Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Catatan
Untuk tutorial yang menggunakan SDK v1 untuk membangun alur, lihat Tutorial: Membuat alur Azure Machine Learning untuk klasifikasi gambar.
Alur pembelajaran mesin membagi tugas pembelajaran mesin lengkap menjadi alur kerja multistep. Setiap langkah adalah komponen yang dapat dikelola yang dapat Anda kembangkan, optimalkan, konfigurasikan, dan otomatiskan satu per satu. Antarmuka yang terdefinisi dengan baik menghubungkan langkah-langkah. Layanan alur Azure Machine Learning mengatur semua dependensi antara langkah-langkah alur.
Manfaat menggunakan pipeline termasuk praktik MLOps yang terstandar, kolaborasi tim yang dapat diskalakan, efisiensi dalam pelatihan, dan pengurangan biaya. Untuk mempelajari selengkapnya tentang manfaat alur, lihat Apa itu alur Azure Pembelajaran Mesin.
Dalam tutorial ini, Anda menggunakan Azure Machine Learning untuk membuat proyek pembelajaran mesin siap produksi, menggunakan Azure Machine Learning Python SDK v2. Setelah tutorial ini, Anda dapat menggunakan Azure Machine Learning Python SDK untuk:
- Mendapatkan handel ke ruang kerja Azure Pembelajaran Mesin Anda
- Membuat aset data Azure Machine Learning
- Membuat komponen Azure Pembelajaran Mesin yang dapat digunakan kembali
- Membuat, memvalidasi, dan menjalankan alur Azure Machine Learning
Selama tutorial ini, Anda membuat alur Azure Pembelajaran Mesin untuk melatih model untuk prediksi default kredit. Alur menangani dua langkah:
- Penyiapan data
- Melatih dan mendaftarkan model terlatih
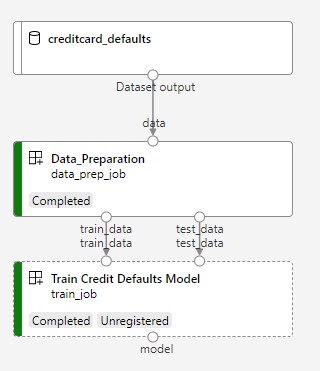
Gambar berikutnya memperlihatkan alur sederhana seperti yang Anda lihat di studio Azure setelah Anda mengirimkannya.
Dua langkah tersebut adalah persiapan dan pelatihan data.
Video ini menunjukkan cara memulai di studio Azure Pembelajaran Mesin sehingga Anda dapat mengikuti langkah-langkah dalam tutorial. Video memperlihatkan cara membuat buku catatan, membuat instans komputasi, dan mengkloning buku catatan. Bagian berikut ini juga menjelaskan langkah-langkah ini.
Prasyarat
-
Untuk menggunakan Azure Pembelajaran Mesin, Anda memerlukan ruang kerja. Jika Anda tidak memilikinya, selesaikan Buat sumber daya yang Anda perlukan untuk mulai membuat ruang kerja dan pelajari selengkapnya tentang menggunakannya.
Penting
Jika ruang kerja Azure Pembelajaran Mesin Anda dikonfigurasi dengan jaringan virtual terkelola, Anda mungkin perlu menambahkan aturan keluar untuk mengizinkan akses ke repositori paket Python publik. Untuk informasi selengkapnya, lihat Skenario: Mengakses paket pembelajaran mesin publik.
-
Masuk ke studio dan pilih ruang kerja Anda jika belum dibuka.
Selesaikan tutorial Mengunggah, mengakses, dan menjelajahi data Anda untuk membuat aset data yang Anda butuhkan dalam tutorial ini. Pastikan Anda menjalankan semua kode untuk membuat aset data awal. Anda dapat menjelajahi data dan merevisinya jika mau, tetapi Anda hanya memerlukan data awal untuk tutorial ini.
-
Buka atau buat buku catatan di ruang kerja Anda:
- Jika Anda ingin menyalin dan menempelkan kode ke dalam sel, buat buku catatan baru.
- Atau, buka tutorial/get-started-notebooks/pipeline.ipynb dari bagian Sampel studio. Lalu pilih Kloning untuk menambahkan buku catatan ke File Anda. Untuk menemukan contoh buku catatan, lihat Pelajari dari contoh buku catatan.
Atur kernel Anda dan buka di Visual Studio Code (Visual Studio Code)
Di bilah atas di atas notebook yang Anda buka, buat instans komputasi jika Anda belum memilikinya.

Jika instans komputasi dihentikan, pilih Mulai komputasi dan tunggu hingga instans berjalan.

Tunggu hingga instans komputasi berjalan. Kemudian pastikan bahwa kernel, yang ditemukan di kanan atas, adalah
Python 3.10 - SDK v2. Jika tidak, gunakan daftar dropdown untuk memilih kernel ini.
Jika Anda tidak melihat kernel ini, verifikasi bahwa instans komputasi Anda sedang berjalan. Jika ya, pilih tombol Refresh di kanan atas buku catatan.
Jika Anda melihat banner yang mengatakan Bahwa Anda perlu diautentikasi, pilih Autentikasi.
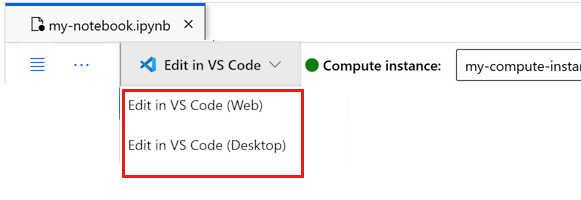
Anda dapat menjalankan buku catatan di sini, atau membukanya di VISUAL Code untuk lingkungan pengembangan terintegrasi penuh (IDE) dengan kekuatan sumber daya Azure Pembelajaran Mesin. Pilih Buka di Visual Studio Code, lalu pilih opsi web atau desktop. Saat diluncurkan dengan cara ini, VISUAL Code dilampirkan ke instans komputasi Anda, kernel, dan sistem file ruang kerja.




Penting
Sisa tutorial ini berisi sel-sel buku catatan tutorial. Salin dan tempelkan ke buku catatan baru Anda, atau beralihlah ke buku catatan sekarang jika Anda mengkloningnya.
Menyiapkan sumber daya alur
Anda dapat menggunakan kerangka kerja Azure Machine Learning dari antarmuka Azure CLI, Python SDK, atau studio. Dalam contoh ini, Anda menggunakan Azure Pembelajaran Mesin Python SDK v2 untuk membuat alur.
Sebelum membuat alur, Anda memerlukan sumber daya ini:
- Aset data untuk pelatihan
- Lingkungan perangkat lunak untuk menjalankan alur
- Sumber daya komputasi tempat pekerjaan berjalan
Membuat handel ke ruang kerja
Sebelum menggunakan kode, Anda memerlukan cara untuk mereferensikan ruang kerja Anda. Buat ml_client sebagai pegangan ke ruang kerja. Anda kemudian menggunakan ml_client untuk mengelola sumber daya dan pekerjaan.
Di sel berikutnya, masukkan ID Langganan, nama Grup Sumber Daya, dan Nama ruang kerja Anda. Untuk menemukan nilai-nilai ini:
- Di toolbar studio Azure Machine Learning, di kanan atas, pilih nama ruang kerja Anda.
- Salin nilai untuk ruang kerja, grup sumber daya, dan ID langganan ke dalam kode. Anda perlu menyalin satu nilai, menutup area, dan menempelkan, lalu mengembalikan untuk nilai berikutnya.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Referensi SDK:
Catatan
Membuat MLClient tidak tersambung ke ruang kerja. Inisialisasi klien malas. Ia menunggu hingga pertama kalinya perlu membuat panggilan. Inisialisasi terjadi di sel kode berikutnya.
Verifikasi koneksi dengan melakukan panggilan ke ml_client. Karena panggilan ini adalah pertama kalinya Anda melakukan panggilan ke ruang kerja, Anda mungkin diminta untuk mengautentikasi.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Referensi SDK:
Mengakses aset data terdaftar
Mulailah dengan mendapatkan data yang sebelumnya Anda daftarkan di Tutorial: Mengunggah, mengakses, dan menjelajahi data Anda di Azure Machine Learning.
Catatan
Azure Machine Learning menggunakan Data objek untuk mendaftarkan definisi data yang dapat digunakan kembali dan menggunakan data dalam alur.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Referensi SDK:
Membuat lingkungan kerja untuk langkah-langkah alur
Sejauh ini, Anda membuat lingkungan pengembangan pada instans komputasi, komputer pengembangan Anda. Anda juga memerlukan lingkungan untuk digunakan untuk setiap langkah alur. Setiap langkah dapat memiliki lingkungannya sendiri, atau Anda dapat menggunakan beberapa lingkungan umum untuk beberapa langkah.
Dalam contoh ini, Anda membuat lingkungan conda untuk pekerjaan Anda, menggunakan file yaml conda. Pertama, buat direktori untuk menyimpan file.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Sekarang, buat file di direktori dependensi.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Spesifikasi berisi beberapa paket biasa yang Anda gunakan dalam alur Anda (numpy, pip), bersama dengan beberapa paket spesifik Azure Machine Learning (azureml-mlflow).
Paket Azure Machine Learning tidak diperlukan untuk menjalankan pekerjaan Azure Machine Learning. Dengan menambahkan paket ini, Anda dapat berinteraksi dengan Azure Machine Learning untuk mencatat metrik dan mendaftarkan model, semuanya di dalam pekerjaan Azure Machine Learning. Anda menggunakannya dalam skrip pelatihan nanti dalam tutorial ini.
Gunakan file yaml untuk membuat dan mendaftarkan lingkungan khusus ini di ruang kerja Anda:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Referensi SDK:
Membuat alur pelatihan
Sekarang setelah Anda memiliki semua aset yang diperlukan untuk menjalankan alur Anda, saatnya untuk membangun alur itu sendiri.
Alur Azure Pembelajaran Mesin adalah alur kerja ML yang dapat digunakan kembali yang biasanya terdiri dari beberapa komponen. Siklus hidup komponen yang khas adalah:
- Tulis spesifikasi YAML komponen, atau buat secara terprogram dengan menggunakan
ComponentMethod. - Secara opsional, daftarkan komponen dengan nama dan versi di ruang kerja Anda untuk membuatnya dapat digunakan kembali dan dapat dibagikan.
- Muat komponen tersebut dari kode alur.
- Terapkan alur dengan menggunakan input, output, dan parameter komponen.
- Kirim alur.
Anda dapat membuat komponen dengan dua cara: definisi terprogram dan definisi YAML. Dua bagian berikutnya memandikan Anda membuat komponen dua arah. Anda dapat membuat dua komponen dengan mencoba kedua opsi atau memilih metode pilihan Anda.
Catatan
Dalam tutorial ini, untuk kesederhanaan, Anda menggunakan komputasi yang sama untuk semua komponen. Namun, Anda dapat mengatur komputasi yang berbeda untuk setiap komponen. Misalnya, Anda dapat menambahkan baris seperti train_step.compute = "cpu-cluster". Untuk melihat contoh membangun alur dengan komputasi yang berbeda untuk setiap komponen, lihat bagian Pekerjaan alur dasar di tutorial alur cifar-10.
Buat komponen 1: penyiapan data (menggunakan definisi terprogram)
Mulailah dengan membuat komponen pertama. Komponen ini menangani pra-pemrosesan data. Tugas pra-pemrosesan dilakukan dalam file Python data_prep.py .
Pertama, buat folder sumber untuk komponen data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Skrip ini melakukan tugas sederhana untuk membagi data menjadi himpunan data latih dan uji. Azure Machine Learning memasang himpunan data sebagai folder ke komputasi. Anda membuat select_first_file fungsi tambahan untuk mengakses file data di dalam folder input yang dipasang.
MLFlow digunakan untuk mencatat parameter dan metrik selama eksekusi alur Anda.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Sekarang setelah Anda memiliki skrip yang dapat melakukan tugas yang diinginkan, buat Azure Pembelajaran Mesin Component darinya.
Gunakan tujuan CommandComponent umum yang dapat menjalankan tindakan baris perintah. Tindakan baris perintah ini dapat langsung memanggil perintah sistem atau menjalankan skrip. Input dan output ditentukan pada baris perintah dengan menggunakan ${{ ... }} notasi.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Referensi SDK:
Secara opsional, daftarkan komponen di ruang kerja untuk digunakan kembali di masa mendatang.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Referensi SDK:
Buat komponen 2: pelatihan (menggunakan definisi yaml)
Komponen kedua yang Anda buat menggunakan data pelatihan dan pengujian, melatih model berbasis pohon, dan mengembalikan model output. Gunakan kemampuan pengelogan Azure Pembelajaran Mesin untuk merekam dan memvisualisasikan kemajuan pembelajaran.
Anda menggunakan kelas CommandComponent untuk membuat komponen pertama Anda. Kali ini, Anda menggunakan definisi yaml untuk menentukan komponen kedua. Setiap metode memiliki kelebihannya masing-masing. Definisi yaml dapat diperiksa di sepanjang kode dan menyediakan pelacakan riwayat yang dapat dibaca. Metode terprogram menggunakan CommandComponent bisa menjadi lebih mudah dengan dokumentasi kelas bawaan dan penyelesaian kode.
Buat direktori untuk komponen ini:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Buat skrip pelatihan di direktori:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Seperti yang Anda lihat dalam skrip pelatihan ini, setelah model dilatih, file model disimpan dan didaftarkan ke ruang kerja. Sekarang Anda dapat menggunakan model terdaftar dalam menyimpulkan titik akhir.
Untuk lingkungan langkah ini, Anda menggunakan salah satu lingkungan Azure Pembelajaran Mesin bawaan (yang dikumpulkan). Tag azureml memberi tahu sistem untuk mencari nama di lingkungan yang dikurasi.
Pertama, buat file yaml yang menjelaskan komponen:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Sekarang buat dan daftarkan komponen. Mendaftarkannya memungkinkan Anda menggunakannya kembali di alur lain. Siapa pun yang memiliki akses ke ruang kerja Anda juga dapat menggunakan komponen terdaftar.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Referensi SDK:
Membuat alur dari komponen
Setelah Anda menentukan dan mendaftarkan komponen Anda, mulai terapkan alur.
Fungsi Python yang load_component() mengembalikan pekerjaan seperti fungsi Python biasa. Gunakan dalam pipeline untuk memanggil setiap langkah.
Untuk membuat kode alur, gunakan dekorator tertentu @dsl.pipeline yang mengidentifikasi alur Azure Machine Learning. Di dekorator, tentukan deskripsi alur dan sumber daya default seperti komputasi dan penyimpanan. Seperti fungsi Python, alur dapat memiliki input. Anda dapat membuat beberapa instans dari satu alur dengan input yang berbeda.
Dalam contoh berikut, gunakan data input, rasio pemisahan, dan nama model terdaftar sebagai variabel input. Kemudian, panggil komponen dan sambungkan dengan menggunakan pengidentifikasi input dan outputnya. Mengakses output dari setiap langkah dengan menggunakan properti .outputs.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Referensi SDK:
Sekarang gunakan definisi alur kerja Anda untuk menginstansiasi sebuah alur kerja dengan himpunan data Anda, tingkat pembagian pilihan, dan nama yang Anda pilih untuk model Anda.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Referensi SDK:
Mengirimkan pekerjaan
Sekarang kirimkan pekerjaan untuk dijalankan di Azure Machine Learning. Kali ini, gunakan create_or_update pada ml_client.jobs.
Berikan nama eksperimen. Eksperimen adalah kontainer untuk semua iterasi yang dilakukan pada proyek tertentu. Semua pekerjaan yang dikirimkan dengan nama eksperimen yang sama muncul di samping satu sama lain di studio Azure Machine Learning.
Setelah selesai, alur mendaftarkan model di ruang kerja Anda sebagai hasil dari pelatihan.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Referensi SDK:
Anda dapat melacak kemajuan alur Anda dengan menggunakan tautan yang dihasilkan di sel sebelumnya. Saat pertama kali memilih tautan ini, Anda mungkin melihat bahwa alur masih berjalan. Setelah selesai, Anda dapat memeriksa hasil setiap komponen.
Klik dua kali komponen Latih Model Default Kredit.
Dua hasil penting yang ingin Anda lihat tentang pelatihan:
Lihat log Anda:
- Pilih tab Output+log .
- Buka folder ke
user_logs>std_log.txtBagian ini memperlihatkan skrip menjalankan stdout.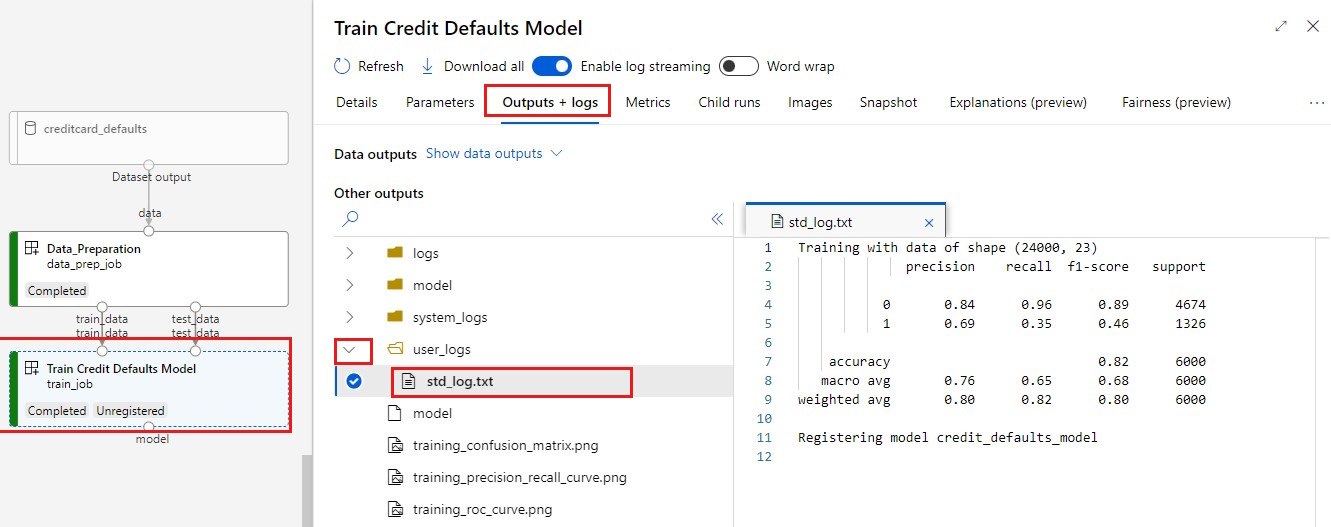
Menampilkan metrik Anda: Pilih tab Metrik . Bagian ini memperlihatkan metrik yang dicatat berbeda. Dalam contoh ini, mlflow
autologgingsecara otomatis mencatat metrik pelatihan.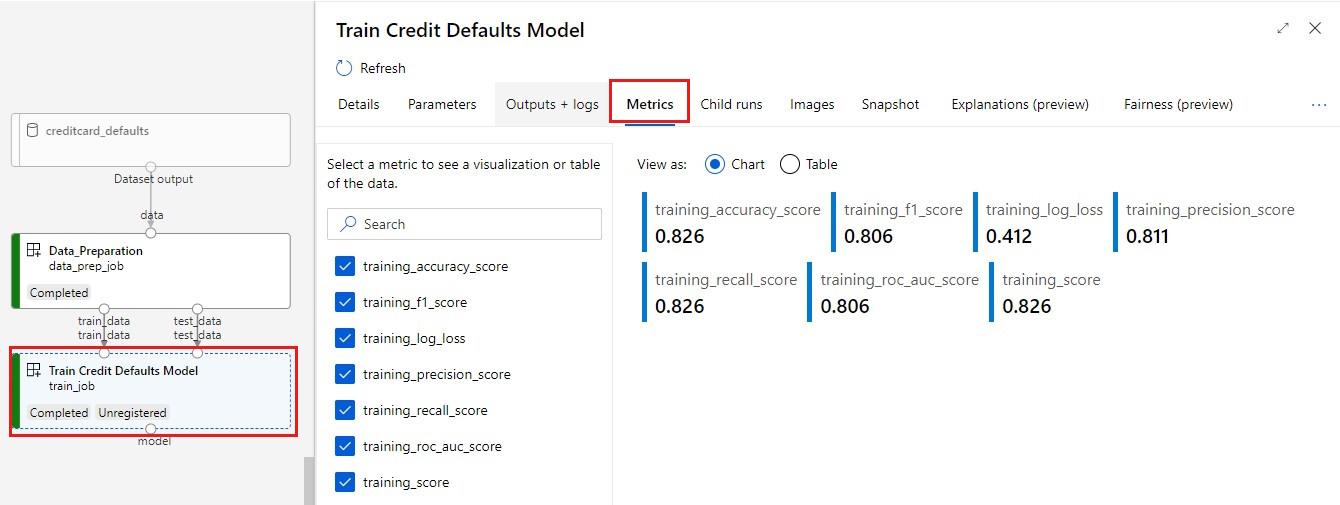


Menyebarkan model sebagai titik akhir online
Untuk informasi selengkapnya tentang menyebarkan model Anda ke titik akhir online, lihat Menyebarkan model sebagai tutorial titik akhir online.
Membersihkan sumber daya
Jika Anda berencana untuk melanjutkan ke tutorial lain, lewati ke Langkah berikutnya.
Menghentikan instans komputasi
Jika Anda tidak akan menggunakan instans komputasi sekarang, hentikan:
- Di studio, di panel kiri, pilih Komputasi.
- Di tab atas, pilih Instans komputasi.
- Pilih instans komputasi dalam daftar.
- Di toolbar atas, pilih Hentikan.
Menghapus semua sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Di portal Azure, di kotak pencarian, masukkan Grup sumber daya dan pilih dari hasil.
Dari daftar, pilih grup sumber daya yang Anda buat.
Di halaman Gambaran Umum , pilih Hapus grup sumber daya.
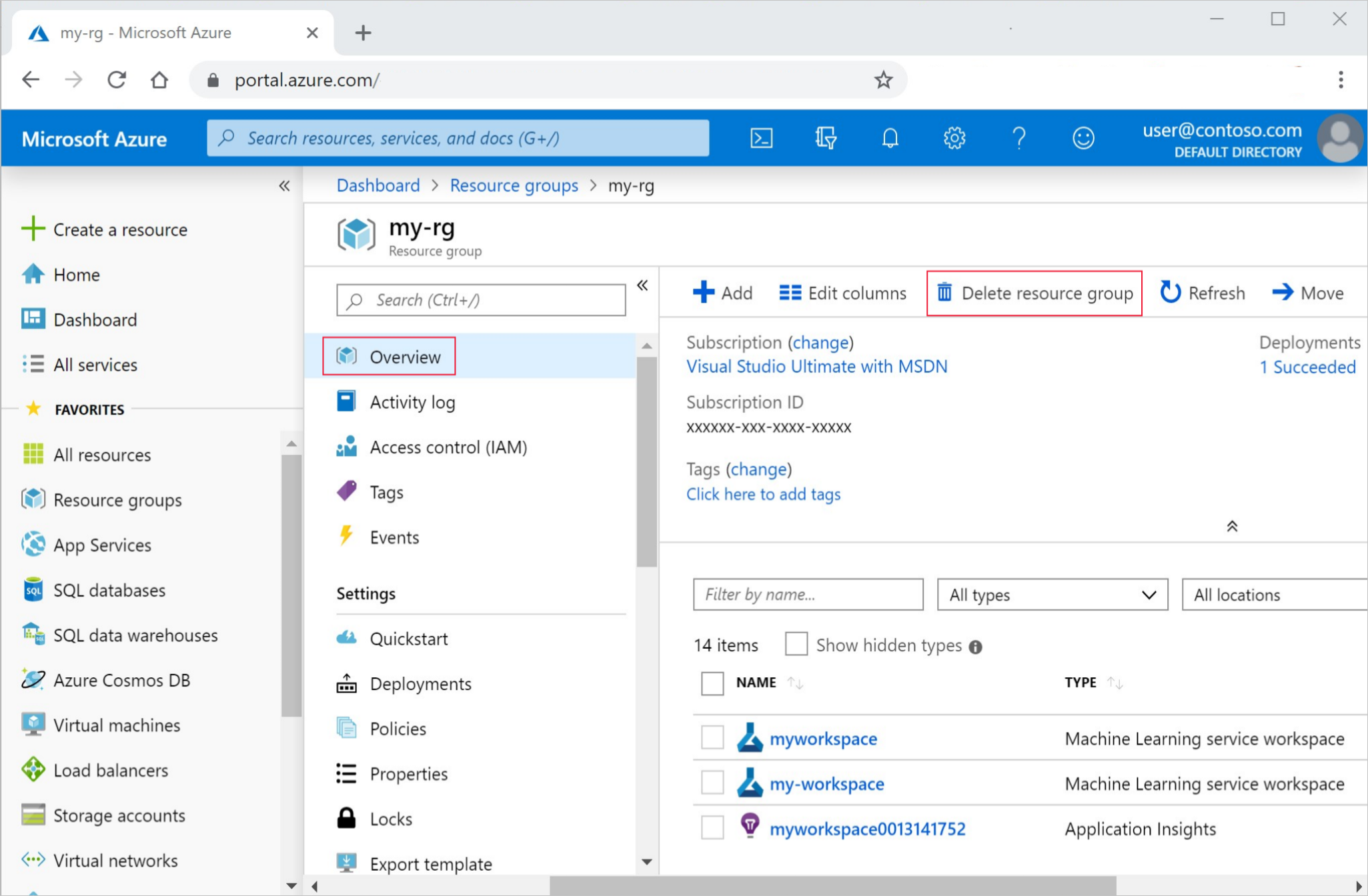
Masukkan nama grup sumber daya. Kemudian pilih Hapus.