Menggunakan kontainer kustom untuk menyebarkan model ke titik akhir online
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Pelajari cara menggunakan kontainer kustom untuk menyebarkan model ke titik akhir online di Azure Pembelajaran Mesin.
Penyebaran kontainer kustom dapat menggunakan server web selain server Python Flask default yang digunakan oleh Azure Machine Learning. Pengguna penyebaran ini masih dapat menggunakan keunggulan bawaan Azure Machine Learning dalam pemantauan, penskalaan, peringatan, dan autentikasi.
Tabel berikut mencantumkan berbagai contoh penyebaran yang menggunakan kontainer kustom seperti TensorFlow Serving, TorchServe, Triton Inference Server, paket Plumber R, dan gambar Azure Pembelajaran Mesin Inference Minimal.
| Contoh | Skrip (CLI) | Deskripsi |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Sebarkan beberapa model ke satu penyebaran dengan memperluas gambar Azure Pembelajaran Mesin Inference Minimal. |
| minimal/model tunggal | deploy-custom-container-minimal-single-model | Sebarkan satu model dengan memperluas gambar Azure Pembelajaran Mesin Inference Minimal. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Sebarkan dua model MLFlow dengan persyaratan Python yang berbeda untuk dua penyebaran terpisah di belakang satu titik akhir menggunakan Azure Pembelajaran Mesin Inference Minimal Image. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Menyebarkan tiga model regresi ke satu titik akhir menggunakan paket Plumber R |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Sebarkan model Half Plus Two menggunakan kontainer kustom TensorFlow Serving menggunakan proses pendaftaran model standar. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Sebarkan model Half Plus Two menggunakan kontainer kustom TensorFlow Serving dengan model yang terintegrasi ke dalam gambar. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Sebarkan satu model menggunakan kontainer kustom TorchServe. |
| triton/model tunggal | deploy-custom-container-triton-single-model | Menyebarkan model Triton menggunakan kontainer kustom |
Artikel ini berfokus pada penyajian model TensorFlow dengan TensorFlow (TF) Serving.
Peringatan
Microsoft mungkin tidak dapat membantu memecahkan masalah yang disebabkan oleh gambar kustom. Jika Mengalami masalah, Anda mungkin diminta untuk menggunakan gambar default atau salah satu gambar yang disediakan Microsoft untuk melihat apakah masalahnya khusus untuk gambar Anda.
Prasyarat
Sebelum mengikuti langkah-langkah dalam artikel ini, pastikan Anda memiliki prasyarat berikut:
Ruang kerja Azure Machine Learning. Jika Anda tidak memilikinya, gunakan langkah-langkah dalam artikel Mulai Cepat: Membuat sumber daya ruang kerja untuk membuatnya.
Azure CLI dan
mlekstensi atau Azure Pembelajaran Mesin Python SDK v2:Untuk menginstal Azure CLI dan ekstensi, lihat Menginstal, menyiapkan, dan menggunakan CLI (v2).
Penting
Contoh CLI dalam artikel ini mengasumsikan bahwa Anda menggunakan shell Bash (atau kompatibel). Misalnya, dari sistem Linux atau Subsistem Windows untuk Linux.
Untuk memasang SDK Python v2, gunakan perintah berikut:
pip install azure-ai-ml azure-identityUntuk memperbarui penginstalan SDK yang ada ke versi terbaru, gunakan perintah berikut:
pip install --upgrade azure-ai-ml azure-identityUntuk informasi selengkapnya, lihat Menginstal Python SDK v2 untuk Azure Pembelajaran Mesin.
Anda, atau perwakilan layanan yang Anda gunakan, harus memiliki akses Kontributor ke grup sumber daya Azure yang berisi ruang kerja Anda. Anda memiliki grup sumber daya seperti itu jika Mengonfigurasi ruang kerja menggunakan artikel mulai cepat.
Untuk penyebaran secara lokal, Anda harus memiliki mesin Docker yang berjalan secara lokal. Langkah ini sangat disarankan. Ini membantu Anda men-debug masalah.
Mengunduh kode sumber
Untuk mengikuti tutorial ini, klon kode sumber dari GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inisialisasi beberapa variabel lingkungan
Tentukan variabel lingkungan:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Unduh model TensorFlow
Unduh dan buka zip model yang membagi input menjadi dua dan menambahkan 2 ke hasilnya:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Jalankan gambar TF Serving secara lokal untuk menguji bahwa layanan tersebut berfungsi
Gunakan docker untuk menjalankan gambar Anda secara lokal untuk pengujian:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Periksa apakah Anda dapat mengirim permintaan keaktifan dan penilaian ke gambar
Pertama, periksa apakah kontainer masih hidup, yang berarti bahwa proses di dalam kontainer masih berjalan. Anda harus mendapatkan respons 200 (OK).
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Kemudian, periksa apakah Anda bisa mendapatkan prediksi tentang data yang tidak berlabel:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Hentikan gambar
Sekarang setelah Anda menguji secara lokal, hentikan gambar:
docker stop tfserving-test
Menyebarkan titik akhir online Anda ke Azure
Selanjutnya, sebarkan titik akhir online Anda ke Azure.
Membuat file YAML untuk titik akhir dan penyebaran Anda
Anda dapat mengonfigurasi penyebaran cloud menggunakan YAML. Lihatlah sampel YAML untuk contoh ini:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Ada beberapa konsep penting yang perlu diperhatikan dalam parameter YAML/Python ini:
Gambar dasar
Gambar dasar ditentukan sebagai parameter di lingkungan, dan docker.io/tensorflow/serving:latest digunakan dalam contoh ini. Saat Anda memeriksa kontainer, Anda dapat menemukan bahwa server ini menggunakan ENTRYPOINT untuk memulai skrip titik masuk, yang mengambil variabel lingkungan seperti MODEL_BASE_PATH dan MODEL_NAME, dan mengekspos port seperti 8501. Detail ini adalah semua informasi spesifik untuk server yang dipilih ini. Anda dapat menggunakan pemahaman server ini, untuk menentukan cara menentukan penyebaran. Misalnya, jika Anda mengatur variabel lingkungan untuk MODEL_BASE_PATH dan MODEL_NAME dalam definisi penyebaran, server (dalam hal ini, TF Serving) akan mengambil nilai untuk memulai server. Demikian juga, jika Anda mengatur port untuk rute yang akan berada 8501 dalam definisi penyebaran, permintaan pengguna ke rute tersebut akan dirutekan dengan benar ke server TF Serving.
Perhatikan bahwa contoh spesifik ini didasarkan pada kasus TF Serving, tetapi Anda dapat menggunakan kontainer apa pun yang akan tetap aktif dan menanggapi permintaan yang akan ditampilkan, kesiapan, dan rute penilaian. Anda dapat merujuk ke contoh lain dan melihat bagaimana dockerfile terbentuk (misalnya, menggunakan CMD alih-alih ENTRYPOINT) untuk membuat kontainer.
Konfigurasi inferensi
Konfigurasi inferensi adalah parameter dalam lingkungan, dan menentukan port dan jalur untuk 3 jenis rute: keaktifan, kesiapan, dan rute penilaian. Konfigurasi inferensi diperlukan jika Anda ingin menjalankan kontainer Anda sendiri dengan titik akhir online terkelola.
Rute kesiapan vs rute keaktifan
Server API yang Anda pilih dapat menyediakan cara untuk memeriksa status server. Ada dua jenis rute yang dapat Anda tentukan: keaktifan dan kesiapan. Rute keaktifan digunakan untuk memeriksa apakah server berjalan. Rute kesiapan digunakan untuk memeriksa apakah server sudah siap untuk melakukan pekerjaan. Dalam konteks inferensi pembelajaran mesin, server dapat merespons 200 OK ke permintaan keaktifan sebelum memuat model, dan server dapat merespons 200 OK ke permintaan kesiapan hanya setelah model dimuat ke dalam memori.
Untuk informasi selengkapnya tentang pemeriksaan keaktifan dan kesiapan secara umum, lihat dokumentasi Kubernetes.
Rute keaktifan dan kesiapan akan ditentukan oleh server API pilihan Anda, seperti yang akan Anda identifikasi saat menguji kontainer secara lokal di langkah sebelumnya. Perhatikan bahwa contoh penyebaran dalam artikel ini menggunakan jalur yang sama untuk keaktifan dan kesiapan, karena TF Serving hanya menentukan rute keaktifan. Lihat contoh lain untuk pola yang berbeda untuk menentukan rute.
Rute penilaian
Server API yang Anda pilih akan menyediakan cara untuk menerima payload untuk dikerjakan. Dalam konteks inferensi pembelajaran mesin, server akan menerima data input melalui rute tertentu. Identifikasi rute ini untuk server API saat Anda menguji kontainer secara lokal di langkah sebelumnya, dan tentukan saat Anda menentukan penyebaran yang akan dibuat.
Perhatikan bahwa pembuatan penyebaran yang berhasil akan memperbarui parameter scoring_uri titik akhir juga, yang dapat Anda verifikasi dengan az ml online-endpoint show -n <name> --query scoring_uri.
Menemukan model yang dipasang
Saat Anda menyebarkan model sebagai titik akhir online, Azure Machine Learning memasang model Anda ke titik akhir Anda. Pemasangan model memungkinkan Anda untuk menyebarkan versi baru model tanpa harus membuat gambar Docker baru. Secara default, model yang terdaftar dengan nama foo dan versi 1 akan terletak di jalur berikut di dalam kontainer yang Anda sebarkan: /var/azureml-app/azureml-models/foo/1
Misalnya, jika Anda memiliki struktur direktori /azureml-examples/cli/endpoints/online/custom-container di komputer lokal Anda, di mana model diberi nama half_plus_two:
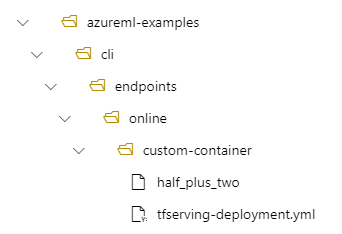
Dan tfserving-deployment.yml berisi:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Kemudian model Anda akan terletak di bawah /var/azureml-app/azureml-models/tfserving-deployment/1 dalam penyebaran Anda:
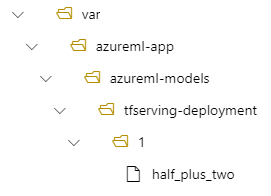
Anda dapat mengonfigurasi model_mount_path secara opsional. Ini memungkinkan Anda mengubah jalur tempat model dipasang.
Penting
model_mount_path harus merupakan jalur absolut yang valid di Linux (OS gambar kontainer).
Misalnya, Anda dapat memiliki parameter model_mount_path dalam tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Kemudian model Anda terletak di /var/tfserving-model-mount/tfserving-deployment/1 dalam penyebaran Anda. Perhatikan bahwa ini tidak lagi berada di bawah azureml-app/azureml-models, tetapi di bawah jalur pemasangan yang Anda tentukan:
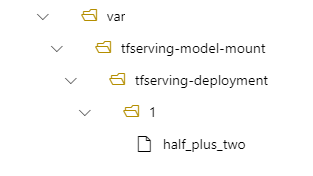
Membuat titik akhir dan penyebaran
Sekarang setelah Anda memahami bagaimana YAML dibangun, buat titik akhir Anda.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Membuat penyebaran mungkin memakan waktu beberapa menit.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Memanggil titik akhir
Setelah penyebaran selesai, lihat apakah Anda dapat membuat permintaan penilaian ke titik akhir yang digunakan.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Menghapus titik akhir
Setelah berhasil mencetak skor dengan titik akhir, Anda dapat menghapusnya:
az ml online-endpoint delete --name tfserving-endpoint