Pembelajaran mesin otomatis (AutoML)?
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Pembelajaran mesin otomatis, juga disebut sebagai ML atau AutoML otomatis, adalah proses mengotomatiskan tugas pengembangan model pembelajaran mesin yang memakan waktu dan berulang. Ini memungkinkan ilmuwan data, analis, dan pengembang untuk membangun model ML dengan skala tinggi, efisiensi, dan produktivitas sambil mempertahankan kualitas model. ML otomatis di Azure Machine Learning didasarkan pada terobosan dari divisi Microsoft Research kami.
Pengembangan model pembelajaran mesin tradisional membutuhkan banyak sumber daya, membutuhkan pengetahuan domain yang signifikan dan waktu untuk memproduksi dan membandingkan puluhan model. Dengan pembelajaran mesin otomatis, Anda akan mempercepat waktu yang diperlukan untuk mendapatkan model ML siap produksi dengan sangat mudah dan efisien.
Cara menggunakan AutoML di Azure Machine Learning
Azure Machine Learning menawarkan dua pengalaman untuk bekerja dengan ML otomatis. Lihat bagian berikut untuk memahami ketersediaan fitur di setiap pengalaman (v1).
Untuk pelanggan yang telah berpengalaman dengan kode, Azure Machine Learning Python SDK. Memulai dengan Tutorial: Menggunakan pembelajaran mesin otomatis untuk memprediksi tarif taksi (v1).
Untuk pelanggan tanpa pengalaman/ dengan pengalaman kode yang terbatas, studio Azure Machine Learning di https://ml.azure.com. Mulai dengan tutorial ini:
Pengaturan eksperimen
Pengaturan berikut memungkinkan Anda mengonfigurasi eksperimen ML otomatis.
| SDK Python | Pengalaman web studio | |
|---|---|---|
| Memisahkan data menjadi set rangkaian/validasi | ✓ | ✓ |
| Mendukung tugas AML: klasifikasi, regresi, dan prakiraan | ✓ | ✓ |
| Mendukung tugas visi komputer: klasifikasi gambar, deteksi objek & segmentasi instans | ✓ | |
| Mengoptimalkan berdasarkan metrik utama | ✓ | ✓ |
| Mendukung komputasi Azure Pembelajaran Mesin sebagai target komputasi | ✓ | ✓ |
| Mengonfigurasi cakrawala prakiraan, target & jendela gulir | ✓ | ✓ |
| Mengatur kriteria keluar | ✓ | ✓ |
| Mengatur iterasi bersamaan | ✓ | ✓ |
| Membuat kolom | ✓ | ✓ |
| Memblokir algoritma | ✓ | ✓ |
| Validasi silang | ✓ | ✓ |
| Mendukung pelatihan pada kluster Azure Databricks | ✓ | |
| Menampilkan nama fitur yang direkayasa | ✓ | |
| Ringkasan fiturisasi | ✓ | |
| Fiturisasi untuk liburan | ✓ | |
| Tingkat verbositas file log | ✓ |
Pengaturan model
Pengaturan ini dapat diterapkan ke model terbaik sebagai hasil dari eksperimen ML otomatis Anda.
| SDK Python | Pengalaman web studio | |
|---|---|---|
| Registrasi, penyebaran, penjelasan model terbaik | ✓ | ✓ |
| Mengaktifkan ansambel model pemungutan suara & susunan | ✓ | ✓ |
| Menampilkan model terbaik berdasarkan metrik non-primer | ✓ | |
| Mengaktifkan/menonaktifkan kompatibilitas model ONNX | ✓ | |
| Menguji model | ✓ | ✓ (pratinjau) |
Pengaturan kontrol pekerjaan
Pengaturan ini memungkinkan Anda meninjau dan mengontrol pekerjaan eksperimen serta turunannya.
| SDK Python | Pengalaman web studio | |
|---|---|---|
| Tabel ringkasan pekerjaan | ✓ | ✓ |
| Membatalkan pekerjaan & pekerjaan anak | ✓ | ✓ |
| Mendapatkan pagar pembatas | ✓ | ✓ |
| Jeda & lanjutkan pekerjaan | ✓ |
Kapan menggunakan AutoML: klasifikasi, regresi, prakiraan, visi komputer & NLP
Terapkan ML otomatis saat Anda ingin Azure Machine Learning melatih dan menyetel model untuk menggunakan metrik target yang Anda tentukan. ML otomatis mendemokratisasi proses pengembangan model pembelajaran mesin dan memberdayakan penggunanya tanpa mempertimbangkan keahlian ilmu data mereka untuk mengidentifikasi alur pembelajaran mesin end-to-end untuk masalah apa pun.
Profesional dan pengembang ML di seluruh industri dapat menggunakan ML otomatis untuk:
- Terapkan solusi ML tanpa pengetahuan pemrograman yang luas
- Menghemat waktu dan sumber daya
- Manfaatkan praktik terbaik ilmu data
- Sediakan pemecahan masalah yang lincah
Klasifikasi
Klasifikasi adalah tugas pembelajaran mesin yang umum. Klasifikasi adalah jenis pembelajaran yang diawasi saat model belajar menggunakan data pelatihan dan menerapkan pembelajaran tersebut ke data baru. Azure Machine Learning menawarkan fiturisasi khusus untuk tugas-tugas ini, seperti fitur teks jaringan saraf dalam untuk klasifikasi. Pelajari selengkapnya tentang opsi fiturisasi (v1).
Tujuan utama dari model klasifikasi adalah untuk memprediksi kategori data baru mana yang akan jatuh berdasarkan pembelajaran dari data pelatihannya. Contoh klasifikasi umum termasuk deteksi penipuan, pengenalan tulisan tangan, dan deteksi objek. Pelajari selengkapnya dan lihat contoh di Membuat model klasifikasi dengan ML otomatis (v1).
Lihat contoh klasifikasi dan pembelajaran mesin otomatis dalam notebook Python ini: Deteksi Penipuan, Prediksi Pemasaran, dan Klasifikasi Data Grup Berita
Regresi
Mirip dengan klasifikasi, tugas regresi juga merupakan tugas pembelajaran yang diawasi bersama.
Berbeda dari klasifikasi saat nilai output yang diprediksi memiliki kategori, model regresi memprediksi nilai output numerik berdasarkan prediktor independen. Dalam regresi, tujuannya adalah untuk membantu membangun hubungan di antara variabel prediktor independen dengan memperkirakan bagaimana satu variabel berdampak pada yang lain. Misalnya, harga mobil berdasarkan fitur seperti jarak tempuh gas, peringkat keselamatan, dll. Pelajari selengkapnya dan lihat contoh regresi dengan pembelajaran mesin otomatis (v1).
Lihat contoh regresi dan pembelajaran mesin otomatis untuk prediksi di notebook Python ini: Prediksi Kinerja CPU,
Prakiraan rangkaian waktu
Prakiraan bangunan adalah bagian integral dari bisnis apa pun, baik itu pendapatan, inventaris, penjualan, atau permintaan pelanggan. Anda dapat menggunakan ML otomatis untuk menggabungkan teknik dan pendekatan dan mendapatkan perkiraan rangkaian waktu berkualitas tinggi yang direkomendasikan. Pelajari selengkapnya cara ini: pembelajaran mesin otomatis untuk prakiraan rangkaian waktu (v1).
Eksperimen seri waktu otomatis diperlakukan sebagai masalah regresi multivariat. Nilai seri waktu sebelumnya "dipivot" untuk menjadi dimensi tambahan bagi regresor bersama dengan prediktor lain. Pendekatan ini, tidak seperti metode seri waktu klasik, memiliki keuntungan secara alami menggabungkan beberapa variabel kontekstual dan hubungan mereka satu sama lain selama pelatihan. ML otomatis mempelajari model tunggal, tetapi sering bercabang secara internal untuk semua item di himpunan data dan cakrawala prediksi. Dengan demikian, tersedia lebih banyak data untuk memperkirakan parameter model dan generalisasi ke seri yang tidak terlihat menjadi mungkin.
Konfigurasi prakiraan tingkat lanjut meliputi:
- deteksi dan keistimewaan liburan
- time-series dan pelajar DNN (Auto-ARIMA, Prophet, ForecastTCN)
- banyak model mendukung melalui pengelompokan
- validasi lintas rolling-origin
- Dapat dikonfigurasi
- fitur agregat jendela bergulir
Lihat contoh regresi dan pembelajaran mesin otomatis untuk prediksi di notebook Python ini: Prakiraan Penjualan, Prakiraan Permintaan, dan Prakiraan Pengguna Aktif Harian GitHub.
Computer Vision
Dukungan untuk tugas visi komputer memungkinkan Anda dengan mudah menghasilkan model yang dilatih pada data citra untuk skenario seperti klasifikasi citra dan deteksi objek.
Dengan kemampuan ini, Anda dapat:
- Terintegrasi dengan mulus dengan kemampuan pelabelan data Azure Machine Learning
- Menggunakan data berlabel untuk menghasilkan model gambar
- Optimalkan performa model dengan menentukan algoritma model dan menyetel hiperparameter.
- Unduh atau sebarkan model yang dihasilkan sebagai layanan web di Azure Machine Learning.
- Mengoperasikan dalam skala, memanfaatkan kemampuan Azure Machine Learning MLOps dan ML Pipelines (v1).
Penulisan model AutoML untuk tugas visi didukung melalui Azure Pembelajaran Mesin Python SDK. Pekerjaan eksperimen yang dihasilkan, model, dan output dapat diakses dari UI studio Azure Machine Learning.
Pelajari cara menyiapkan pelatihan AutoML untuk model penglihatan komputer.

AML otomatis untuk gambar mendukung tugas penglihatan komputer berikut:
| Tugas | Deskripsi |
|---|---|
| Klasifikasi gambar multi-kelas | Tugas di mana gambar diklasifikasikan hanya dengan satu label dari satu set kelas - misalnya setiap gambar diklasifikasikan sebagai gambar 'kucing' atau 'anjing' atau 'bebek' |
| Klasifikasi gambar multi-label | Tugas di mana gambar bisa memiliki satu atau lebih label dari satu set label - misalnya gambar dapat diberi label dengan 'kucing' dan 'anjing' |
| Deteksi objek | Tugas untuk mengidentifikasi objek dalam gambar dan menemukan setiap objek dengan kotak pembatas misalnya menemukan semua anjing dan kucing dalam gambar dan menggambar kotak pembatas di sekitar masing-masing gambar. |
| Segmentasi instans | Tugas untuk mengidentifikasi objek dalam gambar pada tingkat piksel, menggambar poligon di sekitar setiap objek dalam gambar. |
Pemrosesan bahasa alami: NLP
Dukungan untuk tugas pemrosesan bahasa alami (NLP) dalam ML otomatis memungkinkan Anda dengan mudah menghasilkan model terlatih pada data teks untuk klasifikasi teks dan skenario pengenalan entitas karakter. Penulisan model NLP terlatih ML otomatis didukung melalui SDK Python Azure Machine Learning. Pekerjaan eksperimen yang dihasilkan, model, dan output dapat diakses dari UI studio Azure Machine Learning.
Kemampuan NLP mendukung:
- Pelatihan NLP jaringan neural dalam ujung ke ujung dengan model BERT pra-pelatihan terbaru
- Integrasi yang mulus dengan pelabelan data Azure Machine Learning
- Menggunakan data berlabel untuk menghasilkan model NLP
- Dukungan multibahasa dengan 104 bahasa
- Pelatihan terdistribusi dengan Horovod
Pelajari cara menyiapkan pelatihan AutoML untuk model NLP (v1).
Cara kerja ML otomatis
Selama pelatihan, Azure Machine Learning membuat sejumlah alur secara paralel yang mencoba algoritma dan parameter yang berbeda untuk Anda. Layanan berulang melalui algoritme ML yang dipasangkan dengan pilihan fitur, di mana setiap perulangan menghasilkan model dengan skor pelatihan. Semakin tinggi skor, semakin baik model dianggap "sesuai" dengan data Anda. Ini akan berhenti setelah mencapai kriteria keluar yang ditentukan dalam percobaan.
Menggunakan Azure Machine Learning, Anda dapat mendesain dan menjalankan eksperimen pelatihan ML otomatis dengan langkah-langkah berikut:
Identifikasi masalah ML yang akan diselesaikan: klasifikasi, prakiraan, regresi, atau visi komputer.
Pilih apakah Anda ingin menggunakan Python SDK atau pengalaman web studio: Pelajari keseimbangan antara Python SDK dan pengalaman web studio.
- Untuk pengalaman kode terbatas atau tanpa kode, cobalah pengalaman web studio Azure Machine Learning di https://ml.azure.com
- Untuk pengembang Python, periksa Azure Machine Learning Python SDK (v1)
Tentukan sumber dan format data pelatihan berlabel: Array numpy atau Pandas dataframe
Konfigurasikan target komputasi untuk pelatihan model, seperti komputer lokal, Komputasi Azure Machine Learning, VM jarak jauh, atau Azure Databricks dengan SDL v1.
Konfigurasikan parameter pembelajaran mesin otomatis yang menentukan berapa banyak perulangan atas model yang berbeda, pengaturan hyperparameter, prapemrosesan/fiturisasi lanjutan, dan metrik apa yang harus dilihat saat menentukan model terbaik.
Kirim pekerjaan pelatihan.
Tinjau hasilnya
Diagram berikut mengilustrasikan hubungan ini.
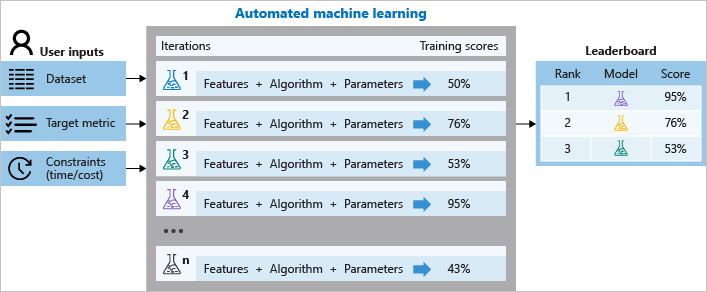
Anda juga dapat memeriksa informasi yang dijalankan dengan log, yang berisi metrik yang dikumpulkan selama pekerjaan berlangsung. Pekerjaan pelatihan ini menghasilkan objek serial Python (file .pkl) yang berisi model dan prapemrosesan data.
Saat pembangunan model dilakukan secara otomatis, Anda juga dapat mempelajari seberapa penting atau relevan fitur untuk model yang dihasilkan.
Panduan tentang target komputasi ML terkelola lokal vs. jarak jauh
Antarmuka web untuk ML otomatis selalu menggunakan target komputasi jarak jauh. Namun, saat Anda menggunakan Python SDK, Anda akan memilih komputasi lokal atau target komputasi jarak jauh untuk pelatihan ML otomatis.
- Komputasi lokal: Pelatihan terjadi di laptop lokal atau komputasi VM Anda.
- Komputasi jarak jauh: Pelatihan terjadi pada klaster komputasi Azure Machine Learning.
Memilih target komputasi
Pertimbangkan faktor-faktor ini saat memilih target komputasi:
- Pilih komputasi lokal: Jika rencana Anda adalah melakukan eksplorasi awal atau demo menggunakan data kecil dan rangkaian pendek (yaitu, beberapa detik atau menit per pekerjaan turunan), pelatihan di komputer lokal Anda mungkin merupakan pilihan yang lebih baik. Tidak ada waktu pengaturan, sumber daya infrastruktur (PC atau VM Anda) tersedia secara langsung.
- Pilih kluster komputasi ML jarak jauh: Jika Anda berlatih dengan himpunan data yang lebih besar seperti dalam pelatihan produksi yang menciptakan model yang membutuhkan rangkaian yang lebih panjang, komputasi jarak jauh akan memberikan performa waktu end-to-end yang jauh lebih baik karena
AutoMLakan mejajarkan rangkaian di seluruh node kluster. Pada komputasi jarak jauh, waktu mulai untuk infrastruktur internal akan menambahkan sekitar 1,5 menit per pekerjaan turunan serta beberapa menit tambahan untuk infrastruktur kluster jika VM belum berjalan.
Pro dan kontra
Pertimbangkan pro dan kontra ini saat memilih untuk menggunakan lokal vs. jarak jauh.
| Kelebihan (Keuntungan) | Kontra (Kekurangan) | |
|---|---|---|
| Target komputasi lokal | ||
| Kluster komputasi ML jarak jauh |
Ketersediaan fitur
Fitur lainnya tersedia saat Anda menggunakan komputasi jarak jauh, seperti yang ditunjukkan pada tabel di bawah ini.
| Fitur | Jarak Jauh | Lokal |
|---|---|---|
| Streaming data (Dukungan data besar, hingga 100 GB) | ✓ | |
| Fiturisasi teks dan pelatihan berbasis DNN-BERT | ✓ | |
| Dukungan GPU out-of-the-box (pelatihan dan inferensi) | ✓ | |
| Dukungan Klasifikasi dan Pelabelan Gambar | ✓ | |
| Model Auto-ARIMA, Prophet, dan ForecastTCN untuk prakiraan | ✓ | |
| Beberapa pekerjaan/perulangan secara paralel | ✓ | |
| Membuat model dengan kemampuan interpretasi di UI pengalaman web studio AutoML | ✓ | |
| Kustomisasi rekayasa fitur di UI pengalaman web studio | ✓ | |
| Penyetelan hyperparameter Azure Pembelajaran Mesin | ✓ | |
| Dukungan alur kerja Azure Pembelajaran Mesin Pipeline | ✓ | |
| Melanjutkan pekerjaan | ✓ | |
| Prakiraan | ✓ | ✓ |
| Membuat dan menjalankan eksperimen di buku catatan | ✓ | ✓ |
| Mendaftarkan dan memvisualisasikan info dan metrik eksperimen di UI | ✓ | ✓ |
| Pagar pembatas data | ✓ | ✓ |
Pelatihan, validasi, dan data pengujian
Dengan ML otomatis, Anda memberikan data pelatihan untuk melatih model ML, dan Anda dapat menentukan jenis validasi model apa yang harus dilakukan. ML otomatis melakukan validasi model sebagai bagian dari pelatihan. Artinya, ML otomatis menggunakan data validasi untuk menyetel hiperparameter model berdasarkan algoritma yang diterapkan untuk menemukan kombinasi terbaik yang paling sesuai dengan data pelatihan. Namun, data validasi yang sama digunakan untuk setiap iterasi penyetelan, yang memperkenalkan bias evaluasi model karena model terus meningkat dan sesuai dengan data validasi.
Untuk membantu mengonfirmasi bahwa bias tersebut tidak diterapkan pada model akhir yang direkomendasikan, ML otomatis mendukung penggunaan data uji untuk mengevaluasi model akhir yang direkomendasikan ML otomatis pada akhir percobaan Anda. Saat Anda memberikan data uji sebagai bagian dari konfigurasi eksperimen AutoML, model yang direkomendasikan ini diuji secara default di akhir eksperimen Anda (pratinjau).
Penting
Menguji model Anda dengan himpunan data uji untuk mengevaluasi model yang dihasilkan adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
Pelajari cara mengonfigurasi eksperimen AutoML untuk menggunakan data uji (pratinjau) dengan SDK (v1) atau dengan studio Azure Machine Learning.
Anda juga dapat menguji model ML otomatis yang ada (pratinjau) (v1)), termasuk model dari pekerjaan turunan, dengan menyediakan data pengujian atau dengan menyisihkan sebagian dari data pelatihan Anda.
Rekayasa fitur
Rekayasa fitur adalah proses penggunaan pengetahuan domain tentang data untuk membuat fitur yang membantu algoritma ML belajar lebih baik. Di Azure Machine Learning, teknik penskalaan dan normalisasi diterapkan untuk memfasilitasi rekayasa fitur. Secara kolektif, teknik dan rekayasa fitur ini disebut sebagai fiturisasi.
Untuk eksperimen pembelajaran mesin otomatis, fiturisasi diterapkan secara otomatis tetapi juga dapat disesuaikan berdasarkan data Anda. Pelajari lebih lanjut fiturisasi apa saja yang disertakan (v1) dan cara AutoML membantu mencegah data yang terlalu pas dan tidak seimbang dalam model Anda.
Catatan
Langkah-langkah fiturisasi pembelajaran mesin otomatis (normalisasi fitur, penanganan data yang hilang, mengonversi teks menjadi numerik, dll.) menjadi bagian dari model yang mendasari. Saat menggunakan model untuk prediksi, langkah-langkah fiturisasi yang sama dan diterapkan selama pelatihan akan diterapkan ke data input Anda secara otomatis.
Menyesuaikan fiturisasi
Teknik fitur tambahan seperti pengkodean dan transformasi juga tersedia.
Aktifkan pengaturan ini dengan:
Studio Azure Machine Learning: Aktifkan Fiturisasi otomatis di bagian Tampilkan konfigurasi tambahan dengan langkah-langkah ini (v1).
Python SDK: Tentukan
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'di objek AutoMLConfig Anda. Pelajari selengkapnya tentang mengaktifkan fiturisasi (v1).
Model ansambel
Pembelajaran mesin otomatis mendukung model ansambel, yang diaktifkan secara default. Pembelajaran ansambel meningkatkan hasil pembelajaran mesin dan performa prediktif dengan menggabungkan beberapa model dan bukan dengan menggunakan model tunggal. Iterasi ansambel muncul sebagai perulangan akhir dari pekerjaan Anda. Pembelajaran mesin otomatis menggunakan metode ansambel pemungutan suara dan susun untuk menggabungkan model:
- Pemungutan suara: memprediksi berdasarkan rata-rata tertimbang probabilitas kelas yang diprediksi (untuk tugas klasifikasi) atau target regresi yang diprediksi (untuk tugas regresi).
- Susun: menggabungkan model heterogen dan melatih meta-model berdasarkan output dari model individu. Meta-model default saat ini adalah LogisticRegression untuk tugas klasifikasi dan ElasticNet untuk tugas regresi/prakiraan.
Algoritma pemilihan ansambel Caruana dengan inisialisasi ansambel yang diurutkan digunakan untuk memutuskan model mana yang akan digunakan dalam ansambel. Pada tingkat tinggi, algoritma ini menginisialisasi ansambel dengan hingga lima model dengan skor individu terbaik dan memverifikasi bahwa model-model ini berada dalam ambang batas 5% dari skor terbaik untuk menghindari ansambel awal yang buruk. Kemudian untuk setiap perulangan ansambel, model baru ditambahkan ke ansambel yang ada dan skor yang dihasilkan dihitung. Jika model baru meningkatkan skor ansambel yang ada, ansambel diperbarui untuk menyertakan model baru.
Lihat cara (v1) untuk mengubah pengaturan ansambel default dalam pembelajaran mesin otomatis.
AutoML & ONNX
Dengan Azure Machine Learning, Anda dapat menggunakan ML otomatis untuk membuat model Python dan mengonversinya ke format ONNX. Setelah model dalam format ONNX, model dapat dijalankan pada berbagai platform dan perangkat. Pelajari selengkapnya cara mempercepat model ML dengan ONNX.
Lihat cara mengonversi ke format ONNX dalam contoh buku catatan Jupyter ini. Pelajari algoritma mana yang didukung di ONNX (v1).
Runtime ONNX juga mendukung C#, sehingga Anda dapat menggunakan model yang dibuat secara otomatis di aplikasi C# Anda tanpa perlu melakukan pengkodean ulang atau latensi jaringan apa pun yang diperkenalkan oleh titik akhir REST. Pelajari selengkapnya tentang menggunakan model AutoML ONNX dalam aplikasi .NET dengan ML.NET dan inferensi model ONNX dengan runtime ONNX C# API.
Langkah berikutnya
Terdapat beberapa sumber daya untuk membantu Anda memulai dan menjalankan AutoML.
Tutorial/cara kerja
Tutorial adalah contoh pengantar end-to-end dari skenario AutoML.
Untuk pengalaman pertama dengan kode, ikuti Tutorial: Melatih model regresi dengan AutoML dan Python (v1).
Untuk pelanggan tanpa atau sedikit pengalaman , lihat Tutorial: Membuat model klasifikasi ML otomatis dengan studio Azure Machine Learning.
Untuk menggunakan AutoML untuk melatih model visi komputer, lihat Tutorial: Melatih model deteksi objek dengan AutoML dan Python (v1).
Artikel manual ini memberikan detail tambahan tentang fungsi yang ditawarkan AutoML. Contohnya,
Mengonfigurasi pengaturan untuk eksperimen pelatihan otomatis
Pelajari cara melatih model peramalan dengan data deret waktu (v1).
Pelajari cara melatih model penglihatan komputer dengan Python (v1).
Pelajari cara melihat kode yang dihasilkan dari model ML otomatis Anda.
Sampel notebook Jupyter
Tinjau contoh kode terperinci dan kasus penggunaan di repositori buku catatan GitHub untuk sampel pembelajaran mesin otomatis.
Referensi Python SDK
Perdalam keahlian Anda tentang pola desain SDK dan spesifikasi kelas dengan dokumentasi referensi kelas AutoML.
Catatan
Kemampuan pembelajaran mesin otomatis juga tersedia di solusi Microsoft lainnya seperti ML.NET, HDInsight, Power BI, dan SQL Server