Prakiraan dalam skala besar: banyak model dan pelatihan terdistribusi
Artikel ini berisi tentang model prakiraan pelatihan pada data historis dalam jumlah besar. Instruksi dan contoh untuk model prakiraan pelatihan di AutoML dapat ditemukan di artikel prakiraan AutoML untuk rangkaian waktu kami.
Data rangkaian waktu bisa besar karena jumlah rangkaian dalam data, jumlah pengamatan historis, atau keduanya. Banyak model dan rangkaian waktu hierarkis, atau HTS, adalah solusi penskalaan untuk skenario sebelumnya, di mana data terdiri dari sejumlah besar rangkaian waktu. Dalam kasus ini, dapat bermanfaat bagi akurasi model dan skalabilitas untuk mempartisi data ke dalam grup dan melatih sejumlah besar model independen secara paralel pada grup. Sebaliknya, ada skenario di mana satu atau sejumlah kecil model kapasitas tinggi lebih baik. Pelatihan DNN terdistribusi menargetkan kasus ini. Kami meninjau konsep sekeliling skenario ini di sisa artikel.
Banyak model
Banyaknya komponen model di AutoML memungkinkan Anda melatih dan mengelola jutaan model secara paralel. Misalnya, Anda memiliki data penjualan historis untuk sejumlah besar toko. Anda dapat menggunakan banyak model untuk meluncurkan pekerjaan pelatihan AutoML paralel untuk setiap toko, seperti dalam diagram berikut:

Banyak komponen pelatihan model menerapkan pembersihan dan pemilihan model AutoML secara independen ke setiap toko dalam contoh ini. Kemandirian model ini membantu skalabilitas dan dapat menguntungkan akurasi model terutama ketika toko memiliki dinamika penjualan yang berbeda. Namun, pendekatan model tunggal dapat menghasilkan perkiraan yang lebih akurat ketika ada dinamika penjualan umum. Lihat bagian pelatihan DNN terdistribusi untuk detail selengkapnya tentang kasus tersebut.
Anda dapat mengonfigurasi partisi data, pengaturan AutoML untuk model, dan tingkat paralelisme untuk banyak pekerjaan pelatihan model. Misalnya, lihat bagian panduan kami tentang banyak komponen model.
Prakiraan deret waktu hierarkis
Umum bagi rangkaian waktu dalam aplikasi bisnis untuk memiliki atribut berlapis yang membentuk hierarki. Atribut geografi dan katalog produk sering disarangkan, misalnya. Pertimbangkan contoh di mana hierarki memiliki dua atribut geografis, ID status dan penyimpanan, dan dua atribut produk, kategori dan SKU:

Hierarki ini diilustrasikan dalam diagram berikut:

Yang penting, jumlah penjualan di tingkat daun (SKU) menambah jumlah penjualan agregat di tingkat status dan total penjualan. Metode prakiraan hierarkis mempertahankan properti agregasi ini saat memperkirakan kuantitas yang dijual pada tingkat hierarki apa pun. Prakiraan dengan properti ini koheren sehubungan dengan hierarki.
AutoML mendukung fitur berikut untuk seri waktu hierarkis (HTS):
- Pelatihan di tingkat hierarki apa pun. Dalam beberapa kasus, data tingkat daun mungkin berisik, tetapi agregat mungkin lebih mudah diprakirakan.
- Mengambil prakiraan titik pada tingkat hierarki apa pun. Jika tingkat prakiraan "di bawah" tingkat pelatihan, maka prakiraan dari tingkat pelatihan disagregasi melalui proporsi historis rata-rata atau proporsi rata-rata historis. Prakiraan tingkat pelatihan dijumlahkan sesuai dengan struktur agregasi ketika tingkat prakiraan "di atas" tingkat pelatihan.
- Mengambil prakiraan kuantil/probabilistik untuk tingkat pada atau "di bawah" tingkat pelatihan. Kemampuan pemodelan saat ini mendukung disagregasi prakiraan probabilistik.
Komponen HTS di AutoML dibangun di atas banyak model, sehingga HTS berbagi properti yang dapat diskalakan dari banyak model. Misalnya, lihat bagian panduan kami tentang komponen HTS.
Pelatihan DNN terdistribusi (pratinjau)
Penting
Fitur ini masih dalam pratinjau umum. Versi pratinjau ini disediakan tanpa perjanjian tingkat layanan, dan tidak disarankan untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas.
Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Skenario data yang menampilkan sejumlah besar pengamatan historis dan/atau sejumlah besar rangkaian waktu terkait dapat memperoleh manfaat dari pendekatan model tunggal yang dapat diskalakan. Oleh karena itu, AutoML mendukung pelatihan terdistribusi dan pencarian model pada model jaringan konvolusional temporal (TCN), yang merupakan jenis jaringan neural dalam (DNN) untuk data rangkaian waktu. Untuk informasi selengkapnya tentang kelas model TCN AutoML, lihat artikel DNN kami.
Pelatihan DNN terdistribusi mencapai skalabilitas menggunakan algoritma pemartisian data yang menghormati batas rangkaian waktu. Diagram berikut mengilustrasikan contoh sederhana dengan dua partisi:
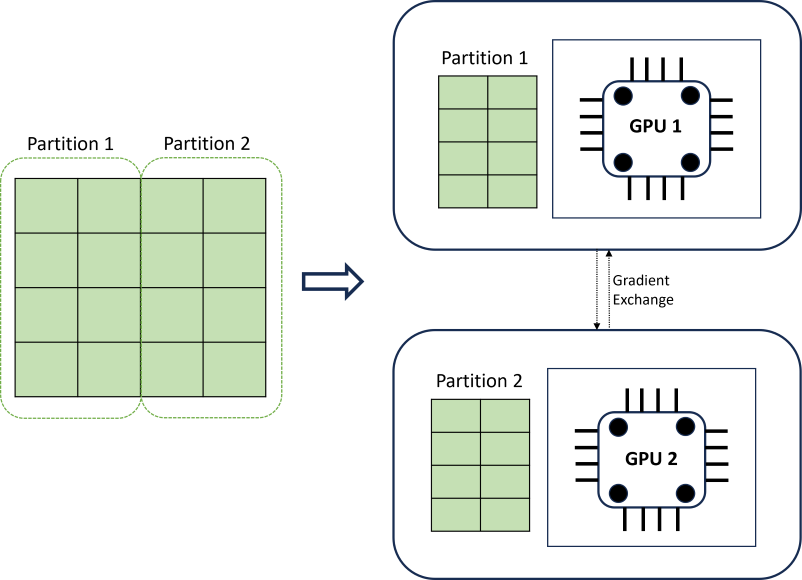
Selama pelatihan, pemuat data DNN pada setiap beban komputasi hanya apa yang mereka butuhkan untuk menyelesaikan iterasi penyebaran kembali; seluruh himpunan data tidak pernah dibaca ke dalam memori. Partisi didistribusikan lebih lanjut di beberapa inti komputasi (biasanya GPU) pada kemungkinan beberapa simpul untuk mempercepat pelatihan. Koordinasi di seluruh komputasi disediakan oleh kerangka kerja Horovod .
Langkah berikutnya
- Pelajari selengkapnya tentang cara menyiapkan AutoML untuk melatih model prakiraan rangkaian waktu.
- Pelajari tentang cara AutoML menggunakan pembelajaran mesin untuk membangun model prakiraan.
- Pelajari tentang model pembelajaran mendalam untuk prakiraan di AutoML
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk