Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara mengakses antarmuka seperti Apache Ambari UI, Apache Hadoop YARN UI, dan Spark History Server yang terkait dengan kluster Apache Spark Anda, dan cara menyetel konfigurasi kluster untuk kinerja optimal.
Membuka Spark History Server
Spark History Server adalah UI web untuk aplikasi Spark yang sudah selesai maupun masih berjalan. Ia merupakan perpanjangan dari Spark Web UI. Untuk informasi selengkapnya, lihat Spark History Server.
Membuka Yarn UI
Anda dapat menggunakan YARN UI untuk memantau aplikasi yang saat ini berjalan pada kluster Spark.
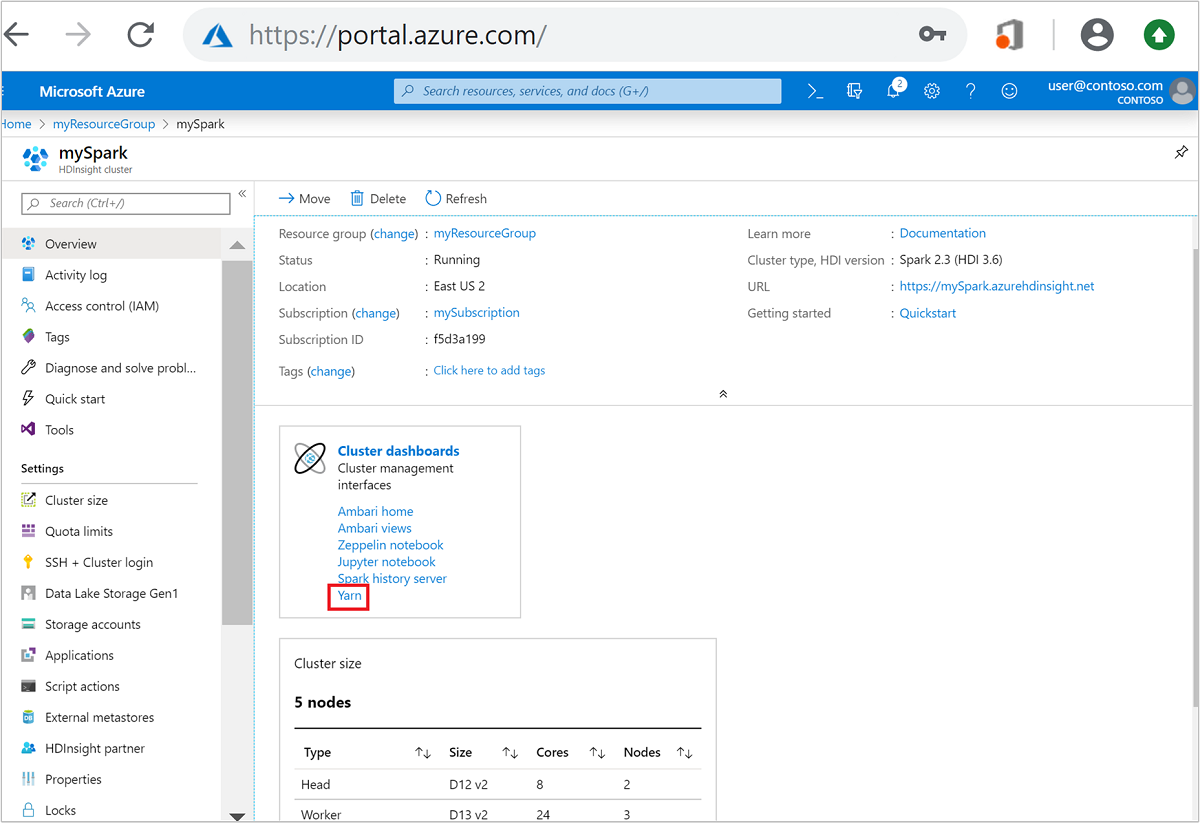
Dari portal Azure, buka kluster Spark. Untuk informasi selengkapnya, lihat Cantumkan dan tunjukkan kluster.
Dari dasbor Kluster, pilih Yarn. Saat diminta, masukkan info masuk admin untuk kluster Spark.
Tips
Atau, Anda juga dapat meluncurkan YARN UI dari Ambari UI. Dari Ambari UI, arahkan ke YARN>Tautan Cepat>Aktif>Resource Manager UI.
Mengoptimalkan kluster untuk aplikasi Spark
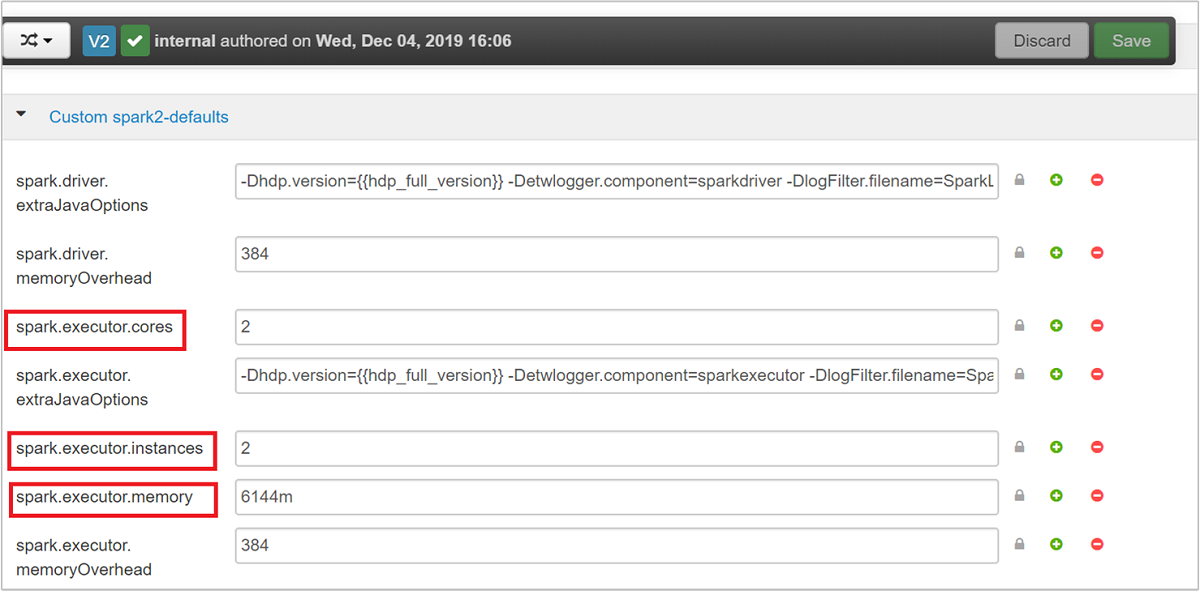
Tiga parameter utama yang dapat digunakan untuk konfigurasi Spark, tergantung dari kebutuhan aplikasi, adalah spark.executor.instances, spark.executor.cores, dan spark.executor.memory. Executor adalah proses yang diluncurkan untuk aplikasi Spark. Ini beroperasi pada simpul pekerja dan bertanggung jawab untuk melaksanakan tugas-tugas aplikasi. Jumlah default eksekutor dan ukuran eksekutor untuk setiap kluster dihitung berdasarkan jumlah simpul pekerja dan ukuran simpul pekerja. Informasi ini disimpan di spark-defaults.conf pada node kepala kluster.
Ketiga parameter konfigurasi ini dapat dikonfigurasi pada tingkat kluster (untuk semua aplikasi yang berjalan pada kluster) dan juga ditentukan untuk setiap aplikasi individu.
Mengubah parameter menggunakan Ambari UI
Dari UI Ambari, buka Spark 2>Konfigurasi>Kustom spark2-defaults.
Nilai default dirancang untuk memungkinkan empat aplikasi Spark berjalan bersamaan pada kluster. Anda bisa mengubah nilai ini dari antarmuka pengguna, seperti yang ditampilkan dalam cuplikan layar berikut:
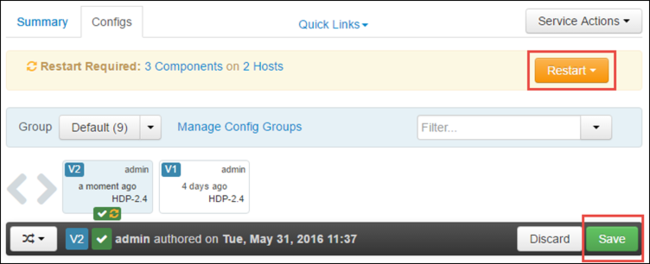
Pilih Simpan untuk menyimpan perubahan konfigurasi. Di bagian atas halaman, Anda diminta untuk memulai ulang semua layanan yang terdampak. Pilih Hidupkan ulang.
Mengubah parameter untuk aplikasi yang berjalan di Jupyter Notebook
Untuk aplikasi yang berjalan di Jupyter Notebook, Anda dapat menggunakan keajaiban %%configure untuk membuat perubahan konfigurasi. Idealnya, Anda harus membuat perubahan tersebut di awal aplikasi, sebelum Anda menjalankan sel kode pertama Anda. Melakukan hal ini memastikan konfigurasi diterapkan ke sesi Livy saat sesi tersebut dibuat. Untuk mengubah konfigurasi pada tahap selanjutnya dalam aplikasi, Anda harus menggunakan parameter -f. Akan tetapi, dengan melakukannya semua kemajuan dalam aplikasi hilang.
Cuplikan berikut menunjukkan cara mengubah konfigurasi untuk aplikasi yang berjalan di Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Parameter konfigurasi harus diteruskan sebagai string JSON dan harus berada di baris berikutnya setelah keajaiban, seperti yang ditampilkan di kolom contoh.
Mengubah parameter untuk aplikasi yang dikirim menggunakan spark-submit
Perintah berikut adalah contoh cara mengubah parameter konfigurasi untuk aplikasi batch yang dikirim menggunakanspark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Mengubah parameter untuk aplikasi yang dikirim menggunakan cURL
Perintah berikut adalah contoh cara mengubah parameter konfigurasi untuk aplikasi batch yang dikirim menggunakan cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Catatan
Salin file JAR ke akun penyimpanan kluster Anda. Jangan menyalin file JAR langsung ke head node.
Mengubah parameter-parameter ini pada Spark Thrift Server
Spark Thrift Server menyediakan akses JDBC/ODBC ke kluster Spark dan digunakan untuk melayani kueri Spark SQL. Alat seperti Power BI, Tableau, dan sebagainya, menggunakan protokol ODBC untuk berkomunikasi dengan Spark Thrift Server untuk menjalankan kueri Spark SQL sebagai Spark Application. Ketika kluster Spark dibuat, dua instans Spark Thrift Server dimulai, satu pada setiap node utama. Setiap Spark Thrift Server terlihat sebagai aplikasi Spark di YARN UI.
Spark Thrift Server menggunakan alokasi eksekutor dinamis Spark dan karenanya spark.executor.instances tidak digunakan. Sebaliknya, Spark Thrift Server menggunakan spark.dynamicAllocation.maxExecutors dan spark.dynamicAllocation.minExecutors untuk menentukan jumlah eksekutor. Parameter konfigurasi spark.executor.cores, dan spark.executor.memory digunakan untuk memodifikasi ukuran eksekutor. Anda dapat mengubah parameter ini seperti yang ditampilkan di langkah-langkah berikut:
Perluas kategori spark2-thrift-sparkconf Tingkat Lanjut untuk memperbarui parameter
spark.dynamicAllocation.maxExecutors, danspark.dynamicAllocation.minExecutors.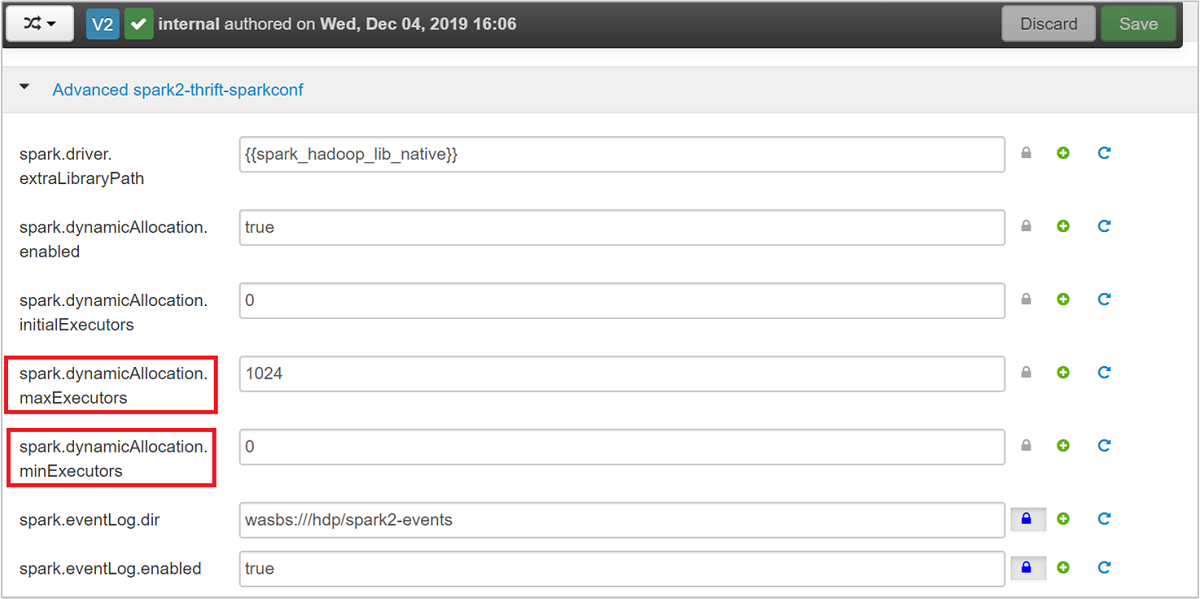
Perluas kategori spark2-thrift-sparkconf Kustom untuk memperbarui parameter
spark.executor.cores, danspark.executor.memory.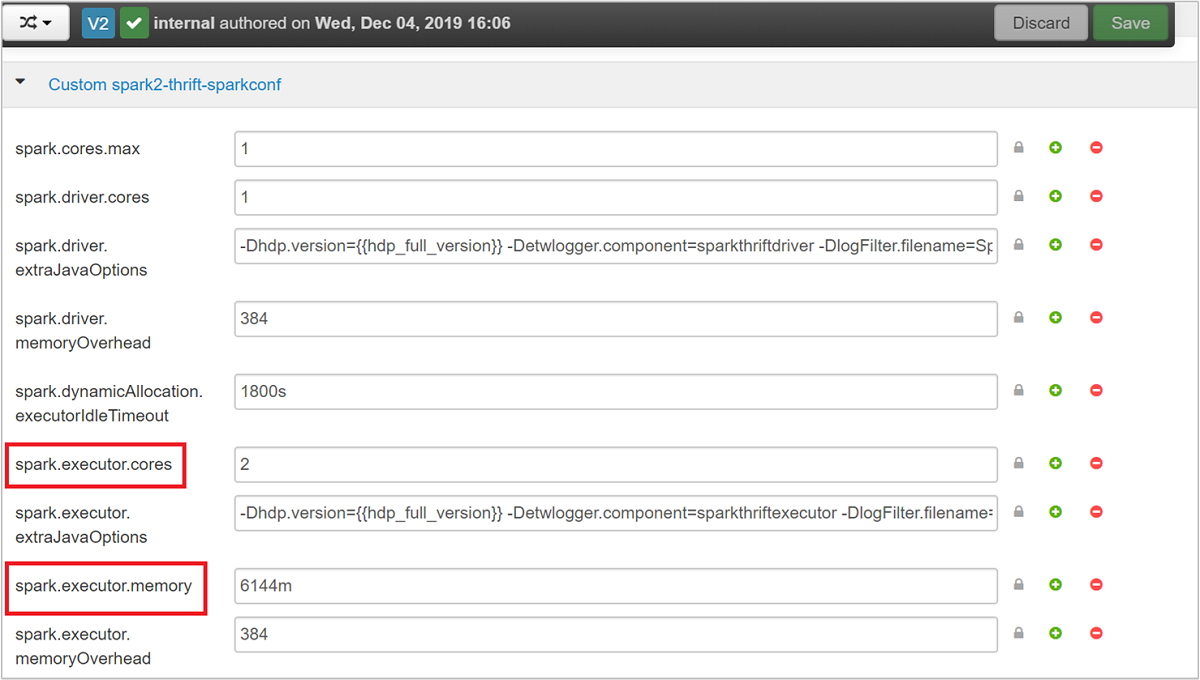
Mengubah memori driver dari Spark Thrift Server
Memori driver Spark Thrift Server dikonfigurasi menjadi 25% dari ukuran RAM node utama, dengan ketentuan bahwa ukuran total RAM node utama lebih besar dari 14 GB. Anda dapat menggunakan Ambari UI untuk mengubah konfigurasi memori driver, seperti yang ditampilkan di cuplikan layar berikut:
Dari Ambari UI, arahkan ke Spark2>Konfigurasi>spark2-env Tingkat Lanjut. Kemudian sediakan nilai untukspark_thrift_cmd_opts.
Mengklaim kembali sumber daya kluster Spark
Karena alokasi dinamis Spark, satu-satunya sumber daya yang digunakan oleh thrift server adalah sumber daya untuk dua master aplikasi. Untuk mengklaim kembali sumber daya ini, Anda harus menghentikan layanan Thrift Server yang berjalan pada kluster.
Dari Ambari UI, dari panel kiri, pilih Spark2.
Di halaman berikutnya, pilih Spark 2 Thrift Servers.
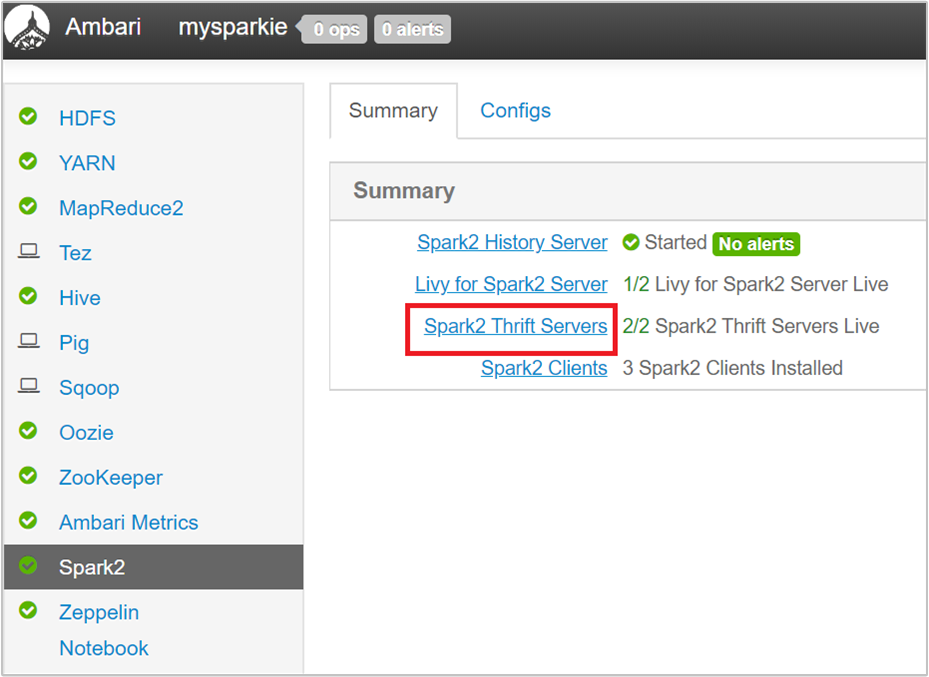
Anda akan melihat dua headnode tempat Spark 2 Thrift Server berjalan. Pilih salah satu simpul induk.
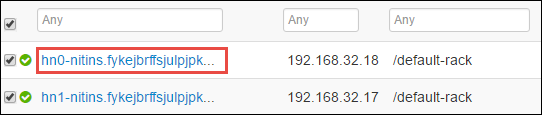
Halaman berikutnya mencantumkan semua layanan yang berjalan pada headnode tersebut. Dari daftar, pilih tombol drop-down di samping Spark 2 Thrift Server, lalu pilih Hentikan.
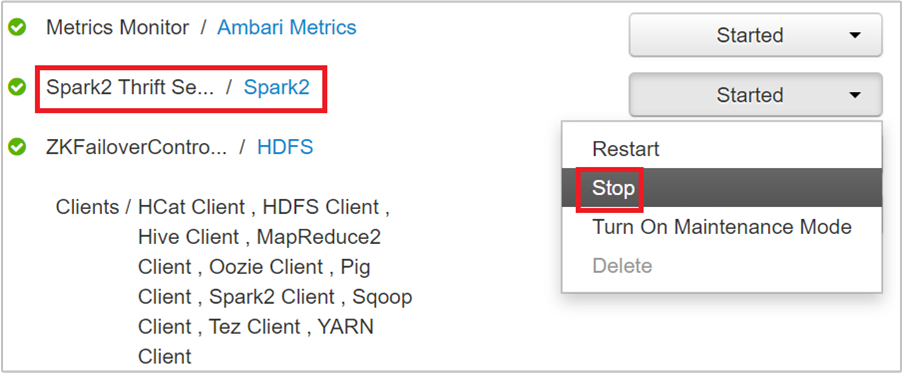
Ulangi langkah-langkah ini pada headnode lain.
Memulai ulang layanan Jupyter
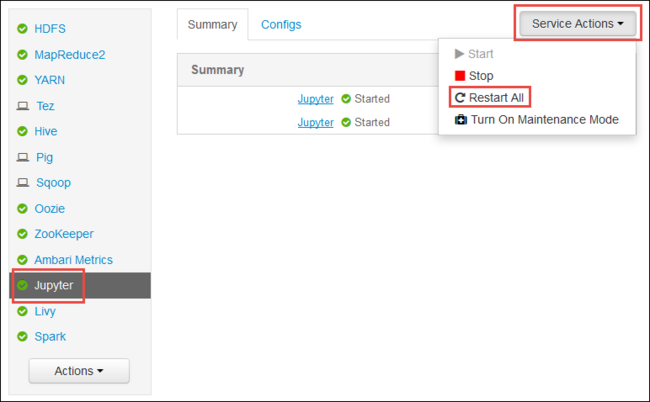
Luncurkan Ambari Web UI seperti yang ditampilkan di awal artikel. Dari panel navigasi kiri, pilih Jupyter, pilih Tindakan Layanan, lalu pilih Mulai Ulang Semua. Tindakan ini memulai layanan Jupyter pada semua headnode.
Memantau sumber daya
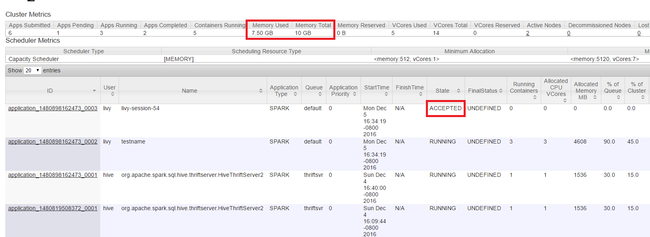
Luncurkan YARN UI seperti yang ditampilkan di awal artikel. Dalam tabel Metrik Kluster di atas layar, periksa nilai kolom Memori yang Digunakan dan Total Memori. Jika dua nilai tersebut hampir sama, mungkin tidak ada cukup sumber daya untuk memulai aplikasi berikutnya. Hal yang sama berlaku untuk kolom VCores yang Digunakan dan Total VCores. Juga, dalam tampilan utama, jika ada aplikasi yang tetap berada dalam status DITERIMA dan tidak bertransisi ke status BERJALAN atau GAGAL, hal ini juga bisa menjadi indikasi bahwa ia tidak mendapatkan sumber daya yang cukup untuk memulai.
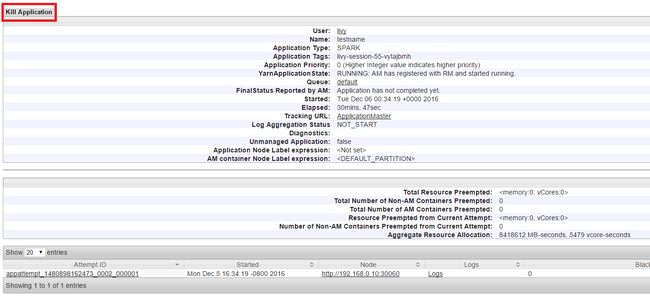
Menghentikan aplikasi yang berjalan
Di Yarn UI, dari panel kiri, pilih Berjalan. Dari daftar aplikasi yang berjalan, tentukan aplikasi yang akan dihentikan dan pilih ID.
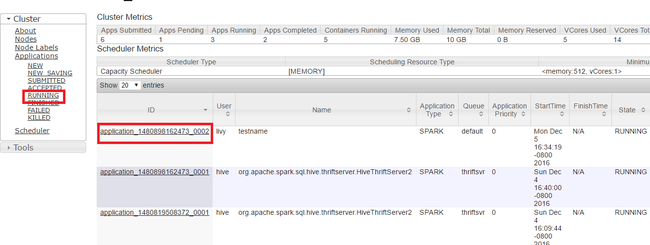
Pilih Hentikan Application di pojok kanan atas, lalu pilih OK.
Lihat juga
Untuk analis data
- Apache Spark dengan Pembelajaran Mesin: Menggunakan Apache Spark di HDInsight untuk menganalisis suhu bangunan menggunakan data HVAC
- Apache Spark dengan Pembelajaran Mesin: Menggunakan Spark di Microsoft Azure HDInsight untuk memprediksi hasil pemeriksaan makanan
- Analisis log situs web menggunakan Apache Spark di HDInsight
- Analisis data telemetri Application Insight menggunakan Apache Spark di HDInsight
Untuk pengembang Apache Spark
- Membuat aplikasi mandiri menggunakan Scala
- Jalankan pekerjaan dari jarak jauh pada kluster Apache Spark menggunakan Apache Livy
- Menggunakan HDInsight Tools Plugin untuk IntelliJ IDEA untuk membuat dan mengirimkan aplikasi Spark Scala
- Menggunakan Plugin Alat Microsoft Azure HDInsight untuk IntelliJ IDEA untuk men-debug aplikasi Apache Spark dari jarak jauh
- Menggunakan notebook Apache Zeppelin dengan klaster Apache Spark pada HDInsight
- Kernel tersedia untuk Jupyter Notebook di kluster Apache Spark untuk Microsoft Azure HDInsight
- Menggunakan paket eksternal dengan Jupyter Notebooks
- Pasang Jupyter di komputer Anda dan sambungkan ke kluster Microsoft Azure HDInsight Spark