Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Jika memungkinkan, sebaiknya gunakan replikasi asli Apache Cassandra untuk memigrasikan data dari kluster Anda yang ada ke Azure Managed Instance for Apache Cassandra dengan mengonfigurasi kluster hibrida. Pendekatan ini akan menggunakan protokol gosip Apache Cassandra untuk mereplikasi data dari pusat data sumber Anda ke pusat data instans terkelola baru Anda. Namun, mungkin ada beberapa skenario di mana versi database sumber Anda tidak kompatibel atau pengaturan kluster hibrida tidak layak.
Tutorial ini menjelaskan cara memigrasikan data ke Migrasi ke Azure Managed Instance for Apache Cassandra secara luring menggunakan Cassandra Spark Connector dan Azure Databricks untuk Apache Spark.
Prasyarat
Memprovisikan Azure Managed Instance for Apache Cassandra menggunakan portal Microsoft Azure atau Azure CLI dan pastikan Anda dapat tersambung ke kluster Anda dengan CQLSH.
Memprovisikan akun Azure Databricks di dalam Managed Cassandra VNet. Yakinkan hal tersebut juga memiliki akses ke sumber kluster Cassandra Anda.
Pastikan Anda telah memigrasikan skema keyspace/table dari database Cassandra sumber Anda ke database Cassandra Managed Instance target Anda.
Kluster Penyediaan Azure Databricks
Sebaiknya pilih runtime Databricks versi 7.5 yang mendukung Spark 3.0.

Menambahkan dependensi
Anda perlu menambahkan pustaka Apache Spark Cassandra Connector ke kluster Anda untuk tersambung ke titik akhir asli dan Azure Cosmos DB Cassandra. Di klaster Anda, pilih Pustaka>Pasang Baru>Maven, lalu tambahkan com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 di koordinat Maven.
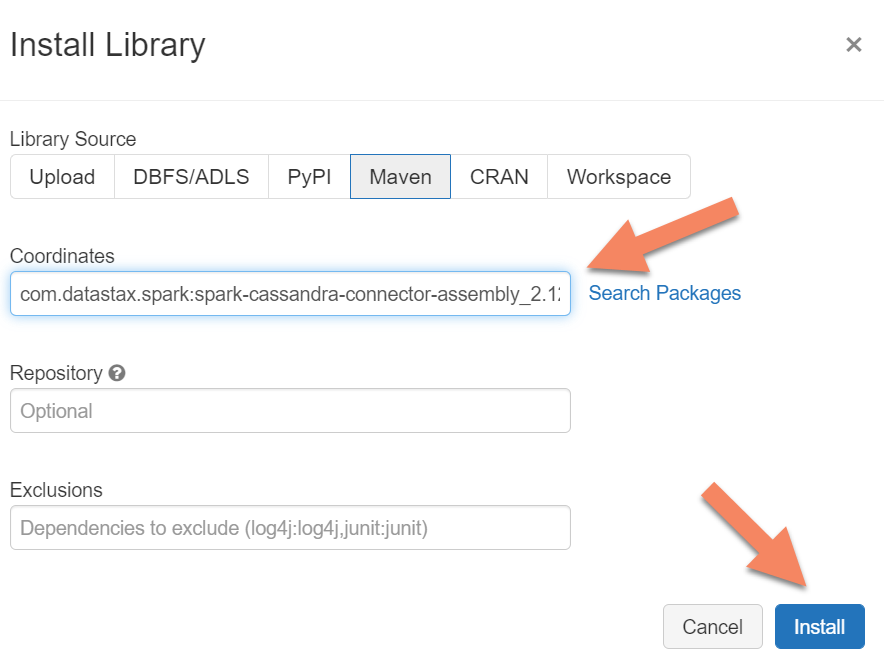
Pilih Pasang,lalu mulai ulang klaster ketika pemasangan selesai.
Catatan
Pastikan Anda memulai ulang klaster Databricks setelah pustaka Konektor Cassandra telah dipasang.
Membuat Scala Notebook untuk migrasi
Membuat Scala Notebook di Databricks. Ganti konfigurasi Cassandra sumber dan target Anda dengan kredensial terkait, ruang kunci dan tabel sumber dan target. Kemudian jalankan perintah berikut:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Catatan
Jika Anda memiliki kebutuhan untuk mempertahankan asli writetime setiap baris, lihat sampel migrator cassandra.