Tutorial 1: Memprediksi risiko kredit - Azure Machine Learning Studio (klasik)
BERLAKU UNTUK: Machine Learning Studio (klasik)
Machine Learning Studio (klasik)  Azure Machine Learning
Azure Machine Learning
Penting
Dukungan untuk Studio Azure Machine Learning (klasik) akan berakhir pada 31 Agustus 2024. Sebaiknya Anda transisi ke Azure Machine Learning sebelum tanggal tersebut.
Mulai 1 Desember 2021, Anda tidak akan dapat membuat sumber daya Studio Azure Machine Learning (klasik) baru. Hingga 31 Agustus 2024, Anda dapat terus menggunakan sumber daya Pembelajaran Mesin Studio (klasik) yang ada.
- Lihat informasi tentang memindahkan proyek pembelajaran mesin dari ML Studio (klasik) ke Azure Machine Learning.
- Pelajari Azure Machine Learning
ML Dokumentasi Studio (klasik) sedang berhenti dan mungkin tidak diperbarui di masa mendatang.
Dalam tutorial ini, Anda melihat proses pengembangan solusi analisis prediktif. Anda mengembangkan model sederhana di Machine Learning Studio (klasik). Kemudian, Anda menyebarkan model sebagai layanan web Azure Machine Learning. Model yang disebarkan ini dapat membuat prediksi menggunakan data baru. Tutorial ini adalah bagian pertama dari seri tutorial tiga bagian.
Misalkan Anda perlu memprediksi risiko kredit seseorang berdasarkan informasi yang mereka berikan pada aplikasi kredit.
Penilaian risiko kredit adalah masalah yang kompleks, tetapi tutorial ini akan sedikit menyederhanakannya. Anda akan menggunakannya sebagai contoh cara membuat solusi analitik prediktif menggunakan Azure Machine Learning Studio (klasik). Anda akan menggunakan Azure Machine Learning Studio (klasik) dan layanan web Azure Machine Learning untuk solusi ini.
Dalam tutorial tiga bagian ini, Anda memulai dengan data risiko kredit yang tersedia untuk umum. Kemudian Anda mengembangkan dan melatih model prediktif. Terakhir, Anda menyebarkan model sebagai layanan web.
Di bagian tutorial ini Anda:
- Membuat ruang kerja Machine Learning Studio (klasik)
- Mengunggah data yang sudah ada
- Membuat eksperimen
Anda kemudian dapat menggunakan eksperimen ini untuk melatih model di bagian 2, lalu menyebarkannya di bagian 3.
Prasyarat
Tutorial ini mengasumsikan bahwa Anda telah menggunakan Machine Learning Studio (klasik) minimal sekali sebelumnya, dan bahwa Anda memiliki beberapa pemahaman tentang konsep pembelajaran mesin. Namun itu juga tidak menganggap Anda seorang ahli.
Jika Anda belum pernah menggunakan Azure Machine Learning Studio (klasik) sebelumnya, sebaiknya mulai dengan panduan mulai cepat, Membuat eksperimen ilmu data pertama Anda di Azure Machine Learning Studio (klasik). Mulai cepat akan membawa Anda melalui Machine Learning Studio (klasik) untuk pertama kalinya. Ini menunjukkan dasar-dasar cara menyeret dan meletakkan modul ke eksperimen Anda, menghubungkannya bersama-sama, menjalankan eksperimen, dan melihat hasilnya.
Tip
Anda dapat menemukan salinan eksperimen yang berfungsi yang Anda kembangkan dalam tutorial ini di Galeri Azure AI. Buka Tutorial - Prediksi risiko kredit dan klik Buka di Studio untuk mengunduh salinan eksperimen ke ruang kerja Machine Learning Studio (klasik).
Membuat ruang kerja Machine Learning Studio (klasik)
Untuk menggunakan Azure Machine Learning Studio (klasik), Anda harus memiliki ruang kerja Azure Machine Learning Studio (klasik). Ruang kerja ini berisi alat yang Anda butuhkan untuk membuat, mengelola, dan menerbitkan eksperimen.
Untuk membuat ruang kerja, lihat Membuat dan berbagi ruang kerja Azure Machine Learning Studio (klasik).
Setelah ruang kerja Anda dibuat, buka Studio Pembelajaran Mesin (klasik) (https://studio.azureml.net/Home). Jika Anda memiliki lebih dari satu ruang kerja, Anda dapat memilih ruang kerja di bar alat di sudut kanan atas jendela.
Tip
Jika Anda adalah pemilik ruang kerja, Anda dapat berbagi eksperimen yang sedang Anda kerjakan dengan mengundang orang lain ke ruang kerja. Anda dapat melakukan ini di Machine Learning Studio (klasik) di halaman PENGATURAN. Anda hanya memerlukan akun Microsoft atau akun organisasi untuk setiap pengguna.
Pada halaman PENGATURAN, klik PENGGUNA, lalu klik UNDANG LEBIH BANYAK PENGGUNA pada bagian bawah jendela.
Mengunggah data yang sudah ada
Untuk mengembangkan model prediktif untuk risiko kredit, Anda memerlukan data yang dapat Anda gunakan untuk melatih lalu menguji model. Untuk tutorial ini, Anda akan menggunakan "Himpunan Data UCI Statlog (German Credit Data)" dari repositori Pembelajaran Mesin UC Irvine. Anda dapat menemukannya di sini:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Anda akan menggunakan file bernama german.data. Unduh file ini ke hard drive lokal Anda.
Himpunan data german.data berisi baris 20 variabel untuk 1000 pemohon kredit sebelumnya. 20 variabel ini mewakili serangkaian fitur set himpunan data (vektor fitur), yang menyediakan karakteristik identifikasi untuk setiap pemohon kredit. Kolom tambahan di setiap baris menunjukkan risiko kredit terhitung pemohon, dengan 700 pemohon diidentifikasi sebagai risiko kredit rendah dan 300 sebagai risiko kredit tinggi.
Situs web UCI menyediakan deskripsi atribut vektor fitur untuk data ini. Data ini mencakup informasi keuangan, riwayat kredit, status pekerjaan, dan informasi pribadi. Untuk setiap pemohon, peringkat biner telah diberikan menunjukkan apakah mereka berisiko kredit rendah atau tinggi.
Anda akan menggunakan data ini untuk melatih model analitik prediktif. Setelah selesai, model Anda harus dapat menerima vektor fitur untuk individu baru dan memprediksi apakah mereka berisiko kredit rendah atau tinggi.
Berikut adalah twist yang menarik.
Deskripsi himpunan data di situs web UCI menyebutkan berapa biayanya jika Anda salah mengklasifikasikan risiko kredit seseorang. Jika model memprediksi risiko kredit yang tinggi untuk seseorang yang sebenarnya berisiko kredit rendah, model telah membuat kesalahan klasifikasi.
Tetapi kesalahan klasifikasi terbalik adalah lima kali lebih mahal bagi lembaga keuangan: jika model memprediksi risiko kredit yang rendah untuk seseorang yang sebenarnya berisiko kredit tinggi.
Jadi, Anda ingin melatih model sehingga biaya jenis kesalahan klasifikasi ini lima kali lebih tinggi alih-alih salah klasifikasi dengan cara lain.
Salah satu cara sederhana untuk melakukan ini ketika melatih model dalam eksperimen Anda adalah dengan menduplikasi (lima kali) entri yang mewakili seseorang dengan risiko kredit tinggi.
Lalu, jika model salah mengklasifikasikan seseorang sebagai risiko kredit rendah ketika mereka sebenarnya berisiko tinggi, model melakukan kesalahan klasifikasi yang sama lima kali, sekali untuk setiap duplikat. Ini akan meningkatkan biaya kesalahan ini dalam hasil pelatihan.
Mengonversi format himpunan data
Himpunan data asli menggunakan format yang dipisahkan kosong. Machine Learning Studio (klasik) berfungsi lebih baik dengan file nilai yang dipisahkan koma (CSV), sehingga Anda akan mengonversi himpuna data dengan mengganti spasi dengan koma.
Ada banyak cara untuk mengonversi data ini. Salah satu caranya adalah dengan menggunakan perintah Windows PowerShell berikut ini:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Cara lain adalah dengan menggunakan perintah sed Unix:
sed 's/ /,/g' german.data > german.csv
Dalam kedua kasus, Anda telah membuat versi data yang dipisahkan koma dalam file bernama german.csv yang dapat Anda gunakan dalam eksperimen Anda.
Mengunggah himpunan data ke Machine Learning Studio (klasik)
Setelah data dikonversi ke format CSV, Anda harus mengunggahnya ke Machine Learning Studio (klasik).
Buka halaman beranda Machine Learning Studio (klasik) (https://studio.azureml.net).
Klik menu
 di sudut kiri atas jendela, klik Azure Machine Learning, pilih Studio, dan masuk.
di sudut kiri atas jendela, klik Azure Machine Learning, pilih Studio, dan masuk.Klik +BARU pada bagian bawah jendela.
Pilih HIMPUNAN DATA.
Pilih DARI FILE LOKAL.
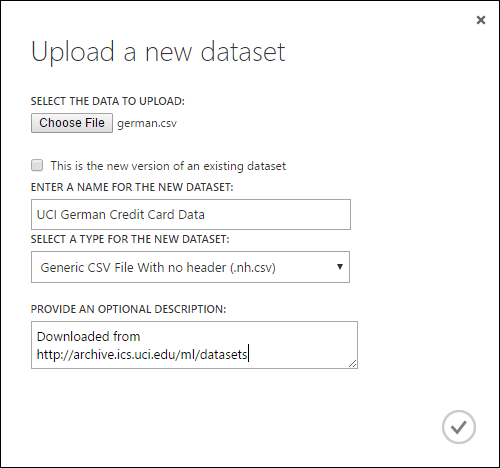
Dalam dialog Unggah himpunan data baru, klik Telusuri, dan temukan german.csv yang Anda buat.
Masukkan nama untuk himpunan data tersebut. Untuk tutorial ini, sebut saja "Data Kartu Kredit Jerman UCI".
Untuk tipe data, pilih File CSV Generik Tanpa header (.nh.csv) .
Tambahkan deskripsi jika Anda inginkan.
Klik tanda centang OK.
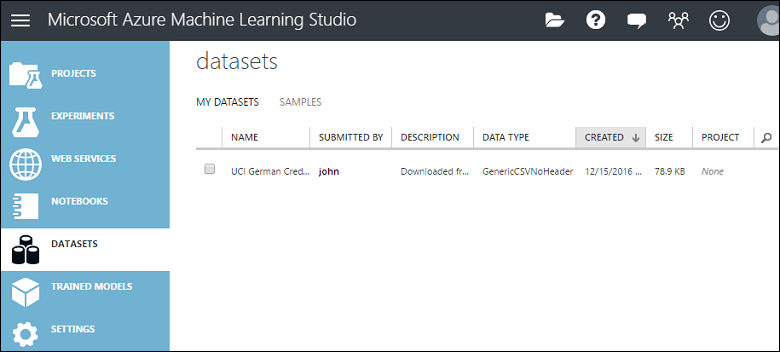
Ini mengunggah data ke dalam modul himpunan data yang dapat Anda gunakan dalam eksperimen.
Anda dapat mengelola himpunan data yang telah Anda unggah ke Studio (klasik) dengan mengklik tab HIMPUNAN DATA di sebelah kiri jendela Studio (klasik).
Untuk informasi selengkapnya tentang cara mengimpor jenis data lain ke dalam eksperimen, lihat Mengimpor data pelatihan Anda ke Azure Machine Learning Studio (klasik).
Membuat eksperimen
Langkah selanjutnya dalam tutorial ini adalah membuat eksperimen di Machine Learning Studio (klasik) yang menggunakan himpunan data yang Anda unggah.
Di Studio (klasik), klik +BARU pada bagian bawah jendela.
Pilih EKSPERIMEN, lalu pilih "Eksperimen Kosong".
Pilih nama eksperimen default di bagian atas kanvas dan ganti namanya menjadi sesuatu yang bermakna.

Tip
Ini adalah praktik yang baik untuk mengisi Ringkasan dan Deskripsi untuk eksperimen di panel Properti. Properti ini memberi Anda kesempatan untuk mendokumentasikan eksperimen sehingga siapa pun yang melihat nantinya akan memahami tujuan dan metodologi Anda.

Di palet modul di sebelah kiri kanvas eksperimen, perluas Himpunan Data Tersimpan.
Temukan himpunan data yang Anda buat pada Himpunan Data Saya, dan seret ke kanvas. Anda juga bisa menemukan himpunan data dengan memasukkan nama di kotak Pencarian di atas palet.
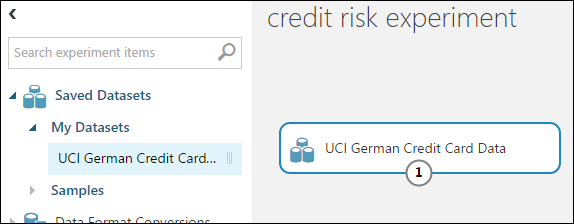
Menyiapkan data
Anda dapat melihat 100 baris pertama data dan beberapa informasi statistik untuk seluruh kumpulan data: Klik port output himpunan data (lingkaran kecil di bagian bawah) dan pilih Visualisasikan.
Karena file data tidak dilengkapi dengan judul kolom, Studio (klasik) telah menyediakan judul generik (Col1, Col2, dll. ). Judul yang baik tidak penting untuk membuat model, tetapi mereka membuatnya lebih mudah untuk bekerja dengan data dalam percobaan. Juga, ketika Anda akhirnya menerbitkan model ini dalam layanan web, judul membantu mengidentifikasi kolom kepada pengguna layanan.
Anda dapat menambahkan judul kolom menggunakan modul Edit Metadata.
Anda menggunakan modul Edit Metadata untuk mengubah metadata yang terkait dengan himpunan data. Dalam hal ini, Anda menggunakannya untuk memberikan nama yang lebih ramah untuk judul kolom.
Untuk menggunakan Edit Metadata, Anda terlebih dahulu menentukan kolom mana yang akan dimodifikasi (dalam hal ini, semuanya). Selanjutnya, Anda menentukan tindakan yang akan dilakukan pada kolom tersebut (dalam hal ini, mengubah judul kolom.)
Di palet modul, ketik "metadata" di kotak Pencarian. Edit Metadata muncul di daftar modul.
Klik dan seret modul Edit Metadata ke kanvas dan letakkan di bawah himpunan data yang Anda tambahkan sebelumnya.
Sambungkan himpunan data ke Edit Metadata: klik port output himpunan data (lingkaran kecil di bagian bawah himpunan data), tarik ke port input Edit Metadata (lingkaran kecil di bagian atas modul), lalu lepaskan tombol mouse. Himpunan data dan modul tetap terhubung meskipun Anda bergerak di sekitar kanvas.
Eksperimen seharusnya terlihat seperti ini sekarang:
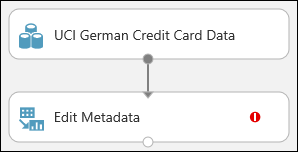
Tanda seru merah menunjukkan bahwa Anda belum menetapkan properti untuk modul ini. Anda akan melakukan hal tersebut berikutnya.
Tip
Anda dapat menambahkan komentar ke modul dengan mengklik dua kali modul dan memasukkan teks. Ini dapat membantu Anda melihat sekilas apa yang dilakukan modul dalam eksperimen Anda. Dalam hal ini, klik dua kali modul Edit Metadata, dan ketikkan komentar "Tambahkan judul kolom". Klik di mana saja pada kanvas untuk menutup kotak teks. Untuk menampilkan komentar, klik tanda panah bawah pada modul.
Pilih Edit Metadata, dan di panel Properti di sebelah kanan kanvas, klik Luncurkan pemilih kolom.
Dalam dialog Pilih kolom, pilih semua baris di Kolom yang Tersedia dan klik > untuk memindahkannya ke Kolom yang Dipilih. Output seharusnya terlihat seperti ini:
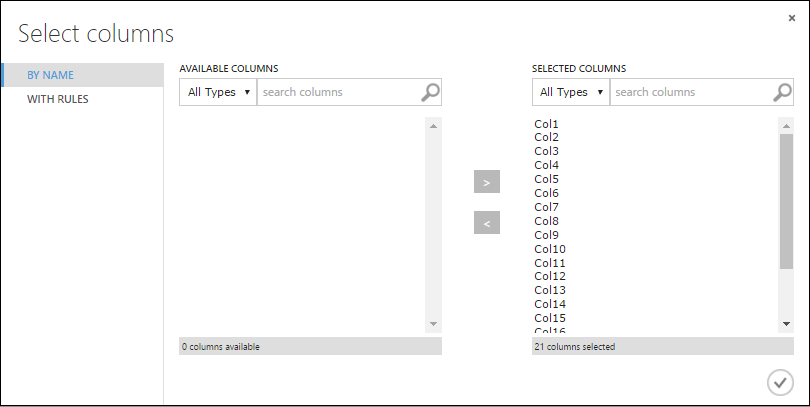
Klik tanda centang OK.
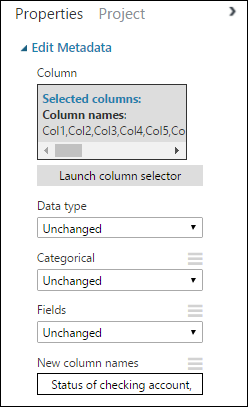
Kembali di panel Properti, cari parameter Nama kolom baru. Di bidang ini, masukkan daftar nama untuk 21 kolom dalam himpunan data, dipisahkan dengan koma dan dalam urutan kolom. Anda bisa mendapatkan nama kolom dari dokumentasi himpunan data di situs web UCI, atau agar nyaman, Anda dapat menyalin dan menempelkan daftar berikut:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskPanel Properti terlihat seperti ini:
Tip
Jika Anda ingin memverifikasi judul kolom, jalankan eksperimen (klik JALANKAN di bawah kanvas eksperimen). Ketika selesai berjalan (tanda centang hijau muncul pada Edit Metadata), klik port output modul Edit Metadata, lalu pilih Visualisasikan. Anda dapat melihat semua output modul dengan cara yang sama untuk melihat kemajuan data melalui eksperimen.
Membuat pelatihan dan menguji himpunan data
Anda perlu beberapa data untuk melatih model dan beberapa data untuk mengujinya. Jadi pada langkah eksperimen berikutnya, Anda membagi himpunan data menjadi dua himpunan data terpisah: satu untuk melatih model kami dan satu lagi untuk mengujinya.
Untuk melakukan ini, Anda menggunakan modul Pisahkan Data.
Temukan modul Pisahkan Data, tarik ke kanvas, dan sambungkan ke modul Edit Metadata.
Secara default, rasio pemisahan adalah 0,5 dan parameter Pemisahan acak diatur. Ini berarti bahwa setengah acak data dihasilkan melalui satu port modul Pisahkan Data, dan setengahnya melalui port yang lain. Anda dapat menyesuaikan parameter ini, serta parameter Benih acak, untuk mengubah pemisahan antara data pelatihan dan pengujian. Untuk contoh ini, Anda membiarkan data apa adanya.
Tip
Properti Pecahan baris dalam himpunan data output pertama menentukan berapa banyak data yang dihasilkan melalui port output kiri. Misalnya, jika Anda mengatur rasio menjadi 0,7, maka 70% data dihasilkan melalui port kiri dan 30% melalui port kanan.
Klik dua kali modul Pisahkan Data dan masukkan komentar, "Data pelatihan/pengujian dibagi 50%".
Anda dapat menggunakan output modul Pisahkan Data sesuai keinginan, tetapi mari kita pilih untuk menggunakan output kiri sebagai data pelatihan dan output yang tepat sebagai data pengujian.
Seperti disebutkan pada langkah sebelumnya, biaya kesalahan klasifikasi risiko kredit tinggi adalah lima kali lebih tinggi dibandingkan biaya kesalahan klasifikasi risiko kredit rendah yang tinggi. Untuk memperhitungkan hal ini, Anda menghasilkan himpunan data baru yang mencerminkan fungsi biaya ini. Dalam himpunan data baru, setiap contoh risiko tinggi direplikasi lima kali, sementara setiap contoh risiko rendah tidak direplikasi.
Anda dapat melakukan replikasi ini menggunakan kode R:
Temukan dan tarik modul Jalankan Skrip R ke kanvas eksperimen.
Sambungkan port output kiri modul Pisahkan Data ke port input pertama ("Dataset1") dari modul Jalankan Skrip R.
Klik dua kali modul Jalankan Skrip R, dan masukkan komentar, "Atur penyesuaian biaya".
Di panel Properti, hapus teks default di parameter Skrip R, dan masukkan skrip ini:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")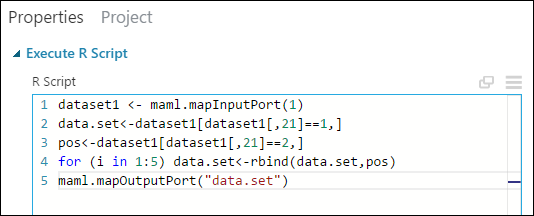
Anda harus melakukan operasi replikasi yang sama ini untuk setiap output modul Pisahkan Data, sehingga data pelatihan dan pengujian memiliki penyesuaian biaya yang sama. Cara termudah untuk melakukan ini adalah dengan menduplikasi modul Jalankan Skrip R yang baru saja Anda buat, dan menghubungkannya ke port output lain dari modul Pisahkan Data.
Klik kanan modul Jalankan Skrip R dan pilih Salin.
Klik kanan kanvas eksperimen dan pilih Tempel.
Tarik modul baru ke posisi, lalu sambungkan port output kanan modul Pisahkan Data ke port input pertama modul Jalankan Skrip R baru ini.
Di bagian bawah kanvas, klik Jalankan.
Tip
Salinan modul Jalankan Skrip R berisi skrip yang sama dengan modul asli. Saat Anda menyalin dan menempelkan modul di kanvas, salinan mempertahankan semua properti aslinya.
Eksperimen kita sekarang terlihat seperti ini:
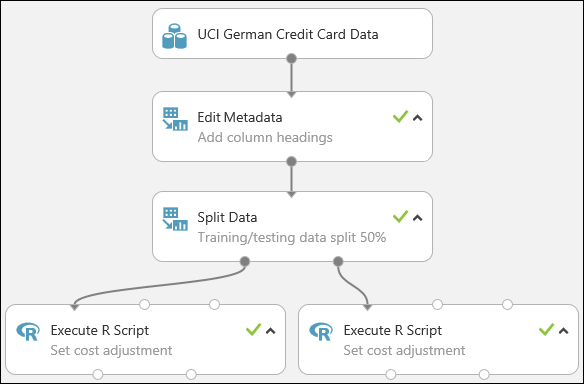
Untuk informasi selengkapnya tentang menggunakan skrip R dalam eksperimen Anda, lihat Memperluas eksperimen Anda dengan R.
Bersihkan sumber daya
Jika Anda tidak lagi memerlukan sumber daya yang Anda buat menggunakan artikel ini, hapus untuk menghindari dikenakan biaya apa pun. Pelajari caranya dalam artikel, Mengekspor dan menghapus data pengguna dalam produk.
Langkah berikutnya
Dalam tutorial ini Anda menyelesaikan langkah-langkah ini:
- Membuat ruang kerja Machine Learning Studio (klasik)
- Mengunggah data yang sudah ada ke dalam ruang kerja
- Membuat eksperimen
Anda sekarang siap untuk melatih dan mengevaluasi model untuk data ini.