Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Studio Pembelajaran Mesin (klasik)
Studio Pembelajaran Mesin (klasik)  Azure Machine Learning
Azure Machine Learning
Penting
Dukungan untuk Studio Azure Machine Learning (klasik) akan berakhir pada 31 Agustus 2024. Sebaiknya Anda transisi ke Azure Machine Learning sebelum tanggal tersebut.
Mulai 1 Desember 2021, Anda tidak akan dapat membuat sumber daya Studio Azure Machine Learning (klasik) baru. Hingga 31 Agustus 2024, Anda dapat terus menggunakan sumber daya Pembelajaran Mesin Studio (klasik) yang ada.
- Lihat informasi tentang memindahkan proyek pembelajaran mesin dari ML Studio (klasik) ke Azure Machine Learning.
- Pelajari lebih lanjut tentang Azure Machine Learning
Dokumentasi ML Studio Klasik sedang dihentikan dan mungkin tidak akan diperbarui di masa mendatang.
Untuk menggunakan data Anda sendiri di Machine Learning Studio (klasik) untuk mengembangkan dan melatih solusi analisis prediktif, Anda dapat menggunakan data dari:
- File lokal - Muat data lokal sebelumnya dari hard drive Anda untuk membuat modul himpunan data di ruang kerja Anda
- Sumber data online - Gunakan modul Impor Data untuk mengakses data dari salah satu dari beberapa sumber online saat eksperimen Anda berjalan
- Eksperimen Machine Learning Studio (klasik) - Gunakan data yang disimpan sebagai himpunan data di Machine Learning Studio (klasik)
- Database SQL Server - Gunakan data dari database SQL Server tanpa harus menyalin data secara manual
Catatan
Ada sejumlah contoh himpunan data yang tersedia di Machine Learning Studio (klasik) yang dapat Anda gunakan untuk data pelatihan. Untuk informasi tentang ini, lihat Menggunakan contoh himpunan data di Machine Learning Studio (klasik).
Siapkan data
Machine Learning Studio (klasik) dirancang untuk bekerja dengan data persegi panjang atau tabular, seperti data teks yang dipisahkan atau data terstruktur dari database, meskipun dalam beberapa keadaan data non-persegi panjang dapat digunakan.
Yang terbaik adalah jika data Anda relatif bersih sebelum Anda mengimpornya ke Studio (klasik). Misalnya, Anda akan ingin mengurus masalah seperti string tanpa tanda kutip.
Namun, ada modul yang tersedia di Studio (klasik) yang memungkinkan beberapa manipulasi data dalam eksperimen setelah Anda mengimpor data. Tergantung pada algoritme pembelajaran mesin yang akan digunakan, Anda mungkin perlu memutuskan cara menangani masalah struktural data seperti nilai yang hilang dan data yang jarang, dan modul yang dapat membantu. Lihat di bagian Transformasi Data dari palet modul untuk modul yang melakukan fungsi-fungsi ini.
Pada titik mana pun dalam eksperimen, Anda dapat melihat atau mengunduh data yang dihasilkan oleh modul dengan mengklik port output. Tergantung modul, mungkin ada berbagai opsi unduhan yang tersedia, atau Anda mungkin dapat memvisualisasikan data dalam browser web Anda di Studio (klasik).
Format data dan tipe data yang didukung
Anda bisa mengimpor sejumlah tipe data ke eksperimen, tergantung pada mekanisme yang Anda gunakan untuk mengimpor data dan asalnya:
- Teks biasa (.txt)
- Nilai yang dipisahkan koma (CSV) dengan header (.csv) atau tanpa (.nh.csv)
- Nilai yang dipisahkan tab (TSV) dengan header (.tsv) atau tanpa (.nh.tsv)
- File Excel
- Tabel Azure
- Tabel Hive
- Tabel database SQL
- Nilai OData
- Data SVMLight (.svmlight) (lihat definisi SVMLight untuk informasi format)
- Data Format File Hubungan Atribut (ARFF) (.arff) (lihat definisi ARFF untuk informasi format)
- File Zip (.zip)
- Objek R atau file ruang kerja (.RData)
Jika Anda mengimpor data dalam format seperti ARFF yang menyertakan metadata, Studio (klasik) menggunakan metadata ini untuk menentukan judul dan jenis data setiap kolom.
Jika Anda mengimpor data seperti format TSV atau CSV yang tidak menyertakan metadata ini, Studio (klasik) akan menyimpulkan jenis data untuk setiap kolom dengan mengambil sampel data. Jika data juga tidak memiliki judul kolom, Studio (klasik) menyediakan nama default.
Anda dapat secara eksplisit menentukan atau mengubah judul dan jenis data untuk kolom menggunakan modul Edit Metadata.
Jenis data berikut dikenali oleh Studio (klasik):
- String
- Bilangan bulat
- Ganda
- Boolean
- Tanggal dan Waktu
- Rentang Waktu
Studio menggunakan jenis data internal yang disebut tabel data untuk meneruskan data antara modul. Anda dapat secara eksplisit mengonversi data ke dalam format tabel data menggunakan modul Konversi ke Himpunan data.
Modul apa pun yang menerima format selain tabel data akan mengonversi data ke tabel data secara diam-diam sebelum meneruskannya ke modul berikutnya.
Jika perlu, Anda dapat mengonversi format tabel data kembali ke format CSV, TSV, ARFF, atau SVMLight menggunakan modul konversi lainnya. Lihat di bagian Konversi Format Data dari palet modul untuk modul yang melakukan fungsi-fungsi ini.
Kapasitas data
Modul di Machine Learning Studio (klasik) mendukung himpunan data hingga 10 GB data numerik padat untuk kasus penggunaan umum. Jika modul mengambil lebih dari satu input, nilai 10 GB adalah total semua ukuran input. Anda dapat mengambil sampel himpunan data yang lebih besar dengan menggunakan kueri dari Hive atau Azure SQL Database, atau Anda dapat menggunakan prapemrosesan Learning by Counts sebelum mengimpor data.
Jenis data berikut dapat diperluas ke himpunan data yang lebih besar selama normalisasi fitur dan dibatasi hingga kurang dari 10 GB:
- Jarang
- Kategorikal
- String
- Data biner
Modul berikut terbatas pada himpunan data kurang dari 10 GB:
- Modul pemberi rekomendasi
- Modul Synthetic Minority Oversampling Technique (SMOTE)
- Modul pembuatan skrip: R, Python, SQL
- Modul dimana ukuran data keluaran dapat lebih besar dari ukuran data masukan, seperti Join atau Feature Hashing
- Validasi silang, Sesuaikan Hyperparameter Model, Regresi Ordinal, dan Satu vs Semua Multikelas, ketika jumlah iterasi sangat besar
Untuk himpunan data yang lebih besar dari beberapa GB, unggah data ke Azure Storage atau Azure SQL Database, atau gunakan Azure HDInsight, daripada mengunggah langsung dari file lokal.
Anda dapat menemukan informasi tentang data gambar dalam referensi modulImpor Gambar.
Mengimpor dari file lokal
Anda dapat mengunggah file data dari hard drive untuk digunakan sebagai data pelatihan di Studio (klasik). Saat mengimpor file data, Anda membuat modul himpunan data yang siap digunakan dalam eksperimen di ruang kerja Anda.
Untuk mengimpor data dari hard drive lokal, lakukan hal berikut:
- Di Studio (klasik), klik +BARU pada bagian bawah jendela.
- Pilih HIMPUNAN DATA dan DARI FILE LOKAL.
- Dalam dialog Unggah himpunan data baru, telusuri ke file yang ingin Anda unggah.
- Masukkan nama, identifikasi jenis data, dan secara opsional masukkan deskripsi. Deskripsi disarankan - ini memungkinkan Anda untuk merekam karakteristik apa pun tentang data yang ingin Anda ingat saat menggunakan data di masa mendatang.
- Kotak centang Ini adalah versi baru dari himpunan data yang sudah ada memungkinkan Anda memperbarui himpunan data yang sudah ada dengan data baru. Untuk melakukannya, klik kotak centang ini lalu masukkan nama himpunan data yang sudah ada.
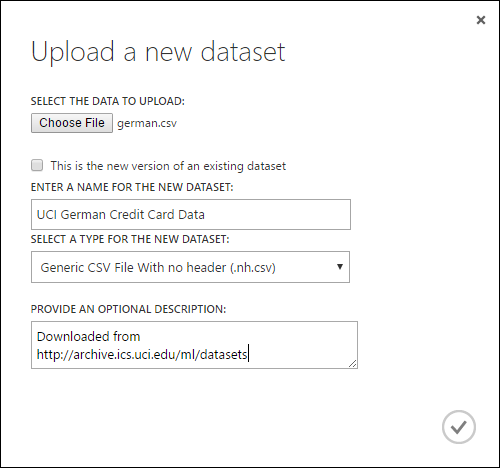
Waktu upload tergantung pada ukuran data Anda dan kecepatan koneksi Anda ke layanan. Jika Anda tahu file akan memakan waktu lama, Anda dapat melakukan hal-hal lain di dalam Studio (klasik) sambil menunggu. Namun, menutup browser sebelum pengunggahan data selesai menyebabkan unggahan gagal.
Setelah data Anda diunggah, data disimpan dalam modul himpunan data dan tersedia untuk eksperimen apa pun di ruang kerja Anda.
Saat mengedit eksperimen, Anda dapat menemukan himpunan data yang telah Anda unggah di daftar Himpunan Data Saya di bawah daftar Himpunan Data Tersimpan di palet modul. Anda dapat menyeret dan meletakkan himpunan data ke kanvas eksperimen saat Anda ingin menggunakan himpunan data untuk analitik dan pembelajaran mesin lebih lanjut.
Mengimpor dari sumber data online
Dengan menggunakan modul Impor Data, eksperimen Anda dapat mengimpor data dari berbagai sumber data online saat eksperimen berjalan.
Catatan
Artikel ini menyediakan informasi umum tentang modul Data Impor. Untuk informasi lebih rinci tentang jenis data yang dapat Anda akses, format, parameter, dan jawaban atas pertanyaan umum, lihat topik referensi modul untuk modul Impor Data.
Dengan menggunakan modul Impor Data, Anda dapat mengakses data dari salah satu sumber online saat eksperimen Anda berjalan:
- URL Web menggunakan HTTP
- Hadoop menggunakan HiveQL
- Penyimpanan blob Azure
- Tabel Azure
- Azure SQL Database. Instans Terkelola SQL, atau SQL Server
- Penyedia umpan data, OData saat ini
- Azure Cosmos DB
Karena data pelatihan ini diakses saat eksperimen Anda berjalan, data hanya tersedia dalam eksperimen itu. Sebagai perbandingan, data yang telah disimpan dalam modul himpunan data tersedia untuk eksperimen apa pun di ruang kerja Anda.
Untuk mengakses sumber data online di eksperimen Studio (klasik), tambahkan modul Impor Data ke eksperimen Anda. Lalu pilih Luncurkan Wizard Impor Data di bawah Properti untuk instruksi panduan langkah demi langkah untuk memilih dan mengonfigurasi sumber data. Atau, Anda dapat memilih Sumber data secara manual di bawah Properti dan menyediakan parameter yang diperlukan untuk mengakses data.
Sumber data online yang didukung di-item dalam tabel di bawah ini. Tabel ini juga meringkas format file yang didukung dan parameter yang digunakan untuk mengakses data.
Penting
Saat ini, modul Impor Data dan Ekspor Data hanya dapat membaca dan menulis data dari penyimpanan Azure yang dibuat menggunakan model penyebaran Klasik. Dengan kata lain, jenis akun Azure Blob Storage baru yang menawarkan tingkat akses penyimpanan panas atau tingkat akses penyimpanan dingin belum didukung.
Umumnya, setiap akun penyimpanan Azure yang mungkin telah Anda buat sebelum opsi layanan ini tersedia tidak boleh terpengaruh. Jika Anda perlu membuat akun baru, pilih Klasik untuk model Penyebaran, atau gunakan Manajer sumber daya dan pilih Tujuan umum daripada penyimpanan Blob untuk Jenis akun.
Untuk informasi selengkapnya, lihat Azure Blob Storage: Tingkat Penyimpanan Panas dan Dingin.
Sumber data online yang didukung
Modul Impor Data Machine Learning Studio (klasik) mendukung sumber data berikut:
| Sumber data | Deskripsi | Parameter |
|---|---|---|
| URL Situs Web melalui HTTP | Membaca data dalam format nilai yang dipisahkan koma (CSV), nilai yang dipisahkan tab (TSV), format file relasi atribut (ARFF), dan Support Vector Machines (SVM-light), dari URL web mana saja yang menggunakan HTTP. |
URL: Menentukan nama lengkap file, termasuk URL situs dan nama file, dengan ekstensi apa pun. Format data: Menentukan salah satu format data yang didukung: CSV, TSV, ARFF, atau SVM-light. Jika data memiliki baris header, data tersebut digunakan untuk menetapkan nama kolom. |
| Hadoop/HDFS | Membaca data dari penyimpanan terdistribusi di Hadoop. Anda menentukan data yang diinginkan dengan menggunakan HiveQL, bahasa kueri seperti SQL. HiveQL juga dapat digunakan untuk mengagregasi data dan melakukan pemfilteran data sebelum Anda menambahkan data ke Studio (klasik). |
Kueri database Hive: Menentukan kueri Hive yang digunakan untuk menghasilkan data. URI server HCatalog : Menentukan nama kluster Anda menggunakan format <nama kluster Anda>.azurehdinsight.net. Nama akun pengguna Hadoop: Menentukan nama akun pengguna Hadoop yang digunakan untuk menyediakan kluster. Kata sandi akun pengguna Hadoop : Menentukan kredensial yang digunakan saat menyediakan kluster. Untuk informasi selengkapnya, lihat Membuat kluster Hadoop di HDInsight. Lokasi data output: Menentukan apakah data disimpan dalam sistem file terdistribusi Hadoop (HDFS) atau di Azure.
Jika menyimpan data output di Azure, Anda harus menentukan nama akun penyimpanan Azure, kunci akses Storage, dan nama kontainer Storage. |
| SQL Database | Membaca data yang disimpan di Azure SQL Database, Instans Terkelola SQL, atau dalam database SQL Server yang berjalan pada komputer virtual Azure. |
Nama server database: Menentukan nama server tempat database dijalankan.
Dalam kasus server SQL yang dihosting di komputer Azure Virtual, masukkan tcp:<Nama DNS Mesin Virtual>, 1433 Nama database : Menentukan nama database di server. Nama akun pengguna server: Menentukan nama pengguna untuk akun yang memiliki izin akses untuk database. Kata sandi akun pengguna server: Menentukan kata sandi untuk akun pengguna. Kueri database: Masukkan pernyataan SQL yang menjelaskan data yang ingin Anda baca. |
| Database SQL di tempat | Membaca data yang disimpan dalam database SQL. |
Gateway data: Menentukan nama Gateway Manajemen Data yang terpasang di komputer tempat gateway dapat mengakses database SQL Server Anda. Untuk informasi tentang menyiapkan gateway, lihat Melakukan analitik tingkat lanjut dengan Machine Learning Studio (klasik) menggunakan data dari server SQL. Nama server database: Menentukan nama server tempat database dijalankan. Nama database : Menentukan nama database di server. Nama akun pengguna server: Menentukan nama pengguna untuk akun yang memiliki izin akses untuk database. Nama pengguna dan kata sandi: Klik Masukkan nilai untuk memasukkan info masuk database Anda. Anda dapat menggunakan Windows Integrated Authentication atau SQL Server Authentication tergantung bagaimana SQL Server Anda dikonfigurasi. Kueri database: Masukkan pernyataan SQL yang menjelaskan data yang ingin Anda baca. |
| Tabel Azure | Membaca data dari layanan Tabel di Azure Storage. Jika Anda jarang membaca data dalam jumlah besar, gunakan Azure Table Service. Ini menyediakan solusi penyimpanan yang fleksibel, non-relasional (NoSQL), dapat diskalakan secara besar-besaran, murah, dan sangat tersedia. |
Opsi dalam Data Impor berubah tergantung pada apakah Anda mengakses informasi publik atau akun penyimpanan privat yang memerlukan kredensial masuk. Ini ditentukan oleh Jenis Otentikasi yang dapat memiliki nilai "PublicOrSAS" atau "Akun", yang masing-masing memiliki sekumpulan parameter sendiri. URI Tanda Tangan Akses Publik atau Bersama (SAS): Parameternya adalah:
Menentukan baris yang akan dipindai untuk nama properti: Nilainya adalah TopN untuk memindai jumlah baris yang ditentukan, atau ScanAll untuk mendapatkan semua baris dalam tabel. Jika data homogen dan dapat diprediksi, disarankan agar Anda memilih TopN dan memasukkan angka untuk N. Untuk tabel besar, ini dapat menghasilkan waktu membaca yang lebih cepat. Jika data disusun dengan kumpulan properti yang bervariasi berdasarkan kedalaman dan posisi tabel, pilih opsi ScanAll untuk memindai semua baris. Ini memastikan integritas hasil properti dan konversi metadata Anda.
Kunci akun: Menentukan kunci penyimpanan yang terkait dengan akun. Nama tabel : Menentukan nama tabel yang berisi data yang akan dibaca. Menentukan baris yang akan dipindai untuk nama properti: Nilainya adalah TopN untuk memindai jumlah baris yang ditentukan, atau ScanAll untuk mendapatkan semua baris dalam tabel. Jika data homogen dan dapat diprediksi, disarankan agar Anda memilih TopN dan memasukkan angka untuk N. Untuk tabel besar, ini dapat menghasilkan waktu membaca yang lebih cepat. Jika data disusun dengan kumpulan properti yang bervariasi berdasarkan kedalaman dan posisi tabel, pilih opsi ScanAll untuk memindai semua baris. Ini memastikan integritas hasil properti dan konversi metadata Anda. |
| Azure Blob Storage (Penyimpanan Blok Azure) | Membaca data yang disimpan dalam layanan Blob di Azure Storage, termasuk gambar, teks yang tidak terstruktur, atau data biner. Anda dapat menggunakan layanan Blob untuk mengekspos data secara publik, atau menyimpan data aplikasi secara pribadi. Anda dapat mengakses data dari mana saja dengan menggunakan koneksi HTTP atau HTTPS. |
Opsi dalam modul Impor Data berubah tergantung pada apakah Anda mengakses informasi publik atau akun penyimpanan privat yang memerlukan kredensial masuk. Ini ditentukan oleh Jenis Autentikasi yang dapat memiliki nilai baik dari "PublicOrSAS" atau "Akun". URI Tanda Tangan Akses Publik atau Bersama (SAS): Parameternya adalah:
Format File: Menentukan format data dalam layanan Blob. Format yang didukung adalah CSV, TSV, dan ARFF.
Kunci akun: Menentukan kunci penyimpanan yang terkait dengan akun. Jalur ke kontainer, direktori, atau blob : Menentukan nama blob yang berisi data yang akan dibaca. Format File blob: Menentukan format data dalam layanan blob. Format data yang didukung adalah CSV, TSV, ARFF, CSV dengan pengodean tertentu, dan Excel.
Anda bisa menggunakan opsi Excel untuk membaca data dari buku kerja Excel. Dalam opsi format data Excel, tunjukkan apakah data berada dalam rentang lembar kerja Excel, atau dalam tabel Excel. Dalam opsi lembar Excel atau tabel yang disematkan, tentukan nama lembar atau tabel yang ingin Anda baca. |
| Penyedia Umpan Data | Membaca data dari penyedia umpan yang didukung. Saat ini hanya format Open Data Protocol (OData) yang didukung. |
Jenis konten data: Menentukan format OData. URL Sumber: Menentukan URL lengkap untuk umpan data. Misalnya, URL berikut ini membaca dari database sampel Northwind: https://services.odata.org/northwind/northwind.svc/ |
Mengimpor data dari eksperimen lain
Akan ada saatnya Anda ingin mengambil hasil dari satu eksperimen dan menggunakannya sebagai bagian dari eksperimen lain. Untuk melakukan ini, Anda menyimpan modul sebagai himpunan data:
- Klik output modul yang ingin Anda simpan sebagai himpunan data.
- Klik Simpan sebagai Himpunan Data.
- Saat diminta, masukkan nama dan deskripsi yang akan memungkinkan Anda mengidentifikasi himpunan data dengan mudah.
- Klik tanda centang OK.
Setelah penyimpanan selesai, himpunan data akan tersedia untuk digunakan dalam eksperimen apa pun di ruang kerja Anda. Anda dapat menemukannya di daftar Himpunan Data Tersimpan di palet modul.