Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Ekstraksi, transformasi, dan pemuatan (ETL) adalah proses di mana data diperoleh dari berbagai sumber. Data dikumpulkan di lokasi standar, dibersihkan, dan diproses. Terakhir, data dimuat ke dalam penyimpanan data untuk bisa dikueri. ETL lama memproses data impor, membersihkannya secara lokal, kemudian menyimpannya di mesin data relasional. Dengan Azure HDInsight, berbagai komponen lingkungan Apache Hadoop mendukung ETL dalam skala besar.
Penggunaan HDInsight dalam proses ETL diringkas dalam alur berikut:
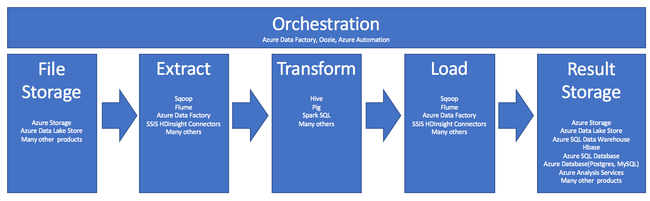
Bagian berikut menjelaskan masing-masing fase ETL beserta komponen-komponen terkait.
Orkestrasi
Orkestrasi mencakup semua fase alur ETL. Pekerjaan ETL dalam HDInsight sering melibatkan beberapa produk berbeda yang bekerja secara berdampingan. Contohnya:
- Anda dapat menggunakan Apache Hive untuk membersihkan sebagian data, dan Apache Pig untuk membersihkan sebagian yang lain.
- Anda dapat menggunakan Azure Data Factory untuk memuat data ke Azure SQL Database dari Azure Data Lake Store.
Orkestrasi diperlukan untuk menjalankan pekerjaan yang dibutuhkan pada waktu yang tepat.
Apache Oozie
Apache Oozie adalah sistem koordinasi alur kerja yang mengelola pekerjaan Hadoop. Oozie berjalan di dalam kluster HDInsight dan diintegrasikan dengan stack Hadoop. Oozie mendukung pekerjaan Hadoop untuk Apache MapReduce, Pig, Hive, dan Sqoop. Anda juga dapat menggunakan Oozie untuk menjadwalkan pekerjaan suatu sistem tertentu, seperti program Java atau skrip shell.
Untuk informasi selengkapnya, lihat Menggunakan Apache Oozie dengan Apache Hadoop untuk menentukan dan menjalankan alur kerja pada HDInsight. Lihat juga, Mengoperasionalkan alur data.
Azure Data Factory
Azure Data Factory menyediakan kemampuan orkestrasi dalam bentuk platform as a service (PaaS). Azure Data Factory adalah layanan integrasi data berbasis cloud. Layanan ini memungkinkan Anda membuat alur kerja berbasis data untuk mengatur dan mengotomatiskan pergerakan serta transformasi data.
Gunakan Azure Data Factory untuk:
- Membuat dan menjadwalkan alur kerja berbasis data. Alur ini menghimpun data dari penyimpanan data yang berbeda.
- Memroses dan mengubah data menggunakan layanan komputasi seperti HDInsight atau Hadoop. Anda juga dapat menggunakan Spark, Azure Data Lake Analytics, Azure Batch, atau Azure Machine Learning untuk langkah ini.
- Mempublikasikan data output ke penyimpanan data, seperti Azure Synapse Analytics, agar dapat digunakan aplikasi BI.
Untuk informasi selengkapnya tentang Azure Data Factory, lihat dokumentasi.
Penyimpanan file masukan dan penyimpanan hasil
File data sumber biasanya dimuat ke suatu lokasi di Azure Storage atau Azure Data Lake Storage. File biasanya berada dalam format datar, seperti CSV. Tetapi file bisa dalam format apa pun.
Azure Storage
Microsoft Azure Storage memiliki target kemampuan beradaptasi tertentu. Lihat Skalabilitas dan target kinerja untuk penyimpanan Blob untuk informasi selengkapnya. Untuk sebagian besar node analitik, penyekalaan Azure Storage mencapai optimal saat menangani banyak file berukuran kecil. Selama berada dalam batas akun Anda, Microsoft Azure Storage menjamin kinerja yang sama, tidak peduli seberapa besar file tersebut. Anda dapat menyimpan ber-terabyte data dan masih mendapatkan kinerja yang konsisten. : Pernyataan ini benar, baik Anda menggunakan subset atau semua data.
Microsoft Azure Storage memiliki beberapa jenis blob. Append blob adalah pilihan yang tepat untuk menyimpan log web atau data sensor.
Beberapa blob dapat didistribusikan di banyak server untuk memperluas skala aksesnya. Tetapi blob tunggal hanya dilayani oleh satu server. Meskipun blob dapat dikelompokkan secara logis dalam kontainer blob, tidak ada implikasi partisi dari pengelompokan ini.
Azure Storage memiliki lapisan API WebHDFS untuk penyimpanan blob. Semua layanan HDInsight dapat mengakses file di penyimpanan Azure Blob untuk pembersihan dan pemrosesan data. Aktivitas ini mirip dengan bagaimana layanan tersebut menggunakan Sistem File Terdistribusi Hadoop (HDFS).
Data biasanya dihimpun ke Azure Storage melalui PowerShell, Azure Storage SDK, atau AzCopy.
Azure Data Lake Storage
Azure Data Lake Storage adalah repositori hyperscale terkelola untuk data analitik. Sistem penyimpanan ini kompatibel dan menggunakan paradigma desain yang mirip dengan HDFS. Data Lake Storage menawarkan kemampuan beradaptasi tanpa batas untuk kapasitas total dan ukuran file individual. Ini adalah pilihan tepat ketika mengerjakan file berukuran besar, karena mereka dapat disimpan di beberapa node. Pemartisian data di Data Lake Storage dilakukan di belakang layar. Anda mendapatkan throughput besar-besaran untuk menjalankan pekerjaan analitik dengan ribuan eksekusi bersamaan yang secara efisien membaca dan menulis ratusan terabyte data.
Data biasanya terhimpun ke Dalam Data Lake Storage melalui Azure Data Factory. Anda juga dapat menggunakan SDK Data Lake Storage, layanan AdlCopy, Apache DistCp, atau Apache Sqoop. Layanan yang Anda pilih bergantung pada tempat data berada. Jika berada di kluster Hadoop yang sudah ada, Anda dapat menggunakan Apache DistCp, layanan AdlCopy, atau Azure Data Factory. Untuk data di penyimpanan Azure Blob, Anda dapat menggunakan SDK .NET Azure Data Lake Storage, Azure PowerShell, atau Azure Data Factory.
Data Lake Storage dioptimalkan untuk penyerapan peristiwa melalui Azure Event Hubs.
Pertimbangan untuk kedua opsi penyimpanan
Untuk mengunggah himpunan data dalam rentang terabyte, latensi jaringan bisa menjadi masalah utama. Masalah ini berlaku terutama jika data berasal dari lokasi lokal. Dalam kasus seperti itu, Anda dapat menggunakan opsi berikut:
Azure ExpressRoute: Buat koneksi pribadi antara pusat data Azure dan infrastruktur lokal Anda. Koneksi ini menyediakan opsi yang dapat diandalkan untuk mentransfer data dalam jumlah besar. Untuk informasi selengkapnya, lihat dokumentasi Azure ExpressRoute.
Pengunggahan data dari drive hard disk: Anda dapat menggunakan layanan Impor/Ekspor Azure untuk mengirim drive hard disk beserta data Anda ke pusat data Azure. Pertama-tama, data Anda diunggah ke penyimpanan Azure Blob. Anda kemudian dapat menggunakan Azure Data Factory atau alat AdlCopy untuk menyalin data dari penyimpanan Azure Blob ke Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analytics adalah pilihan yang tepat untuk menyimpan hasil yang disiapkan. Anda dapat menggunakan Azure HDInsight untuk melakukan layanan tersebut untuk Azure Synapse Analytics.
Azure Synapse Analytics adalah penyimpanan database relasional yang dioptimalkan untuk beban kerja analitik. Ini memerlukan skala berdasarkan tabel yang dipartisi. Tabel dapat dipartisi di beberapa node. Node dipilih pada saat pembuatan. Mereka dapat menskalakan setelah kejadian, tetapi itu adalah proses aktif yang mungkin memerlukan pergerakan data. Untuk informasi selengkapnya, lihat Mengelola komputasi di Azure Synapse Analytics.
Apache HBase
Apache HBase adalah penyimpanan kunci/nilai yang tersedia di Azure HDInsight. Ini adalah database NoSQL sumber terbuka yang dibangun di atas Hadoop dan dimodelkan berdasarkan Google BigTable. HBase menyediakan akses acak berkinerja dan konsistensi yang kuat untuk sejumlah besar data yang tidak terstruktur dan semi terstruktur.
Karena HBase adalah database tanpa skema, Anda tidak perlu menentukan kolom dan tipe data sebelum menggunakannya. Data disimpan dalam baris tabel, dan dikelompokkan menurut keluarga kolom.
Kode sumber terbuka menskalakan secara linier untuk menangani petabyte data pada ribuan simpul. HBase mengandalkan redundansi data, pemrosesan batch, dan fitur lain yang disediakan oleh aplikasi terdistribusi di lingkungan Hadoop.
HBase cocok untuk analisis data sensor dan log di masa mendatang.
Kemampuan beradaptasi HBase tergantung pada jumlah node di kluster HDInsight.
Database Azure SQL
Azure menawarkan tiga database relasional PaaS:
- Azure SQL Database yang merupakan implementasi dari Microsoft SQL Server. Untuk informasi selengkapnya tentang kinerja, lihat Penyetelan Kinerja di Azure SQL Database.
- Azure Database for MySQL adalah implementasi dari Oracle MySQL.
- Azure Database untuk PostgreSQL yang merupakan implementasi dari PostgreSQL.
Tambahkan lebih banyak CPU dan memori untuk meningkatkan skala produk-produk tersebut. Anda juga dapat memilih menggunakan disk premium beserta produk-produk tersebut untuk kinerja I/O yang lebih baik.
Azure Analysis Services
Azure Analysis Services adalah mesin data analitik yang digunakan dalam dukungan keputusan dan analitik bisnis. Mesin ini menyediakan data analitik untuk laporan bisnis dan aplikasi klien seperti Power BI. Data analitik juga berfungsi dengan Excel, laporan SQL Server Reporting Services, dan alat visualisasi data lainnya.
Skalakan kubus analisis dengan mengubah tingkatan untuk setiap kubus individu. Untuk informasi selengkapnya, lihat Harga Azure Analysis Services.
Ekstraksi dan pemuatan
Setelah data ada di Azure, Anda dapat menggunakan banyak layanan untuk mengekstrak dan memuatnya ke produk lain. HDInsight mendukung Sqoop dan Flume.
Apache Sqoop
Apache Sqoop adalah alat yang dirancang untuk mentransfer data secara efisien antara sumber data terstruktur, semi terstruktur, dan tidak terstruktur.
Sqoop menggunakan MapReduce untuk mengimpor dan mengekspor data, untuk memberikan operasi paralel dan toleransi kesalahan.
Apache Flume
Apache Flume adalah layanan terdistribusi, andal, dan tersedia untuk mengumpulkan, menggabungkan, dan memindahkan data log dalam jumlah besar secara efisien. Arsitekturnya yang fleksibel dibuat berdasarkan aliran data streaming. Flume bersifat kokoh dan toleran terhadap kesalahan dengan mekanisme keandalan yang dapat disetel. Ini memiliki banyak mekanisme failover dan pemulihan. Flume menggunakan model data yang dapat diperluas secara sederhana yang memungkinkan aplikasi analitik online.
Apache Flume tidak dapat digunakan dengan Azure HDInsight. Tetapi instalasi Hadoop lokal dapat menggunakan Flume untuk mengirim data ke penyimpanan Azure Blob atau Azure Data Lake Storage. Untuk informasi selengkapnya, lihat Menggunakan Apache Flume dengan HDInsight.
Transformasi
Setelah data ada di lokasi yang dipilih, Anda perlu membersihkannya, menggabungkannya, atau menyiapkannya untuk pola penggunaan tertentu. Apache Hive, Pig, dan Spark SQL adalah pilihan yang cocok untuk pekerjaan semacam itu. Mereka semua didukung di HDInsight.