Gunakan Apache Hive sebagai alat Ekstraksi, Transformasi, dan Pemuatan (ETL)
Anda biasanya perlu membersihkan dan mengubah data masuk sebelum memuatnya ke tujuan yang cocok untuk analitik. Operasi Ekstrak, Transformasi, dan Pemuatan (ETL) digunakan untuk menyiapkan data dan memuatnya ke tujuan data. Apache Hive di HDInsight dapat membaca dalam data yang tidak terstruktur, memproses data sesuai kebutuhan, dan memuat data ke gudang data terkait untuk sistem pendukung keputusan. Dalam pendekatan ini, data diekstraksi dari sumbernya. Kemudian, data disimpan dalam penyimpanan yang dapat disesuaikan, seperti blob Azure Storage atau Azure Data Lake Storage. Data kemudian ditransformasikan menggunakan urutan kueri Hive. Lalu, data mengalami penahapan dalam Hive sebagai persiapan untuk memuat massal ke penyimpanan data tujuan.
Ringkasan kasus penggunaan dan model
Gambar berikut menunjukkan gambaran umum kasus penggunaan dan model untuk otomatisasi ETL. Data input ditransformasikan untuk menghasilkan output yang sesuai. Selama transformasi, data mengubah bentuk, jenis data, dan bahkan bahasa. Proses ETL dapat mengonversi Imperial ke metrik, mengubah zona waktu, dan meningkatkan presisi agar selaras dengan data yang ada di tujuan. Proses ETL juga dapat menggabungkan data baru dengan data yang ada untuk terus menyediakan laporan terbaru, atau untuk memberikan wawasan lebih lanjut tentang data yang ada. Aplikasi seperti alat dan layanan pelaporan kemudian dapat menggunakan data ini dalam format yang diinginkan.
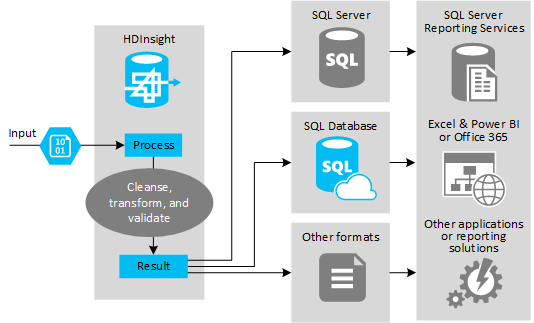
Hadoop biasanya digunakan dalam proses ETL yang mengimpor sejumlah besar file teks (seperti CSV). Atau, jumlah file teks yang lebih kecil tetapi sering berubah, atau keduanya. Hive adalah alat yang tepat untuk menyiapkan data sebelum memuatnya ke tujuan data. Hive memungkinkan Anda membuat skema melalui CSV dan menggunakan bahasa seperti SQL untuk menghasilkan program MapReduce yang berinteraksi dengan data.
Langkah-langkah khas untuk menggunakan Hive guna melakukan ETL adalah sebagai berikut:
Muat data ke Azure Data Lake Storage atau Azure Blob Storage.
Buat database Penyimpanan Metadata (menggunakan Azure SQL Database) untuk digunakan oleh Hive dalam menyimpan skema Anda.
Buat kluster HDInsight dan sambungkan penyimpanan data.
Tentukan skema untuk diterapkan saat waktu baca pada data di penyimpanan data:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Ubah data dan muat ke tujuan. Ada beberapa cara untuk menggunakan Hive selama transformasi dan pemuatan:
- Kueri dan siapkan data menggunakan Hive dan simpan sebagai CSV di Azure Data Lake Storage atau penyimpanan blob Azure. Kemudian, gunakan alat seperti SQL Server Integration Services (SSIS) untuk memperoleh CSV tersebut dan memuat data ke database terkait tujuan seperti SQL Server.
- Kueri data langsung dari Excel atau C# menggunakan driver Hive ODBC.
- Gunakan Apache Sqoop untuk membaca file CSV flat yang disiapkan dan memuatnya ke database terkait tujuan.
Sumber data
Sumber data biasanya merupakan data eksternal yang dapat dicocokkan dengan data yang sudah ada di penyimpanan data Anda, misalnya:
- Data media sosial, file log, sensor, dan aplikasi yang menghasilkan file data.
- Himpunan data yang diperoleh dari penyedia data, seperti statistik cuaca atau nomor penjualan vendor.
- Data streaming yang diambil, difilter, dan diproses melalui alat atau kerangka kerja yang sesuai.
Target output
Anda dapat menggunakan Hive untuk menghasilkan data ke berbagai jenis target termasuk:
- Database terkait, seperti SQL Server atau Database Azure SQL.
- Gudang data, seperti Azure Synapse Analytics.
- Excel.
- Tabel dan penyimpanan blob Azure.
- Aplikasi atau layanan yang mengharuskan data diproses ke format tertentu, atau sebagai file yang berisi jenis struktur informasi tertentu.
- Penyimpanan Dokumen JSON seperti Azure Cosmos DB.
Pertimbangan
Model ETL biasanya digunakan saat Anda ingin:
* Memuat data aliran atau volume data semi terstruktur atau tidak terstruktur yang besar dari sumber eksternal ke dalam database atau sistem informasi yang ada.
* Membersihkan, mengubah, dan memvalidasi data sebelum memuatnya, mungkin dengan menggunakan lebih dari satu transformasi yang melewati kluster.
* Menghasilkan laporan dan visualisasi yang diperbarui secara berkala. Misalnya, jika laporan terlalu lama dihasilkan pada siang hari, Anda dapat menjadwalkan laporan untuk berjalan di malam hari. Untuk menjalankan kueri Hive secara otomatis, Anda dapat menggunakan Azure Logic Apps and PowerShell.
Jika target untuk data bukan database, Anda dapat menghasilkan file dalam format yang sesuai dalam kueri, misalnya CSV. File ini kemudian dapat diimpor ke Excel atau Power BI.
Jika Anda perlu menjalankan beberapa operasi pada data sebagai bagian dari proses ETL, pertimbangkan cara Anda mengelolanya. Dengan operasi yang dikendalikan oleh program eksternal, bukan sebagai alur kerja dalam solusi, tentukan apakah beberapa operasi dapat dijalankan secara paralel. Dan untuk mendeteksi waktu setiap pekerjaan selesai. Menggunakan mekanisme alur kerja seperti Oozie dalam Hadoop mungkin lebih mudah daripada mencoba mengatur urutan operasi menggunakan skrip eksternal atau program kustom.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk