Mengirimkan pekerjaan Spark di Azure Pembelajaran Mesin
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Azure Pembelajaran Mesin mendukung pengiriman pekerjaan pembelajaran mesin mandiri dan pembuatan alur pembelajaran mesin yang melibatkan beberapa langkah alur kerja pembelajaran mesin. Azure Pembelajaran Mesin menangani pembuatan pekerjaan Spark mandiri, dan pembuatan komponen Spark yang dapat digunakan kembali yang dapat digunakan oleh alur Azure Pembelajaran Mesin. Dalam artikel ini, Anda akan mempelajari cara mengirimkan pekerjaan Spark menggunakan:
- Antarmuka pengguna studio Azure Pembelajaran Mesin
- Azure Machine Learning CLI
- Azure Machine Learning SDK
Untuk informasi selengkapnya tentang konsep Apache Spark di Azure Pembelajaran Mesin, lihat sumber daya ini.
Prasyarat
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
- Langganan Azure; jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum memulai.
- Ruang kerja Azure Machine Learning. Lihat Membuat sumber daya ruang kerja.
- Membuat instans komputasi Azure Pembelajaran Mesin.
- Instal Azure Pembelajaran Mesin CLI.
- (Opsional): Kumpulan Synapse Spark terlampir di ruang kerja Azure Pembelajaran Mesin.
Catatan
- Untuk mempelajari selengkapnya tentang akses sumber daya saat menggunakan Azure Pembelajaran Mesin komputasi Spark tanpa server dan kumpulan Synapse Spark terlampir, lihat Memastikan akses sumber daya untuk pekerjaan Spark.
- Azure Pembelajaran Mesin menyediakan kumpulan kuota bersama tempat semua pengguna dapat mengakses kuota komputasi untuk melakukan pengujian dalam waktu terbatas. Saat Anda menggunakan komputasi Spark tanpa server, Azure Pembelajaran Mesin memungkinkan Anda mengakses kuota bersama ini untuk waktu yang singkat.
Melampirkan identitas terkelola yang ditetapkan pengguna menggunakan CLI v2
- Buat file YAML yang menentukan identitas terkelola yang ditetapkan pengguna yang harus dilampirkan ke ruang kerja:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} --fileDengan parameter , gunakan file YAML dalamaz ml workspace updateperintah untuk melampirkan identitas terkelola yang ditetapkan pengguna:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Melampirkan identitas terkelola yang ditetapkan pengguna menggunakan ARMClient
- Instal
ARMClient, alat baris perintah sederhana yang memanggil API Azure Resource Manager. - Buat file JSON yang menentukan identitas terkelola yang ditetapkan pengguna yang harus dilampirkan ke ruang kerja:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Untuk melampirkan identitas terkelola yang ditetapkan pengguna ke ruang kerja, jalankan perintah berikut di prompt PowerShell atau prompt perintah.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Catatan
- Untuk memastikan keberhasilan eksekusi pekerjaan Spark, tetapkan peran Kontributor dan Kontributor Data Blob Penyimpanan, pada akun penyimpanan Azure yang digunakan untuk input dan output data, ke identitas yang digunakan pekerjaan Spark
- Akses Jaringan Publik harus diaktifkan di ruang kerja Azure Synapse untuk memastikan keberhasilan eksekusi pekerjaan Spark menggunakan kumpulan Synapse Spark yang terlampir.
- Jika kumpulan Synapse Spark terlampir menunjuk ke kumpulan Synapse Spark, di ruang kerja Azure Synapse yang memiliki jaringan virtual terkelola yang terkait dengannya, titik akhir privat terkelola ke akun penyimpanan harus dikonfigurasi untuk memastikan akses data.
- Komputasi Spark tanpa server mendukung jaringan virtual terkelola Azure Pembelajaran Mesin. Jika jaringan terkelola disediakan untuk komputasi Spark tanpa server, titik akhir privat yang sesuai untuk akun penyimpanan juga harus disediakan untuk memastikan akses data.
Mengirimkan pekerjaan Spark mandiri
Setelah membuat perubahan yang diperlukan untuk parameterisasi skrip Python, skrip Python yang dikembangkan oleh perselisihan data interaktif dapat digunakan untuk mengirimkan pekerjaan batch untuk memproses volume data yang lebih besar. Pekerjaan batch manipulasi data sederhana dapat dikirimkan sebagai pekerjaan Spark mandiri.
Pekerjaan Spark memerlukan skrip Python yang mengambil argumen, yang dapat dikembangkan dengan modifikasi kode Python yang dikembangkan dari perselisihan data interaktif. Contoh skrip Python ditampilkan di sini.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Catatan
Sampel kode Python ini menggunakan pyspark.pandas. Hanya runtime Spark versi 3.2 atau yang lebih baru yang mendukung ini.
Skrip di atas mengambil dua argumen --titanic_data dan --wrangled_data, yang masing-masing meneruskan jalur data input dan folder output.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Untuk membuat pekerjaan, pekerjaan Spark mandiri dapat didefinisikan sebagai file spesifikasi YAML, yang dapat digunakan dalam az ml job create perintah, dengan --file parameter . Tentukan properti ini dalam file YAML:
Properti YAML dalam spesifikasi pekerjaan Spark
type- diatur kespark.code- mendefinisikan lokasi folder yang berisi kode sumber dan skrip untuk pekerjaan ini.entry- mendefinisikan titik masuk untuk pekerjaan tersebut. Ini harus mencakup salah satu properti ini:file- mendefinisikan nama skrip Python yang berfungsi sebagai titik masuk untuk pekerjaan tersebut.
py_files- mendefinisikan daftar.zip, , atau.pyfile, yang akan ditempatkan dalamPYTHONPATH, untuk keberhasilan.eggeksekusi pekerjaan. Properti ini bersifat opsional.jars- mendefinisikan daftar.jarfile yang akan disertakan pada driver Spark, dan pelaksanaCLASSPATH, untuk keberhasilan eksekusi pekerjaan. Properti ini bersifat opsional.files- mendefinisikan daftar file yang harus disalin ke direktori kerja setiap pelaksana, untuk keberhasilan eksekusi pekerjaan. Properti ini bersifat opsional.archives- mendefinisikan daftar arsip yang harus diekstrak ke dalam direktori kerja setiap pelaksana, untuk keberhasilan eksekusi pekerjaan. Properti ini bersifat opsional.conf- mendefinisikan properti driver dan eksekutor Spark ini:spark.driver.cores: jumlah inti untuk driver Spark.spark.driver.memory: mengalokasikan memori untuk driver Spark, dalam gigabyte (GB).spark.executor.cores: jumlah inti untuk pelaksana Spark.spark.executor.memory: alokasi memori untuk eksekutor Spark, dalam gigabyte (GB).spark.dynamicAllocation.enabled- apakah eksekutor harus dialokasikan secara dinamis, sebagaiTruenilai atauFalse.- Jika alokasi dinamis pelaksana diaktifkan, tentukan properti ini:
spark.dynamicAllocation.minExecutors- jumlah minimum instans pelaksana Spark, untuk alokasi dinamis.spark.dynamicAllocation.maxExecutors- jumlah maksimum instans pelaksana Spark, untuk alokasi dinamis.
- Jika alokasi dinamis pelaksana dinonaktifkan, tentukan properti ini:
spark.executor.instances- jumlah instans pelaksana Spark.
environment- lingkungan Azure Pembelajaran Mesin untuk menjalankan pekerjaan.args- argumen baris perintah yang harus diteruskan ke skrip Python titik entri pekerjaan. Lihat file spesifikasi YAML yang disediakan di sini misalnya.resources- properti ini menentukan sumber daya yang akan digunakan oleh Azure Pembelajaran Mesin komputasi Spark tanpa server. Ini menggunakan properti berikut:instance_type- jenis instans komputasi yang akan digunakan untuk kumpulan Spark. Jenis instans berikut saat ini didukung:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- mendefinisikan versi runtime Spark. Versi runtime Spark berikut saat ini didukung:3.33.4Penting
Azure Synapse Runtime for Apache Spark: Pengumuman
- Azure Synapse Runtime untuk Apache Spark 3.3:
- Tanggal Pengumuman EOLA: 12 Juli 2024
- Tanggal Akhir Dukungan: 31 Maret 2025. Setelah tanggal ini, runtime akan dinonaktifkan.
- Untuk dukungan berkelanjutan dan performa optimal, kami menyarankan migrasi ke Apache Spark 3.4.
- Azure Synapse Runtime untuk Apache Spark 3.3:
Ini adalah contoh:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- properti ini mendefinisikan nama kumpulan Synapse Spark terlampir, seperti yang ditunjukkan dalam contoh ini:compute: mysparkpoolinputs- properti ini mendefinisikan input untuk pekerjaan Spark. Input untuk pekerjaan Spark dapat berupa nilai harfiah, atau data yang disimpan dalam file atau folder.- Nilai harfiah dapat berupa angka, nilai boolean, atau string. Beberapa contoh ditampilkan di sini:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Data yang disimpan dalam file atau folder harus ditentukan menggunakan properti ini:
type- atur properti ini keuri_file, atauuri_folder, untuk data input yang terkandung dalam file atau folder masing-masing.path- URI data input, sepertiazureml://, ,abfss://atauwasbs://.mode- atur properti ini kedirect. Sampel ini menunjukkan definisi input pekerjaan, yang dapat disebut sebagai$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Nilai harfiah dapat berupa angka, nilai boolean, atau string. Beberapa contoh ditampilkan di sini:
outputs- properti ini mendefinisikan output pekerjaan Spark. Output untuk pekerjaan Spark dapat ditulis ke file atau lokasi folder, yang didefinisikan menggunakan tiga properti berikut:type- properti ini dapat diatur keuri_fileatauuri_folderuntuk menulis data output ke file atau folder masing-masing.path- properti ini mendefinisikan URI lokasi output, sepertiazureml://, ,abfss://atauwasbs://.mode- atur properti ini kedirect. Sampel ini menunjukkan definisi output pekerjaan, yang dapat disebut sebagai${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- properti opsional ini mendefinisikan identitas yang digunakan untuk mengirimkan pekerjaan ini. Ini dapat memilikiuser_identitynilai danmanaged. Jika spesifikasi YAML tidak menentukan identitas, pekerjaan Spark menggunakan identitas default.
Pekerjaan Spark Mandiri
Contoh spesifikasi YAML ini menunjukkan pekerjaan Spark mandiri. Ini menggunakan komputasi Spark tanpa server Azure Pembelajaran Mesin:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Catatan
Untuk menggunakan kumpulan Synapse Spark terlampir, tentukan compute properti dalam contoh file spesifikasi YAML yang ditampilkan sebelumnya, bukan resources properti .
File YAML yang ditampilkan sebelumnya dapat digunakan dalam perintah, dengan --file parameter , untuk membuat pekerjaan Spark mandiri seperti yang ditunjukkanaz ml job create:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Anda dapat menjalankan perintah di atas dari:
- terminal instans komputasi Azure Pembelajaran Mesin.
- terminal Visual Studio Code yang tersambung ke instans komputasi Azure Pembelajaran Mesin.
- komputer lokal Anda yang telah menginstal Azure Pembelajaran Mesin CLI.
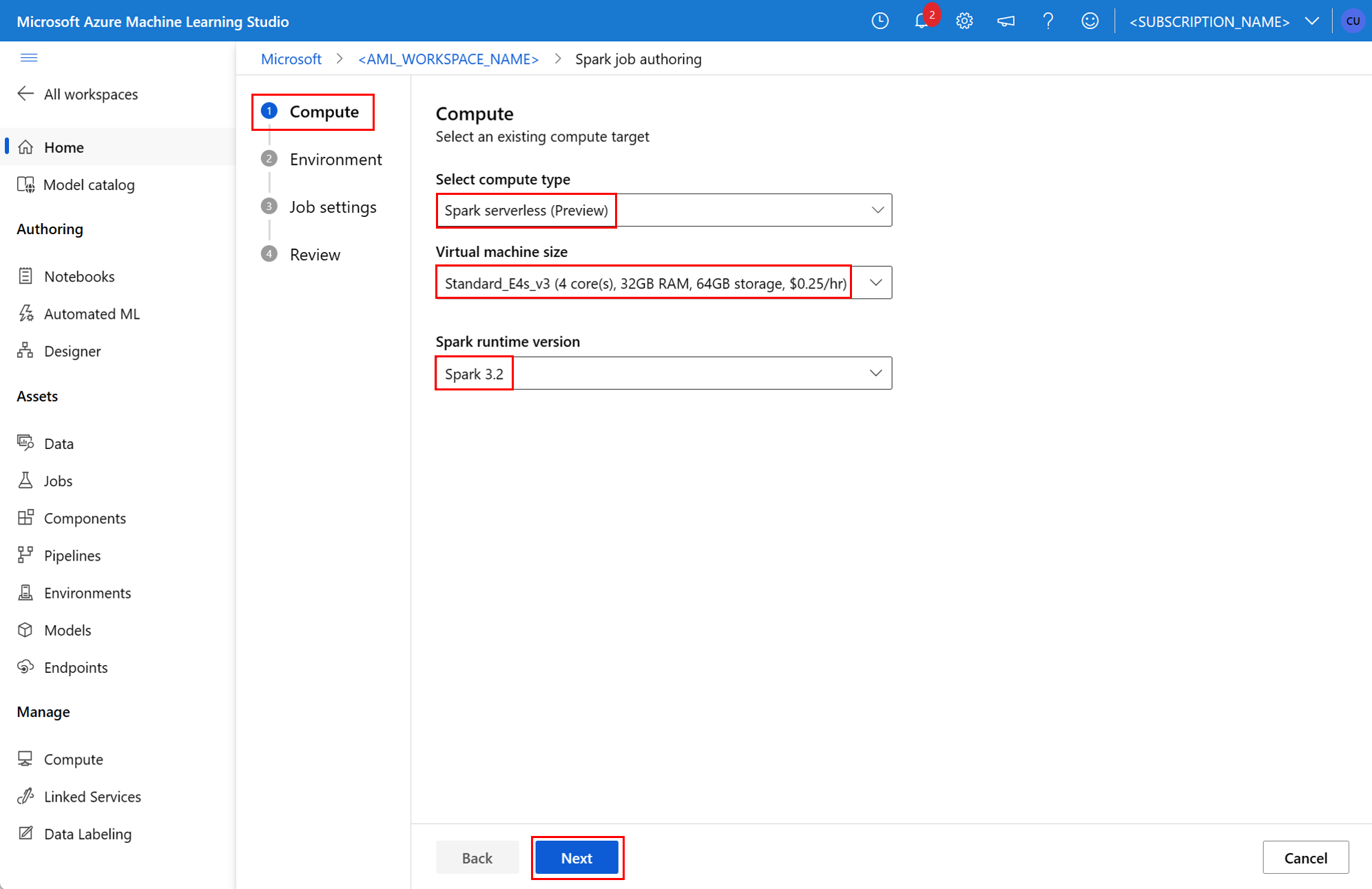
Komponen Spark dalam pekerjaan alur
Komponen Spark menawarkan fleksibilitas untuk menggunakan komponen yang sama di beberapa alur Azure Pembelajaran Mesin, sebagai langkah alur.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Sintaks YAML untuk komponen Spark menyerupai sintaks YAML untuk spesifikasi pekerjaan Spark dalam kebanyakan cara. Properti ini didefinisikan secara berbeda dalam spesifikasi YAML komponen Spark:
name- nama komponen Spark.version- versi komponen Spark.display_name- nama komponen Spark untuk ditampilkan di UI dan di tempat lain.description- deskripsi komponen Spark.inputs- properti ini miripinputsdengan properti yang dijelaskan dalam sintaks YAML untuk spesifikasi pekerjaan Spark, kecuali bahwa properti tersebut tidak menentukanpathproperti . Cuplikan kode ini menunjukkan contoh properti komponeninputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs- properti ini mirip dengan properti yangoutputsdijelaskan dalam sintaks YAML untuk spesifikasi pekerjaan Spark, kecuali bahwa properti tersebut tidak menentukanpathproperti . Cuplikan kode ini menunjukkan contoh properti komponenoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Catatan
Komponen Spark tidak menentukan identityproperti , compute atau resources . File spesifikasi YAML alur menentukan properti ini.
File spesifikasi YAML ini memberikan contoh komponen Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Komponen Spark yang ditentukan dalam file spesifikasi YAML di atas dapat digunakan dalam pekerjaan alur Azure Pembelajaran Mesin. Lihat skema YAML pekerjaan alur untuk mempelajari selengkapnya tentang sintaks YAML yang menentukan pekerjaan alur. Contoh ini menunjukkan file spesifikasi YAML untuk pekerjaan alur, dengan komponen Spark, dan komputasi Spark tanpa server Azure Pembelajaran Mesin:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Catatan
Untuk menggunakan kumpulan Synapse Spark terlampir, tentukan compute properti dalam contoh file spesifikasi YAML yang ditunjukkan di atas, bukan resources properti.
File spesifikasi YAML di atas dapat digunakan dalam perintah, menggunakan --file parameter , untuk membuat pekerjaan alur seperti yang ditunjukkanaz ml job create:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Anda dapat menjalankan perintah di atas dari:
- terminal instans komputasi Azure Pembelajaran Mesin.
- terminal Visual Studio Code yang tersambung ke instans komputasi Azure Pembelajaran Mesin.
- komputer lokal Anda yang telah menginstal Azure Pembelajaran Mesin CLI.
Memecahkan masalah pekerjaan Spark
Untuk memecahkan masalah pekerjaan Spark, Anda dapat mengakses log yang dihasilkan untuk pekerjaan tersebut di studio Azure Pembelajaran Mesin. Untuk melihat log untuk pekerjaan Spark:
- Navigasi ke Pekerjaan dari panel kiri di antarmuka pengguna studio Azure Pembelajaran Mesin
- Pilih tab Semua pekerjaan
- Pilih nilai Nama tampilan untuk pekerjaan
- Pada halaman detail pekerjaan, pilih tab Output + log
- Di penjelajah file, perluas folder log, lalu perluas folder azureml
- Mengakses log pekerjaan Spark di dalam folder manajer driver dan pustaka
Catatan
Untuk memecahkan masalah pekerjaan Spark yang dibuat selama manipulasi data interaktif dalam sesi buku catatan, pilih Detail pekerjaan di dekat sudut kanan atas UI buku catatan. Pekerjaan Spark dari sesi notebook interaktif dibuat di bawah nama eksperimen yang dijalankan notebook.