Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda akan belajar tentang cara menggunakan Jupyter Notebook untuk membangun aplikasi pembelajaran mesin Apache Spark untuk Azure HDInsight.
MLlib adalah pustaka pembelajaran mesin Spark yang dapat beradaptasi dan terdiri dari algoritma serta utilitas pembelajaran umum. (Klasifikasi, regresi, pengklusteran, pemfilteran kolaboratif, dan pengurangan dimensi. Selain itu, dasar pengoptimalan primitif.)
Dalam tutorial ini, Anda akan mempelajari cara:
- Mengembangkan aplikasi pembelajaran mesin Apache Spark
Prasyarat
Klaster Apache Spark pada HDInsight. Lihat Buat kluster Apache Spark.
Terbiasa menggunakan Jupyter Notebooks dengan Spark di Microsoft Azure HDInsight. Untuk informasi selengkapnya, lihat Muat data dan menjalankan kueri dengan Apache Spark di Microsoft Azure HDInsight.
Memahami himpunan data
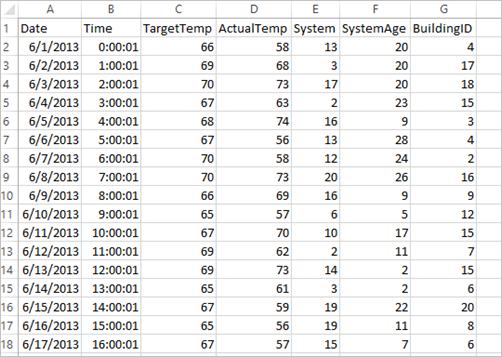
Aplikasi ini menggunakan contoh data HVAC.csv yang secara default tersedia di semua kluster. File ini terletak di \HdiSamples\HdiSamples\SensorSampleData\hvac. Data menunjukkan suhu target dan suhu aktual beberapa bangunan yang memasang sistem HVAC. Kolom Sistem mewakili ID sistem dan kolom SystemAge menunjukkan jumlah tahun diberlakukannya sistem HVAC di bangunan. Anda dapat memprediksi apakah sebuah bangunan akan menjadi lebih panas atau lebih dingin berdasarkan suhu target, ID sistem yang diberikan, dan usia sistem.
Mengembangkan aplikasi pembelajaran mesin Spark menggunakan Spark MLlib
Aplikasi ini menggunakan alur Pembelajaran Mesin Spark untuk melakukan klasifikasi dokumen. Alur Pembelajaran Mesin menyediakan set API tingkat tinggi yang seragam dan dibangun di atas DataFrame. DataFrame membantu pengguna membuat dan menyelaraskan alur pembelajaran mesin praktis. Di dalam alur, Anda membagi dokumen menjadi kata, mengonversi kata menjadi vektor fitur numerik, dan akhirnya membangun model prediksi menggunakan vektor dan label fitur. Lakukan langkah-langkah berikut untuk membuat aplikasi.
Buat Jupyter Notebook menggunakan kernel PySpark. Untuk instruksinya, lihat Membuat file Jupyter Notebook.
Impor jenis yang diperlukan untuk skenario ini. Tempelkan cuplikan berikut dalam sel kosong, lalu tekan SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayMuat data (hvac.csv), pilah, dan gunakan untuk melatih model.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Dalam cuplikan kode, Anda mendefinisikan fungsi yang membandingkan suhu aktual dengan suhu target. Jika suhu aktual lebih besar, berarti suhu bangunan panas, ditandai dengan nilai 1.0. Jika tidak, suhu bangunan dingin, ditandai dengan nilai 0,0.
Konfigurasikan alur pembelajaran mesin Spark yang terdiri dari tiga tahap:
tokenizer, ,hashingTFdanlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Untuk informasi selengkapnya tentang alur dan cara kerjanya, lihat Alur pembelajaran mesin Apache Spark.
Sesuaikan alur ke dokumen pelatihan.
model = pipeline.fit(training)Verifikasi dokumen pelatihan untuk menilai kemajuan Anda dengan aplikasi.
training.show()Output mirip dengan:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Membandingkan output dengan file CSV mentah. Misalnya, baris pertama file CSV memiliki data berikut ini:

Perhatikan bagaimana suhu sebenarnya kurang dari suhu target yang menunjukkan bahwa suhu bangunan dingin. Nilai untuk label di baris pertama adalah 0,0, yang berarti bangunan tidak panas.
Siapkan himpunan data untuk menjalankan model terlatih sebagai perbandingan. Untuk melakukannya, Anda perlu meneruskan ID sistem dan usia sistem (ditandai sebagai SystemInfo dalam output pelatihan). Model memprediksi apakah bangunan dengan ID sistem dan usia sistem tersebut akan menjadi lebih panas (ditandai dengan 1,0) atau lebih dingin (ditandai dengan 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Terakhir, buat prediksi pada data pengujian.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Output mirip dengan:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Amati baris pertama dalam prediksi. Untuk sistem HVAC dengan ID 20 dan usia sistem 25 tahun, bangunan ini tergolong panas(prediksi=1,0). Nilai pertama untuk DenseVector (0,49999) sesuai dengan prediksi 0,0 dan nilai kedua (0,5001) sesuai dengan prediksi 1,0. Dalam output, meskipun nilai kedua hanya sedikit lebih tinggi, model menunjukkan prediksi=1,0.
Matikan notebook untuk membebaskan sumber daya. Untuk melakukannya, dari menu File pada notebook, pilih Tutup dan Hentikan. Tindakan ini akan mematikan dan menutup buku catatan.
Gunakan pustaka Anaconda scikit-learn untuk pembelajaran mesin Spark
Kluster Apache Spark pada HDInsight mencakup pustaka Anaconda. Pustaka ini juga mencakup pustaka scikit-learn untuk pembelajaran mesin. Pustaka ini juga menyertakan berbagai himpunan data yang dapat Anda gunakan untuk membangun aplikasi sampel langsung dari Jupyter Notebook. Sebagai contoh penggunaan pustaka scikit-learn, lihat https://scikit-learn.org/stable/auto_examples/index.html.
Membersihkan sumber daya
Jika Anda tidak akan terus menggunakan aplikasi ini, hapus kluster yang Anda buat dengan langkah-langkah berikut:
Masuk ke portal Azure.
Dalam kotak Pencarian di bagian atas, ketik Microsoft Azure HDInsight.
Pilih kluster Microsoft Azure HDInsight di Layanan.
Dalam daftar kluster HDInsight yang muncul, pilih ... di samping kluster yang Anda buat untuk tutorial ini.
Pilih Hapus. Pilih Ya.
Langkah berikutnya
Dalam tutorial ini, Anda akan belajar tentang cara menggunakan Jupyter Notebook untuk membangun aplikasi pembelajaran mesin Apache Spark untuk Azure HDInsight. Lanjutkan ke tutorial berikutnya untuk mempelajari cara menggunakan IntelliJ IDEA untuk pekerjaan Spark.