Men-debug pekerjaan Apache Spark yang berjalan di Azure HDInsight
Dalam artikel ini, Anda mempelajari cara melacak dan men-debug pekerjaan Apache Spark yang berjalan pada klaster HDInsight. Men-debug menggunakan Apache Hadoop YARN UI, Spark UI, dan Spark History Server. Anda memulai pekerjaan Spark menggunakan notebook yang tersedia dengan klaster Spark, Pembelajaran mesin: Analisis prediktif pada data inspeksi makanan menggunakan MLLib. Gunakan langkah-langkah berikut untuk melacak aplikasi yang Anda kirimkan menggunakan pendekatan lain juga, contohnya, spark-submit.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
Anda harus sudah mulai menjalankan notebook, Pembelajaran mesin: Analisis prediktif pada data inspeksi makanan menggunakan MLLib. Untuk instruksi tentang cara menjalankan notebook ini, ikuti tautan.
Melacak aplikasi di YARN UI
Luncurkan YARN UI. Pilih Yarn di bawah Dasbor klaster.
Tip
Atau, Anda juga dapat meluncurkan YARN UI dari Ambari UI. Untuk meluncurkan Ambari UI, pilih Beranda Ambari di bawah Dasbor klaster. Dari Ambari UI, arahkan ke YARN>Link Cepat> Resource Manager aktif >Resource Manager UI.
Karena Anda memulai pekerjaan Spark menggunakan Jupyter Notebook, aplikasi memiliki nama remotesparkmagics (nama untuk semua aplikasi yang dimulai dari notebook). Pilih ID aplikasi terhadap nama aplikasi untuk mendapatkan informasi selengkapnya tentang pekerjaan. Tindakan ini meluncurkan tampilan aplikasi.
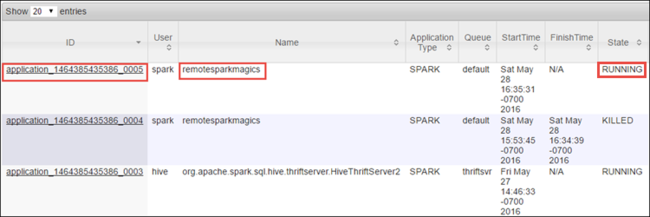
Untuk aplikasi yang diluncurkan dari Jupyter Notebook, status selalu berada dalam BERJALAN sampai Anda keluar dari notebook.
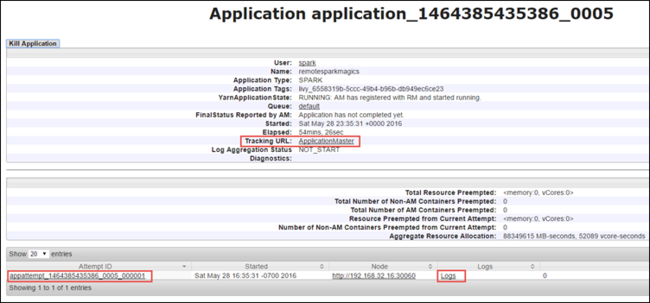
Dari tampilan aplikasi, Anda dapat menelusuri lebih jauh untuk mengetahui kontainer yang terkait dengan aplikasi dan log (stdout/stderr). Anda juga dapat meluncurkan Spark UI dengan mengeklik penautan yang sesuai dengan URL Pelacakan, seperti yang ditunjukkan di bawah ini.
Melacak aplikasi di Spark UI
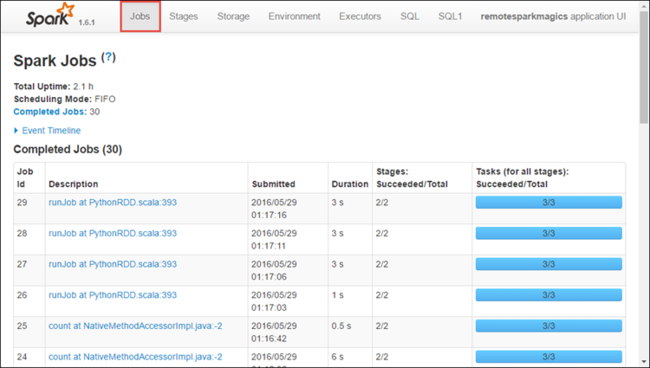
Di Spark UI, Anda dapat menelusuri pekerjaan Spark yang diluncurkan oleh aplikasi yang Anda mulai sebelumnya.
Untuk meluncurkan Spark UI, dari tampilan aplikasi, pilih tautan terhadap URL Pelacakan, seperti yang ditunjukkan pada tangkapan layar di atas. Anda dapat melihat semua pekerjaan Spark yang diluncurkan oleh aplikasi yang berjalan di Jupyter Notebook.
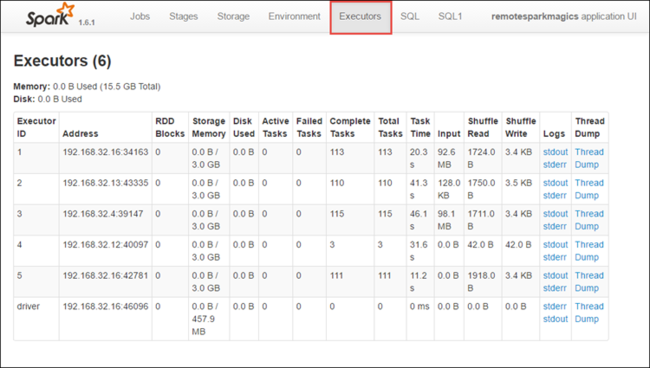
Pilih tab Eksekutor untuk melihat informasi pemrosesan dan penyimpanan untuk setiap eksekutor. Anda juga dapat mengambil tumpukan panggilan dengan memilih tautan Cadangan Rangkaian.
Pilih tab Tahapan untuk melihat tahapan yang terkait dengan aplikasi.
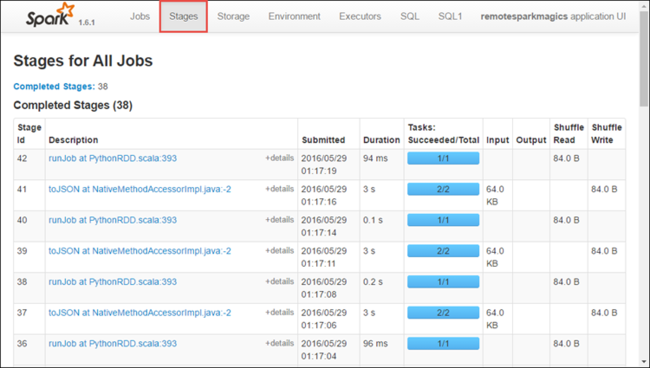
Setiap tahap dapat memiliki beberapa tugas yang dapat Anda lihat statistik eksekusinya, seperti yang ditunjukkan di bawah ini.
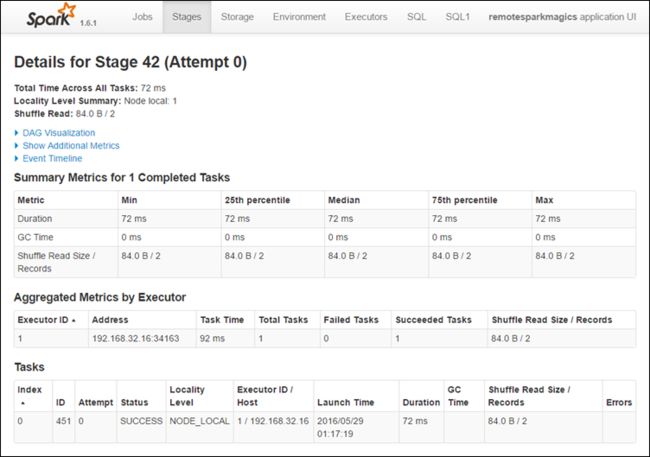
Dari halaman rincian tahapan, Anda dapat meluncurkan DAG Visualization. Perluas link DAG Visualization di bagian atas halaman, seperti yang ditunjukkan di bawah ini.
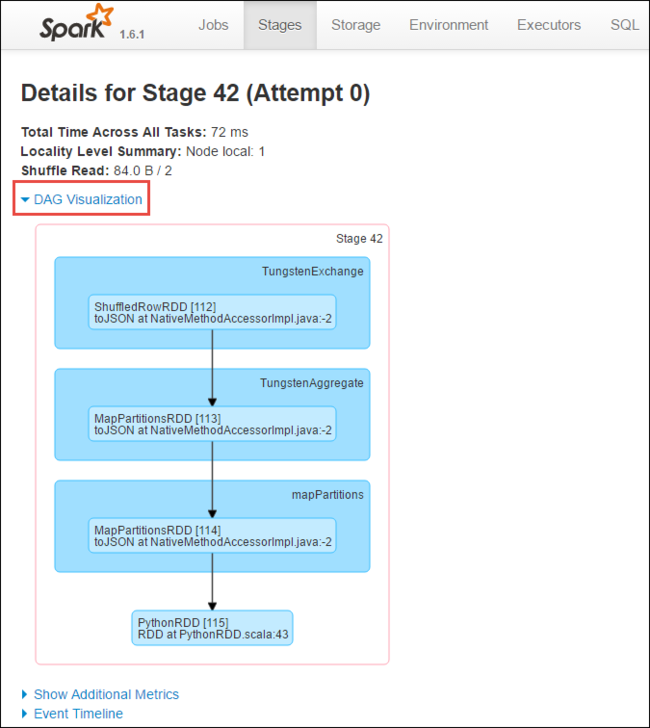
DAG atau Direct Aclyic Graph mewakili berbagai tahapan dalam aplikasi. Setiap kotak biru dalam grafik mewakili operasi Spark yang dipanggil dari aplikasi.
Dari halaman rincian tahapan, Anda juga dapat meluncurkan tampilan linimasa aplikasi. Perluas link Linimasa Peristiwa di bagian atas halaman, seperti yang ditunjukkan di bawah ini.
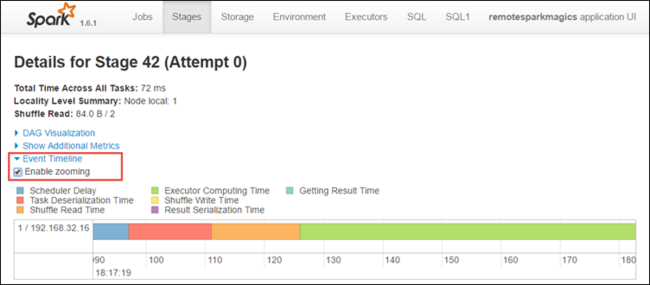
Gambar ini menampilkan peristiwa Spark dalam bentuk linimasa. Tampilan linimasa tersedia pada tiga tingkat, di seluruh pekerjaan, dalam pekerjaan, dan dalam tahapan. Gambar di atas menangkap tampilan linimasa untuk tahapan tertentu.
Tip
Jika Anda memilih kotak centang Aktifkan pembesaran, Anda bisa menggulir ke kiri dan kanan melintasi tampilan linimasa.
Tab lain di Spark UI juga menyediakan informasi yang berguna tentang instans Spark.
- Tab Penyimpanan - Jika aplikasi Anda membuat RDD, Anda dapat menemukan informasi di tab Penyimpanan.
- Tab Lingkungan - Tab ini menyediakan informasi yang berguna tentang instans Spark Anda seperti:
- Versi Scala
- Direktori log peristiwa yang terkait dengan klaster
- Jumlah inti eksekutor untuk aplikasi
Menemukan informasi tentang pekerjaan yang diselesaikan menggunakan Spark History Server
Setelah pekerjaan selesai, informasi tentang pekerjaan tetap ada di Spark History Server.
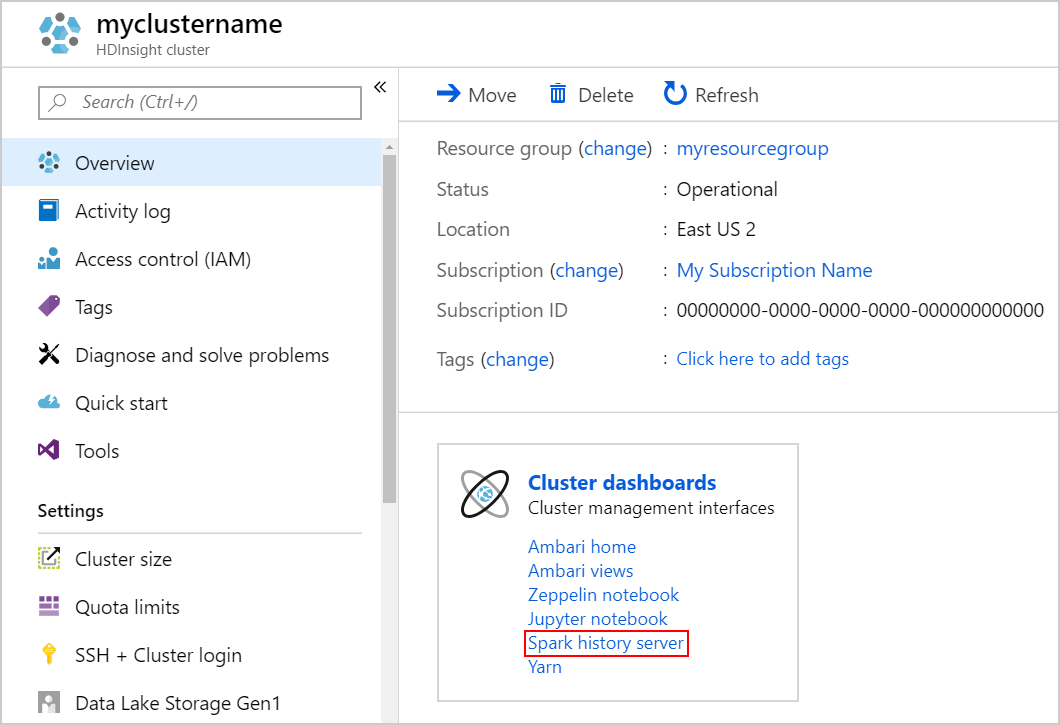
Untuk meluncurkan Spark History Server, dari halaman Ikhtisar, pilih Spark history server di bawah Dasbor klaster.
Tip
Atau, Anda juga dapat meluncurkan Spark History Server UI dari Ambari UI. Untuk meluncurkan Ambari UI, dari bilah Ikhtisar, pilih Beranda Ambari di bawah Dasbor klaster. Dari Ambari UI, arahkan ke Spark2>Tautan Cepat>Spark2 History Server UI.
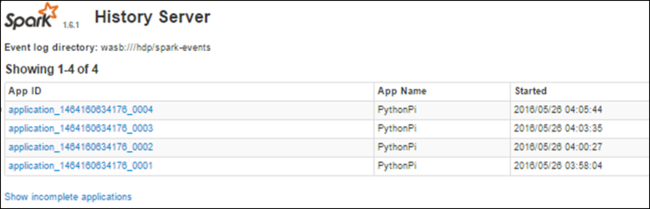
Anda melihat semua aplikasi yang telah selesai tercantum. Pilih ID aplikasi untuk menelusuri ke dalam aplikasi untuk informasi selengkapnya.
Lihat juga
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk