Mulai Cepat: Manipulasi Data Interaktif dengan Apache Spark di Azure Pembelajaran Mesin
Untuk menangani perselisihan data notebook Azure Pembelajaran Mesin interaktif, integrasi Azure Pembelajaran Mesin dengan Azure Synapse Analytics menyediakan akses mudah ke kerangka kerja Apache Spark. Akses ini memungkinkan manipulasi data interaktif Azure Pembelajaran Mesin Notebook.
Dalam panduan mulai cepat ini, Anda mempelajari cara melakukan manipulasi data interaktif dengan komputasi Spark tanpa server Azure Pembelajaran Mesin, akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2, dan passthrough identitas pengguna.
Prasyarat
- Langganan Azure; jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum memulai.
- Ruang kerja Azure Machine Learning. Kunjungi Membuat sumber daya ruang kerja.
- Akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2. Kunjungi Membuat akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2.
Menyimpan kredensial akun penyimpanan Azure sebagai rahasia di Azure Key Vault
Untuk menyimpan kredensial akun penyimpanan Azure sebagai rahasia di Azure Key Vault, dengan antarmuka pengguna portal Azure:
Navigasi ke Azure Key Vault Anda di portal Azure
Pilih Rahasia dari panel kiri
Pilih + Hasilkan/Impor
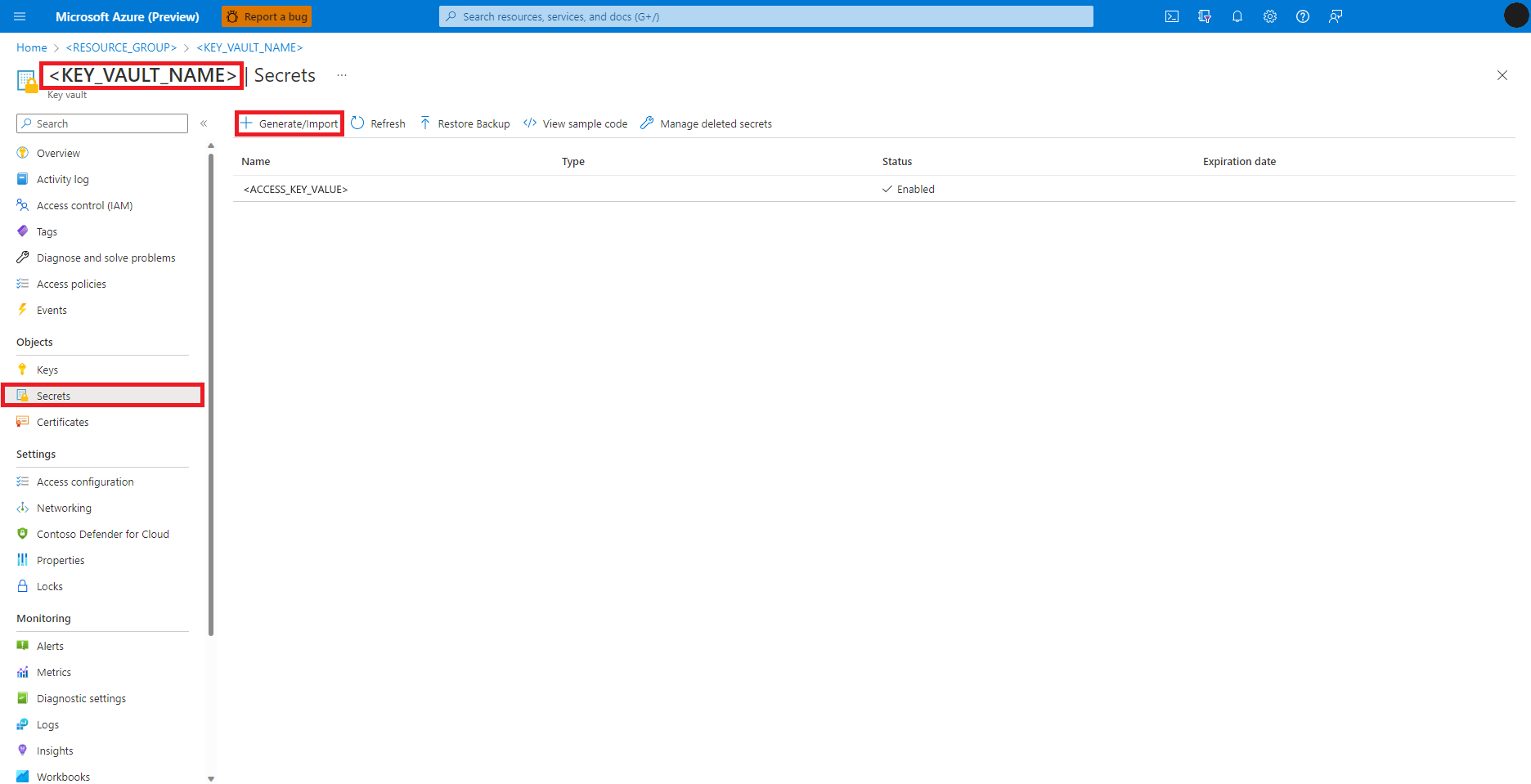
Di layar Buat rahasia, masukkan Nama untuk rahasia yang ingin Anda buat
Navigasi ke Akun Azure Blob Storage, di portal Azure, seperti yang ditunjukkan pada gambar ini:
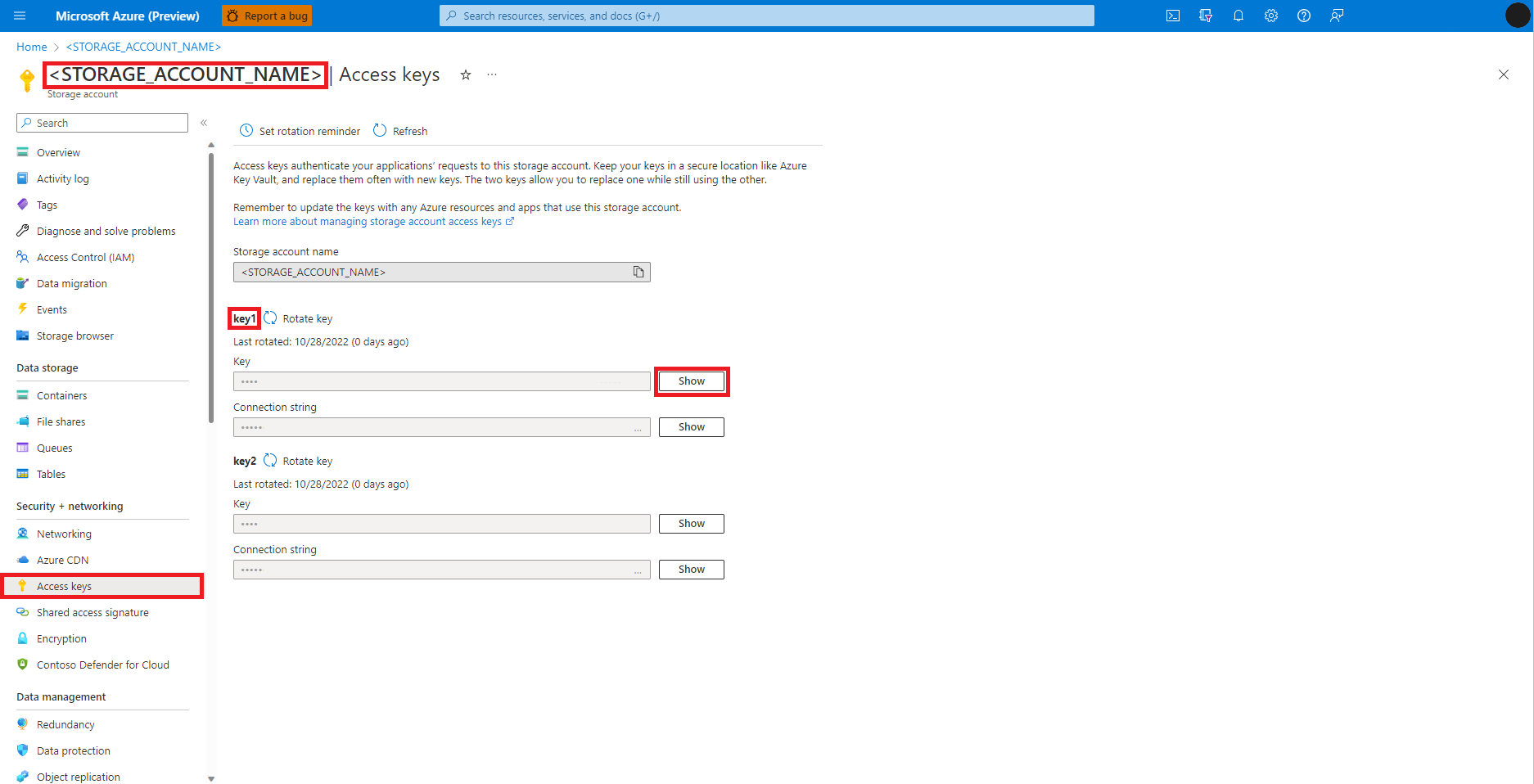
Pilih Kunci akses dari panel kiri halaman Akun Azure Blob Storage
Pilih Perlihatkan di samping Kunci 1, lalu Salin ke clipboard untuk mendapatkan kunci akses akun penyimpanan
Catatan
Pilih opsi yang sesuai untuk disalin
- Token tanda tangan akses bersama (SAS) kontainer penyimpanan Azure Blob
- Kredensial perwakilan layanan akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2
- ID penyewa
- ID klien dan
- rahasia
pada antarmuka pengguna masing-masing saat Anda membuat rahasia Azure Key Vault untuk mereka
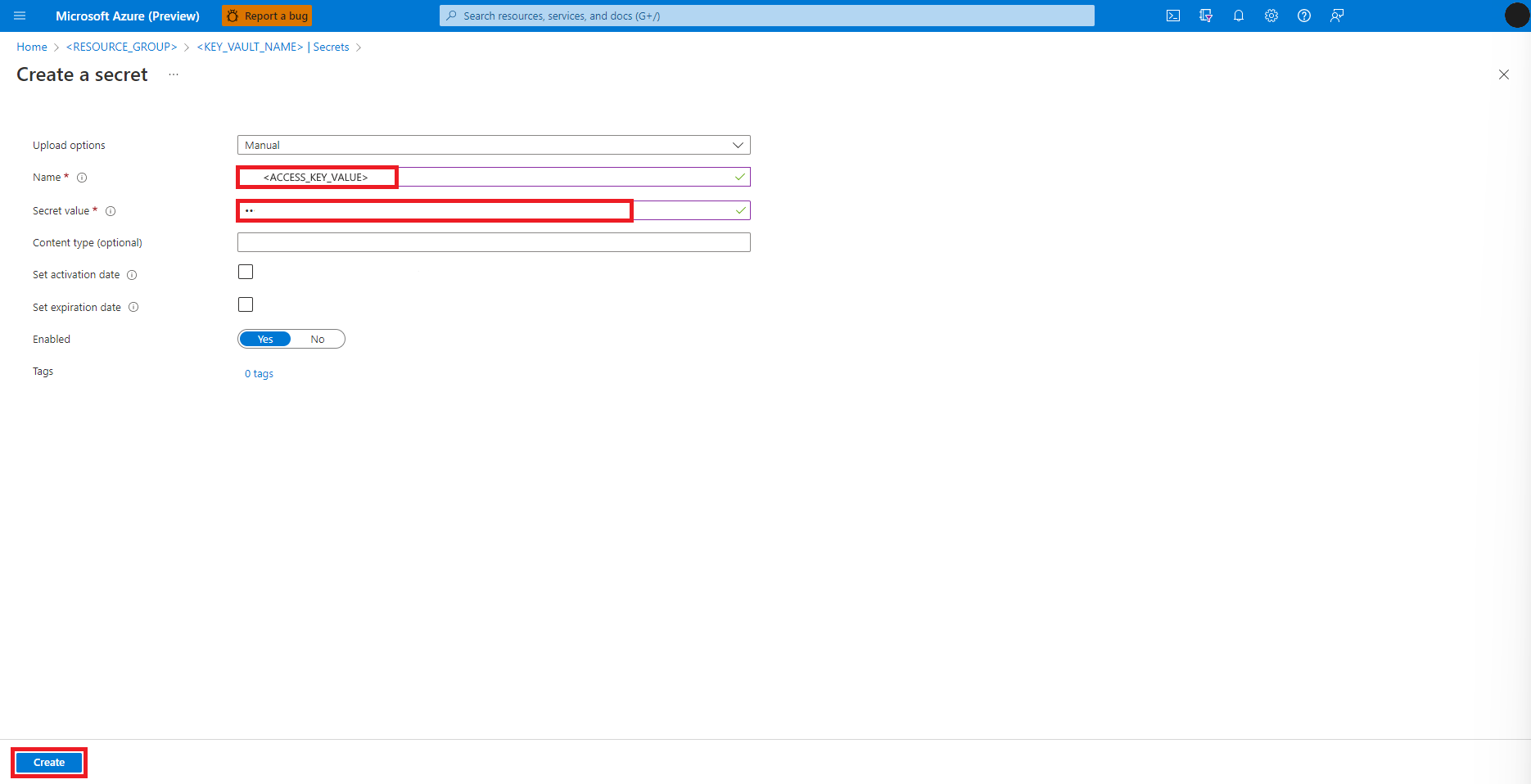
Menavigasi kembali ke layar Buat rahasia
Di kotak teks Nilai rahasia, masukkan kredensial kunci akses untuk akun penyimpanan Azure, yang disalin ke clipboard di langkah sebelumnya
Pilih Buat
Tip
Azure CLI dan pustaka klien rahasia Azure Key Vault untuk Python juga dapat membuat rahasia Azure Key Vault.
Menambahkan penetapan peran di akun penyimpanan Azure
Kita harus memastikan bahwa jalur data input dan output dapat diakses sebelum kita mulai manipulasi data interaktif. Pertama, untuk
identitas pengguna dari pengguna masuk sesi Notebooks
or
perwakilan layanan
tetapkan peran Pembaca dan Pembaca Data Blob Penyimpanan ke identitas pengguna yang masuk. Namun, dalam skenario tertentu, kita mungkin ingin menulis data yang disusun kembali ke akun penyimpanan Azure. Peran Pembaca dan Pembaca Data Blob Penyimpanan menyediakan akses baca-saja ke identitas pengguna atau perwakilan layanan. Untuk mengaktifkan akses baca dan tulis, tetapkan peran Kontributor dan Kontributor Data Blob Penyimpanan ke identitas pengguna atau perwakilan layanan. Untuk menetapkan peran yang sesuai ke identitas pengguna:
Cari dan pilih layanan Akun penyimpanan

Pada halaman Akun penyimpanan , pilih akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2 dari daftar. Halaman yang memperlihatkan Gambaran Umum akun penyimpanan terbuka
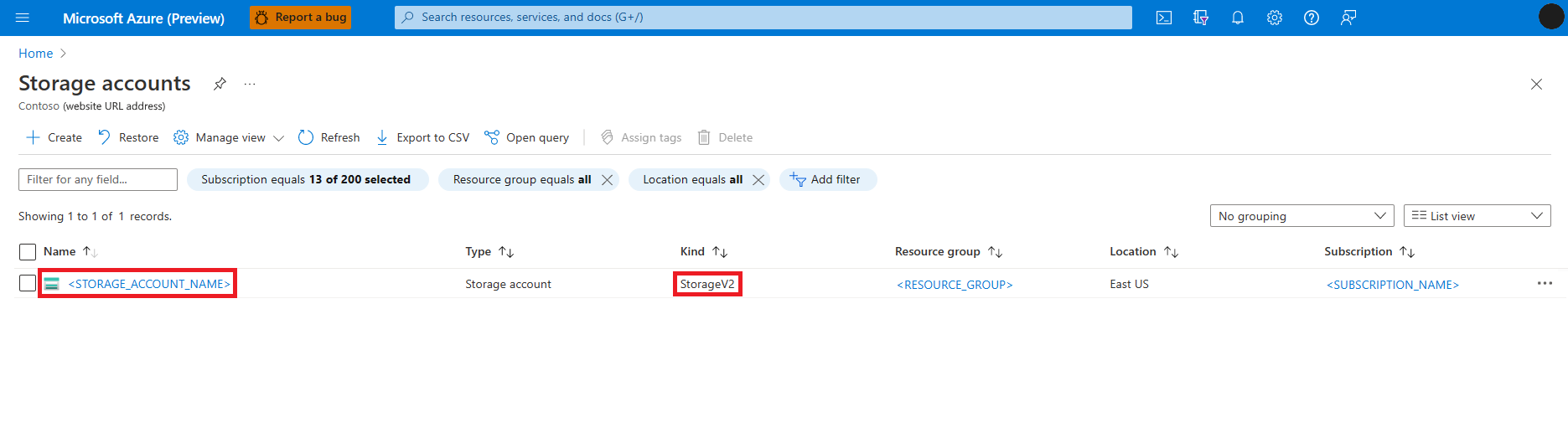
Pilih Access Control (IAM) dari panel kiri
Pilih Tambahkan penetapan peran
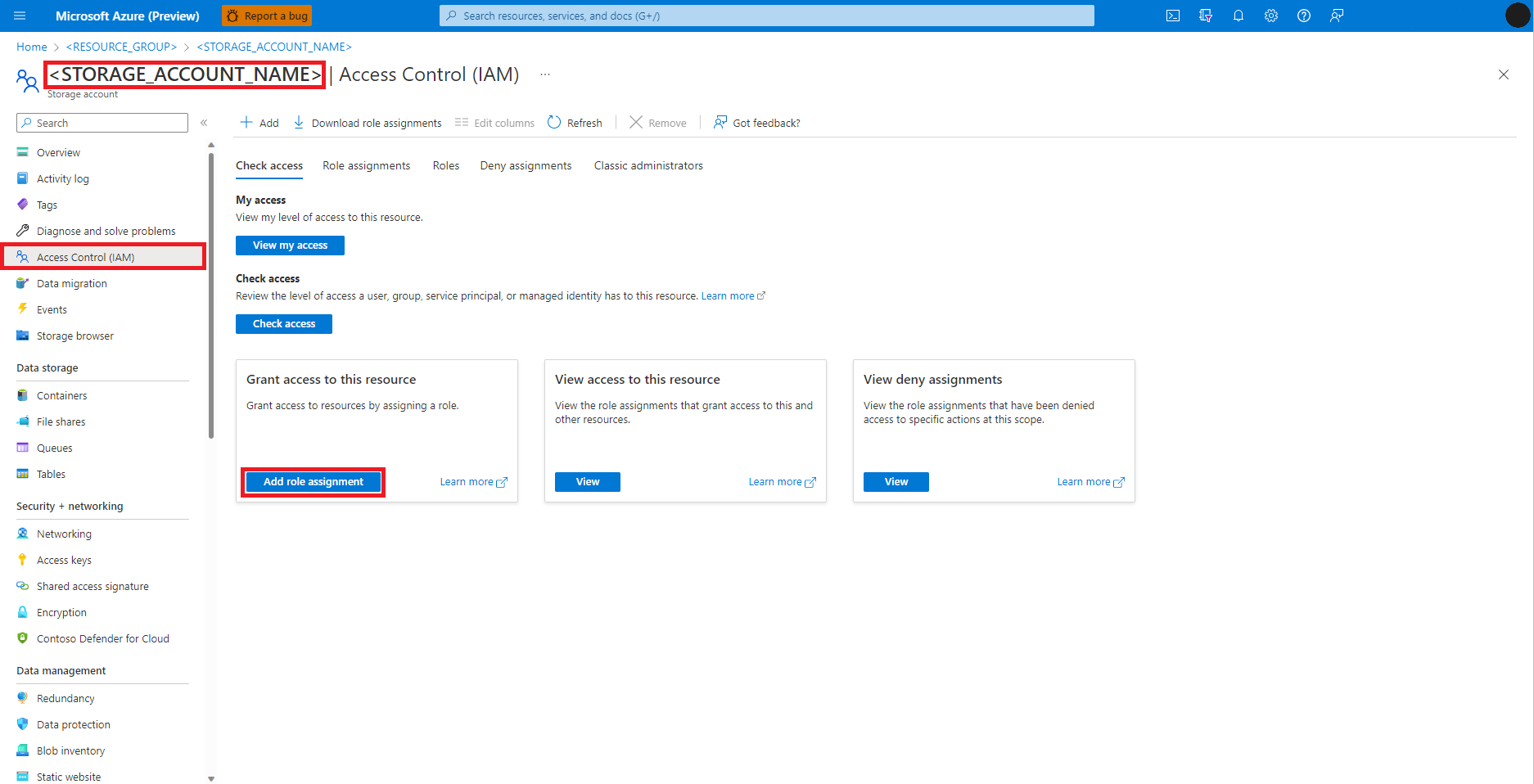
Temukan dan pilih peran Kontributor Data Blob Penyimpanan
Pilih Selanjutnya

Pilih Pengguna, grup, atau perwakilan layanan
Pilih + Pilih anggota
Cari identitas pengguna di bawah Pilih
Pilih identitas pengguna dari daftar, sehingga identitas tersebut ditampilkan di bawah Anggota yang dipilih
Pilih identitas pengguna yang sesuai
Pilih Selanjutnya
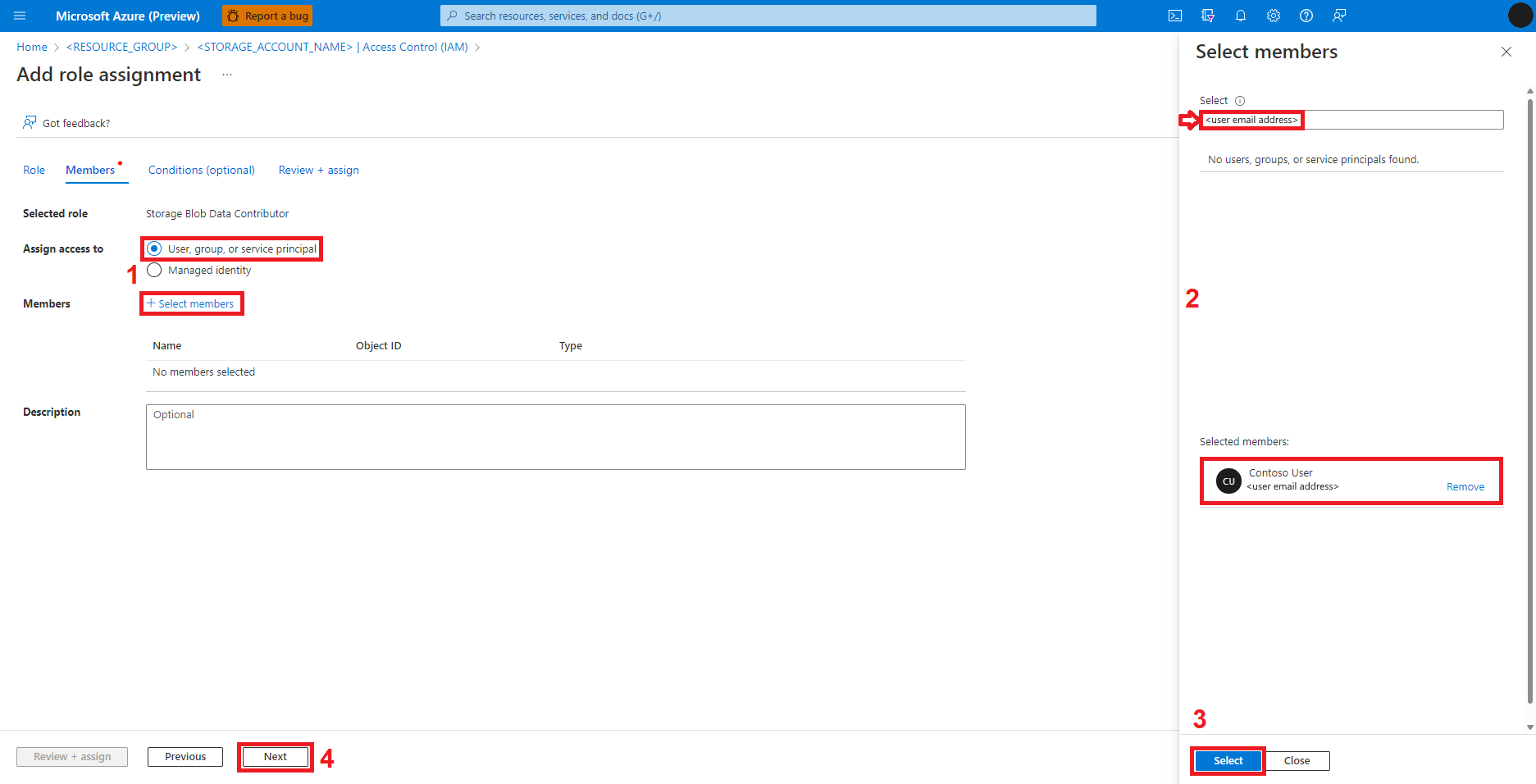
Pilih Tinjau + Tetapkan
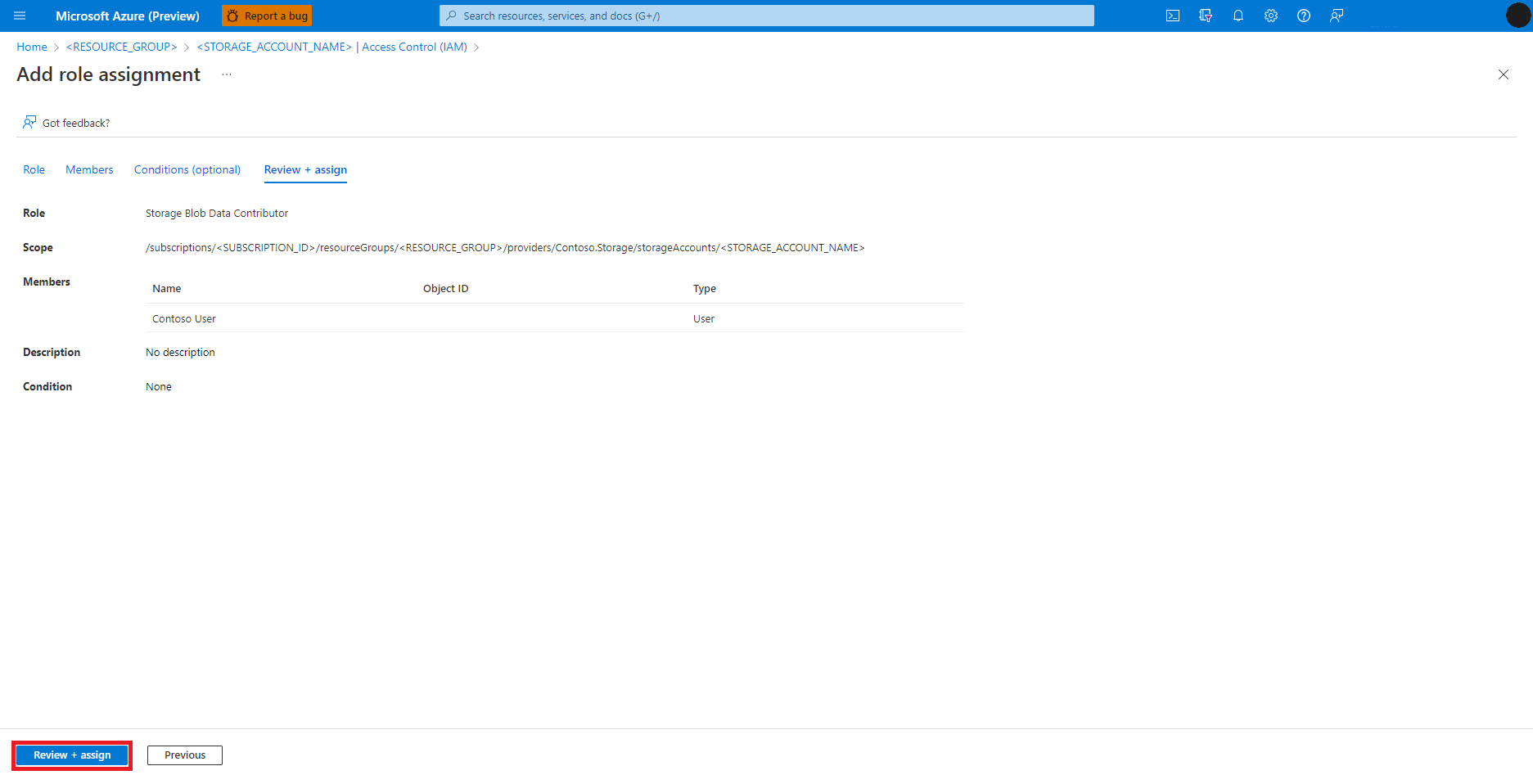
Ulangi langkah 2-13 untuk penetapan peran Kontributor






Setelah identitas pengguna memiliki peran yang sesuai yang ditetapkan, data di akun penyimpanan Azure harus dapat diakses.
Catatan
Jika kumpulan Synapse Spark terlampir menunjuk ke kumpulan Synapse Spark, di ruang kerja Azure Synapse, yang memiliki jaringan virtual terkelola yang terkait dengannya, Anda harus mengonfigurasi titik akhir privat terkelola ke akun penyimpanan untuk memastikan akses data.
Memastikan akses sumber daya untuk pekerjaan Spark
Untuk mengakses data dan sumber daya lainnya, pekerjaan Spark dapat menggunakan identitas terkelola atau passthrough identitas pengguna. Tabel berikut ini meringkas berbagai mekanisme untuk akses sumber daya saat Anda menggunakan Komputasi Spark tanpa server Azure Pembelajaran Mesin dan kumpulan Synapse Spark yang terpasang.
| Kumpulan Spark | Identitas yang didukung | Identitas default |
|---|---|---|
| Komputasi Spark Tanpa Server | Identitas pengguna, identitas terkelola yang ditetapkan pengguna yang dilampirkan ke ruang kerja | Identitas pengguna |
| Kumpulan Synapse Spark Terlampir | Identitas pengguna, identitas terkelola yang ditetapkan pengguna yang dilampirkan ke kumpulan Synapse Spark terlampir, identitas terkelola yang ditetapkan sistem dari kumpulan Synapse Spark terlampir | Identitas terkelola yang ditetapkan sistem dari kumpulan Synapse Spark terlampir |
Jika kode CLI atau SDK menentukan opsi untuk menggunakan identitas terkelola, komputasi Azure Pembelajaran Mesin Spark tanpa server bergantung pada identitas terkelola yang ditetapkan pengguna yang dilampirkan ke ruang kerja. Anda dapat melampirkan identitas terkelola yang ditetapkan pengguna ke ruang kerja Azure Pembelajaran Mesin yang sudah ada dengan Azure Pembelajaran Mesin CLI v2, atau dengan ARMClient.
Langkah berikutnya
- Apache Spark di Azure Pembelajaran Mesin
- Melampirkan dan mengelola kumpulan Synapse Spark di Azure Pembelajaran Mesin
- Manipulasi Data Interaktif dengan Apache Spark di Azure Pembelajaran Mesin
- Mengirimkan pekerjaan Spark di Azure Pembelajaran Mesin
- Sampel kode untuk pekerjaan Spark menggunakan Azure Pembelajaran Mesin CLI
- Sampel kode untuk pekerjaan Spark menggunakan Azure Pembelajaran Mesin Python SDK