Menskalakan kluster Azure HDInsight secara manual
HDInsight menyediakan fleksibilitas dengan beberapa opsi untuk meningkatkan dan menurunkan jumlah simpul pekerja dalam kluster Anda. Fleksibilitas ini memungkinkan Anda untuk memperkecil kluster setelah jam kerja atau pada akhir pekan. Juga memperluasnya saat permintaan bisnis memuncak.
Tingkatkan skala kluster Anda sebelum pemrosesan batch berkala agar kluster memiliki sumber daya yang memadai. Setelah pemrosesan selesai dan penggunaan menurun, turunkan skala kluster HDInsight ke simpul pekerja yang lebih sedikit.
Anda dapat menskalakan kluster secara manual menggunakan salah satu metode berikut. Anda juga dapat menggunakan opsi skala otomatis untuk meningkatkan dan menurunkan skala secara otomatis sebagai respons terhadap metrik tertentu.
Catatan
Hanya kluster dengan HDInsight versi 3.1.3 atau lebih tinggi yang didukung. Jika Anda tidak yakin dengan versi kluster Anda, Anda dapat memeriksa halaman Properti.
Utilitas untuk menskalakan kluster
Microsoft menyediakan utilitas berikut untuk menskalakan kluster:
| Utilitas | Deskripsi |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Azure Classic CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Portal Azure | Buka panel kluster HDInsight Anda, pilih Ukuran kluster pada menu sebelah kiri, lalu pada panel Ukuran kluster, ketik jumlah simpul pekerja, dan pilih Simpan. |
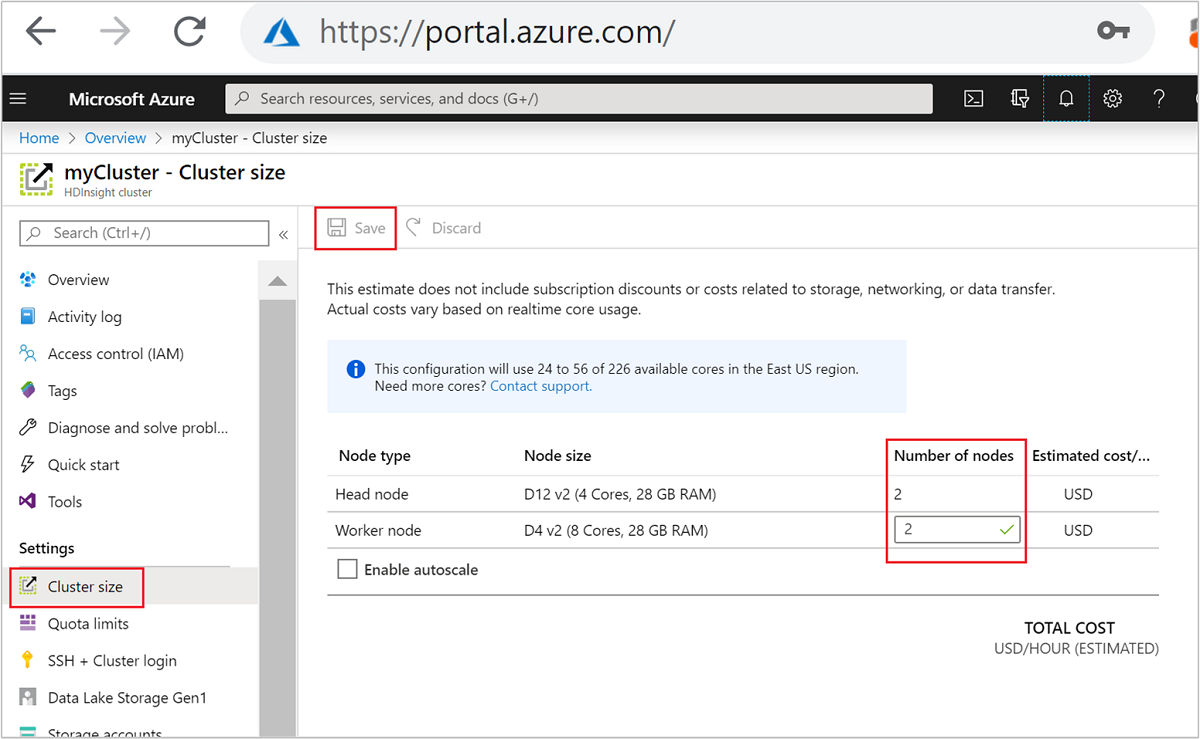
Dengan menggunakan salah satu metode ini, Anda dapat menaikkan atau menurunkan skala kluster HDInsight Anda dalam hitungan menit.
Penting
Dampak operasi penskalaan
Saat Anda menambahkan simpul ke kluster HDInsight yang sedang berjalan (meningkatkan skala), pekerjaan tetap tidak terpengaruh. Pekerjaan baru dapat dikirimkan dengan aman meski proses penskalaan sedang berjalan. Jika operasi penskalaan gagal, kegagalan meninggalkan kluster Anda dalam status fungsi.
Jika Anda menghapus simpul (menurunkan skala), pekerjaan yang tertunda atau berjalan gagal saat operasi penskalan selesai. Kegagalan ini terjadi karena beberapa layanan dimulai ulang selama proses penskalaan. Kluster Anda dapat terjebak dalam mode aman selama operasi penskalaan manual.
Dampak dari perubahan jumlah simpul data beragam untuk setiap jenis kluster yang didukung oleh HDInsight:
Apache Hadoop
Anda dapat dengan lancar meningkatkan jumlah simpul pekerja dalam kluster Hadoop yang sedang berjalan tanpa memengaruhi pekerjaan apa pun. Pekerjaan baru juga dapat dikirimkan saat operasi sedang berlangsung. Kegagalan dalam operasi penskalaan ditangani dengan baik. Kluster selalu dibiarkan dalam keadaan fungsional.
Ketika kluster Hadoop diturunkan dengan simpul data yang lebih sedikit, beberapa layanan dimulai ulang. Perilaku ini menyebabkan semua pekerjaan yang berjalan dan tertunda menjadi gagal saat penyelesaian operasi penskalaan. Namun, Anda dapat mengirim ulang pekerjaan setelah operasi selesai.
Apache HBase
Anda dapat dengan lancar menambahkan atau menghapus simpul ke kluster HBase saat perangkat sedang berjalan. Layanan Wilayah secara otomatis diseimbangkan dalam beberapa menit setelah penyelesaian operasi penskalaan. Namun, Anda dapat menyeimbangkan server regional secara manual. Masuklah ke headnode kluster dan jalankan perintah berikut:
pushd %HBASE_HOME%\bin hbase shell balancerUntuk informasi selengkapnya tentang penggunaan shell HBase, lihat Memulai dengan contoh Apache HBase dalam HDInsight.
Catatan
Tidak dapat digunakan untuk kluster Kafka.
Apache Hive LLAP
Setelah menskalakan ke
Nsimpul pekerja, HDInsight secara otomatis mengatur konfigurasi berikut dan memulai ulang Apache Hive.- Kueri Bersamaan Total Maksimum:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Jumlah simpul yang digunakan oleh LLAP Apache Hive:
num_llap_nodes = N - Jumlah Simpul untuk menjalankan daemon Apache Hive LLAP:
num_llap_nodes_for_llap_daemons = N
- Kueri Bersamaan Total Maksimum:
Cara menurunkan skala kluster dengan aman
Menurunkan skala kluster dengan pekerjaan yang sedang berjalan
Untuk menghindari kegagalan pekerjaan yang sedang berjalan selama operasi menurunkan skala, Anda dapat mencoba tiga hal:
- Tunggu hingga pekerjaan selesai sebelum menurunkan skala kluster Anda.
- Akhiri pekerjaan Anda secara manual.
- Kirim ulang pekerjaan setelah operasi penskalaan berakhir.
Untuk melihat daftar tugas yang tertunda dan berjalan, Anda bisa menggunakan YARN Resource Manager UI, dengan mengikuti langkah-langkah berikut:
Dari portal Microsoft Azure, pilih kluster Anda. Kluster ini dibuka di halaman portal baru.
Dari tampilan utama, navigasikan ke Dasbor kluster > Beranda Ambari. Masukkan informasi masuk kluster Anda.
Dari Ambari UI, pilih YARN pada daftar layanan di menu sebelah kiri.
Dari halaman YARN, pilih Tautan Cepat dan arahkan kursor ke headnode aktif, lalu pilih Resource Manager UI.
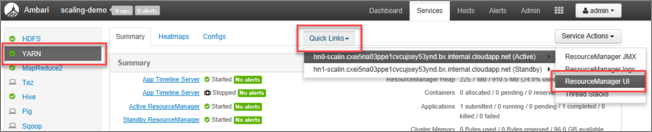
Anda dapat langsung mengakses Resource Manager UI dengan https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Anda melihat daftar pekerjaan, bersama dengan statusnya saat ini. Di cuplikan layar, ada satu pekerjaan yang sedang berjalan:
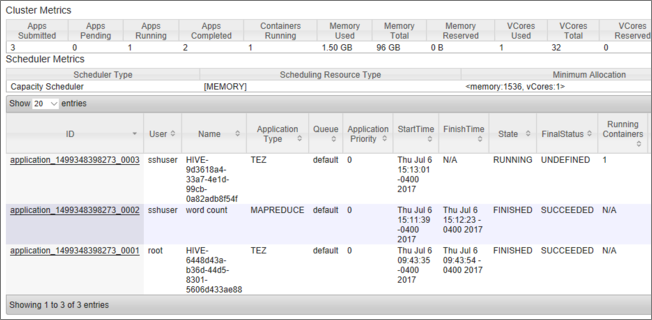
Untuk mematikan aplikasi yang sedang berjalan secara manual, jalankan perintah berikut dari shell SSH:
yarn application -kill <application_id>
Contohnya:
yarn application -kill "application_1499348398273_0003"
Terjebak di dalam mode aman
Saat Anda menurunkan skala kluster, HDInsight akan menggunakan antarmuka manajemen Apache Ambari untuk terlebih dahulu menonaktifkan simpul pekerja tambahan. Simpul akan mereplikasi blok HDFS mereka ke simpul pekerja online lainnya. Setelah itu, HDInsight akan dengan aman menurunkan skala kluster. HDFS masuk ke mode aman selama operasi penskalaan. HDFS harus keluar setelah penskalaan selesai. Namun, dalam beberapa kasus, HDFS terjebak dalam mode aman selama operasi penskalaan karena kurangnya replikasi blok file.
Secara default, HDFS dikonfigurasi dengan dfs.replication pengaturan 1, yang mengontrol berapa banyak salinan yang tersedia untuk setiap blok file. Setiap salinan blok file disimpan pada simpul kluster yang berbeda.
Saat jumlah salinan blok yang diharapkan tidak terpenuhi, HDFS memasuki mode aman dan Ambari mengeluarkan peringatan. HDFS dapat memasuki mode aman untuk operasi penskalaan. Kluster dapat terjebak dalam mode aman jika jumlah simpul yang diperlukan tidak terdeteksi untuk replikasi.
Contoh kesalahan saat mode aman diaktifkan
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Anda dapat meninjau log simpul nama dari folder /var/log/hadoop/hdfs/, mendekati waktu saat kluster diskalakan, untuk melihat kapan kluster tersebut memasuki mode aman. File log diberi nama Hadoop-hdfs-namenode-<active-headnode-name>.*.
Penyebab utamanya adalah Apache Hive bergantung pada file sementara dalam HDFS saat menjalankan kueri. Saat HDFS memasuki mode aman, Apache Hive tidak dapat menjalankan kueri karena tidak dapat menulis ke HDFS. File sementara dalam HDFS terletak dalam drive lokal yang dipasang ke simpul pekerja individu VM. File direplikasi di antara simpul pekerja lainnya dengan jumlah minimal tiga replika.
Cara mencegah HDInsight terjebak dalam mode aman
Ada beberapa cara untuk mencegah HDInsight dibiarkan dalam mode aman:
- Hentikan semua pekerjaan Apache Hive sebelum menurunkan skala HDInsight. Atau, jadwalkan proses penurunan skala untuk mencegah terjadinya konflik dengan pekerjaan Apache Hive yang sedang berjalan.
- Bersihkan file direktori
tmpscratch Apache Hive secara manual dalam HDFS sebelum menurunkan skala. - Hanya turunkan skala HDInsight ke minimal tiga simpul pekerja. Hindari menjalankan skala senilai satu simpul pekerja.
- Jalankan perintah untuk meninggalkan mode aman, jika diperlukan.
Bagian berikut menjelaskan opsi ini.
Menghentikan semua pekerjaan Apache Hive
Hentikan semua pekerjaan Apache Hive sebelum menurunkan skala ke satu simpul pekerja. Jika beban kerja Anda dijadwalkan, maka lakukan penurunan skala setelah pekerjaan Apache Hive tidak berfungsi.
Hentikan pekerjaan Apache Hive sebelum penskalaan, membantu meminimalkan jumlah file goresan di folder tmp (jika ada).
Bersihkan file scratch Apache Hive secara manual
Jika Apache Hive telah meninggalkan file sementara, maka Anda dapat membersihkan file tersebut secara manual sebelum menurunkan skala untuk menghindari mode aman.
Periksa lokasi mana yang digunakan untuk file sementara Apache Hive dengan melihat
hive.exec.scratchdirproperti konfigurasi. Parameter ini diatur dalam/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Hentikan layanan Apache Hive dan pastikan semua kueri dan pekerjaan selesai.
Cantumkan konten direktori scratch yang ditemukan di atas dalam daftar,
hdfs://mycluster/tmp/hive/untuk melihat apakah berisi file:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveBerikut adalah output sampel saat file ada:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoJika Anda mengetahui bahwa Apache Hive tidak memerlukan file ini lagi, Anda dapat menghapusnya. Pastikan bahwa Apache Hive tidak memiliki kueri yang sedang berjalan dengan melihat di halaman Yarn Resource Manager UI.
Contoh baris perintah untuk menghapus file dari HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Skalakan HDInsight ke tiga atau lebih simpul pekerja
Jika kluster sering terjebak dalam mode aman saat penurunan skala ke kurang dari tiga simpul pekerja, maka pertahankan setidaknya tiga simpul pekerja.
Memiliki tiga simpul pekerja lebih mahal dibandingkan menurunkan skala ke hanya satu simpul pekerja. Namun, tindakan ini mencegah kluster Anda terjebak dalam mode aman.
Menurunkan skala HDInsight ke satu simpul pekerja
Bahkan ketika kluster diturunkan ke satu node, simpul pekerja 0 masih bertahan hidup. Simpul pekerja 0 tidak pernah bisa dinonaktifkan.
Menjalankan perintah untuk meninggalkan mode aman
Opsi terakhir adalah menjalankan perintah untuk meninggalkan mode aman. Jika HDFS memasuki mode aman karena kurangnya replikasi file Apache Hive, jalankan perintah berikut untuk meninggalkan mode aman:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Turunkan skala kluster Apache HBase
Server wilayah secara otomatis diseimbangkan dalam beberapa menit setelah penyelesaian operasi penskalaan. Untuk menyeimbangkan server wilayah secara manual, selesaikan langkah-langkah berikut ini:
Sambungkan ke kluster HDInsight menggunakan SSH. Untuk informasi selengkapnya, lihat Menggunakan SSH dengan HDInsight.
Jalankan shell HBase:
hbase shellGunakan perintah berikut ini untuk menyeimbangkan server wilayah secara manual:
balancer
Langkah berikutnya
Untuk informasi lebih lanjut tentang penskalaan kluster HDInsight Anda, lihat: