Tampilan terwujud Databricks SQL , alur Lakeflow Spark Declarative Pipelines, dan job Spark Structured Streaming semuanya memproses baris baru secara inkremental dari log transaksi Delta, sehingga pipeline hilir hanya melakukan pemrosesan yang sebanding dengan perubahan yang terjadi. Anda tidak perlu mengaktifkan Umpan Data Perubahan Delta pada tabel riwayat karena semantik perubahan sudah dikodekan dalam data baris.
Pemetaan jenis data
CDF mendukung sebagian besar jenis primitif PostgreSQL standar. Tipe data yang tidak memiliki padanan langsung dalam Delta akan disimpan sebagai STRING.
| Jenis PostgreSQL | jenis Delta di Azure Databricks | Notes |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| TEKS, VARCHAR, KARAKTER | STRING | |
| JSONB | STRING | Disimpan sebagai string JSON. |
| ENUM | STRING | Disimpan sebagai label enum. |
| NUMERIK / DESIMAL | desimal atau string | Menggunakan presisi/skala sumber jika memungkinkan. Melakukan penskalaan ulang tanpa kerugian untuk nilai presisi/skala yang tidak kompatibel. Kembali ke STRING ketika presisi melebihi 38 atau ketika presisi/skala tidak terdefinisi (NUMERIC tidak terbatas). Semua kolom NUMERIC/DECIMAL dapat bernilai NULL karena nilai NaN dipetakan ke NULL. Lihat Jenis numerik PostgreSQL. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
Jenis yang disimpan sebagai STRING:
-
Geografi/Geometri (PostGIS): Jenis dari ekstensi PostGIS (misalnya,
geometry,geography). -
Vektor (pgvector): Jenis
vectordari ekstensi pgvector. -
Jenis komposit/struktur: Jenis kustom yang ditentukan dengan
CREATE TYPE ... AS (field_name type, ...). Ini adalah tipe mirip baris dengan bidang bernama. -
Peta: Jenis nilai kunci seperti peta seperti hstore (dari
hstoreekstensi). Postgres tidak memiliki jenis peta bawaan.hstoreadalah cara umum untuk menyimpan pasangan kunci-nilai dalam kolom.
Mengelola perubahan skema
-
Mengganti nama tabel di Postgres (misalnya,
ALTER TABLE users RENAME TO customers) memungkinkan umpan berlanjut. Nama tabel Delta tujuan tidak berubah — tetaplb_users_history. - Perubahan skema (menambahkan kolom, menghilangkan kolom, atau mengubah jenis data kolom) memicu rekam jepret ulang tabel yang terpengaruh. CDF membaca ulang seluruh tabel dari Postgres dan menulis ulang tabel Delta tujuan.
Menonaktifkan Lakebase CDF
Menonaktifkan CDF menghentikan umpan untuk semua skema Lakebase dalam proyek.
- Di ruang kerja Azure Databricks Anda, buka Lakebase Postgres dari pengalih aplikasi (kanan atas).
- Pilih proyek Lakebase dan cabang tempat Anda mengonfigurasi CDF.
- Buka Gambaran umum cabang dan klik tab Ubah Umpan Data .
- Klik Nonaktifkan. Dalam dialog konfirmasi, tinjau peringatan bahwa perubahan akan berhenti mengalir ke tabel Delta, lalu klik Nonaktifkan lagi untuk mengonfirmasi.
Menonaktifkan CDF tidak memulai ulang komputasi Anda.
Warning
Jika Anda mengaktifkan kembali CDF nanti, sistem tidak melakukan rekam jepret ulang penuh. Setiap perubahan yang terjadi saat CDF dinonaktifkan hilang secara permanen dari tabel Delta tujuan.
Batasan dan pemecahan masalah
Anda dapat melihat status per tabel (rekam jepret, dilewati, atau streaming) di tab Ubah Umpan Data , atau dengan menjalankan ini di Lakebase:
SELECT * FROM wal2delta.tables;
Alasan umum tabel tidak muncul di umpan:
-
REPLICA IDENTITY FULLbelum diatur: JalankanALTER TABLE <table_name> REPLICA IDENTITY FULL;pada tabel. Lihat Langkah 1: Atur identitas replika penuh. - Tabel yang dipartisi: Tabel yang dipartisi Lakebase tidak didukung. Skema yang berisi tabel yang dipartisi menyebabkan tabel tersebut gagal.
- Tabel kosong: Tabel dengan nol baris dilewati hingga setidaknya satu baris ada.
Langkah berikutnya
- Bangun ETL inkremental dengan Alur Deklaratif Spark. Lihat Tutorial: Membuat alur ETL menggunakan penangkapan data perubahan untuk panduan lengkap.
- Kueri lapisan perunggu dengan Databricks SQL. Lihat Mulai menggunakan pergudangan data menggunakan Databricks SQL.
- Riwayat audit dengan kueri perjalanan waktu pada tabel Delta tujuan.