Access data from Azure cloud storage during interactive development
APPLIES TO:  Python SDK azure-ai-ml v2 (current)
Python SDK azure-ai-ml v2 (current)
A machine learning project typically starts with exploratory data analysis (EDA), data-preprocessing (cleaning, feature engineering), and it includes building ML model prototypes to validate hypotheses. This prototyping project phase is highly interactive in nature, and it lends itself to development in a Jupyter notebook, or in an IDE with a Python interactive console. In this article, learn how to:
- Access data from an Azure Machine Learning Datastores URI as if it were a file system.
- Materialize data into Pandas using the
mltablePython library. - Materialize Azure Machine Learning data assets into Pandas using the
mltablePython library. - Materialize data through an explicit download with the
azcopyutility.
Prerequisites
- An Azure Machine Learning workspace. For more information, visit Manage Azure Machine Learning workspaces in the portal or with the Python SDK (v2).
- An Azure Machine Learning Datastore. For more information, visit Create datastores.
Tip
The guidance in this article describes data access during interactive development. It applies to any host that can run a Python session. This can include your local machine, a cloud VM, a GitHub Codespace, etc. We recommend use of an Azure Machine Learning compute instance - a fully managed and pre-configured cloud workstation. For more information, visit Create an Azure Machine Learning compute instance.
Important
Ensure you have the latest azure-fsspec, mltable, and azure-ai-ml python libraries installed in your Python environment:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
The latest azure-fsspec package version can potentially change over time. For more information about the azure-fsspec package, visit this resource.
Access data from a datastore URI, like a filesystem
An Azure Machine Learning datastore is a reference to an existing Azure storage account. The benefits of datastore creation and use include:
- A common, easy-to-use API to interact with different storage types (Blob/Files/ADLS).
- Easy discovery of useful datastores in team operations.
- Support of both credential-based (for example, SAS token) and identity-based (use Microsoft Entra ID or Manged identity) access, to access data.
- For credential-based access, the connection information is secured, to void key exposure in scripts.
- Browse data and copy-paste datastore URIs in the Studio UI.
A Datastore URI is a Uniform Resource Identifier, which is a reference to a storage location (path) on your Azure storage account. A datastore URI has this format:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
These Datastore URIs are a known implementation of the Filesystem spec (fsspec): a unified pythonic interface to local, remote, and embedded file systems and bytes storage. First, use pip to install the azureml-fsspec package and its dependency azureml-dataprep package. Then, you can use the Azure Machine Learning Datastore fsspec implementation.
The Azure Machine Learning Datastore fsspec implementation automatically handles the credential/identity passthrough that the Azure Machine Learning datastore uses. You can avoid both account key exposure in your scripts, and extra sign-in procedures, on a compute instance.
For example, you can directly use Datastore URIs in Pandas. This example shows how to read a CSV file:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Tip
To avoid remembering the datastore URI format, you can copy-and-paste the datastore URI from the Studio UI with these steps:
- Select Data from the left-hand menu, then select the Datastores tab.
- Select your datastore name, and then Browse.
- Find the file/folder you want to read into Pandas, and select the ellipsis (...) next to it. Select Copy URI from the menu. You can select the Datastore URI to copy into your notebook/script.
You can also instantiate an Azure Machine Learning filesystem, to handle filesystem-like commands - for example ls, glob, exists, open.
- The
ls()method lists files in a specific directory. You can use ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) to list files. We support both '.' and '..', in relative paths. - The
glob()method supports '*' and '**' globbing. - The
exists()method returns a Boolean value that indicates whether a specified file exists in current root directory. - The
open()method returns a file-like object, which can be passed to any other library that expects to work with python files. Your code can also use this object, as if it were a normal python file object. These file-like objects respect the use ofwithcontexts, as shown in this example:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Upload files via AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath is the local path, and rpath is the remote path.
If the folders you specify in rpath don't yet exist, we create the folders for you.
We support three 'overwrite' modes:
- APPEND: if a file with the same name exists in the destination path, APPEND keeps the original file
- FAIL_ON_FILE_CONFLICT: if a file with the same name exists in the destination path, FAIL_ON_FILE_CONFLICT throws an error
- MERGE_WITH_OVERWRITE: if a file with the same name exists in the destination path, MERGE_WITH_OVERWRITE overwrites that existing file with the new file
Download files via AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Examples
These examples show use of the filesystem spec use in common scenarios.
Read a single CSV file into Pandas
You can read a single CSV file into Pandas as shown:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Read a folder of CSV files into Pandas
The Pandas read_csv() method doesn't support reading a folder of CSV files. To handle this, glob the csv paths, and concatenate them to a data frame with the Pandas concat() method. The next code sample shows how to achieve this concatenation with the Azure Machine Learning filesystem:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Reading CSV files into Dask
This example shows how to read a CSV file into a Dask data frame:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Read a folder of parquet files into Pandas
As part of an ETL process, Parquet files are typically written to a folder, which can then emit files relevant to the ETL such as progress, commits, etc. This example shows files created from an ETL process (files beginning with _) which then produce a parquet file of data.
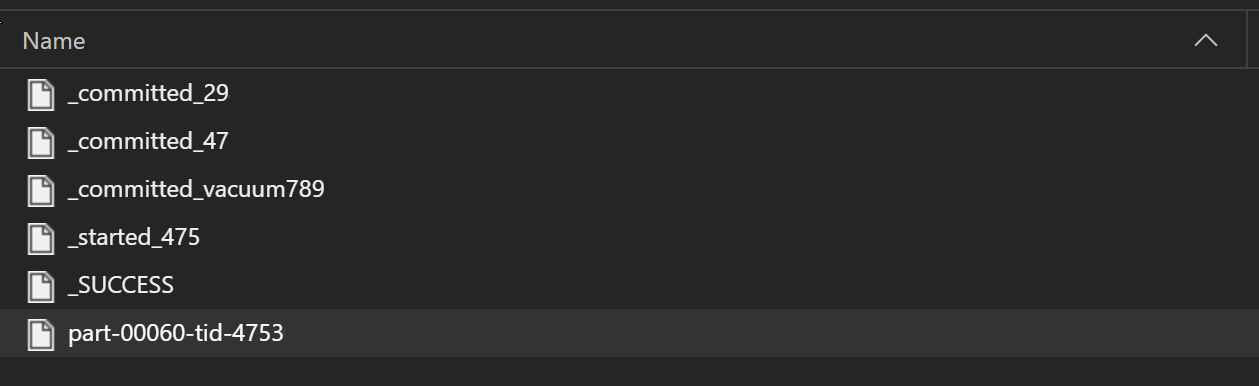
In these scenarios, you only read the parquet files in the folder, and ignore the ETL process files. This code sample shows how glob patterns can read only parquet files in a folder:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Accessing data from your Azure Databricks filesystem (dbfs)
Filesystem spec (fsspec) has a range of known implementations, including the Databricks Filesystem (dbfs).
To access data from the dbfs resource, you need:
- Instance name, in the form of
adb-<some-number>.<two digits>.azuredatabricks.net. You can find this value in the URL of your Azure Databricks workspace. - Personal Access Token (PAT); for more information about PAT creation, visit Authentication using Azure Databricks personal access tokens
With these values, you must create an environment variable for the PAT token on your compute instance:
export ADB_PAT=<pat_token>
You can then access data in Pandas, as shown in this example:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Reading images with pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
PyTorch custom dataset example
In this example, you create a PyTorch custom dataset for processing images. We assume that an annotations file (in CSV format) exists, with this overall structure:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Subfolders store these images, according to their labels:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
A custom PyTorch Dataset class must implement three functions: __init__, __len__, and __getitem__, as shown here:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
You can then instantiate the dataset, as shown here:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materialize data into Pandas using mltable library
The mltable library can also help access data in cloud storage. Reading data into Pandas with mltable has this general format:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Supported paths
The mltable library supports reading of tabular data from different path types:
| Location | Examples |
|---|---|
| A path on your local computer | ./home/username/data/my_data |
| A path on a public http(s) server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| A path on Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| A long-form Azure Machine Learning datastore | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Note
mltable does user credential passthrough for paths on Azure Storage and Azure Machine Learning datastores. If you do not have permission to access the data on the underlying storage, you cannot access the data.
Files, folders, and globs
mltable supports reading from:
- file(s) - for example:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - folder(s) - for example
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - glob pattern(s) - for example
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - a combination of files, folders, and/or globbing patterns
mltable flexibility allows data materialization, into a single dataframe, from a combination of local and cloud storage resources, and combinations of files/folder/globs. For example:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Supported file formats
mltable supports the following file formats:
- Delimited Text (for example: CSV files):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - JSON lines format:
mltable.from_json_lines_files(paths=[path])
Examples
Read a CSV file
Update the placeholders (<>) in this code snippet with your specific details:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Read parquet files in a folder
This example shows how mltable can use glob patterns - such as wildcards - to ensure that only the parquet files are read.
Update the placeholders (<>) in this code snippet with your specific details:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Reading data assets
This section shows how to access your Azure Machine Learning data assets in Pandas.
Table asset
If you previously created a table asset in Azure Machine Learning (an mltable, or a V1 TabularDataset), you can load that table asset into Pandas with this code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
File asset
If you registered a file asset (a CSV file, for example), you can read that asset into a Pandas data frame with this code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Folder asset
If you registered a folder asset (uri_folder or a V1 FileDataset) - for example, a folder containing a CSV file - you can read that asset into a Pandas data frame with this code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
A note on reading and processing large data volumes with Pandas
Tip
Pandas is not designed to handle large datasets. Pandas can only process data that can fit into the memory of the compute instance.
For large datasets, we recommend use of Azure Machine Learning managed Spark. This provides the PySpark Pandas API.
You might want to iterate quickly on a smaller subset of a large dataset before scaling up to a remote asynchronous job. mltable provides in-built functionality to get samples of large data using the take_random_sample method:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
You can also take subsets of large data with these operations:
Downloading data using the azcopy utility
Use the azcopy utility to download the data to the local SSD of your host (local machine, cloud VM, Azure Machine Learning Compute Instance, etc.), into the local filesystem. The azcopy utility, which is preinstalled on an Azure Machine Learning compute instance, handles the data download. If you don't use an Azure Machine Learning compute instance or a Data Science Virtual Machine (DSVM), you might need to install azcopy. For more information, visit azcopy.
Caution
We don't recommend data downloads into the /home/azureuser/cloudfiles/code location on a compute instance. This location is designed to store notebook and code artifacts, not data. Reading data from this location will incur significant performance overhead when training. Instead, we recommend data storage in the home/azureuser, which is the local SSD of the compute node.
Open a terminal and create a new directory, for example:
mkdir /home/azureuser/data
Sign-in to azcopy using:
azcopy login
Next, you can copy data using a storage URI
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST