Menyiapkan AutoML untuk melatih model penglihatan komputer
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Dalam artikel ini, Anda mempelajari cara melatih model visi komputer pada data gambar dengan ML otomatis. Anda dapat melatih model menggunakan ekstensi Azure Pembelajaran Mesin CLI v2 atau Azure Pembelajaran Mesin Python SDK v2.
ML otomatis mendukung pelatihan model untuk tugas computer vision seperti klasifikasi gambar, deteksi objek, dan segmentasi instans. Penulisan model AutoML untuk tugas computer vision saat ini didukung via Azure Machine Learning Python SDK. Percobaan, model, dan output eksperimen yang dihasilkan dapat diakses dari antarmuka pengguna studio Azure Pembelajaran Mesin. Pelajari selengkapnya tentang ml otomatis untuk tugas computer vision pada data gambar.
Prasyarat
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
- Ruang kerja Azure Machine Learning. Untuk membuat ruang kerja, lihat Membuat sumber daya ruang kerja.
- Instal dan siapkan CLI (v2) dan pastikan Anda menginstal ekstensi
ml.
Memilih jenis tugas Anda
ML otomatis untuk gambar mendukung jenis tugas berikut:
| Jenis tugas | Sintaks Pekerjaan AutoML |
|---|---|
| klasifikasi gambar | CLI v2: image_classification SDK v2: image_classification() |
| multi-label klasifikasi gambar | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| deteksi objek gambar | CLI v2: image_object_detection SDK v2: image_object_detection() |
| segmentasi instans gambar | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Jenis tugas ini adalah parameter yang diperlukan dan dapat diatur menggunakan kunci task.
Contohnya:
task: image_object_detection
Data pelatihan dan validasi
Untuk membuat model penglihatan komputer, Anda perlu membawa data citra berlabel sebagai input untuk pelatihan model dalam bentuk MLTable. Anda dapat membuat MLTable dari data pelatihan dalam format JSONL.
Jika data pelatihan Anda dalam format yang berbeda (seperti, pascal VOC atau COCO), Anda dapat menerapkan skrip helper yang disertakan dengan notebook sampel untuk mengonversi data ke JSONL. Pelajari selengkapnya tentang cara menyiapkan data untuk tugas computer vision dengan ML otomatis.
Catatan
Data pelatihan harus memiliki setidaknya 10 gambar agar dapat mengirimkan pekerjaan AutoML.
Peringatan
Pembuatan MLTable dari data dalam format JSONL didukung hanya oleh SDK dan CLI untuk kemampuan ini. Membuat MLTable melalui antarmuka pengguna tidak didukung saat ini.
Sampel skema JSONL
Struktur TabularDataset tergantung pada tugas yang ada. Untuk jenis tugas computer vision, ia terdiri dari bidang berikut:
| Bidang | Deskripsi |
|---|---|
image_url |
Berisi filepath sebagai objek StreamInfo |
image_details |
Informasi metadata gambar terdiri dari tinggi, lebar, dan format. Bidang ini opsional dan karenanya mungkin ada atau mungkin tidak ada. |
label |
Representasi json dari label gambar, berdasarkan jenis tugas. |
Kode berikut adalah contoh file JSONL untuk klasifikasi gambar:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Kode berikut ini adalah file JSONL sampel untuk deteksi objek:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Mengkonsumsi data
Setelah data Anda berada dalam format JSONL, Anda dapat membuat pelatihan dan validasi MLTable seperti yang ditunjukkan di bawah ini.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
ML otomatis tidak memaksakan batasan pada pelatihan atau validasi ukuran data untuk tugas penglihatan komputer. Ukuran himpunan data maksimum hanya dibatasi oleh lapisan penyimpanan di belakang himpunan data (Contoh: penyimpanan blob). Tidak ada jumlah minimum citra atau label. Namun, sebaiknya mulai dengan minimal 10-15 sampel per label untuk memastikan model output cukup terlatih. Semakin tinggi jumlah total label/kelas, semakin banyak sampel yang Anda butuhkan per label.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Data pelatihan adalah parameter yang diperlukan dan diteruskan menggunakan training_data kunci. Anda dapat secara opsional menentukan MLtable lain sebagai data validasi dengan kunci validation_data. Jika tidak ada data validasi yang ditentukan, 20% data pelatihan Anda digunakan untuk validasi secara default, kecuali Anda meneruskan validation_data_size argumen dengan nilai yang berbeda.
Nama kolom target adalah parameter yang diperlukan dan digunakan sebagai target untuk tugas ML yang diawasi. Ini diteruskan menggunakan target_column_name kunci. Contohnya,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Komputasi untuk menjalankan eksperimen
Berikan target komputasi untuk ML otomatis untuk melakukan pelatihan model. Model ML otomatis untuk tugas computer vision memerlukan GPU SKU dan mendukung keluarga NC dan ND. Kami merekomendasikan seri NCsv3 (dengan v100 GPU) untuk pelatihan yang lebih cepat. Target komputasi dengan SKU VM multi-GPU menggunakan beberapa GPU untuk juga mempercepat pelatihan. Selain itu, ketika Anda mengatur target komputasi dengan beberapa node Anda dapat melakukan pelatihan model yang lebih cepat melalui paralelisme saat menyetel hiperparameter untuk model Anda.
Catatan
Jika Anda menggunakan instans komputasi sebagai target komputasi Anda, pastikan bahwa beberapa pekerjaan AutoML tidak dijalankan secara bersamaan. Selain itu, pastikan bahwa max_concurrent_trials diatur ke 1 dalam batas pekerjaan Anda.
Target komputasi diteruskan menggunakan parameter compute. Contohnya:
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
compute: azureml:gpu-cluster
Mengonfigurasi eksperimen
Untuk tugas visi komputer, Anda dapat meluncurkan percobaan individual, pembersihan manual, atau pembersihan otomatis. Sebaiknya mulai dengan sapuan otomatis untuk mendapatkan model garis besar pertama. Kemudian, Anda dapat mencoba percobaan individual dengan model tertentu dan konfigurasi hyperparameter. Terakhir, dengan sapuan manual Anda dapat menjelajahi beberapa nilai hyperparameter di dekat model dan konfigurasi hyperparameter yang lebih menjanjikan. Alur kerja tiga langkah ini (pembersihan otomatis, uji coba individual, sapuan manual) menghindari pencarian keseluruhan ruang hiperparameter, yang tumbuh secara eksponensial dalam jumlah hiperparameter.
Pembersihan otomatis dapat menghasilkan hasil yang kompetitif untuk banyak himpunan data. Selain itu, mereka tidak memerlukan pengetahuan lanjutan tentang arsitektur model, mereka memperhitungkan korelasi hiperparameter dan mereka bekerja dengan mulus di berbagai pengaturan perangkat keras. Semua alasan ini menjadikannya pilihan yang kuat untuk tahap awal proses eksperimen Anda.
Metrik utama
Pekerjaan pelatihan AutoML menggunakan metrik utama untuk pengoptimalan model dan penyetelan hiperparameter. Metrik utama bergantung pada jenis tugas seperti yang ditunjukkan di bawah ini; nilai metrik utama lainnya saat ini tidak didukung.
- Akurasi untuk klasifikasi gambar
- Persimpangan atas serikat untuk multilabel klasifikasi gambar
- Presisi rata-rata rata untuk deteksi objek gambar
- Presisi rata-rata rata untuk segmentasi instans gambar
Batas untuk pekerjaan
Anda dapat mengontrol sumber daya yang dihabiskan untuk pekerjaan pelatihan AutoML Image Anda dengan menentukan timeout_minutes, max_trials dan max_concurrent_trials untuk pekerjaan dalam pengaturan batas seperti yang dijelaskan dalam contoh di bawah ini.
| Parameter | Detail |
|---|---|
max_trials |
Parameter untuk jumlah maksimum uji coba yang akan disapu. Harus bilangan bulat antara 1 dan 1000. Saat menjelajahi hanya hiperparameter default untuk arsitektur model tertentu, atur parameter ini ke 1. Nilai default adalah 1. |
max_concurrent_trials |
Jumlah maksimum uji coba yang dapat berjalan bersamaan. Jika ditentukan, harus bilangan bulat antara 1 dan 100. Nilai default adalah 1. CATATAN: max_concurrent_trials dibatasi max_trials secara internal. Misalnya, jika set max_concurrent_trials=4pengguna , max_trials=2, nilai akan diperbarui secara internal sebagai max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
Jumlah waktu dalam menit sebelum eksperimen berakhir. Jika tidak ada yang ditentukan, eksperimen default timeout_minutes adalah tujuh hari (maksimum 60 hari) |
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Menyapu hiperparameter model secara otomatis (AutoMode)
Penting
Fitur ini masih dalam pratinjau umum. Versi pratinjau ini disediakan tanpa perjanjian tingkat layanan. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Sulit untuk memprediksi arsitektur model dan hyperparameter terbaik untuk himpunan data. Juga, dalam beberapa kasus waktu manusia yang dialokasikan untuk menyetel hiperparameter mungkin terbatas. Untuk tugas visi komputer, Anda dapat menentukan sejumlah uji coba dan sistem secara otomatis menentukan wilayah ruang hyperparameter untuk disapu. Anda tidak perlu menentukan ruang pencarian hiperparameter, metode pengambilan sampel, atau kebijakan penghentian dini.
Memicu AutoMode
Anda dapat menjalankan pembersihan otomatis dengan mengatur max_trials ke nilai yang lebih besar dari 1 in limits dan dengan tidak menentukan ruang pencarian, metode pengambilan sampel, dan kebijakan penghentian. Kami menyebut fungsi ini AutoMode; silakan lihat contoh berikut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
limits:
max_trials: 10
max_concurrent_trials: 2
Sejumlah uji coba antara 10 dan 20 kemungkinan berfungsi dengan baik pada banyak himpunan data. Anggaran waktu untuk pekerjaan AutoML masih dapat ditetapkan, tetapi sebaiknya lakukan ini hanya jika setiap percobaan mungkin memakan waktu lama.
Peringatan
Meluncurkan pembersihan otomatis melalui UI tidak didukung saat ini.
Percobaan individual
Dalam percobaan individual, Anda langsung mengontrol arsitektur model dan hyperparameter. Arsitektur model diteruskan melalui model_name parameter .
Arsitektur model yang didukung
Tabel berikut ini meringkas model warisan yang didukung untuk setiap tugas visi komputer. Hanya menggunakan model warisan ini yang akan memicu eksekusi menggunakan runtime warisan (di mana setiap eksekusi atau uji coba individu dikirimkan sebagai pekerjaan perintah). Silakan lihat di bawah ini untuk dukungan HuggingFace dan MMDetection.
| Tugas | arsitektur model | Sintaks literal stringdefault_model* dilambangkan dengan * |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) |
MobileNet: Model ringan untuk aplikasi seluler ResNet: Jaringan residual ResNeSt: Jaringan perhatian terpisah SE-ResNeXt50: Jaringan Squeeze-and-Excitation ViT: Jaringan transformator visi |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (kecil) vitb16r224* (dasar) vitl16r224 (besar) |
| Deteksi objek | YOLOv5: Model deteksi objek satu tahap RCNN ResNet FPN yang lebih cepat: Model deteksi objek dua tahap RetinaNet ResNet FPN: mengatasi ketidakseimbangan kelas dengan Focal Loss Catatan: Lihat model_size hiperparameter untuk ukuran model YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentasi instans | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Arsitektur model yang didukung - HuggingFace dan MMDetection (pratinjau)
Dengan backend baru yang berjalan pada alur Azure Pembelajaran Mesin, Anda juga dapat menggunakan model klasifikasi gambar apa pun dari HuggingFace Hub yang merupakan bagian dari pustaka transformator (seperti microsoft/beit-base-patch16-224), serta deteksi objek atau model segmentasi instans dari MMDetection Versi 3.1.0 Model Zoo (seperti atss_r50_fpn_1x_coco).
Selain mendukung model apa pun dari HuggingFace Transfomers dan MMDetection 3.1.0, kami juga menawarkan daftar model yang dikumpulkan dari pustaka ini di registri azureml. Model yang dikumpulkan ini telah diuji secara menyeluruh dan menggunakan hiperparameter default yang dipilih dari tolok ukur ekstensif untuk memastikan pelatihan yang efektif. Tabel di bawah ini meringkas model yang dikumpulkan ini.
| Tugas | arsitektur model | Sintaks literal string |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) |
BEiT Vit DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Deteksi Objek | Sparse R-CNN DETR yang dapat dideformasi VFNet YOLOF Kembar |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentasi Instans | Kembar | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Kami terus memperbarui daftar model yang dikumpulkan. Anda bisa mendapatkan daftar terbaru model yang dikumpulkan untuk tugas tertentu menggunakan Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Output:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Menggunakan model HuggingFace atau MMDetection apa pun akan memicu eksekusi menggunakan komponen alur. Jika model warisan dan HuggingFace/MMdetection digunakan, semua eksekusi/uji coba akan dipicu menggunakan komponen.
Selain mengontrol arsitektur model, Anda juga dapat menyetel hiperparameter yang digunakan untuk pelatihan model. Meskipun banyak hiperparameter yang terpapar adalah agnostik model, ada instans di mana hiperparameter spesifik tugas atau spesifik model. Pelajari lebih lanjut hyperparameter yang tersedia untuk instans ini.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Jika Anda ingin menggunakan nilai hiperparameter default untuk arsitektur tertentu (misalnya yolov5), Anda dapat menentukannya menggunakan kunci model_name di bagian training_parameters. Contohnya,
training_parameters:
model_name: yolov5
Menyapu hiperparameter model secara manual
Ketika melatih model computer vision, performa model sangat tergantung pada nilai hiperparameter yang dipilih. Sering kali, Anda mungkin ingin menyetel hiperparameter untuk mendapatkan performa yang optimal. Untuk tugas visi komputer, Anda dapat menyapu hyperparameter untuk menemukan pengaturan optimal untuk model Anda. Fitur ini menerapkan kemampuan penyetelan hyperparameter dalam Azure Machine Learning. Pelajari cara menyetel hiperparameter.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Menentukan ruang pencarian parameter
Anda dapat menentukan arsitektur model dan hiperparameter untuk disapu di ruang parameter. Anda dapat menentukan arsitektur model tunggal atau beberapa arsitektur.
- Lihat Uji coba individual untuk daftar arsitektur model yang didukung untuk setiap jenis tugas.
- Lihat Hyperparameter untuk tugas visi komputer untuk setiap jenis tugas visi komputer.
- Lihat detail tentang distribusi yang didukung untuk hiperparameter diskret dan berkelanjutan.
Metode pengambilan sampel untuk sapuan
Saat menyapu hiperparameter, Anda perlu menentukan metode pengambilan sampel yang digunakan untuk menyapu ruang parameter yang ditentukan. Saat ini, metode pengambilan sampel berikut didukung dengan parameter sampling_algorithm:
| Jenis pengambilan sampel | Sintaks Pekerjaan AutoML |
|---|---|
| Pengambilan Sampel Acak | random |
| Pengambilan Sampel Kisi | grid |
| Pengambilan Sampel Bayes | bayesian |
Catatan
Saat ini hanya pengambilan sampel acak dan kisi yang mendukung ruang hiperparameter bersyar.
Kebijakan penghentian dini
Anda dapat secara otomatis mengakhiri uji coba dengan performa buruk dengan kebijakan penghentian dini. Penghentian dini meningkatkan efisiensi komputasi, menghemat sumber daya komputasi yang seharusnya dihabiskan untuk uji coba yang kurang menjanjikan. ML otomatis untuk gambar mendukung kebijakan penghentian dini berikut menggunakan parameter early_termination. Jika tidak ada kebijakan penghentian yang ditentukan, semua uji coba dijalankan hingga selesai.
| Kebijakan penghentian dini | Sintaks Pekerjaan AutoML |
|---|---|
| Kebijakan bandit | CLI v2: bandit SDK v2: BanditPolicy() |
| Kebijakan penghentian median | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Kebijakan pemilihan pemotongan | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Pelajari lebih lanjut tentang cara mengonfigurasi kebijakan penghentian dini untuk sapuan hiperparameter Anda.
Catatan
Untuk sampel konfigurasi sapuan lengkap, silakan lihat tutorial ini.
Anda dapat mengonfigurasi semua parameter terkait pembersihan seperti yang ditunjukkan dalam contoh berikut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Pengaturan tetap
Anda dapat meneruskan pengaturan tetap atau parameter yang tidak berubah selama pembersihan ruang parameter seperti yang ditunjukkan dalam contoh berikut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Augmentasi data
Secara umum, performa model pembelajaran mendalam sering dapat meningkat dengan lebih banyak data. Augmentasi data adalah teknik praktis untuk memperkuat ukuran data dan varianbilitas himpunan data, yang membantu mencegah overfitting dan meningkatkan kemampuan generalisasi model pada data yang tidak jelas. ML otomatis menerapkan teknik augmentasi data yang berbeda berdasarkan tugas computer vision, sebelum mengumpan gambar input ke model. Saat ini, tidak ada hyperparameter yang terekspos untuk mengontrol augmentasi data.
| Tugas | Himpunan data terdampak | Teknik augmentasi data yang diterapkan |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) | Pelatihan Validasi dan Uji |
Mengubah ukuran dan memangkas secara acak, flip horizontal, jitter warna (kecerahan, kontras, saturasi, dan warna), normalisasi menggunakan rata-rata dan simpangan baku ImageNet yang bijaksana Mengubah ukuran, potong tengah, normalisasi |
| Deteksi objek, segmentasi instans | Pelatihan Validasi dan Uji |
Pemangkasan acak di sekitar kotak pembatas, perluas, balik horizontal, normalisasi, ubah ukuran Normalisasi, pengubahan ukuran |
| Deteksi objek menggunakan yolov5 | Pelatihan Validasi dan Uji |
Mosaik, affine acak (rotasi, terjemahan, skala, geser), flip horizontal Mengubah ukuran letterbox |
Saat ini augmentasi yang ditentukan di atas diterapkan secara default untuk ML Otomatis untuk pekerjaan gambar. Untuk memberikan kontrol atas augmentasi, ML Otomatis untuk gambar mengekspos di bawah dua bendera untuk mematikan augmentasi tertentu. Saat ini, bendera ini hanya didukung untuk deteksi objek dan tugas segmentasi instans.
- apply_mosaic_for_yolo: Bendera ini hanya khusus untuk model Yolo. Mengaturnya ke False menonaktifkan augmentasi data mosaik, yang diterapkan pada waktu pelatihan.
- apply_automl_train_augmentations: Mengatur bendera ini ke false akan menonaktifkan augmentasi yang diterapkan selama waktu pelatihan untuk deteksi objek dan model segmentasi instans. Untuk augmentasi, lihat detail dalam tabel di atas.
- Untuk model deteksi objek non-yolo dan model segmentasi instans, bendera ini hanya menonaktifkan tiga augmentasi pertama. Misalnya: Pangkas acak di sekitar kotak pembatas, perluas, balik horizontal. Normalisasi dan augmentasi perubahan ukuran masih diterapkan terlepas dari bendera ini.
- Untuk model Yolo, bendera ini mematikan affine acak dan augmentasi flip horizontal.
Kedua bendera ini didukung melalui advanced_settings di bawah training_parameters dan dapat dikontrol dengan cara berikut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Perhatikan bahwa kedua bendera ini independen satu sama lain dan juga dapat digunakan dalam kombinasi menggunakan pengaturan berikut.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Dalam eksperimen kami, kami menemukan bahwa augmentasi ini membantu model untuk menggeneralisasi dengan lebih baik. Oleh karena itu, ketika augmentasi ini dinonaktifkan, kami menyarankan pengguna untuk menggabungkannya dengan augmentasi offline lainnya untuk mendapatkan hasil yang lebih baik.
Pelatihan bertahap (opsional)
Setelah pekerjaan pelatihan selesai, Anda dapat memilih untuk melatih model lebih lanjut dengan memuat titik pemeriksaan model terlatih. Untuk pelatihan bertahap, Anda dapat menggunakan himpunan data yang sama atau yang berbeda. Jika Anda puas dengan model, Anda dapat memilih untuk menghentikan pelatihan dan menggunakan model saat ini.
Meneruskan titik pemeriksaan melalui ID pekerjaan
Anda dapat meneruskan ID pekerjaan yang ingin Anda muat titik pemeriksaannya.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Mengirimkan pekerjaan AutoML
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
Untuk mengirimkan pekerjaan AutoML, jalankan perintah CLI v2 berikut dengan jalur ke file .yml, nama ruang kerja, grup sumber daya, dan ID langganan Anda.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Output dan metrik evaluasi
Pekerjaan pelatihan ML otomatis menghasilkan file model output, metrik evaluasi, log, dan artefak penyebaran seperti file penilaian dan file lingkungan. File dan metrik ini dapat dilihat dari tab output dan log dan metrik dari pekerjaan anak.
Tip
Periksa cara menavigasi ke hasil pekerjaan dari bagian Tampilkan hasil pekerjaan.
Untuk definisi dan contoh diagram dan metrik kinerja yang disediakan untuk setiap pekerjaan, lihat Mengevaluasi hasil eksperimen pembelajaran mesin otomatis.
Mendaftarkan dan menggunakan model
Setelah pekerjaan selesai, Anda dapat mendaftarkan model yang dibuat dari uji coba terbaik (konfigurasi yang menghasilkan metrik utama terbaik). Anda dapat mendaftarkan model setelah mengunduh atau dengan menentukan jalur azureml dengan jobid yang sesuai. Catatan: Saat Anda ingin mengubah pengaturan inferensi yang dijelaskan di bawah ini, Anda perlu mengunduh model dan mengubah settings.json dan mendaftar menggunakan folder model yang diperbarui.
Dapatkan uji coba terbaik
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
CLI example not available, please use Python SDK.
mendaftarkan model
Daftarkan model menggunakan jalur azureml atau jalur yang diunduh secara lokal.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Setelah mendaftarkan model yang ingin digunakan, Anda dapat menyebarkannya menggunakan titik akhir online terkelola deploy-managed-online-endpoint
Mengonfigurasi titik akhir online
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Membuat titik akhir
Dengan menggunakan yang MLClient dibuat sebelumnya, kita membuat Titik Akhir di ruang kerja. Perintah ini memulai pembuatan titik akhir dan mengembalikan respons konfirmasi saat pembuatan titik akhir berlanjut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Mengonfigurasi penyebaran online
Penyebaran adalah kumpulan sumber daya yang diperlukan untuk menghosting model yang melakukan inferensi aktual. Kita akan membuat penyebaran untuk titik akhir kita menggunakan kelas ManagedOnlineDeployment. Anda dapat menggunakan GPU atau CPU VM SKU untuk kluster penyebaran Anda.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Membuat penyebaran
Dengan menggunakan MLClient yang dibuat sebelumnya, kita sekarang akan membuat penyebaran di ruang kerja. Perintah ini akan memulai pembuatan penyebaran dan mengembalikan respons konfirmasi saat pembuatan penyebaran berlanjut.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
memperbarui lalu lintas:
Secara default penyebaran saat ini diatur untuk menerima 0% lalu lintas. Anda dapat mengatur persentase lalu lintas yang harus diterima penyebaran saat ini. Jumlah persentase lalu lintas dari semua penyebaran dengan satu titik akhir tidak boleh melebihi 100%.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Alternatifnya, Anda dapat menyebarkan model dari antarmuka pengguna studio Azure Machine Learning. Navigasikan ke model yang ingin Anda sebarkan di tab Model dari pekerjaan ML otomatis dan pilih Sebarkan dan pilih Sebarkan ke titik akhir real-time .
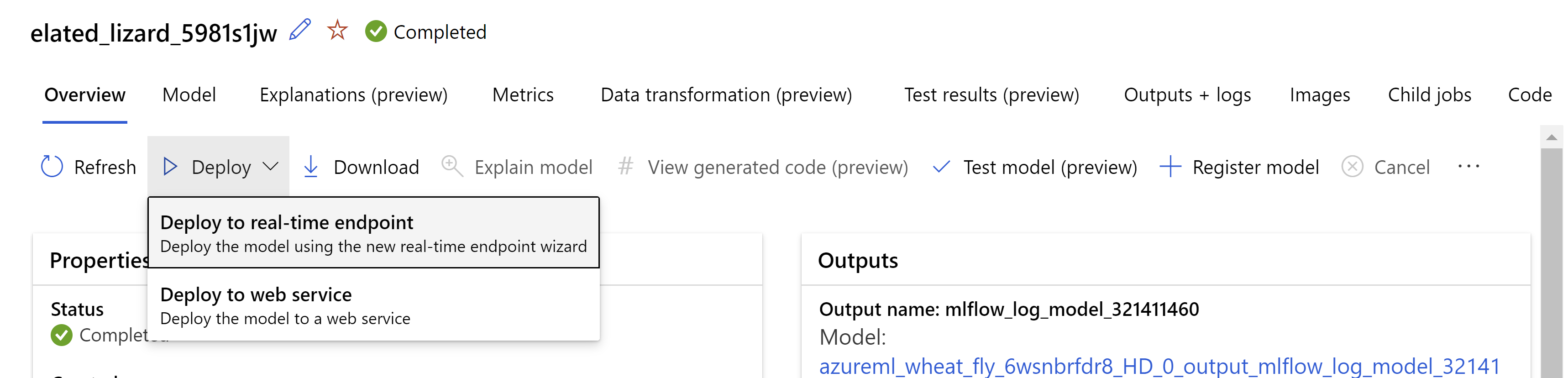 .
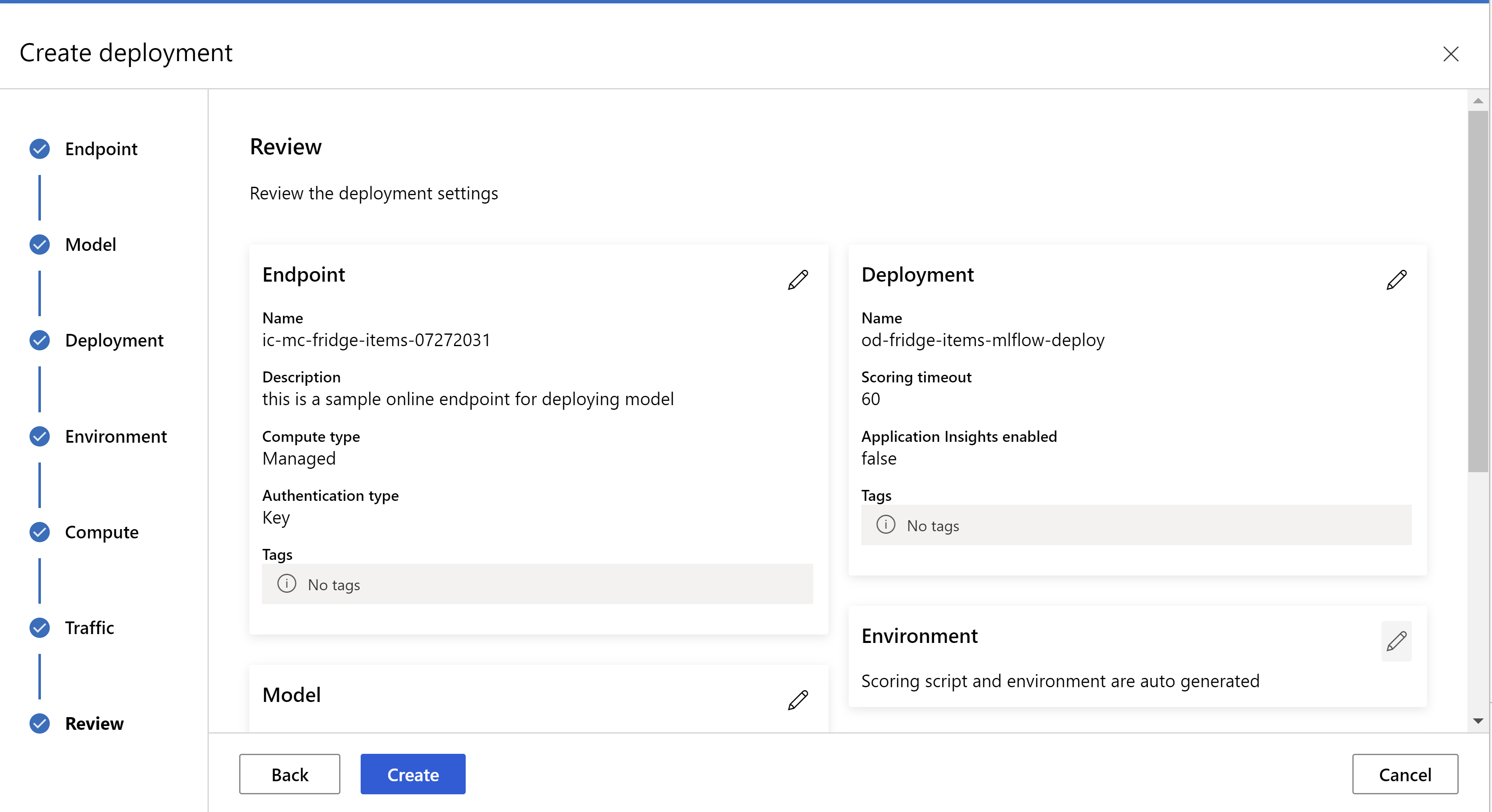
.
seperti inilah tampilan halaman ulasan Anda. kita dapat memilih jenis instans, jumlah instans, dan mengatur persentase lalu lintas untuk penyebaran saat ini.
 .
.
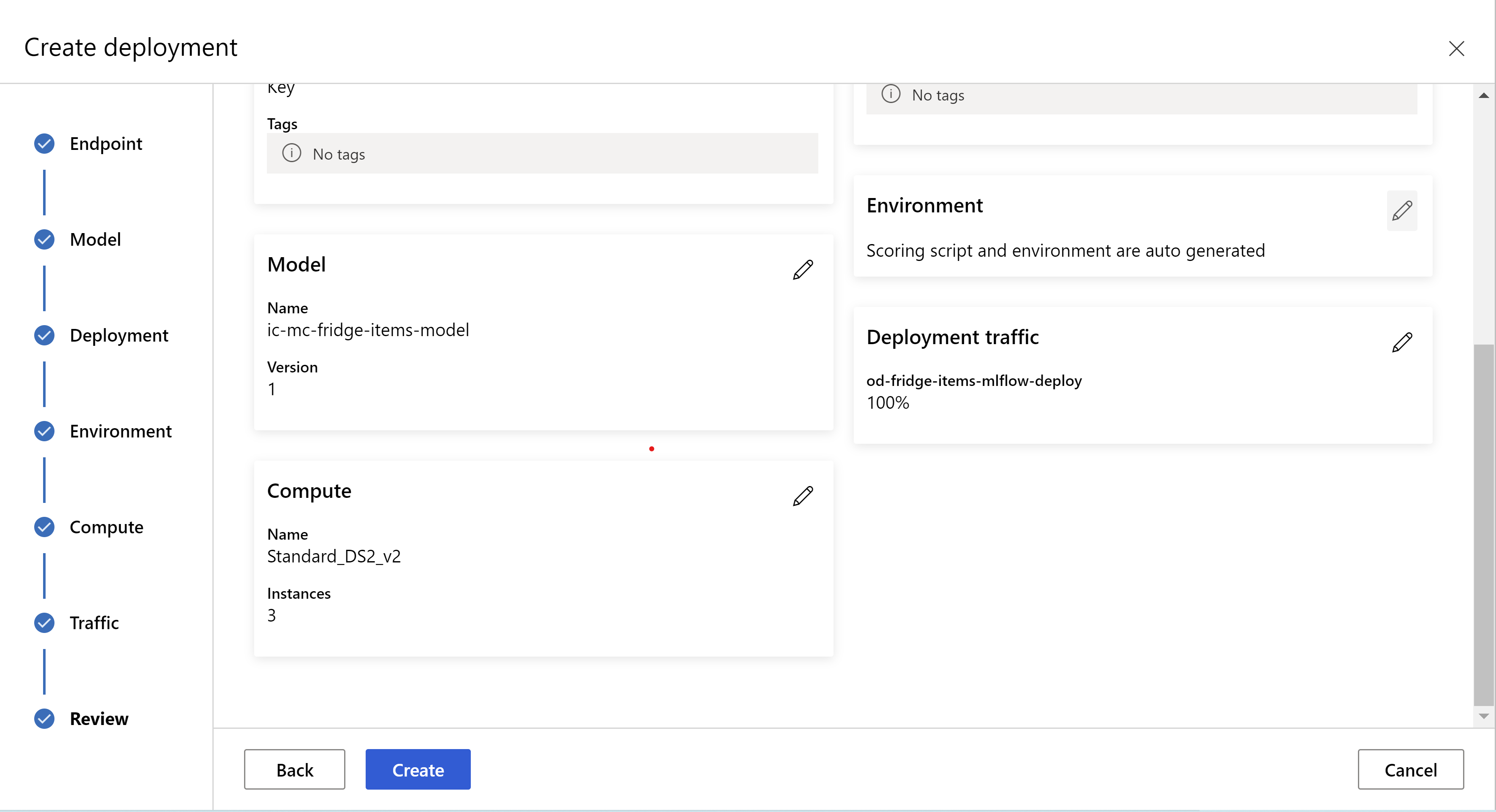 .
.
Memperbarui pengaturan inferensi
Di langkah sebelumnya, kita mengunduh file mlflow-model/artifacts/settings.json dari model terbaik. yang dapat digunakan untuk memperbarui pengaturan inferensi sebelum mendaftarkan model. Meskipun disarankan untuk menggunakan parameter yang sama dengan pelatihan untuk performa terbaik.
Masing-masing tugas (dan beberapa model) memiliki set parameter. Secara default, kami menggunakan nilai yang sama untuk parameter yang digunakan selama pelatihan dan validasi. Tergantung pada perilaku yang kita butuhkan ketika menggunakan model untuk inferensi, kita dapat mengubah parameter ini. Di bawah ini Anda dapat menemukan daftar parameter untuk setiap jenis dan model tugas.
| Tugas | Nama Parameter | Default |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) | valid_resize_sizevalid_crop_size |
256 224 |
| Deteksi objek | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Deteksi objek menggunakan yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 Sedang 0.1 0,5 |
| Segmentasi instans | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Salah JPG |
Untuk deskripsi terperinci tentang hiperparameter khusus tugas, lihat Hyperparameter untuk tugas visi komputer dalam pembelajaran mesin otomatis.
Jika Anda ingin menggunakan pemetakan, dan ingin mengontrol perilaku pemetakan, parameter berikut tersedia: tile_grid_size, tile_overlap_ratio, dan tile_predictions_nms_thresh. Untuk detail selengkapnya tentang parameter ini, periksa Melatih model deteksi objek kecil menggunakan AutoML.
Menguji penyebarannya
Periksa bagian Uji penyebaran ini untuk menguji penyebaran dan memvisualisasikan deteksi dari model.
Hasilkan penjelasan untuk prediksi
Penting
Pengaturan ini saat ini dalam pratinjau publik. Mereka disediakan tanpa perjanjian tingkat layanan. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Peringatan
Penjelasan Model hanya didukung untuk klasifikasi multi-kelas dan klasifikasi multi-label.
Beberapa keuntungan menggunakan Explainable AI (XAI) dengan AutoML untuk gambar:
- Meningkatkan transparansi dalam prediksi model visi yang kompleks
- Membantu pengguna memahami fitur/piksel penting dalam gambar input yang berkontribusi pada prediksi model
- Membantu dalam memecahkan masalah model
- Membantu dalam menemukan bias
Penjelasan
Penjelasan adalah atribusi fitur atau bobot yang diberikan untuk setiap piksel dalam gambar input berdasarkan kontribusinya terhadap prediksi model. Setiap berat dapat negatif (berkorelasi negatif dengan prediksi) atau positif (berkorelasi positif dengan prediksi). Atribusi ini dihitung terhadap kelas yang diprediksi. Untuk klasifikasi multi-kelas, tepat satu matriks atribusi ukuran [3, valid_crop_size, valid_crop_size] dihasilkan per sampel, sedangkan untuk klasifikasi multi-label, matriks atribusi ukuran [3, valid_crop_size, valid_crop_size] dihasilkan untuk setiap label/kelas yang diprediksi untuk setiap sampel.
Menggunakan AI yang Dapat Dijelaskan di AutoML untuk Gambar pada titik akhir yang disebarkan, pengguna bisa mendapatkan visualisasi penjelasan (atribusi yang dilapisi pada gambar input) dan/atau atribusi (array ukuran [3, valid_crop_size, valid_crop_size]multidimensi ) untuk setiap gambar. Selain visualisasi, pengguna juga bisa mendapatkan matriks atribusi untuk mendapatkan kontrol lebih atas penjelasan (seperti menghasilkan visualisasi kustom menggunakan atribusi atau memeriksa segmen atribusi). Semua algoritma penjelasan menggunakan gambar persegi yang dipotong dengan ukuran valid_crop_size untuk menghasilkan atribusi.
Penjelasan dapat dihasilkan baik dari titik akhir online atau titik akhir batch. Setelah penyebaran selesai, titik akhir ini dapat digunakan untuk menghasilkan penjelasan untuk prediksi. Dalam penyebaran online, pastikan untuk meneruskan request_settings = OnlineRequestSettings(request_timeout_ms=90000) parameter ke ManagedOnlineDeployment dan mengatur request_timeout_ms ke nilai maksimumnya untuk menghindari masalah waktu habis saat menghasilkan penjelasan (lihat bagian mendaftar dan menyebarkan model). Beberapa metode kemampuan penjelasan (XAI) seperti xrai menghabiskan lebih banyak waktu (khususnya untuk klasifikasi multi-label karena kita perlu menghasilkan atribusi dan/atau visualisasi terhadap setiap label yang diprediksi). Jadi, kami merekomendasikan instans GPU apa pun untuk penjelasan yang lebih cepat. Untuk informasi selengkapnya tentang skema input dan output untuk menghasilkan penjelasan, lihat dokumen skema.
Kami mendukung algoritma penjelasan state-of-the-art berikut di AutoML untuk gambar:
- XRAI (xrai)
- Gradien Terintegrasi (integrated_gradients)
- GradCAM Terpandu (guided_gradcam)
- BackPropagation Terpandu (guided_backprop)
Tabel berikut menjelaskan parameter penyetelan khusus algoritma penjelasan untuk XRAI dan Gradien Terintegrasi. Backpropagation terpandu dan gradcam terpandu tidak memerlukan parameter penyetelan apa pun.
| Algoritma XAI | Parameter khusus algoritma | Nilai Default |
|---|---|---|
xrai |
1. n_steps: Jumlah langkah yang digunakan oleh metode perkiraan. Jumlah langkah yang lebih besar menyebabkan perkiraan atribusi yang lebih baik (penjelasan). Rentang n_steps adalah [2, inf), tetapi performa atribusi mulai menyatu setelah 50 langkah. Optional, Int 2. xrai_fast: Apakah akan menggunakan versi XRAI yang lebih cepat. jika True, maka waktu komputasi untuk penjelasan lebih cepat tetapi mengarah pada penjelasan yang kurang akurat (atribusi) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Jumlah langkah yang digunakan oleh metode perkiraan. Jumlah langkah yang lebih besar menyebabkan atribusi yang lebih baik (penjelasan). Rentang n_steps adalah [2, inf), tetapi performa atribusi mulai menyatu setelah 50 langkah.Optional, Int 2. approximation_method: Metode untuk menyetujui integral. Metode perkiraan yang tersedia adalah riemann_middle dan gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Algoritma XRAI secara internal menggunakan gradien terintegrasi. Jadi, n_steps parameter diperlukan oleh gradien terintegrasi dan algoritma XRAI. Jumlah langkah yang lebih besar menghabiskan lebih banyak waktu untuk mendekati penjelasan dan dapat mengakibatkan masalah waktu habis pada titik akhir online.
Sebaiknya gunakan algoritma BackPropagation Terpandu GradCAM Terpandu > XRAI > untuk penjelasan yang lebih baik, sedangkan BackPropagation > Terpandu GradCAM > Integrated Gradients > XRAI direkomendasikan untuk penjelasan yang lebih cepat dalam urutan yang ditentukan.>
Contoh permintaan ke titik akhir online terlihat seperti berikut ini. Permintaan ini menghasilkan penjelasan ketika model_explainability diatur ke True. Permintaan berikut menghasilkan visualisasi dan atribusi menggunakan algoritma XRAI versi yang lebih cepat dengan 50 langkah.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Untuk informasi selengkapnya tentang membuat penjelasan, lihat Repositori buku catatan GitHub untuk sampel pembelajaran mesin otomatis.
Menafsirkan Visualisasi
Titik akhir yang disebarkan mengembalikan string gambar yang dikodekan base64 jika keduanya model_explainability dan visualizations diatur ke True. Dekodekan string base64 seperti yang dijelaskan dalam notebook atau gunakan kode berikut untuk mendekode dan memvisualisasikan string gambar base64 dalam prediksi.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Gambar berikut menjelaskan Visualisasi penjelasan untuk gambar input sampel.

Gambar base64 yang didekodekan memiliki empat bagian gambar dalam kisi 2 x 2.
- Gambar di sudut kiri atas (0, 0) adalah gambar input yang dipotong
- Gambar di sudut kanan atas (0, 1) adalah peta panas atribusi pada skala warna bgyw (biru hijau kuning putih) di mana kontribusi piksel putih pada kelas yang diprediksi adalah piksel tertinggi dan biru adalah yang terendah.
- Gambar di sudut kiri bawah (1, 0) adalah peta panas campuran atribusi pada gambar input yang dipotong
- Gambar di sudut kanan bawah (1, 1) adalah gambar input yang dipotong dengan 30 persen piksel teratas berdasarkan skor atribusi.
Menafsirkan Atribusi
Titik akhir yang disebarkan mengembalikan atribusi jika keduanya model_explainability dan attributions diatur ke True. Untuk detail selengkapnya, lihat buku catatan klasifikasi multi-kelas dan klasifikasi multi-label.
Atribusi ini memberikan kontrol lebih kepada pengguna untuk menghasilkan visualisasi kustom atau untuk meneliti skor atribusi tingkat piksel. Cuplikan kode berikut menjelaskan cara untuk menghasilkan visualisasi kustom menggunakan matriks atribusi. Untuk informasi selengkapnya tentang skema atribusi untuk klasifikasi multi-kelas dan klasifikasi multi-label, lihat dokumen skema.
Gunakan nilai dan valid_crop_size yang tepat valid_resize_size dari model yang dipilih untuk menghasilkan penjelasan (nilai default masing-masing adalah 256 dan 224). Kode berikut menggunakan fungsionalitas visualisasi Captum untuk menghasilkan visualisasi kustom. Pengguna dapat menggunakan pustaka lain untuk menghasilkan visualisasi. Untuk detail selengkapnya, lihat utilitas visualisasi captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Himpunan data besar
Jika Anda menggunakan AutoML untuk melatih himpunan data besar, ada beberapa pengaturan eksperimental yang mungkin berguna.
Penting
Pengaturan ini saat ini dalam pratinjau publik. Mereka disediakan tanpa perjanjian tingkat layanan. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Pelatihan multi-GPU dan multi-simpul
Secara default, setiap model melatih pada satu VM. Jika melatih model membutuhkan terlalu banyak waktu, menggunakan VM yang berisi beberapa GPU dapat membantu. Waktu untuk melatih model pada himpunan data besar harus menurun dalam proporsi yang kira-kira linier dengan jumlah GPU yang digunakan. (Misalnya, model harus berlatih sekitar dua kali lebih cepat pada VM dengan dua GPU seperti pada VM dengan satu GPU.) Jika waktu untuk melatih model masih tinggi pada VM dengan beberapa GPU, Anda dapat meningkatkan jumlah VM yang digunakan untuk melatih setiap model. Mirip dengan pelatihan multi-GPU, waktu untuk melatih model pada himpunan data besar juga harus menurun dalam proporsi yang kira-kira linier dengan jumlah VM yang digunakan. Saat melatih model di beberapa VM, pastikan untuk menggunakan SKU komputasi yang mendukung InfiniBand untuk hasil terbaik. Anda dapat mengonfigurasi jumlah VM yang digunakan untuk melatih satu model dengan mengatur node_count_per_trial properti pekerjaan AutoML.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
properties:
node_count_per_trial: "2"
Streaming file gambar dari penyimpanan
Secara default, semua file gambar diunduh ke disk sebelum pelatihan model. Jika ukuran file gambar lebih besar dari ruang disk yang tersedia, pekerjaan gagal. Alih-alih mengunduh semua gambar ke disk, Anda dapat memilih untuk melakukan streaming file gambar dari penyimpanan Azure sesuai kebutuhan selama pelatihan. File gambar dialirkan dari penyimpanan Azure langsung ke memori sistem, melewati disk. Pada saat yang sama, sebanyak mungkin file dari penyimpanan di-cache pada disk untuk meminimalkan jumlah permintaan ke penyimpanan.
Catatan
Jika streaming diaktifkan, pastikan akun penyimpanan Azure terletak di wilayah yang sama dengan komputasi untuk meminimalkan biaya dan latensi.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Contoh buku catatan
Tinjau contoh kode terperinci dan kasus penggunaan di repositori buku catatan GitHub untuk sampel pembelajaran mesin otomatis. Periksa folder dengan awalan 'automl-image-' untuk sampel khusus untuk membangun model visi komputer.
Contoh kode
Tinjau contoh kode terperinci dan kasus penggunaan di repositori azureml-examples untuk sampel pembelajaran mesin otomatis.