Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling berada di Beta di wilayah berikut: eastus2, , westeuropewestus.
Lakebase Autoscaling adalah versi terbaru Lakebase dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk perbandingan fitur dengan Lakebase Provisioned, lihat memilih antar versi.
Reverse ETL di Lakebase menyinkronkan tabel Unity Catalog ke Postgres sehingga aplikasi dapat menggunakan data lakehouse yang telah disusun secara langsung. Lakehouse dioptimalkan untuk analisis dan pengayaan, sementara Lakebase dirancang untuk beban kerja operasional yang memerlukan kueri cepat serta konsistensi transaksi.
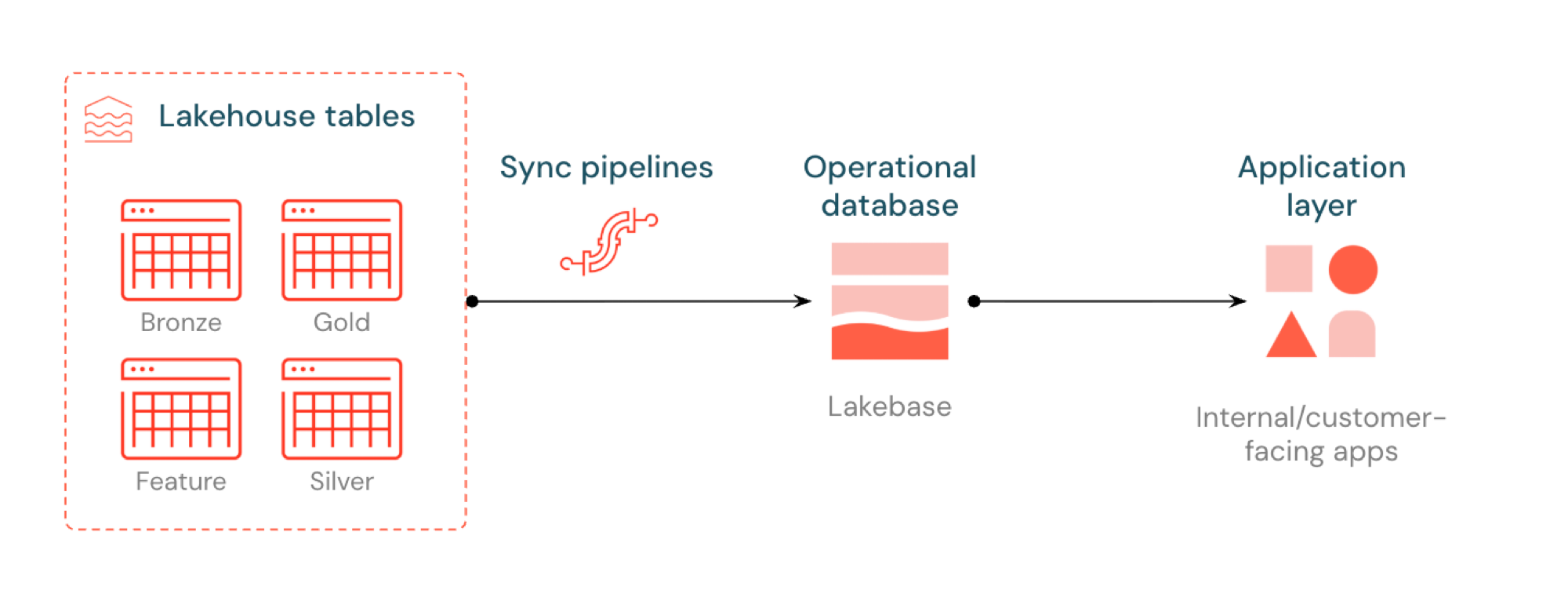
Apa itu reverse ETL?
Reverse ETL memungkinkan Anda memindahkan data tingkat analitik dari Unity Catalog ke Lakebase Postgres, di mana Anda dapat membuatnya tersedia untuk aplikasi yang membutuhkan kueri latensi rendah (sub-10ms) dan transaksi ACID penuh. Ini menjembatani kesenjangan antara penyimpanan analitik dan sistem operasional dengan menjaga data terkurasi dapat digunakan dalam aplikasi real-time.
Cara kerjanya
Tabel yang disinkronkan Databricks membuat salinan terkelola data Unity Catalog Anda di Lakebase. Saat membuat tabel yang disinkronkan, Anda mendapatkan:
- Tabel Unity Catalog baru (baca-saja, dikelola oleh alur sinkronisasi)
- Tabel Postgres di Lakebase (dapat dikueri oleh aplikasi Anda)
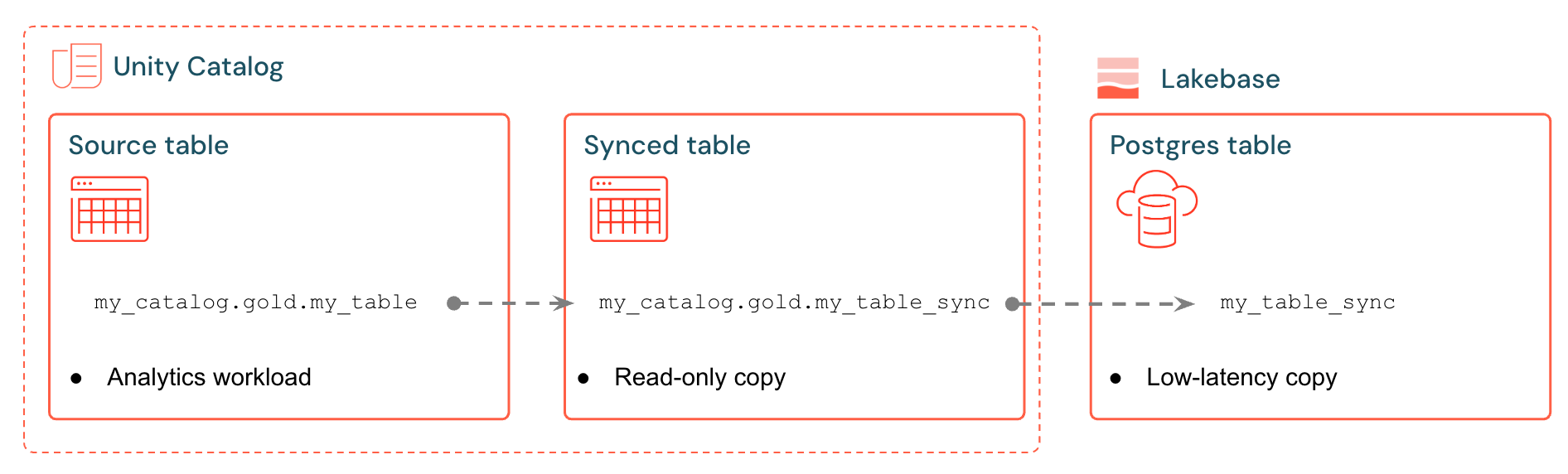
Misalnya, Anda dapat menyinkronkan tabel emas, fitur rekayasa, atau output ML dari analytics.gold.user_profiles ke dalam tabel analytics.gold.user_profiles_syncedbaru yang disinkronkan . Di Postgres, nama skema Katalog Unity menjadi nama skema Postgres, sehingga muncul sebagai "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Aplikasi terhubung dengan driver Postgres standar dan mengkueri data yang disinkronkan bersama status operasionalnya sendiri.
Alur sinkronisasi menggunakan Alur Deklaratif Lakeflow Spark terkelola untuk terus memperbarui tabel yang disinkronkan Katalog Unity dan tabel Postgres dengan perubahan dari tabel sumber. Setiap sinkronisasi dapat menggunakan hingga 16 koneksi ke database Lakebase Anda.
Lakebase Postgres mendukung hingga 1.000 koneksi bersamaan dengan jaminan transaksional, sehingga aplikasi dapat membaca data yang diperkaya sambil juga menangani sisipan, pembaruan, dan penghapusan dalam database yang sama.
Mode sinkronisasi
Pilih mode sinkronisasi yang tepat berdasarkan kebutuhan aplikasi Anda:
| Pengaturan | Description | Paling cocok untuk | Performance |
|---|---|---|---|
| Snapshot | Salin sekali semua data | Penyiapan awal atau analisis historis | 10x lebih efisien jika memodifikasi >10% data sumber |
| Diaktifkan | Pembaruan terjadwal yang dijalankan sesuai permintaan atau pada interval | Dasbor, diperbarui per jam/hari | Keseimbangan biaya/keterlambatan yang baik. Mahal jika dijalankan pada interval <5 menit |
| Terus-menerus | Streaming real-time dengan latensi beberapa detik | Aplikasi langsung (biaya yang lebih tinggi karena komputasi khusus) | Jeda terendah, biaya tertinggi. Interval minimum 15 detik |
Mode Terpicu dan Berkelanjutan mengharuskan Umpan Data Perubahan (CDF) diaktifkan pada tabel sumber Anda. Jika CDF tidak diaktifkan, Anda akan melihat peringatan di UI dengan perintah yang tepat ALTER TABLE yang harus dijalankan. Untuk informasi lebih lanjut mengenai Change Data Feed, lihat Gunakan Change Data Feed Delta Lake di Databricks.
Contoh kasus penggunaan
ETL terbalik dengan Lakebase mendukung skenario operasional umum:
- Mesin personalisasi yang memerlukan profil pengguna baru yang disinkronkan ke Dalam Aplikasi Databricks
- Aplikasi yang melayani prediksi model atau nilai fitur yang dihitung di lakehouse
- Dasbor untuk pelanggan yang menampilkan indikator kinerja utama (KPI) secara waktu nyata
- Layanan deteksi penipuan yang memerlukan skor risiko yang tersedia untuk tindakan segera
- Perangkat dukungan yang memperkaya catatan pelanggan dengan data yang dikurasi dari lakehouse
Membuat tabel yang disinkronkan (UI)
Anda dapat membuat tabel yang disinkronkan di UI Databricks atau secara terprogram dengan SDK. Alur kerja UI diuraikan di bawah ini.
Prasyarat
Anda memerlukan:
- Ruang kerja Databricks yang mengaktifkan Lakebase.
- Proyek Lakebase (lihat Membuat proyek).
- Tabel Unity Catalog dengan data yang dikurasi.
- Izin untuk membuat tabel yang disinkronkan.
Untuk perencanaan kapasitas dan kompatibilitas jenis data, lihat Jenis data dan kompatibilitas dan Perencanaan kapasitas.
Langkah 1: Pilih tabel sumber Anda
Buka Katalog di bilah samping ruang kerja dan pilih tabel Katalog Unity yang ingin Anda sinkronkan.
Langkah 2: Aktifkan Ubah Umpan Data (jika diperlukan)
Jika Anda berencana menggunakan mode Sinkronisasi terpicu atau Berkelanjutan , tabel sumber Anda memerlukan Umpan Data Perubahan diaktifkan. Periksa apakah tabel Anda sudah mengaktifkan CDF, atau jalankan perintah ini di editor atau buku catatan SQL:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Ganti your_catalog.your_schema.your_table dengan nama tabel Anda yang sebenarnya.
Langkah 3: Membuat tabel yang disinkronkan
Klik Buat>tabel Yang Disinkronkan dari tampilan detail tabel.
Langkah 4: Mengonfigurasi
Dalam dialog Buat tabel yang disinkronkan :
- Nama tabel: Masukkan nama untuk tabel yang disinkronkan (dibuat dalam katalog dan skema yang sama dengan tabel sumber Anda). Ini membuat tabel yang disinkronkan dengan Katalog Unity dan tabel Postgres yang dapat Anda kueri.
- Jenis database: Pilih Lakebase Serverless (Autoscaling).
- Mode sinkronisasi: Pilih Rekam Jepret, Dipicu, atau Berkelanjutan berdasarkan kebutuhan Anda (lihat mode sinkronisasi di atas).
- Konfigurasikan pilihan proyek, cabang, dan database Anda.
- Verifikasi kunci Primer sudah benar (biasanya terdeteksi otomatis).
Jika Anda memilih mode Terpicu atau Berkelanjutan dan belum mengaktifkan Ubah Umpan Data, Anda akan melihat peringatan dengan perintah yang tepat untuk dijalankan. Untuk pertanyaan kompatibilitas jenis data, lihat Jenis dan kompatibilitas data.
Klik Buat untuk membuat tabel yang disinkronkan.
Langkah 5: Memantau
Setelah pembuatan, pantau tabel yang disinkronkan di Katalog. Tab Gambaran Umum memperlihatkan status sinkronisasi, konfigurasi, status alur, dan tanda waktu sinkronisasi terakhir. Gunakan Sinkronkan sekarang untuk refresh manual.
Jenis dan kompatibilitas data
Jenis data Unity Catalog dipetakan ke jenis Postgres saat membuat tabel yang disinkronkan. Jenis kompleks (ARRAY, MAP, STRUCT) disimpan sebagai JSONB di Postgres.
| Jenis kolom sumber | Jenis kolom Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | NUMERIK |
| dobel | PRESISI GANDA |
| FLOAT | WAKTU NYATA |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | TEKS |
| TIMESTAMP | PENANDA WAKTU DENGAN ZONA WAKTU |
| TIMESTAMP_NTZ | TANDA WAKTU TANPA ZONA WAKTU |
| TINYINT | SMALLINT |
| ARRAY<elemenTipe> | JSONB |
| MAP<keyType,valueType> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
Nota
Jenis GEOGRAFI, GEOMETRI, VARIAN, dan OBJEK tidak didukung.
Menangani karakter yang tidak valid
Karakter tertentu seperti byte null (0x00) diizinkan di kolom STRING, ARRAY, MAP, atau STRUCT pada Unity Catalog tetapi tidak didukung di kolom Postgres TEXT atau JSONB. Ini dapat menyebabkan kegagalan sinkronisasi dengan kesalahan seperti:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Solusi:
Membersihkan bidang string: Hapus karakter yang tidak didukung sebelum menyinkronkan. Untuk byte nol dalam kolom STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableKonversi ke BINARY: Untuk kolom STRING di mana mempertahankan byte mentah diperlukan, konversi ke jenis BINARY.
Pembuatan terprogram
Untuk alur kerja otomatisasi, Anda dapat membuat tabel yang disinkronkan secara terprogram menggunakan Databricks SDK, CLI, atau REST API.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.database import (
SyncedDatabaseTable,
SyncedTableSpec,
NewPipelineSpec,
SyncedTableSchedulingPolicy
)
# Initialize the Workspace client
w = WorkspaceClient()
# Create a synced table
synced_table = w.database.create_synced_database_table(
SyncedDatabaseTable(
name="lakebase_catalog.schema.synced_table", # Full three-part name
spec=SyncedTableSpec(
source_table_full_name="analytics.gold.user_profiles",
primary_key_columns=["user_id"], # Primary key columns
scheduling_policy=SyncedTableSchedulingPolicy.TRIGGERED, # SNAPSHOT, TRIGGERED, or CONTINUOUS
new_pipeline_spec=NewPipelineSpec(
storage_catalog="lakebase_catalog",
storage_schema="staging"
)
),
)
)
print(f"Created synced table: {synced_table.name}")
# Check the status of a synced table
status = w.database.get_synced_database_table(name=synced_table.name)
print(f"Synced table status: {status.data_synchronization_status.detailed_state}")
print(f"Status message: {status.data_synchronization_status.message}")
antarmuka baris perintah (CLI)
# Create a synced table
databricks database create-synced-database-table \
--json '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status of a synced table
databricks database get-synced-database-table "lakebase_catalog.schema.synced_table"
REST API
export WORKSPACE_URL="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-token"
# Create a synced table
curl -X POST "$WORKSPACE_URL/api/2.0/database/synced_tables" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
--data '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status
curl -X GET "$WORKSPACE_URL/api/2.0/database/synced_tables/lakebase_catalog.schema.synced_table" \
-H "Authorization: Bearer $DATABRICKS_TOKEN"
Perencanaan kapasitas
Saat merencanakan implementasi ETL terbalik Anda, pertimbangkan persyaratan sumber daya ini:
- Penggunaan koneksi: Setiap tabel yang disinkronkan menggunakan hingga 16 koneksi ke database Lakebase Anda, yang dihitung terhadap batas koneksi instans.
- Batas ukuran: Total batas ukuran data logis di semua tabel yang disinkronkan adalah 8 TB. Tabel individual tidak memiliki batas, tetapi Databricks merekomendasikan tidak melebihi 1 TB untuk tabel yang memerlukan refresh.
-
Persyaratan penamaan: Nama database, skema, dan tabel hanya boleh berisi karakter alfanumerik dan garis bawah (
[A-Za-z0-9_]+). - Evolusi skema: Hanya perubahan skema aditif (seperti menambahkan kolom) yang didukung untuk mode Dipicu dan Berkelanjutan.
- Laju pembaruan:: Untuk penskalaan otomatis Lakebase, alur sinkronisasi mendukung penulisan berkelanjutan dan dipicu pada sekitar 150 baris per detik per Unit Kapasitas (CU) dan penulisan snapshot hingga 2.000 baris per detik per Unit Kapasitas (CU).
Menghapus tabel yang disinkronkan
Untuk menghapus tabel yang disinkronkan, Anda harus menghapusnya dari Unity Catalog dan Postgres:
Hapus dari Katalog Unity: Di Katalog, temukan tabel yang disinkronkan, klik
 menu, dan pilih Hapus. Ini menghentikan refresh data tetapi meninggalkan tabel di Postgres.
menu, dan pilih Hapus. Ini menghentikan refresh data tetapi meninggalkan tabel di Postgres.Hapus dari Postgres: Sambungkan ke database Lakebase Anda dan hapus tabel untuk mengosongkan ruang.
DROP TABLE your_database.your_schema.your_table;
Anda dapat menggunakan editor SQL atau alat eksternal untuk menyambungkan ke Postgres.
Pelajari lebih lanjut
| Task | Description |
|---|---|
| Membuat proyek | Menyiapkan proyek Lakebase |
| Menyambungkan ke database Anda | Pelajari opsi koneksi untuk Lakebase |
| Mendaftarkan database di Katalog Unity | Membuat data Lakebase Anda terlihat di Unity Catalog untuk tata kelola terpadu dan kueri lintas sumber |
| Integrasi Katalog Unity | Memahami tata kelola dan izin |
Opsi lainnya
Untuk menyinkronkan data ke dalam sistem non-Databricks, lihat Solusi ETL terbalik Partner Connect seperti Sensus atau Hightouch.