Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Pembelajaran Mesin Studio (klasik)
Pembelajaran Mesin Studio (klasik)  Azure Pembelajaran Mesin
Azure Pembelajaran Mesin
Penting
Dukungan untuk Studio Azure Machine Learning (klasik) akan berakhir pada 31 Agustus 2024. Sebaiknya Anda transisi ke Azure Machine Learning sebelum tanggal tersebut.
Mulai 1 Desember 2021, Anda tidak akan dapat membuat sumber daya Studio Azure Machine Learning (klasik) baru. Hingga 31 Agustus 2024, Anda dapat terus menggunakan sumber daya Pembelajaran Mesin Studio (klasik) yang ada.
- Lihat informasi tentang memindahkan proyek pembelajaran mesin dari ML Studio (klasik) ke Azure Machine Learning.
- Pelajari lebih lanjut tentang Azure Machine Learning
Dukumentasi ML Studio (klasik) akan dihentikan dan mungkin tidak akan diperbarui di kemudian hari.
Dalam artikel ini, Anda membuat eksperimen pembelajaran mesin di Azure Machine Learning Studio (klasik) yang memprediksi harga mobil berdasarkan variabel yang berbeda seperti spesifikasi pembuatan dan teknis.
Jika Anda baru mengetahui tentang pembelajaran mesin, seri video Ilmu Data untuk Pemula adalah pengantar yang bagus untuk pembelajaran mesin menggunakan bahasa dan konsep sehari-hari.
Panduan cepat ini mengikuti alur kerja default untuk eksperimen:
- Membuat model
- Melatih model
- Menilai dan menguji model
Mendapatkan data
Hal pertama yang Anda butuhkan dalam pembelajaran mesin adalah data. Ada beberapa contoh kumpulan data yang disertakan dengan Studio (klasik) yang dapat Anda gunakan, atau Anda dapat mengimpor data dari berbagai sumber. Untuk contoh ini, kami akan menggunakan kumpulan data sampel, Data harga mobil (Mentah),yang disertakan dalam ruang kerja Anda. Himpunan data ini mencakup entri untuk berbagai mobil individu, termasuk informasi seperti pembuatan, model, spesifikasi teknis, dan harga.
Tip
Anda dapat menemukan salinan fungsional eksperimen berikut ini di Galeri Azure AI. Buka Eksperimen ilmu data pertama Anda - Prediksi harga mobil lalu klik Buka di Studio untuk mengunduh salinan eksperimen ke ruang kerja Azure Machine Learning Studio (klasik) Anda.
Berikut cara mendapatkan himpunan data ke dalam eksperimen Anda.
Buat eksperimen baru dengan mengklik +BARU di bagian bawah jendela Azure Machine Learning Studio (klasik). Pilih EKSPERIMEN>Eksperimen Kosong.
Eksperimen ini diberi nama default yang dapat Anda lihat di bagian atas kanvas. Pilih teks ini lalu ganti namanya menjadi sesuatu yang bermakna, misalnya, Prediksi harga mobil. Namanya tidak perlu unik.
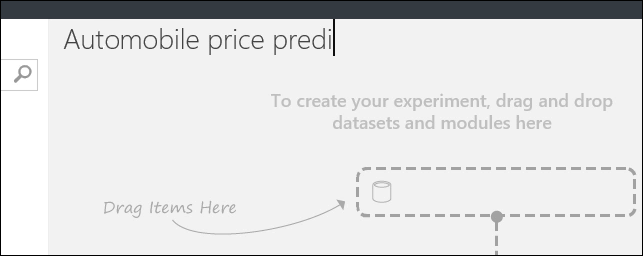
Di sebelah kiri kanvas eksperimen adalah palet himpunan data dan modul. Ketik mobil di kotak Pencarian di bagian atas palet ini untuk menemukan himpunan data berlabel Data harga mobil (Mentah). Seret himpunan data ini ke kanvas eksperimen.
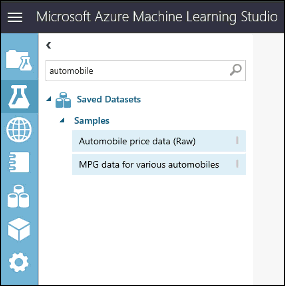
Untuk melihat tampilan data ini, klik port output di bagian bawah himpunan data mobil lalu pilih Visualisasi.
Kiat
Himpunan data dan modul memiliki port input dan output yang dinyatakan oleh lingkaran kecil - port input di bagian atas, port output di bagian bawah. Untuk membuat aliran data melalui eksperimen, Anda akan menyambungkan port output dari satu modul ke port input lainnya. Kapan pun, Anda dapat mengklik port output himpunan data atau modul untuk melihat seperti apa data pada titik itu dalam aliran data.
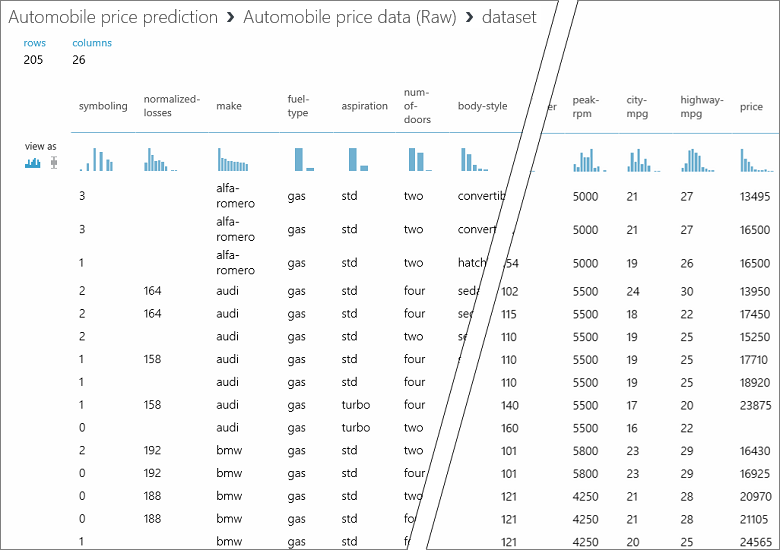
Dalam himpunan data ini, setiap baris mewakili mobil, dan variabel yang terkait dengan setiap mobil muncul sebagai kolom. Kami akan memprediksi harga di kolom sebelah kanan (kolom 26, berjudul "harga") menggunakan variabel untuk mobil tertentu.
Tutup jendela visualisasi dengan mengklik "x" di sudut kanan atas.
Menyiapkan data
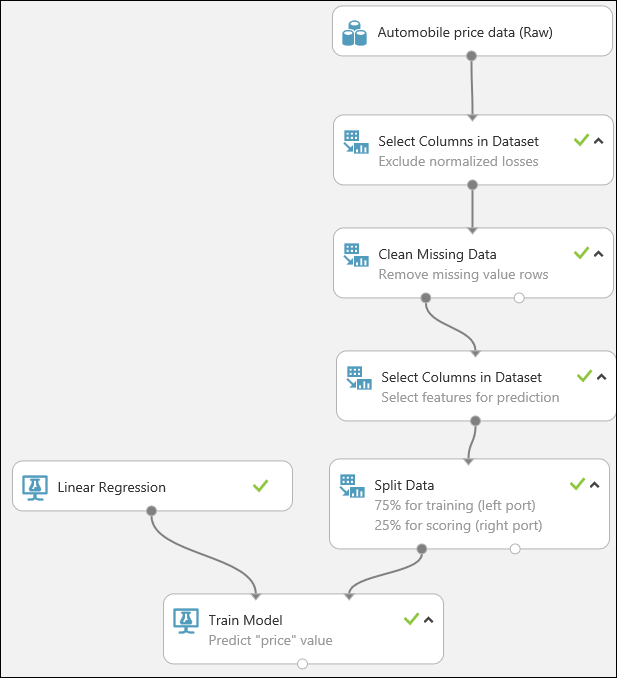
Himpunan data biasanya memerlukan beberapa pra-pemrosesan sebelum dapat dianalisis. Anda mungkin telah melihat nilai yang hilang di kolom pada beberapa baris. Nilai yang hilang ini perlu dibersihkan agar model dapat menganalisis data dengan benar. Kami akan menghapus setiap baris yang memiliki nilai hilang. Selain itu, kolom kerugian yang dinormalisasi memiliki proporsi nilai hilang yang besar, jadi kami akan mengecualikan kolom tersebut dari model tersebut sekaligus.
Tips
Membersihkan nilai hilang dari data input adalah prasyarat untuk menggunakan sebagian besar modul.
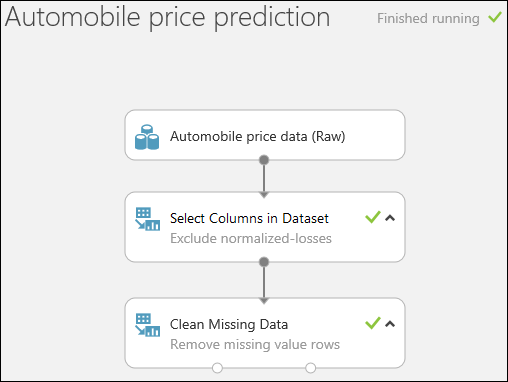
Pertama, kami menambahkan modul yang menghapus kolom kerugian yang dinormalisasi sepenuhnya. Kemudian kami menambahkan modul lain yang menghapus setiap baris yang kehilangan data.
Ketik pilih kolom di kotak pencarian di bagian atas palet modul untuk menemukan modul Pilih Kolom di Himpunan Data. Kemudian seret ke kanvas eksperimen. Modul ini memungkinkan kita untuk memilih kolom data mana yang ingin kita sertakan atau kecualikan dalam model.
Hubungkan port keluaran dari himpunan data Data Harga Mobil (Mentah) ke port masukan dari Pilih Kolom dalam Himpunan Data.
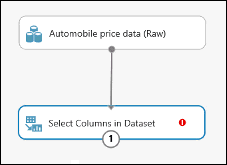
Klik modul Pilih Kolom di Himpunan Data lalu klik Buka pemilih kolom di panel Properti.
Di sebelah kiri, klik Dengan aturan
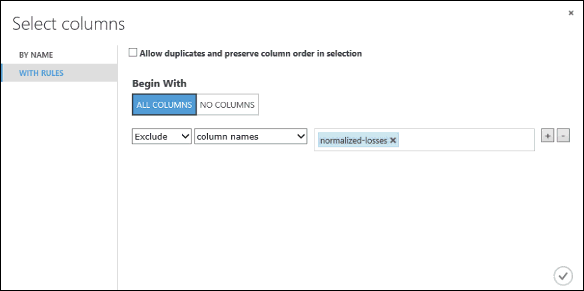
Pada Mulai Dengan, klik Semua kolom. Aturan ini mengarahkan Pilih Kolom di Himpunan Data untuk melewati semua kolom (kecuali kolom yang akan kami kecualikan).
Dari menu pilihan, pilih Kecualikan dan nama kolom, lalu klik di dalam kotak teks. Daftar kolom akan ditampilkan. Pilih kerugian yang dinormalisasi, dan akan ditambahkan ke kotak teks.
Klik tombol tanda centang (OK) untuk menutup pemilih kolom (di kanan bawah).
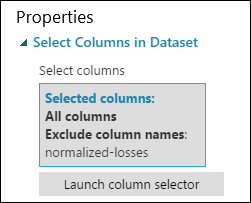
Sekarang panel properti untuk Pilih Kolom di Himpunan Data menunjukkan bahwa ia akan melewati semua kolom dari himpunan data kecuali kerugian yang dinormalisasi.
Tip
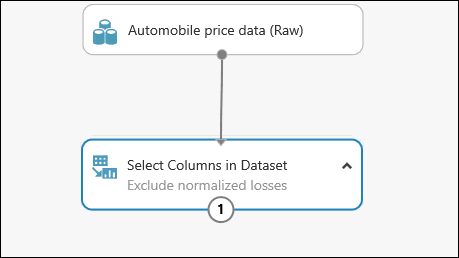
Anda dapat menambahkan komentar ke modul dengan mengklik dua kali modul dan memasukkan teks. Ini dapat membantu Anda melihat sekilas apa yang dilakukan modul dalam eksperimen Anda. Dalam hal ini klik dua kali modul Pilih Kolom di Himpunan Data lalu ketikkan komentar "Kecualikan kerugian yang dinormalisasi".
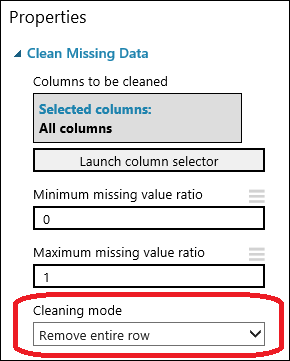
Seret modul Bersihkan Data yang Hilang ke kanvas eksperimen lalu hubungkan ke modul Pilih Kolom di Himpunan Data. Di panel Properti, pilih Hapus seluruh baris pada Mode pembersihan. Opsi ini mengarahkan Bersihkan Data yang Hilang untuk membersihkan data dengan menghapus baris yang memiliki nilai hilang. Klik dua kali modul lalu ketik komentar "Hapus baris nilai yang hilang".
Jalankan eksperimen dengan mengklik JALANKAN di bagian bawah halaman.
Ketika percobaan selesai berjalan, semua modul memiliki tanda centang hijau untuk menunjukkan bahwa telah berhasil selesai. Perhatikan juga status Selesai berjalan di sudut kanan atas.
Tips
Mengapa kita menjalankan eksperimen sekarang? Dengan menjalankan eksperimen, definisi kolom untuk data kami diteruskan dari himpunan data, melalui modul Pilih Kolom di Himpunan Data, dan melalui modul Bersihkan Data yang Hilang. Ini berarti bahwa setiap modul yang kami hubungkan ke Bersihkan Data yang Hilang juga akan memiliki informasi yang sama ini.
Sekarang kita memiliki data yang bersih. Jika Anda ingin melihat set data yang dibersihkan, klik port output kiri dari modul Bersihkan Data yang Hilang lalu pilih Visualisasi. Perhatikan bahwa kolom kerugian yang dinormalisasi tidak lagi disertakan, dan tidak ada nilai hilang.
Sekarang setelah data bersih, kami siap untuk menentukan fitur apa yang akan kami gunakan dalam model prediktif.
Menentukan fitur
Dalam pembelajaran mesin, fitur adalah properti terukur individual dari sesuatu yang Anda minati. Dalam himpunan data kami, setiap baris mewakili satu mobil, dan setiap kolom adalah fitur mobil tersebut.
Menemukan serangkaian fitur yang baik untuk membuat model prediktif membutuhkan eksperimen dan pengetahuan tentang masalah yang ingin Anda selesaikan. Beberapa fitur lebih baik untuk memprediksi target daripada fitur yang lain. Beberapa fitur memiliki korelasi yang kuat dengan fitur lain dan dapat dihapus. Misalnya, mpg-kota dan mpg-jalan raya saling berkaitan erat sehingga kita dapat mempertahankan satu dan menghapus yang lain tanpa secara signifikan mempengaruhi prediksi.
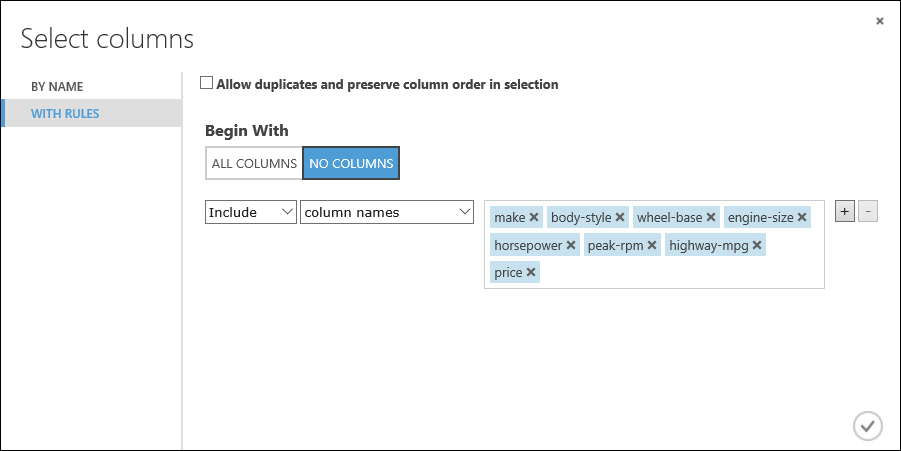
Mari kita buat model yang menggunakan subset fitur dalam himpunan data kami. Anda dapat kembali nanti dan memilih fitur yang lain, menjalankan eksperimen lagi, dan melihat apakah Anda mendapatkan hasil yang lebih baik. Namun untuk memulai, mari kita coba fitur-fitur berikut:
merek, gaya bodi, jarak sumbu roda, ukuran mesin, tenaga kuda, putaran maksimum, konsumsi bahan bakar jalan raya, harga
Seret modul Pilih Kolom di Himpunan Data lain ke kanvas eksperimen. Hubungkan port output kiri modul Bersihkan Data yang Hilang ke input modul Pilih Kolom di Himpunan Data.
Klik dua kali modul lalu ketik "Pilih fitur untuk prediksi".
Klik Luncurkan pemilih kolom di panel Properti.
Klik Dengan aturan.
Pada Mulai Dengan, klik Tanpa kolom. Di baris filter, pilih Sertakan dan nama kolom lalu pilih daftar nama kolom kami di kotak teks. Filter ini mengarahkan modul untuk tidak melewati kolom (fitur) apa pun kecuali yang kami tentukan.
Klik tombol tanda centang (OK).
Modul ini menghasilkan himpunan data yang difilter yang hanya berisi fitur yang ingin kami berikan ke algoritma pembelajaran yang akan kami gunakan pada langkah berikutnya. Nantinya, Anda dapat kembali dan mencoba lagi dengan berbagai pilihan fitur.
Memilih dan menerapkan algoritma
Sekarang setelah data siap, membangun model prediktif terdiri dari pelatihan dan pengujian. Kami akan menggunakan data kami untuk melatih model, lalu kami akan menguji model tersebut guna melihat seberapa dekat ia dapat memprediksi harga.
Klasifikasi dan regresi adalah dua jenis algoritma pembelajaran mesin yang diawasi. Klasifikasi memprediksi jawaban dari kumpulan kategori yang ditentukan, seperti warna (merah, biru, atau hijau). Regresi digunakan untuk memprediksi angka.
Karena kita ingin memprediksi harga, yang merupakan angka, kita akan menggunakan algoritma regresi. Untuk contoh ini, kita akan menggunakan model regresi linear.
Kita melatih model dengan memberikan himpunan data yang mencakup harga. Model tersebut memindai data dan mencari korelasi antara fitur mobil dan harganya. Kemudian kita akan menguji model - kita akan memberikan satu set fitur untuk mobil yang kita kenal dan melihat seberapa dekat model tersebut untuk dapat memprediksi harga yang diketahui.
Kita akan menggunakan data kita untuk melatih model dan mengujinya dengan membagi data menjadi himpunan data pelatihan dan pengujian terpisah.
Pilih dan seret modul Pisahkan Data ke kanvas eksperimen lalu hubungkan ke modul Pilih Kolom di Himpunan Data yang terakhir.
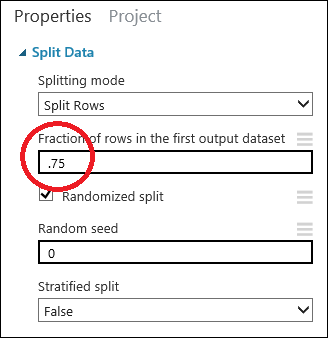
Klik modul Pisahkan Data untuk memilihnya. Temukan Pecahan baris di himpunan data output pertama (di panel Properti di sebelah kanan kanvas) dan atur ke 0,75. Dengan cara ini, kita akan menggunakan 75 persen data untuk melatih model, dan menahan 25 persen untuk pengujian.
Petunjuk
Dengan mengubah parameter Biji acak, Anda dapat menghasilkan sampel acak yang berbeda untuk pelatihan dan pengujian. Parameter ini mengontrol pemulaian generator bilangan acak semu.
Jalankan eksperimen. Saat eksperimen dijalankan, modul Pilih Kolom di Himpunan Data dan Pisahkan Data meneruskan definisi kolom ke modul yang akan kita tambahkan berikutnya.
Untuk memilih algoritma pembelajaran, perluas kategori Pembelajaran Mesin di palet modul di sebelah kiri kanvas, lalu perluas Model Inisialisasi. Ini menampilkan beberapa kategori modul yang dapat digunakan untuk menginisialisasi algoritma pembelajaran mesin. Untuk eksperimen ini, pilih modul Regresi Linear pada kategori Regresi, lalu seret ke kanvas eksperimen. (Anda juga dapat menemukan modul dengan mengetik "regresi linear" di kotak Pencarian palet.)
Temukan dan seret modul Latih Model ke kanvas eksperimen. Hubungkan output modul Regresi Linear ke input kiri modul Latih Model, lalu hubungkan output data pelatihan (port kiri) modul Pisahkan Data ke input kanan modul Latih Model.
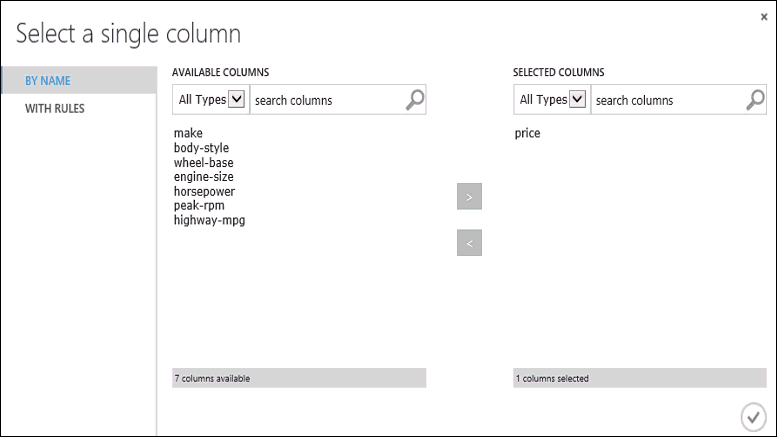
Klik modul Latih Model, lalu klik Buka pemilih kolom di panel Properti, dan pilih kolom harga. Harga adalah nilai yang akan diprediksi model kita.
Anda memilih kolom harga di pemilih kolom dengan memindahkannya dari daftar Kolom yang tersedia ke daftar Kolom yang dipilih.
Jalankan eksperimen.
Kita sekarang memiliki model regresi terlatih yang dapat digunakan untuk menilai data mobil baru untuk membuat prediksi harga.
Memprediksi harga mobil baru
Sekarang kita telah melatih model menggunakan 75 persen data, kita dapat menggunakannya untuk menilai 25 persen data lainnya untuk melihat seberapa baik fungsi model kita.
Temukan dan seret modul Nilai Model ke kanvas eksperimen. Hubungkan keluaran modul Model Pelatihan ke port input kiri Model Penilaian. Sambungkan output data pengujian (port kanan) modul Data Terpisah ke port input kanan Model Skor.
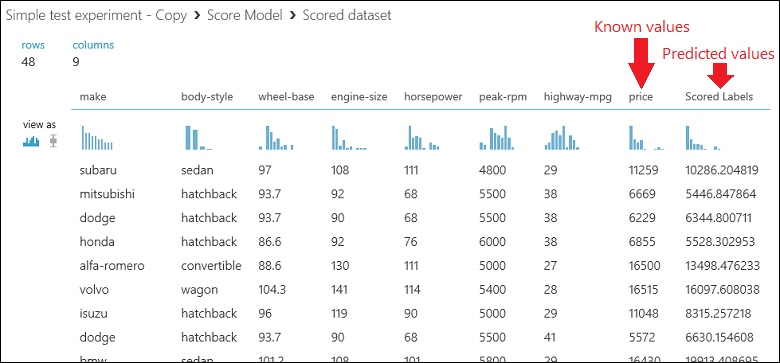
Jalankan eksperimen lalu lihat output dari modul Nilai Model dengan mengklik port output Nilai Model lalu pilih Visualisasi. Output tersebut menunjukkan nilai yang diprediksi untuk harga dan nilai yang diketahui dari data pengujian.
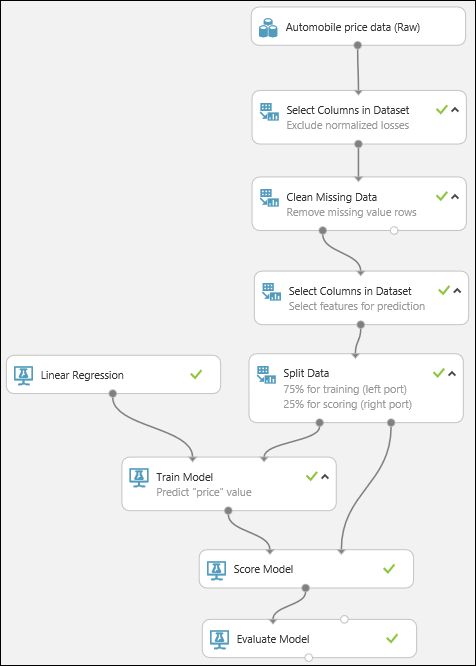
Terakhir, kita menguji kualitas hasilnya. Pilih dan seret modul Evaluasi Model ke kanvas eksperimen, lalu hubungkan output modul Nilai Model ke input kiri Evaluasi Model. Eksperimen terakhir seharusnya terlihat seperti ini:
Jalankan eksperimen.
Untuk melihat output dari modul Evaluasi Model, klik port output, lalu pilih Visualisasi.
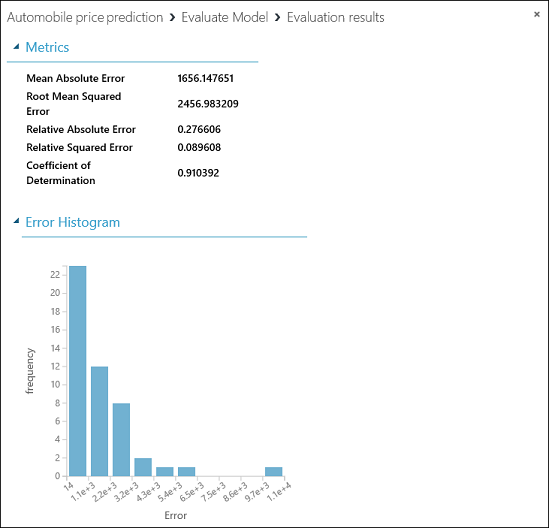
Statistik berikut ditampilkan untuk model kita:
- Kesalahan Absolut Rata-Rata (MAE): Rata-rata kesalahan absolut (kesalahan adalah selisih antara nilai yang diprediksi dan nilai aktual).
- Kesalahan Kuadrat Rata-rata Akar (RMSE): Akar kuadrat dari rata-rata kesalahan kuadrat dari prediksi yang dibuat pada himpunan data pengujian.
- Kesalahan Absolut Relatif: Rata-rata kesalahan absolut relatif terhadap selisih absolut antara nilai aktual dan rata-rata semua nilai aktual.
- Kesalahan Kuadrat Relatif: Rata-rata kesalahan kuadrat relatif terhadap selisih kuadrat antara nilai aktual dan rata-rata semua nilai aktual.
- Koefisien Penentuan: Juga disebut sebagai nilai kuadrat R, ini adalah metrik statistik yang menunjukkan seberapa baik model cocok dengan data.
Untuk setiap statistik kesalahan, lebih kecil lebih baik. Nilai yang lebih kecil menunjukkan bahwa prediksi lebih cocok dengan nilai aktual. Untuk Koefisien Penentuan, semakin dekat nilainya dengan satu (1,0), semakin baik prediksinya.
Membersihkan sumber daya
Jika Anda tidak lagi memerlukan sumber daya yang Anda buat menggunakan artikel ini, hapus untuk menghindari dikenakan biaya apa pun. Pelajari caranya dalam artikel, Mengekspor dan menghapus data pengguna dalam produk.
Langkah berikutnya
Dalam panduan cepat ini, Anda telah membuat eksperimen sederhana menggunakan set data sampel. Untuk menjelajahi proses pembuatan dan penyebaran model secara lebih mendalam, lanjutkan ke tutorial solusi prediktif.