Membuat pekerjaan dan memasukkan data untuk titik akhir batch
Titik akhir batch dapat digunakan untuk melakukan operasi batch panjang atas data dalam jumlah besar. Data tersebut dapat ditempatkan di tempat yang berbeda. Beberapa jenis titik akhir batch juga dapat menerima parameter harfiah sebagai input. Dalam tutorial ini kita akan membahas bagaimana Anda dapat menentukan input tersebut, dan berbagai jenis atau lokasi yang didukung.
Sebelum memanggil titik akhir
Agar berhasil memanggil titik akhir batch dan membuat pekerjaan, pastikan Anda memiliki hal berikut:
Anda memiliki izin untuk menjalankan penyebaran titik akhir batch. Peran Ilmuwan, Kontributor, dan Pemilik Data AzureML dapat digunakan untuk menjalankan penyebaran. Untuk definisi peran kustom, baca Otorisasi pada titik akhir batch untuk mengetahui izin tertentu yang diperlukan.
Anda memiliki token ID Microsoft Entra yang valid yang mewakili perwakilan keamanan untuk memanggil titik akhir. Perwakilan ini dapat menjadi prinsipal pengguna atau perwakilan layanan. Bagaimanapun, setelah titik akhir dipanggil, pekerjaan penyebaran batch dibuat di bawah identitas yang terkait dengan token. Untuk tujuan pengujian, Anda dapat menggunakan kredensial Anda sendiri untuk pemanggilan seperti yang disebutkan di bawah ini.
Gunakan Azure CLI untuk masuk menggunakan autentikasi kode interaktif atau perangkat:
az loginUntuk mempelajari selengkapnya tentang cara mengautentikasi dengan beberapa jenis kredensial baca Otorisasi pada titik akhir batch.
Kluster komputasi tempat titik akhir disebarkan memiliki akses untuk membaca data input.
Tip
Jika Anda menggunakan penyimpanan data tanpa kredensial atau Akun Azure Storage eksternal sebagai input data, pastikan Anda mengonfigurasi kluster komputasi untuk akses data. Identitas terkelola kluster komputasi digunakan untuk memasang akun penyimpanan. Identitas pekerjaan (pemanggil) masih digunakan untuk membaca data yang mendasarinya yang memungkinkan Anda mencapai kontrol akses terperinci.
Membuat dasar-dasar pekerjaan
Untuk membuat pekerjaan dari titik akhir batch, Anda harus memanggilnya. Pemanggilan dapat dilakukan menggunakan Azure CLI, Azure Pembelajaran Mesin SDK untuk Python, atau panggilan REST API. Contoh berikut menunjukkan dasar-dasar pemanggilan untuk titik akhir batch yang menerima satu folder data input untuk diproses. Lihat Memahami input dan output untuk contoh dengan input dan output yang berbeda.
Gunakan operasi di invoke bawah titik akhir batch:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Memanggil penyebaran tertentu
Titik akhir batch dapat menghosting beberapa penyebaran di bawah titik akhir yang sama. Titik akhir default digunakan kecuali pengguna menentukan sebaliknya. Anda dapat mengubah penyebaran yang digunakan sebagai berikut:
Gunakan argumen --deployment-name atau -d untuk menentukan nama penyebaran:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Mengonfigurasi properti pekerjaan
Anda dapat mengonfigurasi beberapa properti dalam pekerjaan yang dibuat pada waktu pemanggilan.
Catatan
Mengonfigurasi properti pekerjaan hanya tersedia di titik akhir batch dengan penyebaran komponen Alur saat ini.
Mengonfigurasi nama eksperimen
Gunakan argumen --experiment-name untuk menentukan nama eksperimen:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Memahami input dan output
Titik akhir batch menyediakan API tahan lama yang dapat digunakan konsumen untuk membuat pekerjaan batch. Antarmuka yang sama dapat digunakan untuk menentukan input dan output yang diharapkan penyebaran Anda. Gunakan input untuk meneruskan informasi apa pun yang diperlukan titik akhir Anda untuk melakukan pekerjaan.
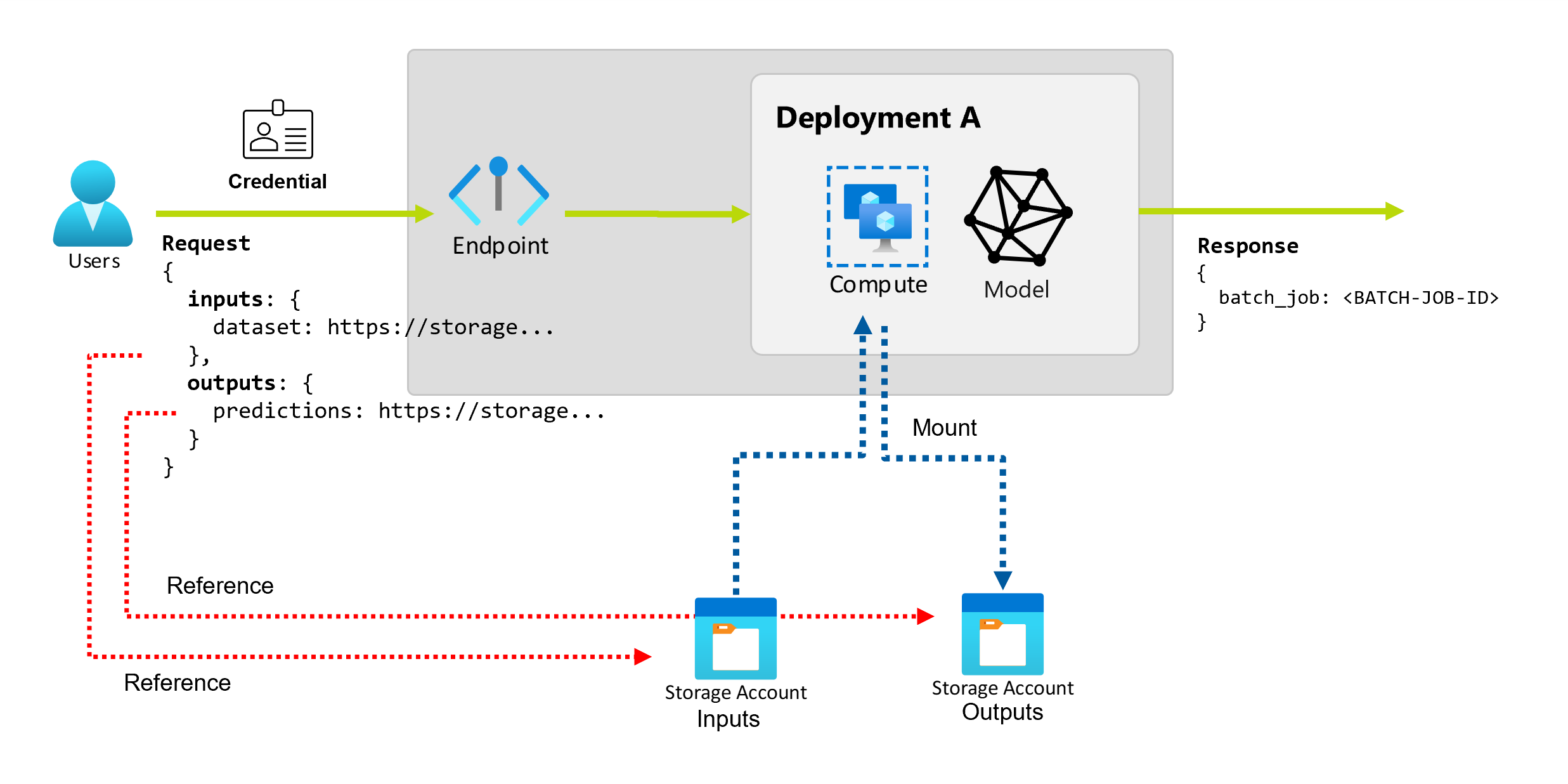
Titik akhir batch mendukung dua jenis input:
- Input data, yang merupakan penunjuk ke lokasi penyimpanan tertentu atau aset Azure Pembelajaran Mesin.
- Input harfiah, yang merupakan nilai harfiah (seperti angka atau string) yang ingin Anda teruskan ke pekerjaan.
Jumlah dan jenis input dan output bergantung pada jenis penyebaran batch. Penyebaran model selalu memerlukan satu input data dan menghasilkan satu output data. Input literal tidak didukung. Namun, penyebaran komponen alur menyediakan konstruksi yang lebih umum untuk membangun titik akhir dan memungkinkan Anda menentukan sejumlah input (data dan literal) dan output.
Tabel berikut ini meringkas input dan output untuk penyebaran batch:
| Jenis penyebaran | Nomor input | Jenis input yang didukung | Nomor output | Jenis output yang didukung |
|---|---|---|---|---|
| Penyebaran model | 1 | Input data | 1 | Output data |
| Penyebaran komponen alur | [0..N] | Input data dan input harfiah | [0..N] | Output data |
Tip
Input dan output selalu diberi nama. Nama-nama tersebut berfungsi sebagai kunci untuk mengidentifikasinya dan meneruskan nilai aktual selama pemanggilan. Untuk penyebaran model, karena selalu memerlukan satu input dan output, nama diabaikan selama pemanggilan. Anda dapat menetapkan nama yang paling tepat menggambarkan kasus penggunaan Anda, seperti "sales_estimation".
Input data
Input data mengacu pada input yang menunjuk ke lokasi tempat data ditempatkan. Karena titik akhir batch biasanya menggunakan data dalam jumlah besar, Anda tidak dapat meneruskan data input sebagai bagian dari permintaan pemanggilan. Sebagai gantinya, Anda menentukan lokasi tempat titik akhir batch harus pergi untuk mencari data. Data input dipasang dan dialirkan pada komputasi target untuk meningkatkan performa.
Titik akhir batch mendukung membaca file yang terletak di opsi penyimpanan berikut:
- Azure Pembelajaran Mesin Aset Data, termasuk Folder (
uri_folder) dan File (uri_file). - Azure Pembelajaran Mesin Data Stores, termasuk Azure Blob Storage, Azure Data Lake Storage Gen1, dan Azure Data Lake Storage Gen2.
- Akun Azure Storage, termasuk Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, dan Azure Blob Storage.
- Folder/file data lokal (Azure Pembelajaran Mesin CLI atau Azure Pembelajaran Mesin SDK untuk Python). Namun, operasi tersebut menghasilkan data lokal yang akan diunggah ke Azure Pembelajaran Mesin Data Store default dari ruang kerja yang sedang Anda kerjakan.
Penting
Pemberitahuan penghentian: Himpunan data jenis FileDataset (V1) tidak digunakan lagi dan akan dihentikan di masa mendatang. Titik akhir batch yang ada yang mengandalkan fungsionalitas ini akan terus berfungsi tetapi titik akhir batch yang dibuat dengan GA CLIv2 (2.4.0 dan yang lebih baru) atau GA REST API (2022-05-01 dan yang lebih baru) tidak akan mendukung himpunan data V1.
Input harfiah
Input literal mengacu pada input yang dapat diwakili dan diselesaikan pada waktu pemanggilan, seperti string, angka, dan nilai boolean. Anda biasanya menggunakan input harfiah untuk meneruskan parameter ke titik akhir Anda sebagai bagian dari penyebaran komponen alur. Titik akhir batch mendukung jenis harfiah berikut:
stringbooleanfloatinteger
Input literal hanya didukung dalam penyebaran komponen alur. Lihat Membuat pekerjaan dengan input harfiah untuk mempelajari cara menentukannya.
Output data
Output data merujuk ke lokasi tempat hasil pekerjaan batch harus ditempatkan. Output diidentifikasi berdasarkan nama, dan Azure Pembelajaran Mesin secara otomatis menetapkan jalur unik ke setiap output bernama. Namun, Anda dapat menentukan jalur lain jika diperlukan.
Penting
Titik akhir batch hanya mendukung penulisan output di penyimpanan data Azure Blob Storage. Jika Anda perlu menulis ke akun penyimpanan dengan namespace hierarki diaktifkan (juga dikenal sebagai Azure Datalake Gen2 atau ADLS Gen2), perhatikan bahwa layanan penyimpanan tersebut dapat didaftarkan sebagai datastore Azure Blob Storage karena layanan sepenuhnya kompatibel. Dengan cara ini, Anda dapat menulis output dari titik akhir batch ke ADLS Gen2.
Membuat pekerjaan dengan input data
Contoh berikut menunjukkan cara membuat pekerjaan, mengambil input data dari aset data, penyimpanan data, dan Akun Azure Storage.
Input data dari aset data
Azure Pembelajaran Mesin aset data (sebelumnya dikenal sebagai himpunan data) didukung sebagai input untuk pekerjaan. Ikuti langkah-langkah ini untuk menjalankan pekerjaan titik akhir batch menggunakan data yang disimpan dalam aset data terdaftar di Azure Pembelajaran Mesin:
Peringatan
Aset data jenis Tabel (MLTable) saat ini tidak didukung.
Pertama-tama buat aset data. Aset data ini terdiri dari folder dengan beberapa file CSV yang akan Anda proses secara paralel, menggunakan titik akhir batch. Anda dapat melewati langkah ini jika data Anda sudah terdaftar sebagai aset data.
Buat definisi aset data di
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataKemudian, buat aset data:
az ml data create -f heart-dataset-unlabeled.ymlBuat input atau permintaan:
DATASET_ID=$(az ml data show -n heart-dataset-unlabeled --label latest | jq -r .id)Catatan
ID aset data akan terlihat seperti
/subscriptions/<subscription>/resourcegroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/data/<data-asset>/versions/<version>. Anda juga dapat menggunakanazureml:/<datasset_name>@latestsebagai cara untuk menentukan input.Jalankan titik akhir:
--setGunakan argumen untuk menentukan input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDUntuk titik akhir yang melayani penyebaran model, Anda dapat menggunakan
--inputargumen untuk menentukan input data, karena penyebaran model selalu hanya memerlukan satu input data.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDArgumen
--setcenderung menghasilkan perintah panjang ketika beberapa input ditentukan. Dalam kasus seperti itu, tempatkan input Anda dalamYAMLfile dan gunakan--fileuntuk menentukan input yang Anda butuhkan untuk pemanggilan titik akhir Anda.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Input data dari penyimpanan data
Data dari penyimpanan data terdaftar Azure Pembelajaran Mesin dapat langsung direferensikan oleh pekerjaan penyebaran batch. Dalam contoh ini, Anda terlebih dahulu mengunggah beberapa data ke penyimpanan data default di ruang kerja Azure Pembelajaran Mesin lalu menjalankan penyebaran batch di dalamnya. Ikuti langkah-langkah ini untuk menjalankan pekerjaan titik akhir batch menggunakan data yang disimpan di penyimpanan data.
Akses penyimpanan data default di ruang kerja Azure Pembelajaran Mesin. Jika data Anda berada di penyimpanan yang berbeda, Anda dapat menggunakan penyimpanan tersebut sebagai gantinya. Anda tidak diharuskan menggunakan penyimpanan data default.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Catatan
ID penyimpanan data akan terlihat seperti
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Tip
Penyimpanan data blob default di ruang kerja disebut workspaceblobstore. Anda dapat melewati langkah ini jika Anda sudah mengetahui ID sumber daya penyimpanan data default di ruang kerja Anda.
Anda perlu mengunggah beberapa data sampel ke penyimpanan data. Contoh ini mengasumsikan Anda sudah mengunggah data sampel yang disertakan dalam repositori di folder
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/datadiheart-disease-uci-unlabeledakun penyimpanan blob. Pastikan Anda telah melakukannya sebelum bergerak maju.Buat input atau permintaan:
Tempatkan jalur file dalam variabel berikut:
DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Catatan
Lihat bagaimana jalur
pathsditambahkan ke id sumber daya penyimpanan data untuk menunjukkan bahwa apa berikut ini adalah jalur di dalamnya.Tip
Anda juga dapat menggunakan
azureml://datastores/<data-store>/paths/<data-path>sebagai cara untuk menentukan input.Jalankan titik akhir:
--setGunakan argumen untuk menentukan input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHUntuk titik akhir yang melayani penyebaran model, Anda dapat menggunakan
--inputargumen untuk menentukan input data, karena penyebaran model selalu hanya memerlukan satu input data.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderArgumen
--setcenderung menghasilkan perintah panjang ketika beberapa input ditentukan. Dalam kasus seperti itu, tempatkan input Anda dalamYAMLfile dan gunakan--fileuntuk menentukan input yang Anda butuhkan untuk pemanggilan titik akhir Anda.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlJika data Anda adalah file, gunakan
uri_filesebagai jenis sebagai gantinya.
Input data dari Akun Azure Storage
Titik akhir batch Azure Pembelajaran Mesin dapat membaca data dari lokasi cloud di Akun Azure Storage, baik publik maupun privat. Gunakan langkah-langkah berikut untuk menjalankan pekerjaan titik akhir batch menggunakan data yang disimpan di akun penyimpanan:
Catatan
Periksa bagian mengonfigurasi kluster komputasi untuk akses data untuk mempelajari selengkapnya tentang konfigurasi tambahan yang diperlukan untuk berhasil membaca data dari akumulasi penyimpanan.
Buat input atau permintaan:
Jalankan titik akhir:
--setGunakan argumen untuk menentukan input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAUntuk titik akhir yang melayani penyebaran model, Anda dapat menggunakan
--inputargumen untuk menentukan input data, karena penyebaran model selalu hanya memerlukan satu input data.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderArgumen
--setcenderung menghasilkan perintah panjang ketika beberapa input ditentukan. Dalam kasus seperti itu, tempatkan input Anda dalamYAMLfile dan gunakan--fileuntuk menentukan input yang Anda butuhkan untuk pemanggilan titik akhir Anda.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlJika data Anda adalah file, gunakan
uri_filesebagai jenis sebagai gantinya.
Membuat pekerjaan dengan input harfiah
Penyebaran komponen alur dapat mengambil input harfiah. Contoh berikut menunjukkan cara menentukan input bernama score_mode, dari jenis string, dengan nilai append:
Tempatkan input Anda dalam YAML file dan gunakan --file untuk menentukan input yang Anda butuhkan untuk pemanggilan titik akhir Anda.
inputs.yml
inputs:
score_mode:
type: string
default: append
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Anda juga dapat menggunakan argumen --set untuk menentukan nilai. Namun, ia cenderung menghasilkan perintah panjang ketika beberapa input ditentukan:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Membuat pekerjaan dengan output data
Contoh berikut menunjukkan cara mengubah lokasi tempat output bernama score ditempatkan. Untuk kelengkapan, contoh-contoh ini juga mengonfigurasi input bernama heart_dataset.
Gunakan penyimpanan data default di ruang kerja Azure Pembelajaran Mesin untuk menyimpan output. Anda dapat menggunakan penyimpanan data lain di ruang kerja Anda selama itu adalah akun penyimpanan blob.
Membuat output data:
DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Untuk kelengkapan, buat juga input data:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Catatan
Lihat bagaimana jalur
pathsditambahkan ke id sumber daya penyimpanan data untuk menunjukkan bahwa apa berikut ini adalah jalur di dalamnya.Jalankan penyebaran: