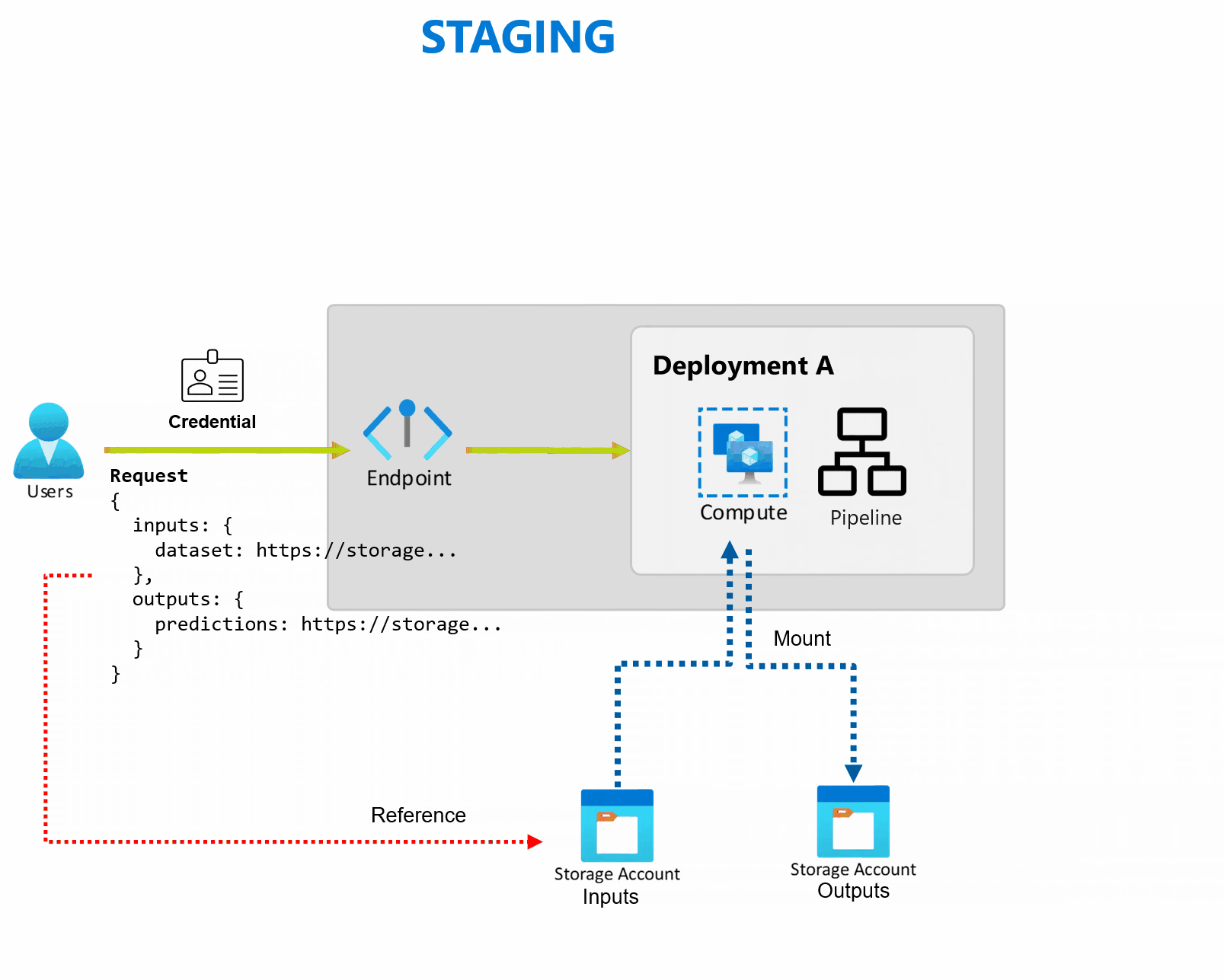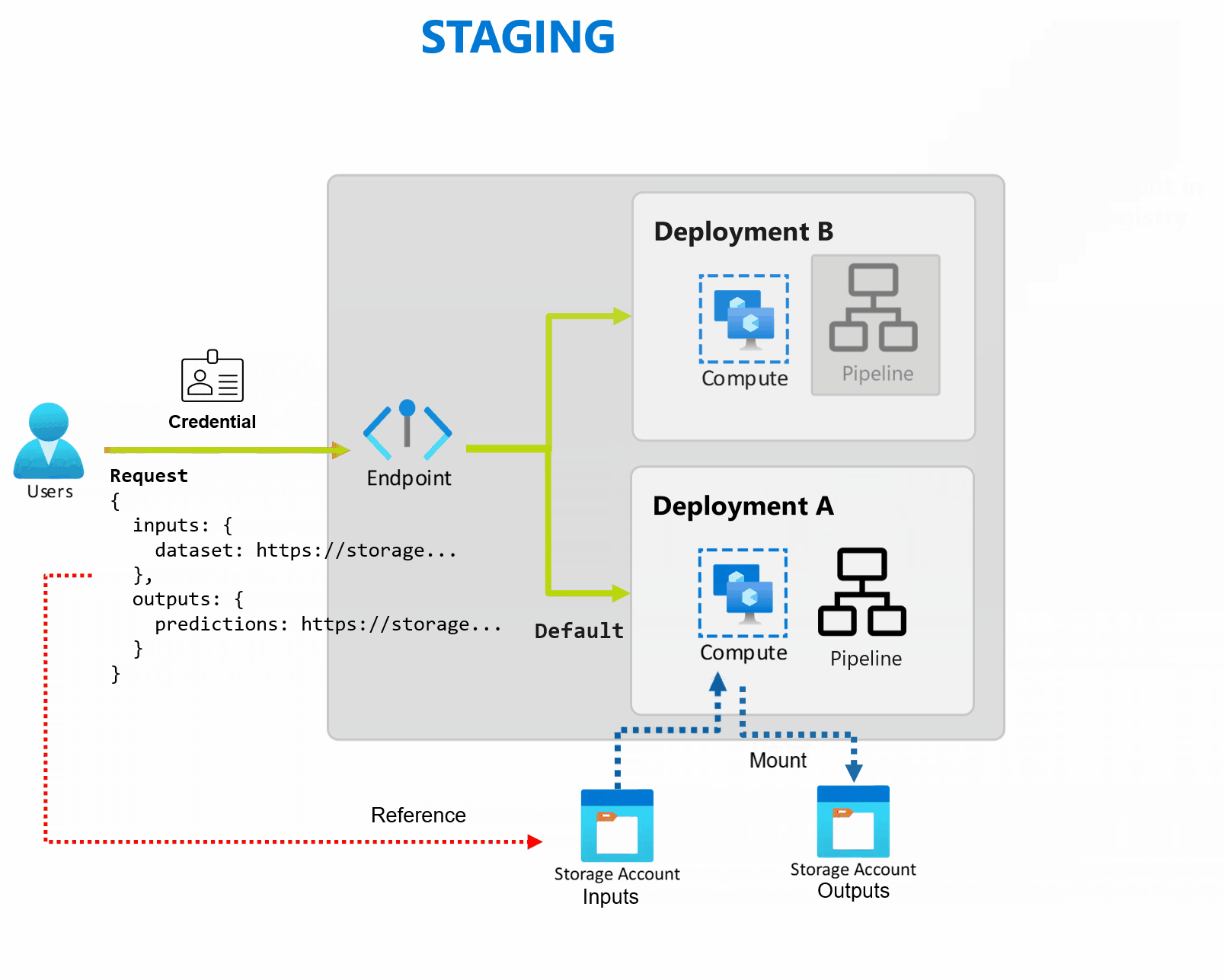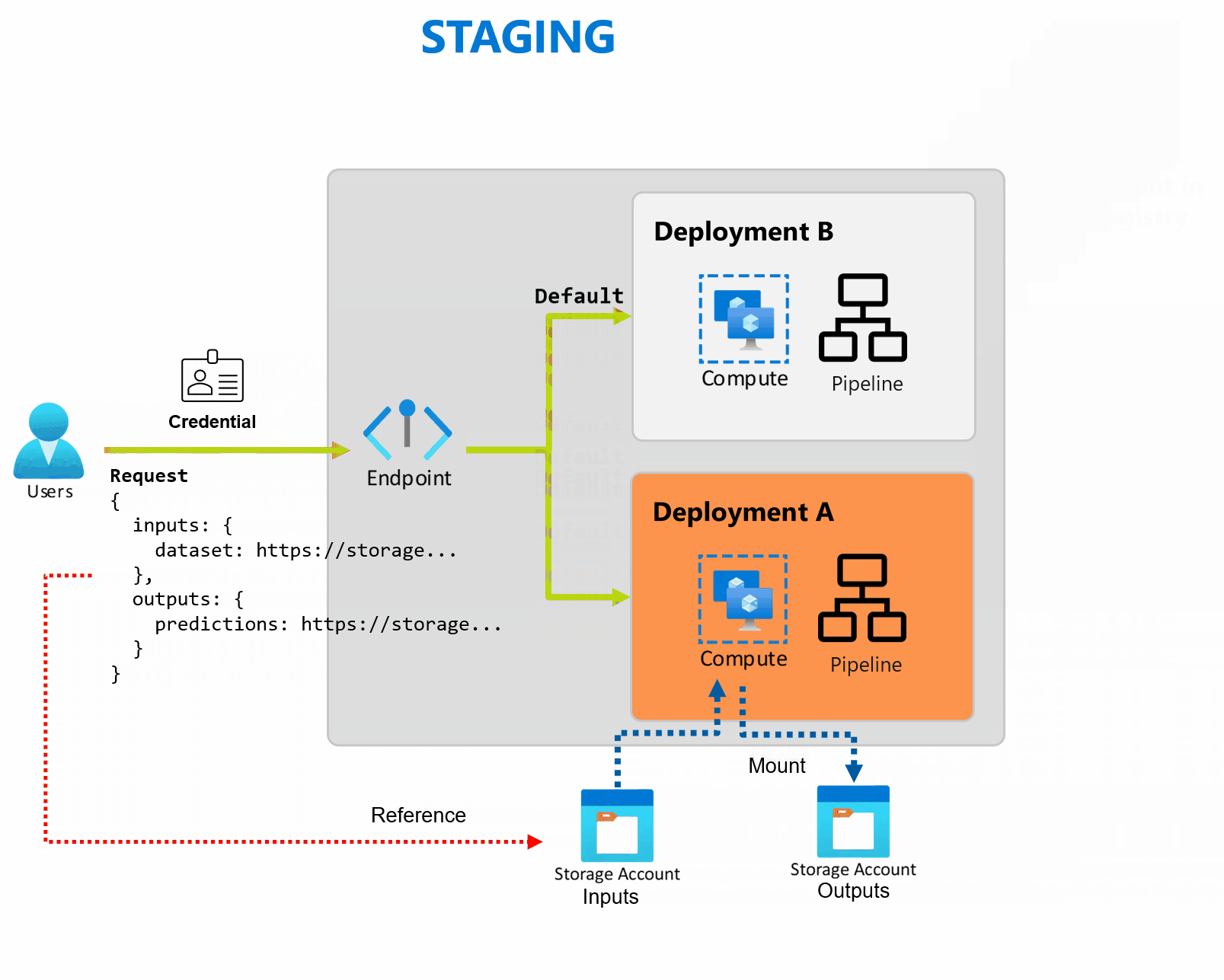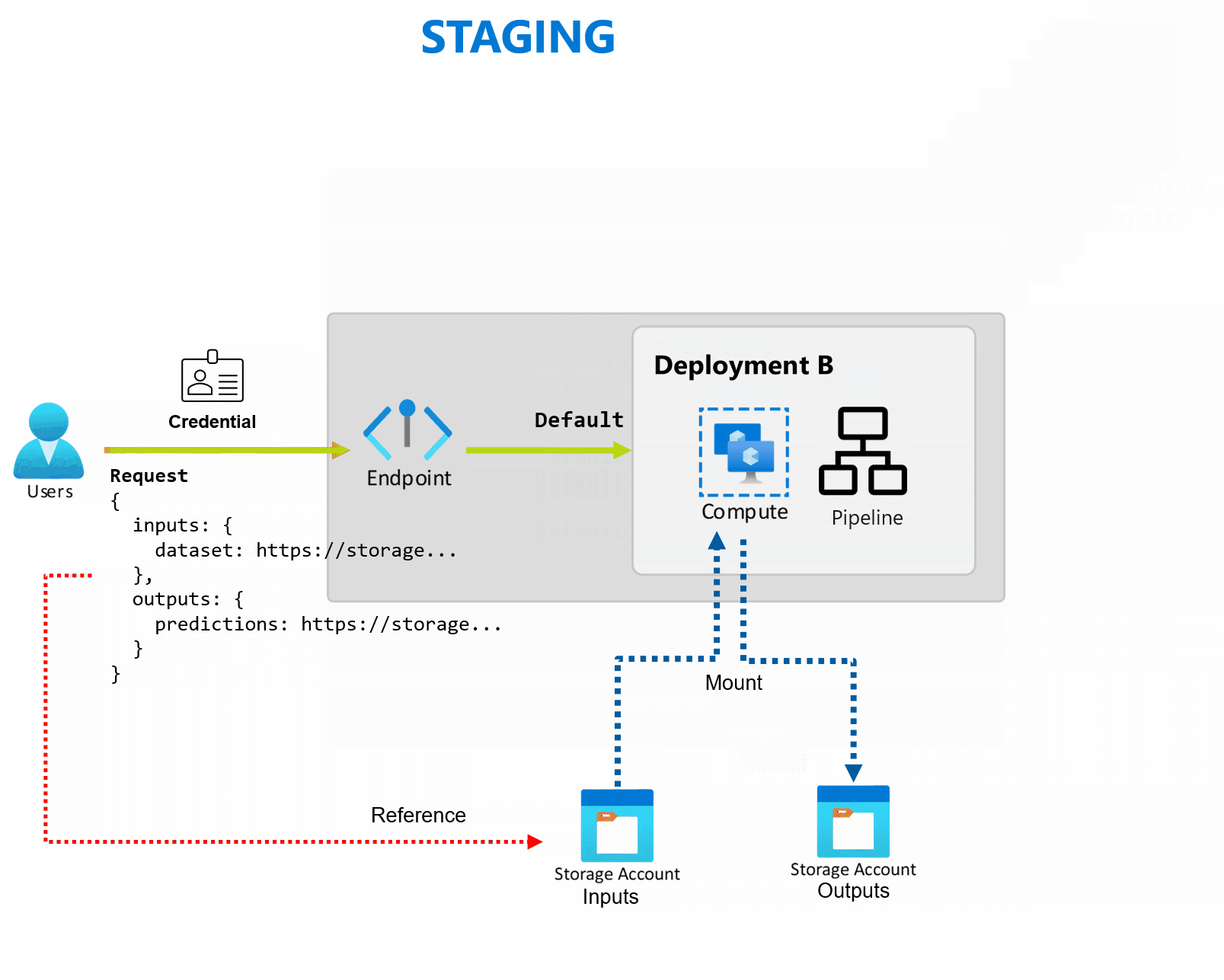
Titik akhir batch
Azure Pembelajaran Mesin memungkinkan Anda menerapkan titik akhir dan penyebaran batch untuk melakukan inferensi asinkron yang berjalan lama dengan model dan alur pembelajaran mesin. Saat melatih model atau alur pembelajaran mesin, Anda perlu menyebarkannya sehingga orang lain dapat menggunakannya dengan data input baru untuk menghasilkan prediksi. Proses pembuatan prediksi dengan model atau alur ini disebut inferensi.
Titik akhir batch menerima penunjuk ke data dan menjalankan tugas secara asinkron untuk memproses data secara paralel pada kluster komputasi. Titik akhir batch menyimpan output ke penyimpanan data untuk analisis lebih lanjut. Gunakan titik akhir batch saat:
- Anda memiliki model atau alur mahal yang membutuhkan waktu lebih lama untuk dijalankan.
- Anda ingin mengoprasialisasi alur pembelajaran mesin dan menggunakan kembali komponen.
- Anda perlu melakukan inferensi atas sejumlah besar data, didistribusikan dalam beberapa file.
- Anda tidak memiliki persyaratan latensi rendah.
- Input model Anda disimpan di Akun Penyimpanan atau di aset data pembelajaran Mesin Azure.
- Anda dapat memanfaatkan paralelisasi.
Penyebaran batch
Penyebaran adalah sekumpulan sumber daya dan komputasi yang diperlukan untuk mengimplementasikan fungsionalitas yang disediakan titik akhir. Setiap titik akhir dapat menghosting beberapa penyebaran dengan konfigurasi yang berbeda, dan fungsi ini membantu memisahkan antarmuka titik akhir dari detail implementasi yang ditentukan oleh penyebaran. Ketika titik akhir batch dipanggil, titik akhir secara otomatis merutekan klien ke penyebaran defaultnya. Penyebaran default ini dapat dikonfigurasi dan diubah kapan saja.

Dua jenis penyebaran dimungkinkan di titik akhir batch Azure Pembelajaran Mesin:
Penyebaran model
Penyebaran model memungkinkan operasionalisasi inferensi model dalam skala besar, memungkinkan Anda memproses data dalam jumlah besar dengan latensi rendah dan cara asinkron. Azure Pembelajaran Mesin secara otomatis melengkapi skalabilitas dengan memberikan paralelisasi proses inferensi di beberapa simpul dalam kluster komputasi.
Gunakan penyebaran Model saat:
- Anda memiliki model mahal yang membutuhkan waktu lebih lama untuk menjalankan inferensi.
- Anda perlu melakukan inferensi atas sejumlah besar data, didistribusikan dalam beberapa file.
- Anda tidak memiliki persyaratan latensi rendah.
- Anda dapat memanfaatkan paralelisasi.
Manfaat utama penyebaran model adalah Anda dapat menggunakan aset yang sama yang disebarkan untuk inferensi real time ke titik akhir online, tetapi sekarang, Anda dapat menjalankannya dalam skala besar dalam batch. Jika model Anda memerlukan praproses sederhana atau pasca-pemrosesan, Anda dapat menulis skrip penilaian yang melakukan transformasi data yang diperlukan.
Untuk membuat penyebaran model di titik akhir batch, Anda perlu menentukan elemen berikut:
- Model
- Kluster komputasi
- Skrip penilaian (opsional untuk model MLflow)
- Lingkungan (opsional untuk model MLflow)
Penyebaran komponen alur
Penyebaran komponen alur memungkinkan operasionalisasi seluruh grafik pemrosesan (atau alur) untuk melakukan inferensi batch dengan latensi rendah dan cara asinkron.
Gunakan penyebaran komponen Alur saat:
- Anda perlu mengoperalisasi grafik komputasi lengkap yang dapat didekomposisikan ke dalam beberapa langkah.
- Anda perlu menggunakan kembali komponen dari alur pelatihan dalam alur inferensi Anda.
- Anda tidak memiliki persyaratan latensi rendah.
Manfaat utama penyebaran komponen alur adalah penggunaan kembali komponen yang sudah ada di platform Anda dan kemampuan untuk mengoperasionalkan rutinitas inferensi yang kompleks.
Untuk membuat penyebaran komponen alur di titik akhir batch, Anda perlu menentukan elemen berikut:
- Komponen alur
- Konfigurasi kluster komputasi
Titik akhir batch juga memungkinkan Anda membuat penyebaran komponen alur dari pekerjaan alur yang ada. Saat melakukannya, Azure Pembelajaran Mesin secara otomatis membuat komponen alur dari pekerjaan. Ini menyederhanakan penggunaan penyebaran semacam ini. Namun, ini adalah praktik terbaik untuk selalu membuat komponen alur secara eksplisit untuk menyederhanakan praktik MLOps Anda.
Cost management
Memanggil titik akhir batch memicu tugas inferensi batch asinkron. Azure Pembelajaran Mesin secara otomatis menyediakan sumber daya komputasi saat pekerjaan dimulai, dan secara otomatis membatalkan alokasinya saat pekerjaan selesai. Dengan cara ini, Anda hanya membayar komputasi ketika Anda menggunakannya.
Tip
Saat menyebarkan model, Anda dapat mengganti pengaturan sumber daya komputasi (seperti jumlah instans) dan pengaturan tingkat lanjut (seperti ukuran batch mini, ambang kesalahan, dan sebagainya) untuk setiap pekerjaan inferensi batch individual. Dengan memanfaatkan konfigurasi spesifik ini, Anda mungkin dapat mempercepat eksekusi dan mengurangi biaya.
Titik akhir batch juga dapat berjalan pada VM berprioritas rendah. Titik akhir batch dapat secara otomatis pulih dari VM yang dibatalkan alokasinya dan melanjutkan pekerjaan dari tempatnya dibiarkan saat menyebarkan model untuk inferensi. Untuk informasi selengkapnya tentang cara menggunakan VM berprioritas rendah untuk mengurangi biaya beban kerja inferensi batch, lihat Menggunakan VM berprioritas rendah di titik akhir batch.
Terakhir, Azure Pembelajaran Mesin tidak menagih Anda untuk titik akhir batch atau penyebaran batch itu sendiri, sehingga Anda dapat mengatur titik akhir dan penyebaran yang paling sesuai dengan skenario Anda. Titik akhir dan penyebaran dapat menggunakan kluster independen atau bersama, sehingga Anda dapat mencapai kontrol halus di mana menghitung pekerjaan yang digunakan. Gunakan skala-ke-nol dalam kluster untuk memastikan tidak ada sumber daya yang digunakan saat diam.
Menyederhanakan praktik MLOps
Titik akhir batch dapat menangani beberapa penyebaran di bawah titik akhir yang sama, memungkinkan Anda mengubah implementasi titik akhir tanpa mengubah URL yang digunakan konsumen Anda untuk memanggilnya.
Anda dapat menambahkan, menghapus, dan memperbarui penyebaran tanpa memengaruhi titik akhir itu sendiri.
Sumber dan penyimpanan data yang fleksibel
Titik akhir batch membaca dan menulis data langsung dari penyimpanan. Anda dapat menentukan penyimpanan data Azure Pembelajaran Mesin, aset data Azure Pembelajaran Mesin, atau Akun Penyimpanan sebagai input. Untuk informasi selengkapnya tentang opsi input yang didukung dan cara menentukannya, lihat Membuat pekerjaan dan memasukkan data ke titik akhir batch.
Keamanan
Titik akhir batch menyediakan semua kemampuan yang diperlukan untuk mengoperasikan beban kerja tingkat produksi dalam pengaturan perusahaan. Mereka mendukung jaringan privat di ruang kerja aman dan autentikasi Microsoft Entra, baik menggunakan prinsipal pengguna (seperti akun pengguna) atau perwakilan layanan (seperti identitas terkelola atau tidak terkelola). Pekerjaan yang dihasilkan oleh titik akhir batch berjalan di bawah identitas pemanggil, yang memberi Anda fleksibilitas untuk mengimplementasikan skenario apa pun. Untuk informasi selengkapnya tentang otorisasi saat menggunakan titik akhir batch, lihat Cara mengautentikasi pada titik akhir batch.