Manipulasi Data Interaktif dengan Apache Spark di Azure Pembelajaran Mesin
Perselisihan data menjadi salah satu aspek terpenting dari proyek pembelajaran mesin. Integrasi integrasi Azure Pembelajaran Mesin dengan Azure Synapse Analytics menyediakan akses ke kumpulan Apache Spark - didukung oleh Azure Synapse - untuk perselisihan data interaktif yang menggunakan Azure Pembelajaran Mesin Notebooks.
Dalam artikel ini, Anda mempelajari cara menangani manipulasi data menggunakan
- Komputasi Spark Tanpa Server
- Kumpulan Synapse Spark Terlampir
Prasyarat
- Langganan Azure; jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum memulai.
- Ruang kerja Azure Machine Learning. Kunjungi Membuat sumber daya ruang kerja untuk informasi selengkapnya.
- Akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2. Kunjungi Membuat akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2 untuk informasi selengkapnya.
- (Opsional): Azure Key Vault. Kunjungi Membuat Azure Key Vault untuk informasi selengkapnya.
- (Opsional): Perwakilan Layanan. Kunjungi Membuat Perwakilan Layanan untuk informasi selengkapnya.
- (Opsional): Kumpulan Synapse Spark terlampir di ruang kerja Azure Pembelajaran Mesin.
Sebelum Anda memulai tugas manipulasi data, pelajari tentang proses penyimpanan rahasia
- Kunci akses akun penyimpanan Azure Blob
- Token Tanda Tangan Akses Bersama (SAS)
- Informasi perwakilan layanan Azure Data Lake Storage (ADLS) Gen 2
di Azure Key Vault. Anda juga perlu tahu cara menangani penetapan peran di akun penyimpanan Azure. Bagian berikut dalam dokumen ini menjelaskan konsep-konsep ini. Kemudian, kami menjelajahi detail perselisihan data interaktif, menggunakan kumpulan Spark di Azure Pembelajaran Mesin Notebooks.
Tip
Untuk mempelajari tentang konfigurasi penetapan peran akun penyimpanan Azure, atau jika Anda mengakses data di akun penyimpanan Menggunakan passthrough identitas pengguna, kunjungi Menambahkan penetapan peran di akun penyimpanan Azure untuk informasi selengkapnya.
Manipulasi Data Interaktif dengan Apache Spark
Untuk perselisihan data interaktif dengan Apache Spark di Azure Pembelajaran Mesin Notebooks, Azure Pembelajaran Mesin menawarkan komputasi Spark tanpa server dan kumpulan Synapse Spark yang terpasang. Komputasi Spark tanpa server tidak memerlukan pembuatan sumber daya di ruang kerja Azure Synapse. Sebaliknya, komputasi Spark tanpa server yang dikelola sepenuhnya menjadi tersedia langsung di Azure Pembelajaran Mesin Notebooks. Penggunaan komputasi Spark tanpa server adalah cara termampu untuk mengakses kluster Spark di Azure Pembelajaran Mesin.
Komputasi Spark tanpa server di Azure Pembelajaran Mesin Notebooks
Komputasi Spark tanpa server tersedia di Azure Pembelajaran Mesin Notebooks secara default. Untuk mengaksesnya di buku catatan, pilih Komputasi Spark Tanpa Server di bawah Azure Pembelajaran Mesin Serverless Spark dari menu Pilihan komputasi.
UI Notebooks juga menyediakan opsi untuk konfigurasi sesi Spark untuk komputasi Spark tanpa server. Untuk mengonfigurasi sesi Spark:
- Pilih Konfigurasikan sesi di bagian atas layar.
- Pilih versi Apache Spark dari menu dropdown.
Penting
Azure Synapse Runtime for Apache Spark: Pengumuman
- Azure Synapse Runtime untuk Apache Spark 3.2:
- Tanggal Pengumuman EOLA: 8 Juli 2023
- Tanggal Akhir Dukungan: 8 Juli 2024. Setelah tanggal ini, runtime akan dinonaktifkan.
- Apache Spark 3.3:
- Tanggal Pengumuman EOLA: 12 Juli 2024
- Tanggal Akhir Dukungan: 31 Maret 2025. Setelah tanggal ini, runtime akan dinonaktifkan.
- Untuk dukungan berkelanjutan dan performa optimal, kami menyarankan migrasi ke Apache Spark 3.4
- Azure Synapse Runtime untuk Apache Spark 3.2:
- Pilih Jenis instans dari menu dropdown. Jenis ini saat ini didukung:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Masukkan nilai batas waktu Sesi Spark, dalam menit.
- Pilih apakah Anda ingin mengalokasikan pelaksana secara dinamis atau tidak
- Pilih jumlah Pelaksana untuk sesi Spark.
- Pilih Ukuran pelaksana dari menu dropdown.
- Pilih Ukuran driver dari menu dropdown.
- Untuk menggunakan file Conda untuk mengonfigurasi sesi Spark, centang kotak Unggah file conda. Lalu, pilih Telusuri, dan pilih file Conda dengan konfigurasi sesi Spark yang Anda inginkan.
- Tambahkan properti pengaturan Konfigurasi, masukkan nilai di kotak teks Properti dan Nilai , dan pilih Tambahkan.
- Pilih Terapkan.
- Di pop-up Konfigurasikan sesi baru? , pilih Hentikan sesi.
Konfigurasi sesi berubah bertahan dan tersedia untuk sesi notebook lain yang mulai menggunakan komputasi Spark tanpa server.
Tip
Jika Anda menggunakan paket Conda tingkat sesi, Anda dapat meningkatkan waktu mulai dingin sesi Spark jika Anda mengatur variabel spark.hadoop.aml.enable_cache konfigurasi ke true. Sesi cold start dengan paket Conda tingkat sesi biasanya membutuhkan waktu 10 hingga 15 menit ketika sesi dimulai untuk pertama kalinya. Namun, sesi berikutnya dingin dimulai dengan variabel konfigurasi yang diatur ke true biasanya memakan waktu tiga hingga lima menit.
Mengimpor dan membungkus data dari Azure Data Lake Storage (ADLS) Gen 2
Anda dapat mengakses dan membungkus data yang disimpan di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2 dengan abfss:// URI data. Untuk melakukan ini, Anda harus mengikuti salah satu dari dua mekanisme akses data:
- Passthrough identitas pengguna
- Akses data berbasis perwakilan layanan
Tip
Perselisihan data dengan komputasi Spark tanpa server, dan passthrough identitas pengguna untuk mengakses data di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2, memerlukan sejumlah kecil langkah konfigurasi.
Untuk memulai manipulasi data interaktif dengan passthrough identitas pengguna:
Verifikasi bahwa identitas pengguna memiliki penetapan peran Kontributor dan Kontributor Data Blob Penyimpanan di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2.
Untuk menggunakan komputasi Spark tanpa server, pilih Komputasi Spark Tanpa Server di bawah Azure Pembelajaran Mesin Serverless Spark dari menu pilihan Komputasi.
Untuk menggunakan kumpulan Synapse Spark terlampir, pilih kumpulan Synapse Spark terlampir di bawah kumpulan Synapse Spark dari menu pilihan Komputasi .
Sampel kode manipulasi data Titanic ini menunjukkan penggunaan URI data dalam format
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>denganpyspark.pandasdanpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Catatan
Sampel kode Python ini menggunakan
pyspark.pandas. Hanya runtime Spark versi 3.2 atau yang lebih baru yang mendukung ini.
Untuk membungkus data dengan akses melalui perwakilan layanan:
Verifikasi bahwa perwakilan layanan memiliki penetapan peran Kontributor dan Kontributor Data Blob Penyimpanan di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2.
Buat rahasia Azure Key Vault untuk ID penyewa perwakilan layanan, ID klien, dan nilai rahasia klien.
Di menu Pilihan komputasi, pilih Komputasi Spark Tanpa Server di bawah Azure Pembelajaran Mesin Serverless Spark. Anda juga dapat memilih kumpulan Synapse Spark terlampir di bawah kumpulan Synapse Spark dari menu Pilihan komputasi .
Atur ID penyewa perwakilan layanan, ID klien, dan nilai rahasia klien dalam konfigurasi, dan jalankan sampel kode berikut.
Panggilan
get_secret()dalam kode bergantung pada nama Azure Key Vault, dan nama rahasia Azure Key Vault yang dibuat untuk ID penyewa perwakilan layanan, ID klien, dan rahasia klien. Atur nama/nilai properti terkait ini dalam konfigurasi:- Properti ID Klien:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Properti rahasia klien:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Properti ID penyewa:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Nilai ID penyewa:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Properti ID Klien:
Menggunakan data Titanic, impor dan manipulasi data menggunakan URI data dalam
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>format, seperti yang ditunjukkan dalam sampel kode.
Mengimpor dan membungkus data dari penyimpanan Azure Blob
Anda dapat mengakses data penyimpanan Azure Blob dengan kunci akses akun penyimpanan atau token tanda tangan akses bersama (SAS). Anda harus menyimpan kredensial ini di Azure Key Vault sebagai rahasia, dan mengaturnya sebagai properti dalam konfigurasi sesi.
Untuk memulai manipulasi data interaktif:
Di panel kiri studio Azure Pembelajaran Mesin, pilih Buku Catatan.
Di menu Pilihan komputasi, pilih Komputasi Spark Tanpa Server di bawah Azure Pembelajaran Mesin Serverless Spark. Anda juga dapat memilih kumpulan Synapse Spark terlampir di bawah kumpulan Synapse Spark dari menu Pilihan komputasi .
Untuk mengonfigurasi kunci akses akun penyimpanan atau token tanda tangan akses bersama (SAS) untuk akses data di Azure Pembelajaran Mesin Notebooks:
Untuk kunci akses, atur properti , seperti yang
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netditunjukkan dalam cuplikan kode ini:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Untuk token SAS, atur properti , seperti yang
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netditunjukkan dalam cuplikan kode ini:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Catatan
Panggilan
get_secret()dalam cuplikan kode sebelumnya memerlukan nama Azure Key Vault, dan nama rahasia yang dibuat untuk kunci akses akun penyimpanan Azure Blob atau token SAS.
Jalankan kode manipulasi data di notebook yang sama. Format URI data sebagai
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, mirip dengan apa yang ditunjukkan cuplikan kode ini:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Catatan
Sampel kode Python ini menggunakan
pyspark.pandas. Hanya runtime Spark versi 3.2 atau yang lebih baru yang mendukung ini.
Mengimpor dan membungkus data dari Azure Pembelajaran Mesin Datastore
Untuk mengakses data dari Azure Pembelajaran Mesin Datastore, tentukan jalur ke data di datastore dengan format azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>URI . Untuk membungkus data dari Azure Pembelajaran Mesin Datastore dalam sesi Notebooks secara interaktif:
Pilih Komputasi Spark Tanpa Server di bawah Azure Pembelajaran Mesin Spark Tanpa Server dari menu pilihan Komputasi, atau pilih kumpulan Synapse Spark terlampir di bawah kumpulan Synapse Spark dari menu Pilihan komputasi.
Sampel kode ini menunjukkan cara membaca dan membungkus data Titanic dari Azure Pembelajaran Mesin Datastore, menggunakan
azureml://URI datastore,pyspark.pandas, danpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Catatan
Sampel kode Python ini menggunakan
pyspark.pandas. Hanya runtime Spark versi 3.2 atau yang lebih baru yang mendukung ini.
Datastore Azure Pembelajaran Mesin dapat mengakses data menggunakan kredensial akun penyimpanan Azure
- kunci akses
- Token SAS
- prinsip layanan
atau mereka menggunakan akses data tanpa kredensial. Bergantung pada jenis datastore dan jenis akun penyimpanan Azure yang mendasar, pilih mekanisme autentikasi yang sesuai untuk memastikan akses data. Tabel ini meringkas mekanisme autentikasi untuk mengakses data di datastore Azure Pembelajaran Mesin:
| Jenis akun penyimpanan | Akses data tanpa kredensial | Mekanisme akses data | Penetapan peran |
|---|---|---|---|
| Azure Blob | No | Kunci akses atau token SAS | Tidak diperlukan penetapan peran |
| Azure Blob | Ya | Passthrough identitas pengguna* | Identitas pengguna harus memiliki penetapan peran yang sesuai di akun penyimpanan Azure Blob |
| Azure Data Lake Storage (ADLS) Gen 2 | No | Perwakilan layanan | Perwakilan layanan harus memiliki penetapan peran yang sesuai di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen 2 | Ya | Passthrough identitas pengguna | Identitas pengguna harus memiliki penetapan peran yang sesuai di akun penyimpanan Azure Data Lake Storage (ADLS) Gen 2 |
* Passthrough identitas pengguna berfungsi untuk datastore tanpa kredensial yang menunjuk ke akun penyimpanan Azure Blob, hanya jika penghapusan sementara tidak diaktifkan.
Mengakses data pada berbagi file default
Berbagi file default dipasang ke komputasi Spark tanpa server dan kumpulan Synapse Spark yang terpasang.
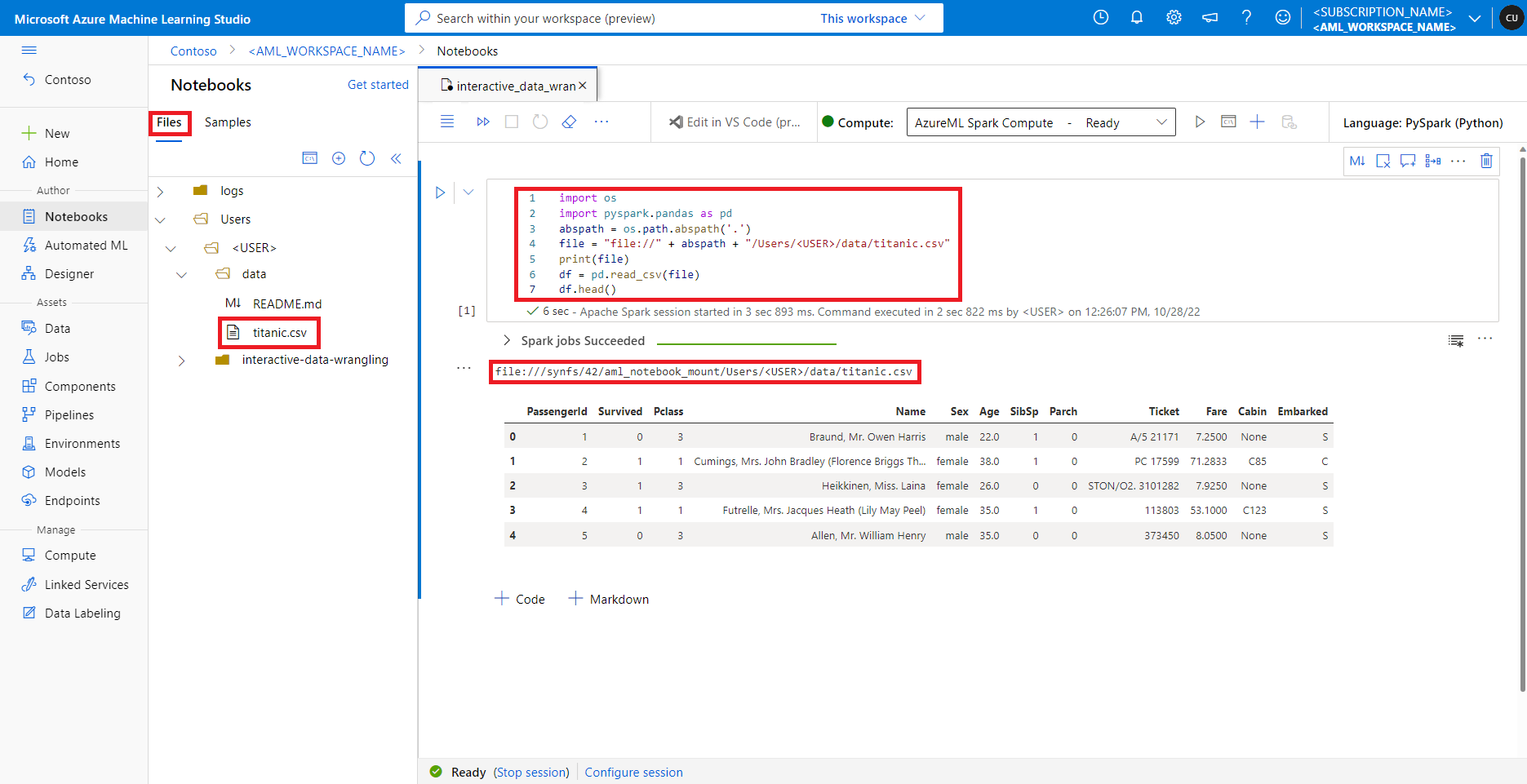
Di studio Azure Pembelajaran Mesin, file dalam berbagi file default ditampilkan di pohon direktori di bawah tab File. Kode buku catatan dapat langsung mengakses file yang disimpan dalam berbagi file ini dengan file:// protokol, bersama dengan jalur absolut file, tanpa lebih banyak konfigurasi. Cuplikan kode ini menunjukkan cara mengakses file yang disimpan pada berbagi file default:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Catatan
Sampel kode Python ini menggunakan pyspark.pandas. Hanya runtime Spark versi 3.2 atau yang lebih baru yang mendukung ini.